

Riche en inspiration, l’édition 2026 du Devoxx nous a encore donné plein d’idées neuves et a confirmé l'accélération qu’a donnée l’IA à l’ingénierie logicielle. Cet article décrypte les avancées majeures qui seront nos outils de demain : architecture multi-agents, informatique quantique et des outils pour conserver la qualité à l’ère de l’IA. Découvrez dès maintenant nos résumés de conférence pour revoir avec nous les grands concepts de cette édition !
Sommaire
- Les design patterns agentiques dont vous êtes le héros
- Serveurs MCP : bonnes pratiques, choix de conception et leurs conséquences
- Du Storytelling au rendu GPU : Quand Winamax remplace ta console de jeu
- Façonner la pertinence et la résilience de notre expertise au-delà de 2030
- Informatique quantique, ce coup-ci on vous dit tout !
- Les erreurs normales : Anatomie d’un renoncement collectif
- ClaudeCode.proTips(30, minutes=30).run()
- Comment les développeurs lisent du code ?
- Les Value Types ne sont pas ℂomplexes
- Article des stagiaires SE
Les design patterns agentiques dont vous êtes le héros
Guillaume Laforge - Developer Advocate chez Google
Durant cette conférence, Guillaume Laforge nous présente de nombreux systèmes multi-agents ainsi que leurs usages. Loin des simples chatbots, ces architectures redéfinissent notre manière d'interagir avec les LLMs.
Avant de plonger dans la complexité des systèmes multiples, Guillaume rappelle les fondations. Un agent n'est pas juste un LLM "dans une boîte" ; c'est un écosystème articulé autour de quatre piliers :
- L'Objectif : La mission finale confiée par l'utilisateur.
- La Mémoire : La capacité à retenir l'historique et les informations contextuelles.
- Les Outils : Les APIs, processus externes que l'agent peut manipuler.
- Le Planning : La logique qui décide de l'ordre des actions.
Mais pour que l'agent soit efficace, il doit surmonter trois défis techniques majeurs :
- Le planning : quels outils appeler et à quel moment?
- Context engineer : avoir les bonnes informations dans le contexte
- Multitude d’outils à disposition : qui perdent l’agent et le font halluciner
Les patterns
Programmatic planning
Parfois, l'autonomie totale d'un agent n’est pas la meilleure solution. Si votre processus suit une logique métier précise, le Planning Programmatique est souvent la meilleure option.
Ici, le développeur garde le contrôle : on code une séquence fixe d'appels aux LLM.
Cela demande certes de maintenir le code, mais donne de très bons résultats à moindre coûts et sans gestion complexe du contexte.
L’exemple démontré par Guillaume était celui d’une deep research :
- Exploration : Gemini génère une liste de sous-sujets à partir d'une thématique globale, où l’utilisateur n’a plus qu’à sélectionner ceux qui l’intéressent.
- Extraction : Un agent spécialisé utilise Google Search pour compiler des données brutes et rédiger un rapport.
- Synthèse : Gemini condense ce rapport en un résumé percutant.
- Visualisation : Nano Banana transforme le résumé en une infographie visuelle.
Retrieval Augmented Generation
Le RAG est très efficace pour connecter une IA à des données fraîches ou privées sans avoir à réentraîner le modèle. Plutôt que de saturer la fenêtre de contexte avec des documents massifs, on extrait uniquement les fragments de données les plus pertinents. Ceci se fait avec :
- L'Indexation : Le contenu est découpé et converti pour être facilement consultable.
- Le Retrieval : Le système repère et extrait les passages précis liés à la question.
- L'Augmentation : Le LLM utilise ces extraits pour répondre de façon sourcée et fiable.
Progressive Disclosure
Ce pattern consiste à révéler la complexité progressivement. C’est ce que peuvent apporter les skills de Claude. En ne fournissant les instructions et les outils qu'au moment précis où ils deviennent nécessaires, on limite la surcharge cognitive du modèle et on réduit drastiquement le risque d'hallucination.
Guillaume évoque aussi que la solution à la confusion des agents lorsque trop d’outils sont à disposition peut être sous la forme de l’utilisation d'un sous-agent dont l’unique fonction est de rechercher l’outil le plus adapté à la demande.
Hierarchical Agent Decomposition
Lorsqu'on veut réaliser une tâche très complexe, on pourrait être enclin à rédiger un énorme prompt et le donner à un agent monolithique qui a du mal à bien performer sur l’ensemble des tâches. Ce pattern consiste à décomposer une tâche complexe en sous-objectifs confiés à plusieurs agents spécialisés, travaillant souvent en parallèle.
L’exemple démontré était la réalisation d’une bande dessinée basée sur des photos de voyage, où une fois qu’un premier agent avait reconnu le lieu de la photo, deux agents travaillent ensuite en parallèle, un s’occupant de la génération d’une image en format de comics, et l’autre rédigeant un texte sur les lieux proches à visiter et des informations sur le lieu de la photo. En isolant alors les responsabilités, on obtient une qualité de sortie bien supérieure. Chaque agent utilise 100% de sa "puissance de calcul" et de son contexte sur une micro-tâche dédiée, plutôt que de s'éparpiller.
LLM-as-Judge
Évaluer la qualité d’une réponse générée par IA a toujours été complexe. LLM-as-Judge consiste à utiliser un LLM, souvent d’un autre modèle, afin d’évaluer et de noter le résultat d’un agent. La clé ici est de séparer la notation par rubrique, et de demander de rédiger les défauts et points forts de la réponse afin d’avoir une notation cohérente et d’éviter la tendance des IA à évaluer en “bien mais peut être amélioré”.
Ce juge permet éventuellement de réduire les coûts : au lieu d’appeler un gros modèle pour faire une tâche spécifique (comme le résumé d’un texte), il peut être intéressant d’appeler 3 modèles de plus petite taille et moins coûteux, et de prendre le meilleur résultat des 3. Ce résultat peut ainsi parfois surpasser les réponses du plus gros modèle.
GOAP : Goal Oriented Action Planning
Les workflows hardcodés sont souvent rigides et limitent la scalabilité dans leur utilisation. C'est ici qu'intervient le GOAP, un concept issu de l'intelligence artificielle du jeu vidéo, adapté aux agents LLM. Ainsi, au lieu de définir COMMENT réaliser une tâche, on peut définir l’objectif final, fournir des agents avec des préconditions strictes, et laisser alors un agent planificateur qui trouve de manière autonome le chemin atteignant l’objectif.
Coding Agent Loop
Les LLMs sont parfois incapables de résoudre des problèmes complexes du premier coup. Le Coding Agent Loop résout ce problème en introduisant un cycle itératif de "Test & Learn". Au lieu de considérer la première réponse comme finale, on place l'agent dans une boucle de rétroaction incluant des tests, analyse d’erreur et corrections.
En résumé, la conférence de Guillaume Laforge nous rappelle que l'avenir de l'IA ne réside pas dans la puissance d'un modèle unique, mais dans l'intelligence de l'architecture que vous bâtissez autour.
Serveurs MCP : bonnes pratiques, choix de conception et leurs conséquences
de Horacio Gonzales - VP de DevRel chez Clever Cloud
And yet another API style…
Une conférence deep dive bâtie en partant d'un retour d’expérience : comment un LLM a vidé une base de prod via un serveur MCP déployé par les soins du conférencier. Comment ? Un simple "ALTER TABLE" mitraillé par un LLM sans vergogne, un serveur MCP postgre - pourtant officiel - beaucoup trop permissif, et le tour est joué !
Horacio nous emmène dans les arcanes d'un serveur MCP (son rôle dans le harnais agentique, ses primitives, …), puis énumère méthodiquement les points d'attention à adresser avant de déployer en production.
En résumé ? Tous les plâtres essuyés sur vos anciennes api (SOAP, REST, protobuf, ...) et vos microservices n'ont pas été vains. Ressortez vos "vieux" patterns et protocoles, ils s'appliquent plus que jamais pour construire des serveurs MCP prod ready : sanitization des inputs/output, gateway, orchestrator, OAuth2,etc.
Mention spéciale au conférencier : 3h, 140 slides, tout défile sans accroc et sans note sous les yeux, avec un soin didactique particulier... Une réelle performance !
Du Storytelling au rendu GPU : Quand Winamax remplace ta console de jeu
de Thomas Cami et Anthony Maffert - Développeurs chez Winamax
Les règles du poker sont les mêmes, pourtant l'expérience n'a plus rien à voir.
Ces dernières années, la manière de consommer des produits numériques a profondément changé. On est passé d’applications qu’on utilise ponctuellement à des expériences plus proches du divertissement : rapides, accessibles à la demande, et capables de capter l’attention immédiatement.
Des plateformes comme Netflix ou des jeux comme Hearthstone ou Candy Crush ont imposé de nouveaux standards :
- sessions courtes
- gratification rapide
- interaction constante
Partant de ce constat, Winamax a cherché à intégrer ces codes dans son propre univers : le poker.
Un des premiers leviers qu’ils ont activés, c’est la réduction du temps de jeu. Avec le format Expresso, ils proposent des parties à 3 joueurs qui durent moins de 10 minutes. Il re-découpe l’expérience utilisateur en interactions plus courtes et plus rythmées.
C’est un pattern qu’on retrouve partout aujourd’hui :
- formats courts en vidéo
- micro-interactions en mobile
Un autre point central, c’est l’utilisation de l’aléatoire.
Inspiré de Hearthstone, Winamax introduit un système où le gain est déterminé avant même de jouer, avec des multiplicateurs pouvant aller jusqu’à des jackpots très élevés.
Ce mécanisme change complètement la dynamique :
- chaque partie devient potentiellement “spéciale”
- il y a une forme d’anticipation dès le début
- l’expérience est renouvelée en permanence
Une récompense incertaine génère plus d’engagement qu’une récompense fixe. C'est cette recette, des parties rapides et un gain aléatoire, qui fait de ce mode le plus populaire sur la plateforme. L'aléatoire change la dynamique du jeu et permet de créer de l'émotion, du suspense, et devient un levier puissant pour fidéliser et attirer de nouveaux joueurs.
Gamifier sans trahir l'essence du jeu
Aujourd'hui, la frontière entre "application fonctionnelle" et "jeu vidéo" s'estompe.
Fort du succès de l'Expresso, Winamax cherche à appliquer cette logique à d'autres formats. L'objectif : gamifier tous les modes de jeu du poker sans en changer l'essence, et occuper les joueurs en permanence avec la création d'un jeu dans le jeu.
C’est exactement ce qu’ils font avec City of Gold.
Le concept part d'une idée d'anciens joueurs : un jeu de plateau comme un jeu de l'oie où les joueurs avancent petit à petit pour décrocher une récompense finale. Le tout avec des bonus malus, de l'aléatoire, et des règles les plus équilibrées possible.
Ajouter une boucle secondaire permet de maintenir l’engagement, même si le cœur de l’activité est répétitif. C’est particulièrement intéressant dans des contextes où les actions utilisateurs sont similaires, la répétition est forte et l’engagement repose sur la durée.
Mais une boucle de jeu, aussi bien pensée soit-elle, ne suffit pas si l'univers qui l'entoure ne fait pas envie.
C'est là qu'intervient le studio créatif : le logo, le plateau et l'identité visuelle sont travaillés, pour créer une expérience immersive et un engagement émotionnel. L'UI est diégétique, intégrée dans l'univers : chaque case parle d'elle-même. Le joueur n'est plus un utilisateur qui clique, il incarne un personnage qui progresse.
Des vidéos et des storyboards sont créés pour expliquer les règles visuellement et alimenter les réseaux sociaux.
Toutes ces animations ont demandé des innovations technologiques, liées à la taille des applications et aux contraintes des joueurs. La solution de rendu repose sur Spine et WebGL : WebGL comme moteur de rendu 2D, Spine comme outil d'animation.
Plutôt que d'exporter les 60 images du joueur, on exporte un petit bras, une petite jambe, etc. Les charges sont balancées sur la carte graphique plutôt que le CPU. Spine permet de créer des animations hyper précises, visuelles et sonores.
À travers le projet City of Gold, Winamax montre comment les technologies issues du jeu vidéo (moteurs de rendu, design émotionnel) ne sont plus réservées au pur divertissement. Elles deviennent des outils de performance et de rétention indispensables.
Façonner la pertinence et la résilience de notre expertise au-delà de 2030
de Philippe Ensarguet - VP Cloud & Software Engineering chez Orange
À l’occasion de la Devoxx 2026, Philippe Ensarguet a partagé une réflexion profonde sur l'avenir de nos métiers. Alors que l'IA bouscule notre quotidien ces dernières années, une question essentielle subsiste : que signifiera être un expert dans le futur ?
L’évolution rapide de l’expertise
Pour introduire son intervention, le speaker a mis en évidence trois étapes clés qui marquent l'évolution de l'expertise humaine face à la technologie.
Avant l'arrivée de l'IA, l'expert était avant tout celui qui détenait l'information. Dans un contexte où le savoir était rare et difficile d'accès, il occupait un rôle central de référent.
Aujourd'hui, avec l'essor de l'IA, l'information est devenue abondante. Le rôle de l'expert s'est donc déplacé : il ne s'agit plus de posséder l’information, mais de savoir la vérifier, la contextualiser et lui donner du sens.
Dans un futur proche, avec le développement d'IA plus autonomes, l'expert évoluera vers un rôle de « boussole de sagesse ». Son travail consistera à définir précisément les problèmes, à assurer l'intégration entre les différents domaines et à fixer des limites stratégiques avant même de formuler une réponse.
Par ailleurs, rivaliser avec l'IA sur la mémorisation est un combat perdu : dans notre secteur technique, la durée de vie des connaissances a radicalement chuté, passant de 10 ans dans les années 90 à seulement 1 an aujourd'hui. L’expertise n’est donc plus un acquis définitif, mais un capital à réinvestir quotidiennement.
Le constat est clair : si l'IA surperforme dans les tâches routinières et répétitives, elle ne remplace pas pour autant l’humain. Elle agit comme un copilote, mais l'humain reste indispensable pour la compréhension du contexte, la gestion des parties prenantes et le discernement. Le principe est simple : l’IA n’écrase pas l’expertise, elle en automatise une partie et augmente le reste. Finalement, la valeur ajoutée de l'expert se déplace vers sa dimension humaine.
Un nouveau modèle de travail
La généralisation de l’IA nous impose de repenser nos méthodes de travail. Plutôt que de limiter l’IA à un simple moteur de recherche où on pose des questions, il faut la concevoir comme un véritable partenaire avec lequel on co-construit la réflexion. Pour transformer, l’IA en un partenaire actif, quatre pratiques fondamentales sont recommandées :
- L’attribution d’un rôle : Définir précisément le rôle de l’IA au début de l’échange
- La chaîne de pensée : Demander systématiquement d’expliciter le raisonnement afin d’en comprendre la logique
- L’initiative du contexte : Autoriser l’IA à poser des questions lorsqu’il lui manque des informations dans sa fenêtre de contexte
- La boucle de feedback : Instaurer un processus pour affiner et améliorer les réponses au fur et à mesure des échanges
Cette nouvelle forme de collaboration exige une évolution de notre matrice de compétences pour permettre un partenariat efficace et s’étend sur trois domaines : technique (savoir formuler des prompts, évaluer les réponses), cognitif (intégrer l’IA dans notre cheminement de pensée tout en restant vigilant des réponses apportées) et interpersonnel (gérer les équipes humaines et outils IA, traduire les besoins métiers en instructions).
Apprendre à apprendre : la méta-compétence essentielle
Le talk introduit un concept fondamental : l’art d' « apprendre à apprendre », structuré autour d’un cycle en quatre phases.
La première, l’acquisition, consiste à définir précisément les savoirs à acquérir et les objectifs visés. Elle est suivie de l’application, pour laquelle le speaker préconise la méthode de l’« interleaving » : cette approche consiste à étudier plusieurs disciplines connexes en parallèle afin de renforcer la mémorisation. Enfin, les phases de réflexion et de perfectionnement complètent ce cycle ; elles sont cruciales pour prendre du recul sur le travail produit.
Le speaker nous met d'ailleurs en garde contre le piège de la production infinie. Sans ces phases de recul, l'IA nous permet de produire et d'apprendre sans relâche, mais sans réelle direction. Il est donc impératif de définir un besoin clair dès l'exploration, de fixer un critère d'arrêt à la phase d'application et de questionner chaque itération.
Le principe fondamental à retenir est simple : ce n'est pas parce que l'IA nous permet de produire plus que nous devons nécessairement produire plus.
L'intelligence humaine : notre ultime différenciateur
Une distinction majeure doit être établie entre connaissance et intelligence. La connaissance, rationnelle et factuelle, peut aujourd’hui être déléguée à l’IA. L’intelligence, en revanche, est multidimensionnelle : elle exige de combiner le rationnel avec le relationnel (comprendre les non-dits) et l’émotionnel (intégrer la culture et le vécu).
Au-delà de ces dimensions, cinq capacités humaines fondamentales permettent de se distinguer, chacune activée par des leviers spécifiques :
- La découverte : portée par une curiosité active, elle consiste à questionner systématiquement le fonctionnement des choses et à explorer de nouvelles hypothèses.
- La précision : elle repose sur la conscience métacognitive. Contrairement à l'IA qui ne doute jamais, l'humain possède la faculté de réfléchir sur sa propre pensée, transformant le doute en une force de vérification.
- L'agilité : activée par le raisonnement adaptatif, elle permet de changer de perspective, de croiser les disciplines et de détecter quand les règles établies ne s'appliquent plus.
- La résilience : elle s'appuie sur l'interprétation contextuelle. Là où l'IA identifie des modèles statistiques, l'expert humain est capable d'extraire du sens.
- La navigation dans l'ambiguïté : cette capacité permet d'évoluer dans des cadres non définis, de gérer des vérités multiples et de transformer le chaos initial en paramètres clairs et exploitables.
En résumé, le message du speaker est clair : l’IA ne va pas remplacer notre expertise, elle va la transformer. Elle augmente notre expertise en nous délestant de tâches répétitives et en nous permettant de développer notre valeur ajoutée : nos soft skills, seuls remparts contre l’obsolescence.
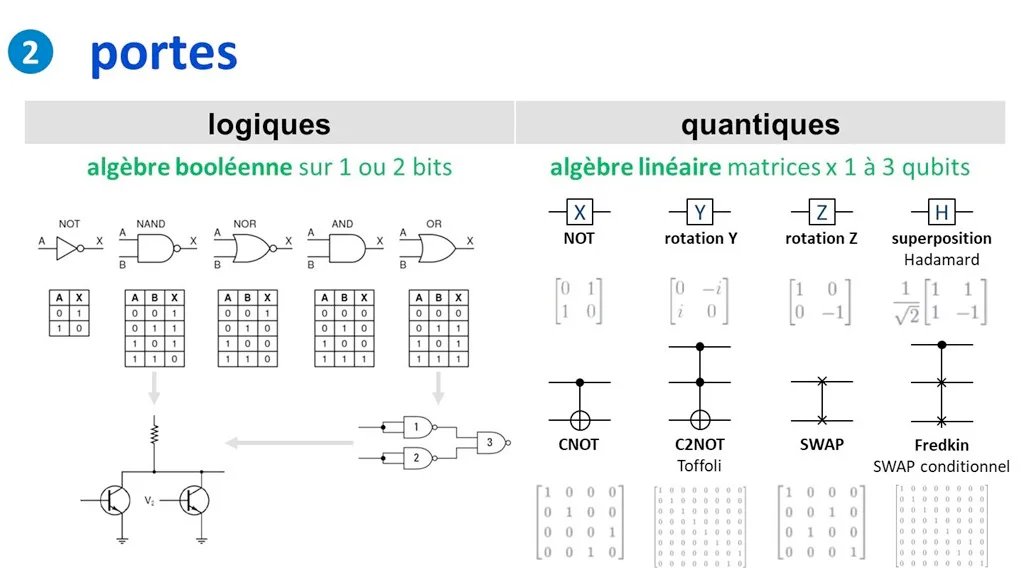
Informatique quantique, ce coup-ci on vous dit tout !
de Fanny Bouton (PM, OVHCloud), Olivier Ezratty (Quantum Energy Initiative), Guillaume Schurck (Développeur Alice & Bob), Sébastien Marie (CTO, Matmut)
Et oui, je me suis engagé sur trois heures de conférences sur l’informatique quantique.
Je vous rassure, je n’ai pas tout retenu, mais j’ai essayé de faire le tri pour vous livrer les éléments les plus concrets et les plus pertinents pour les développeurs. C'était en trois parties, avec les bases du quantique, la mise en pratique via un live coding sur un émulateur d'ordinateur quantique, puis les cas d’usage industriels.
Ces trois heures m'ont surtout prouvé que le quantique n’est plus juste un sujet de physiciens, mais qu’il devient un vrai terrain de jeu pour développeurs curieux, pas encore simple ni mature, mais déjà suffisamment concret pour mériter qu’on s’y attarde.
La théorie
La première partie était très dense, parce qu’Olivier Ezratty a remis les bases sur la table sans trop les édulcorer, en passant par les qubits, la superposition, l’intrication, le bruit et la correction d’erreurs. Le point le plus utile pour un dev reste assez clair, un ordinateur quantique ne remplace pas un ordinateur classique et s’ajoute à lui dans une logique de calcul hybride, avec un CPU qui orchestre et un QPU qu’on appelle sur des problèmes très particuliers.
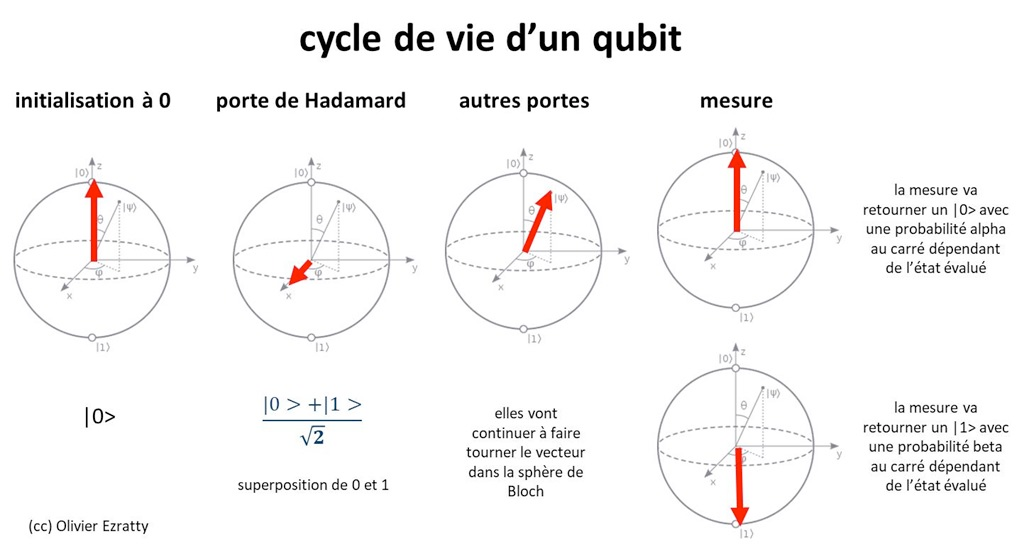
Le live coding était probablement le moment le plus parlant, avec un notebook Jupyter, du code Python et un SDK de développement quantique, même si je serais incapable de vous dire avec certitude si c’était Qiskit ou Cirq. On a vu un workflow que n’importe quel dev peut comprendre, où l’on écrit un circuit, on le teste sur simulateur, on lit les résultats, puis on peut l’envoyer sur un vrai QPU dans le cloud via des services comme ceux d’OVHCloud. C’est précisément à ce moment-là que le quantique cesse d’être une abstraction pour commencer à ressembler, malgré son côté encore très labo, à un vrai environnement de dev.
La pratique
Guillaume Schurck a bien montré ce décalage avec nos habitudes, parce qu’on ne programme pas un ordinateur quantique comme on écrit un backend classique, on construit un circuit, on applique des portes, on mesure, et surtout on accepte qu’un résultat soit probabiliste. Il faut donc exécuter plusieurs fois, lire des distributions et raisonner un peu différemment, ce qui est déroutant au début mais franchement passionnant dès qu’on aime comprendre un nouveau modèle de calcul.
Le business
L’autre très bon moment, c’est le retour d’expérience de la Matmut, où Sébastien Marie a eu le mérite de sortir du fantasme en expliquant que le quantique ne va pas tout révolutionner demain matin, mais qu’il existe déjà des cas d’exploration sérieux. Notamment sur l’optimisation tarifaire et la détection de fraude. Le plus intéressant n’est d’ailleurs pas seulement le cas d’usage, mais la méthode, parce qu’il faut identifier des problèmes très précis, les formuler mathématiquement, puis vérifier si une approche quantique a du sens, le vrai verrou aujourd’hui n’étant pas seulement le hardware, mais la capacité des équipes à poser le bon problème.
Je retiens surtout que le premier ROI du quantique n’est pas forcément business, mais intellectuel, parce qu’il est d’abord dans l’apprentissage, comprendre le modèle, tester, se tromper, voir où ça casse et commencer à bâtir des réflexes avant que la techno soit réellement prête à grande échelle. Attendre que tout soit mûr, c’est probablement surtout prendre le risque d’arriver trop tard.
C’était une conférence longue, très technique et parfois exigeante, mais qui avait le bon réflexe de rester concrète du début à la fin. Si vous êtes dev et que vous pensiez encore que le quantique était un sujet lointain, ce n’est plus vraiment vrai, ce n’est pas prêt pour toutes vos applications, mais c’est déjà assez réel pour qu’on commence à s’y mettre sérieusement.
Les erreurs normales : Anatomie d’un renoncement collectif
de Ivan Jewczuk - Tech Lead chez Decathlon
Avez-vous déjà regardé un tableau de bord de monitoring clignoter en rouge tout en vous disant : « Oh ça ? C'est normal, on a l'habitude » ? Si oui, vous souffrez probablement de déni technique.
C'est ce phénomène fascinant qu'a exploré le talk "Les erreurs normales : Anatomie d'un renoncement collectif". Loin d'être de simples anomalies techniques, ces exceptions ignorées sont le symptôme d'un renoncement psychologique de toute une équipe. Comment en arrive-t-on à tolérer l'intolérable, au point de trouver un absurde Log.error("tout va bien") en production, pouvant coûter des milliers de dollars en stockage de logs chaque mois ?
La ménagerie du développeur : nos 4 animaux de compagnie
Plutôt que de corriger nos erreurs de production, nous avons tendance à les adopter. La conférence a brillamment classifié ces anomalies "domestiques" en quatre catégories :
-
Le Hamster : C'est le redémarrage systématique en production. Face à l'anomalie, on ne cherche plus la cause, on clique sur "restart". Un réflexe automatique qui masque temporairement le problème de fond en faisant tourner la roue sans jamais avancer.
-
Le Chat de Schrödinger : La fameuse erreur qui n'existe que dans un état quantique incertain : « Ça ne marche pas en prod, mais je n'arrive pas à le reproduire en local. » Souvent causé par des règles métier incomplètes ou des données de production impossibles à récupérer.
-
Le Poisson rouge : L'erreur stupide qui noie les vrais problèmes. L'exemple typique ? Un simple test de nullité qui lève une exception et génère 80% des erreurs (le fameux "data not found"). La solution est pourtant simple : inverser le IF et baisser le niveau du log.
-
Le Perroquet : L'erreur qui répète inlassablement la même chose (500 fois par jour dans l’exemple donné durant le talk). Par son volume assourdissant, le perroquet rend les véritables erreurs critiques totalement invisibles dans les dashboards.
La courbe du déni : De la panique à l'oubli
Une erreur ne naît pas "normale", elle le devient. Ce glissement suit une trajectoire psychologique bien précise, calquée sur les phases du deuil :
- La découverte : « Mon Dieu, il faut corriger cette erreur d'urgence ! »
- L'investigation : « Attends, elle impacte qui exactement ? »
- L'adoption : « Ce n'est pas critique, on a d'autres priorités pour ce sprint. »
- L'invisibilité : L'erreur prend la poussière dans le fond du backlog et devient un élément naturel du paysage.
La perception de la gravité d'une erreur n'est pas liée à sa complexité technique, mais à son impact social. C'est le nombre de personnes impactées (ou le profil du client) qui dicte la réaction, pas la laideur du code.
Le syndrome de la vitre brisée
Ce renoncement a un coût. Une erreur non corrigée signale inconsciemment à l'équipe qu'il est acceptable de laisser la qualité se dégrader. Une vitre brisée en entraîne d'autres, et l'application se transforme progressivement en système legacy où le coût de remédiation devient exponentiel. Un risque aujourd'hui amplifié par l'IA, capable de générer rapidement du code très verbeux avec une journalisation excessive.
La cure de désintoxication en 3 "R"
Pour briser ce cycle, il faut changer de méthode. La conférence propose la règle des 3 “R” :
- Reconnaître : Il faut avoir l'honnêteté d'identifier et de nommer ces "erreurs normales" dans nos systèmes.
- Responsabiliser : Impliquer directement les équipes dans la remédiation. La qualité est l'affaire de tous.
- Ritualiser : Ne plus repousser à un hypothétique "sprint technique". La correction des erreurs de logs doit être intégrée dans chaque sprint.
Et donc le meilleur moment pour corriger une erreur, c’est avant qu’elle ne devienne “normale”. Si votre solution consiste simplement à filtrer les logs pour ne plus voir le rouge… sachez que ce n’est pas un correctif, c’est une capitulation.
ClaudeCode.proTips(30, minutes=30).run()
de Erwan Gereec - Engineering Manager chez Doctolib
Derrière ce nom un peu cryptique qui parlera surtout aux développeurs se cache une introduction plutôt solide à Claude Code et ses possibilités. Le principe est simple : 30 astuces / bonnes pratiques liées à l’utilisation de Claude Code en 30 minutes ! Le pari semblait risqué, et pourtant la présentation était plutôt complète, bien structurée et surtout accessible à tous.
En partant de l’installation de Claude Code, Erwan a d'abord balayé les paramètres de confort visuel (thèmes, status line, modes d’affichage alternatifs) pour poser les bases de l'interface. L’occasion de donner au passage quelques définitions clés sur les termes basiques, qui seront utilisés tout le reste de la présentation.
S’en est suivie la présentation de commandes de plus en plus complexes liées à l’utilisation de Claude Code, le tout entrecoupé de guidelines utiles pour la définition de nos fichiers de configuration Claude, de raccourcis pour accélérer nos intéractions avec l’outil ou encore d’astuces pour mieux gérer ses fenêtres de contexte.
Parmi les exemples les plus marquants figurent :
/powerup- Lance un tutoriel interactif qui passe rapidement sur les possibilités de Claude Code/clear- Réinitialise la fenêtre de contexte actuelle sans la fermer/context- Affiche précisément l’état de la fenêtre de contexte actuelle/simplify- Lance plusieurs agents en parallèle pour simplifier la structure du code/effort: Ajuste la profondeur du raisonnement du modèle/insights: Génère un rapport d’analyse de vos sessions, qui permet d’identifier les pertes de temps actuelles et les optimisations possibles dans les intéractions avec Claude./fork&/resume- Tester différentes implémentations en parallèle sans perdre sa progression.
La présentation s’est terminée sur la présentation succincte de notions un peu plus avancées telles que les hooks, les skills et l’automatisation de tâches, qui permettent aujourd’hui d’aller beaucoup plus loin dans l’amélioration de nos workflows avec Claude.
En résumé, cette conférence est une excellente porte d'entrée pour les débutants et un rappel efficace pour les utilisateurs plus avertis. Le support de présentation, déjà disponible en ligne, constitue un aide-mémoire précieux pour quiconque souhaite transformer son terminal en partenaire de programmation.
Comment les développeurs lisent du code ?
de Nicolas Delsaux et Clément Bout - Développeur Java chez Zenika et Ingénieur logiciel chez Zenika
Cette conférence nous plonge dans les coulisses physiologiques de notre métier. Nicolas Delsaux et Clément Bout décryptent la manière dont notre cerveau traite le code, s'appuyant sur les travaux de Felienne Hermans et son livre The Programmer's Brain.
Les trois types de confusion : Pourquoi votre cerveau bloque
La lecture de code n'est pas une activité monolithique. Selon Hermans, nous rencontrons trois types de confusion distincts, liés à trois processus cognitifs différents :
| Type de confusion | Origine physiologique | Description |
|---|---|---|
| Manque d'informations | Mémoire à Court Terme (STM) | Vous ne trouvez pas la définition d'une méthode ou d'une variable dans le code actuel. |
| Manque de connaissances | Mémoire à Long Terme (LTM) | Vous ne connaissez pas la syntaxe ou le concept (ex: un mot-clé APL). |
| Manque de capacité de calcul | Mémoire de travail (Working Memory) | Le code est trop complexe (boucles imbriquées, logique dense) pour être "compilé" mentalement. |
Le fonctionnement de nos mémoires
La Mémoire à Court Terme (STM)
Notre STM est le premier point d'entrée des informations mais elle est limitée. Bien qu'elle dispose de 4 à 8 "cases", la mémorisation devient complexe dès que l'on dépasse 4 éléments.
C'est pour cette raison que nous retenons mieux un numéro de téléphone segmenté en 4 groupes de 3 chiffres (0 800 666 666) plutôt qu'une suite brute de 10 chiffres (ou 5 groupes de 2). En code, c'est la même chose : au-delà d'un certain seuil d'informations disparates, notre cerveau "drop" les données.
La Mémoire à Long Terme (LTM)
La LTM est notre disque dur permanent. Elle se divise en deux grandes catégories:
- Mémoire Déclarative (Explicite) :
- Sémantique : Le sens des concepts, des mots-clés et des algorithmes.
- Épisodique : Le souvenir de vos expériences passées (ex: "J'ai déjà eu ce bug sur ce projet").
- Mémoire Implicite : Les automatismes et aptitudes (ex: taper au clavier, utiliser les raccourcis de l'IDE).
Un point fascinant soulevé durant la conf : notre mémoire épisodique fonctionne comme une base de données graphe indexée par les émotions. Nous retenons mieux un restaurant pour le plaisir qu'il nous a procuré (émotion) que par la date de visite. En programmation, un bug particulièrement frustrant sera mieux mémorisé qu'une correction triviale.
La Mémoire de Travail : Le processeur
Elle se situe à l'intersection entre la STM et la LTM. C'est là que s'effectue la "compilation cognitive". Elle permet d'analyser le code en récupérant les définitions de la STM et les concepts de la LTM pour résoudre un problème. Si le code impose trop d'étapes de calcul (comme des boucles complexes), elle sature : c'est la surcharge cognitive.
Du Code à la Narration
L'enjeu de la lecture de code est la fusion entre ce que nous voyons (STM) et ce que nous savons (LTM). Pour faciliter ce travail, plusieurs pistes ont été explorées.
La plus marquante est celle du "code comme une phrase". L'utilisation d'API Fluent permet de donner un sens sémantique immédiat au code. Cette approche est particulièrement visible dans les bibliothèques de tests qui structurent les assertions de manière quasi naturelle, comme avec assertThat(var).hasSize(n). Au-delà du code pur, l'idée est de raconter une histoire à travers nos Pull Requests pour offrir une véritable structure narrative au relecteur.
Le lien avec le Software Craftsmanship
A mon sens, cette approche physiologique apporte une justification scientifique aux principes du Clean Code et du Craftsmanship. Pourquoi limiter la complexité cognitive ? Pourquoi préférer de petites fonctions ? Ce n'est pas juste une question d'esthétique, mais une nécessité pour respecter les limites physiques de notre mémoire de travail et optimiser le processus de lecture.
En comprenant nos limites cognitives, nous ne nous contentons plus d'écrire du code qui fonctionne ; nous écrivons du code qui peut être lu, compris et maintenu par un cerveau humain.
Les Value Types ne sont pas ℂomplexes
de Clément de Tastes et Rémi Forax - Technical leader chez SCIAM et Enseignant chercheur à l’Université Gustave Eiffel
Depuis de nombreuses années, les développeurs Java sont confrontés à un compromis frustrant : faut-il privilégier l'élégance du code orienté objet ou les performances brutes des types primitifs ? De là est né le projet Valhalla
Le Dilemme de Mandelbrot : Abstraction contre Efficacité
Pour illustrer l'impact des choix d'architecture sur les performances, les conférenciers se sont appuyés sur le calcul de la fractale de Mandelbrot.
- Une implémentation basée uniquement sur des types primitifs offre une exécution extrêmement rapide, mais génère un code complexe, lourd et difficile à lire.
- À l'inverse, l'utilisation de belles abstractions orientées objet produit un code beaucoup plus propre, lisible et maintenable mais le coût en ressources s'envole, rendant l'exécution environ 10 fois plus lente.
L'objectif du projet Valhalla est précis : permettre de coder avec des abstractions de haut niveau tout en garantissant des performances d'exécution comparables à celles des types primitifs.
La JEP 401 et la mécanique des "Value Classes"
La solution technique proposée par la JEP 401 réside dans l'introduction d'un nouveau concept : la value class. En ajoutant simplement le mot-clé value devant la déclaration d'une classe ou d'un record, le comportement de l'objet dans la (JVM) est radicalement modifié.
Ce changement de paradigme implique plusieurs concessions fondamentales :
- Perte d'identité mémoire : Contrairement aux objets traditionnels stockés dans le tas (Heap) avec une adresse mémoire unique, les classes de valeur perdent cette identité.
- Immutabilité garantie : L'objet perd toute mutabilité, ce qui signifie que l'ensemble de ses champs deviennent implicitement constants et finaux.
- Aplatissement des données (Scalarization) : En l'absence d'identité et de mutabilité, les compilateurs JIT (C1 et C2) peuvent "aplatir" les données. La JVM charge alors directement les valeurs dans les registres du processeur, contournant ainsi le coûteux système de pointeurs.
Les impacts directs sur le code Java
Ces optimisations invisibles à l'exécution entraînent des changements de comportement que les développeurs devront anticiper au moment de l'écriture du code :
- L'opérateur de comparaison : Puisqu'il n'y a plus d'adresse mémoire à comparer, l'utilisation de l'opérateur
==évaluera désormais directement le contenu et les valeurs des champs de la classe de valeur. - La synchronisation : L'absence d'identité rend impossible la pose d'un verrou mémoire. Tenter d'utiliser le mot-clé
synchronizedsur une value class lèvera inévitablement une exception à l'exécution. - Rétrocompatibilité : Pour ne pas briser l'écosystème existant, toutes les classes Java historiques seront considérées implicitement comme des classes d'identité (
identity class).
Un prototype prometteur, mais pas encore pour la production
Si ces annonces font rêver les développeurs en quête de micro-optimisations, le Projet Valhalla et la JEP 401 sont toujours en phase de prototypage. Les comportements décrits sont vrais à l'heure actuelle, mais non définitifs, les spécifications demeurent mouvantes. Il est donc fortement déconseillé de concevoir des architectures de production basées sur ces fonctionnalités avant leur intégration définitive et stable dans une future version de Java.
Article des stagiaires SE
Durant cette Devoxx 2026, Ippon a invité quatre stagiaires Software Engineer à l’évènement. Cette section donne ainsi leur ressenti et ce qu’ils ont retenu et appris de cette conférence.
Sessions coup de cœur
Les Fantastiques Petits Modèles de Langue (SML) et quand les utiliser
La conférence a suivi un fil conducteur très clair. Après avoir posé une définition précise des SML, Pierre a abordé l'étape cruciale du choix du modèle, avec un message fort, prendre le temps de créer son propre benchmark est un excellent investissement. Il a ensuite expliqué plusieurs approches comme la RAG, LoRa et le Fine-tuning. pour nous expliquer concrètement dans quels cas les utiliser, en gardant toujours en tête le rapport coût/performance. En résumé, le constat est simple, on réserve les gros LLM aux tâches vraiment complexes. Pour le reste, les SML s'imposent de plus en plus, notamment grâce à l'argument clé de la souveraineté (très à la mode dans le contexte géopolitique européen/français), pouvoir les héberger soi-même garantit un contrôle total sur nos données. Dans un cas d’usage ou l’assistance par IA est un cas d’usage reconnu par exemple pour des développeurs dans de grandes entreprises.
L'Iceberg du CSS : Plongée dans les abysses du moteur de rendu
Présentation animée par un développeur de Winamax structurée comme une descente dans les profondeurs de css. Il a commencé à la surface en présentant des concepts qu’un développeur front utilise quotidiennement et nous avons commencé à descendre. Plus nous descendions les niveaux, plus les fonctionnalités présentées devenaient impressionnantes et je me demandais comment le CSS en était capable. Nous avons vu comment casser l’aspect rectangulaire d’une page, comment intégrer de la logique, jusqu’à avoir un semblant de site marchand sans utiliser de JavaScript ou encore à quel point il est possible de faire des maths pour rendre le style en temps réel. Le clou du spectacle a été la présentation d’un émulateur x86 en CSS, rendu possible car CSS est Turing-complet (https://lyra.horse/x86css/). Entre les concepts hérités de l’aube d’internet, les détournements de directives pour faire du conditionnel et les découvertes récentes, on se rend compte à quel point le CSS est un outil vaste et que son plein potentiel est loin d’être encore atteint. Ma mission me demande d’utiliser du CSS à un niveau élevé pour un projet exigeant. Cette présentation m’a permis de le démystifier et d’avoir une vraie vision globale de toutes ses possibilités et applications.
Debugging with InteliJ IDEA
Un développeur expert en debugging de chez JetBrains nous a montré des fonctionnalités insoupçonnées et de nombreux cas d’utilisations pratiques. Ainsi, durant cette session de live coding, ou plutôt live debugging, Anton Arhipov nous a fait découvrir de nombreuses techniques peu connues d’utiliser le debugger d’Intellij Idea. Il a ainsi parlé des breakpoints qui peuvent exécuter du code, ou qui permettent de servir de condition de passage pour les breakpoints suivants, des boucles jusqu’à ce que des tests incohérents (aussi appelés “flaky tests”) échouent. On a également pu voir l’utilisation du plugin Spring qui fournit des informations supplémentaires lorsque l’application est exécutée. Toutes ces techniques m’aideront sans doute durant mes prochaines sessions de debug!
Les Design Patterns Agentiques : Le futur de l'orchestration IA
Une session animée par un expert de chez Google qui nous a offert une prise de recul sur l’architecture agentique, avec des explications détaillées sur le "pourquoi" et le "comment" de ces structures qui peuvent parfois paraître complexes à première vue.
L'aspect le plus marquant a été l'équilibre parfait entre théorie et pratique : chaque pattern était illustré par des démos en live via de petits projets développés par le conférencier lui-même. Voir l'application directe de la théorie permet de saisir immédiatement la subtilité des interactions entre agents. Cette présentation, à la fois pédagogique et technique, m'a donné une immense motivation pour expérimenter ces patterns de mon côté et explorer tout le potentiel de ces architectures.
Atmosphère
Nous avons beaucoup aimé l’atmosphère de cette Devoxx, marquée par une volonté de partage et de transmission de savoir, renforçant l'aspect inspirant de la conférence. Le cadre était tourné vers les devs, ambiance conviviale, notamment grâce aux bornes d’arcade et aux espaces de détente, essentiels pour maintenir l'énergie durant ces journées denses.
Les assets entièrement IAs, images, vidéos ou même musiques nous ont semblés peu pertinents, un peu trop présents et pour certains indigestes. Là où l’utilisation de l’IA pour la transcription automatique était la bienvenue.
Ressentis
Jules
C’était une expérience très enrichissante ! J’ai pu avoir une idée globale des tendances actuelles avec les nouveaux outils d’IA qui se développent.
Quentin
J’ai beaucoup apprécié cette Devoxx, par ses stands de toute tailles, ses conférences pertinentes avec de nombreux retours d’expérience. Cependant, il reste difficile de trouver d’autres sujets que l’IA, que ce soit dans les stands ou les conférences. Ce grand shift de l’industrie a certes besoin de place pour de la discussion et des retours d’expérience, mais il fait beaucoup d’ombre sur d'autres sujets tout autant intéressants.
Valentin
L’expérience est globalement très positive ! C’est un excellent moyen de se mettre à jour sur les tendances du marché. L’atmosphère est vraiment axée sur le partage, l’échange et l’innovation, ce qui est super inspirant et m'a clairement donné envie de présenter mes propres projets perso à l'avenir.
En revanche, tout n’était pas rose. Visuellement, c’était presque l'indigestion d'IA : entre les vidéos d’intro et les mascottes générées par IA, le rendu global faisait un peu kitsch. C'est aussi un peu dommage de voir que 95% des talks portent sur l'IA... un peu de variété ne ferait pas de mal.
Jonathan
C’était vraiment bien en soi, je m’attendais à avoir une petite mise à jour sur ce que pensait l’industrie tech dans le monde / européen et c’est ce que j’ai eu. Bonne expérience en tant que stagiaire. Très content d’avoir eu la chance de participer à cet évènement même pour un seul jour.
Cette édition 2026 aura été l’occasion de voir à nouveau de super conférences. Les rediffusions seront disponibles sur la chaîne YouTube Devoxx France et les photos de l'événement sur leur Flickr. Nous tenons à remercier les speakerines et speakers, ainsi que la team organisatrice pour cette superbe édition. Nous sommes particulièrement fiers de nos Ippons, Vivien Maleze, Anaïs Moulin et Jérémy Nadal, qui ont donné d’excellentes conférences au Devoxx 2026. A l’année prochaine !
- Dataquitaine 2026 : comment Industrialiser l'IA de Manière Souveraine
- DevFest Toulouse 2025
- AWS Summit 2026 : Comment AWS veut simplifier la vie du DevOps
- Une journée au salon de la data et de l'IA de Nantes 2025


