

Le 19 mars 2026, Dataquitaine tenait sa 9e édition à KEDGE Business School, à Talence. Organisé par ENTER, l’événement confirme son positionnement : un rendez-vous de référence en Nouvelle-Aquitaine pour parler data, IA, recherche opérationnelle et numérique responsable, avec plus de 400 participants annoncés dans la continuité des éditions précédentes, rassemblant universitaire et industriel.
Cette édition 2026 avait un fil rouge clair : sortir des discours généraux sur l’IA pour revenir à des sujets d’exécution. Souveraineté, biais algorithmiques, impact cognitif de l’IA générative, observabilité, industrialisation des agents et qualité des systèmes RAG : les conférences ont rappelé une chose simple. Une fois de plus ( comme BDX.IO le confirmait BDX I/O 2025 : IA, innovations et retours clés de l’édition ), nous ne sommes plus à “que peut faire l’IA ?”, mais “dans quelles conditions peut-on l’utiliser sérieusement ?”. (DATAQUITAINE)
Trois conférences qui ont particulièrement retenu l’attention
1. Souveraineté numérique : passer du principe à l’action
La plénière d’ouverture, “Souveraineté numérique : et si on passait aux actes ?”, était portée par Michel Paulin, président du CSF Logiciels et Solutions Numériques de Confiance. Dans le programme Dataquitaine, cette keynote ouvrait explicitement l’événement, ce qui n’est pas anodin (surtout quand organisé par ENTER Accueil - Pôle ENTER) : la souveraineté n’est plus traitée comme un sujet périphérique, mais comme une condition d’exécution pour les stratégies data et IA. (DATAQUITAINE)
Le message de fond est martelé : dépendre d’un petit nombre d’acteurs technologiques, sur le calcul, les modèles, les couches logicielles ou l’hébergement, expose mécaniquement les organisations à une perte de maîtrise sur leurs coûts, leurs choix techniques et leur trajectoire.
En pratique, cela pousse à réfléchir en termes de multi-cloud, de diversification des briques critiques et de renforcement de la filière européenne et française. Ce point fait écho aux travaux du CSF, qui mettent l’accent sur l’interconnexion des offres logicielles, data, IA et cyber de confiance. (Solutions Numeriques & Cybersécurité)
2. Délégation cognitive : le vrai coût caché de l’IA générative
Autre moment fort : la conférence de Nicolas Charles intitulée “L’IA générative et le coût caché d’une délégation cognitive incontrôlée : comment agir ?”.
Une étude intéressante et complémentaire des premiers travaux menés par Anthropic Accueil - Pôle ENTER : l’IA fait gagner du temps, mais que reste-t-il de l’apprentissage quand on délègue trop vite l’effort de compréhension ?
Le retour d’expérience présenté autour de groupes d’étudiants montrait une tension désormais bien connue sur le terrain : à court terme, l’IA accélère la production, mais cette vitesse peut masquer une moindre rétention des connaissances.
Dit autrement : produire plus vite n’implique pas forcément apprendre mieux. Sans engagement cognitif fort sur une tâche, quelques jours après il ne reste plus grand chose.
On peut alors se demander comment et si c’est possible d’avoir cet engagement en utilisant des outils IA ?
3. Embeddings multimodaux : quand la recherche devient un levier business direct
En fin de journée, la conférence “Embeddings multimodaux pour moteurs de recherches scalables en retail-media” par Mehdi Elion et Aymane Khattabi a illustré un autre visage très concret de l’IA : l’alignement entre performance technique et impact métier.
L’idée est simple: améliorer le matching entre texte et image grâce à des embeddings multimodaux pour mieux servir les usages de recherche et de recommandation. Derrière le sujet technique, il y a un enjeu business immédiat : la qualité du retrieval ne relève pas seulement de la technique à l’état de l’art, elle agit directement sur l’expérience utilisateur et la performance commerciale. Pour ce faire, la démarche de finetuning a été présentée.
Et pour quel résultat ? Près de +30% de clique de la part des utilisateurs par rapport au modèle précédent !
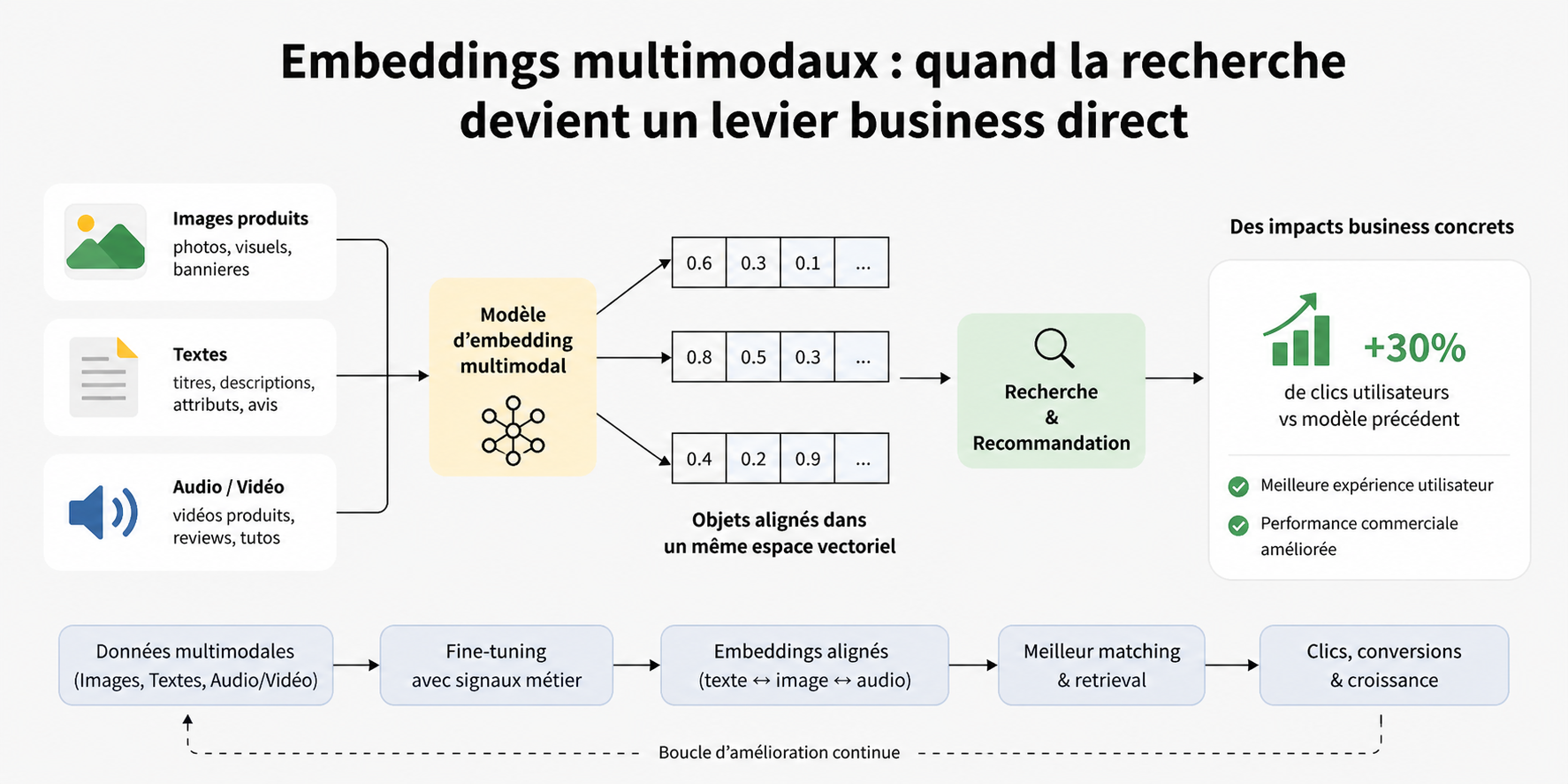
C’est typiquement le genre de talk qui rappelle que les architectures IA robustes ne valent que si elles déplacent une métrique métier utile.
Notre conférence : un RAG qui progresse à chaque commit
Parmi les conférences de l’après-midi, nous avons présenté la démarche de construction d“Un RAG qui progresse à chaque commit : évaluations automatiques, CI, dashboards”, construit avec notre client, le lab Innovation ANSSI.
Le sujet part d’un problème très concret : comment construire un assistant fiable sur un corpus exigeant, ici les guides de l’ANSSI, qui compte plus de 130 documents PDF, complétés par d’autres sources externes. Le choix du RAG s’impose pour garder la main sur la base de connaissance, citer les sources utilisées et orienter l’utilisateur vers les documents de référence.
Mais l’intérêt principal de ce retour d’expérience n’est pas simplement “faire un RAG”. Il est ailleurs : faire progresser un RAG comme un vrai produit logiciel.
La présentation montre une chaîne complète :
- découpage et indexation documentaire des guides ;
- vectorisation avec BAAI/bge-m3 ;
- génération de réponse avec citations et call-to-action vers les sources ;
- mise sous contrôle de la qualité, côté retrieval comme côté generation.
Le point clé est l’évaluation continue. Un dataset d’environ 200 questions typiques a été constitué, avec pour chacune une réponse experte et l’identification des bons documents et pages attendus. À chaque évolution du système, une GitHub Action déclenche les évaluations, les résultats sont historisés par commit et exposés dans Metabase. L’équipe suit à la fois des métriques déterministes de retrieval et des métriques de génération via DeepEval, comme la pertinence de réponse, les hallucinations ou la toxicité. L’idée directrice est simple et très saine : ne conserver que les évolutions réellement gagnantes.
Nous y avons défendu notre conviction: un système RAG ne se pilote pas au feeling, il se pilote par la mesure.
Autre point intéressant : ce REX s’inscrit dans un contexte souverain cohérent de bout en bout, via l’usage d’Albert API, la plateforme interministérielle d’inférence de l’État, conçue pour permettre aux administrations d’exploiter l’IA générative dans un environnement sécurisé et souverain. (Numerique)

👋Pour voir le replay de notre conférence c’est ici :
https://www.dailymotion.com/video/xa4y1v8?playlist=xbwnns
Ce que Dataquitaine 2026 confirme
Cette édition 2026 a surtout confirmé une bascule. Le marché parle moins de promesses abstraites et davantage de conditions de passage à l’échelle :
- maîtrise de la dépendance technologique ;
- contrôle des biais et des atteintes au droit ;
- vigilance sur les effets cognitifs de l’usage massif de l’IA ;
- évaluation continue des systèmes ;
- lien explicite entre qualité technique et performance métier.
C’est précisément là que les acteurs data et IA sont attendus en 2026 : non pas sur leur capacité à produire une démo de plus, mais sur leur capacité à construire des systèmes robustes, mesurables, explicables et exploitables durablement.