
Avant d'être un développeur IA, je suis software crafter. TDD, DDD, architecture hexagonale, pyramide de tests réfléchie : ça fait des années que ces pratiques structurent mon quotidien de développeur afin de garantir un code toujours centré sur la qualité. Mais ma façon de travailler a beaucoup évolué récemment. Cette évolution s'est faite par étapes depuis quelques années et l'arrivée de l'IA.
ChatGPT d'abord, un Stack Overflow sous stéroïdes qui n'a pas vraiment changé ma manière de coder, plutôt une manière de trouver de l'aide ou de structurer ma pensée. Le vrai tournant pour moi est arrivé il y a environ un an avec le Prompt-Driven Development : l'IA dans l'IDE, des prompts structurés, des skills qu'on construit et qu'on affine petit à petit. Cela correspond finalement à la rédaction des règles qui étaient jusque-là peu documentées ou tacites dans nos équipes de développement. Le dev devient celui qui cadre l'IA plutôt que celui qui tape du code.
Louis Lenoir détaille bien cette approche dans son livre blanc sur le PDD.
Il y a quelques semaines, j'ai découvert Vibe Kanban et j'ai pu l'utiliser chez un client : plusieurs agents IA en parallèle, orchestrés visuellement via un kanban, ce que Cédric Magne appelle le "Kanban-driven development". C'est puissant, mais c'est encore le dev qui pilote tout.
Et puis il y a eu cette soirée avec la communauté CTO de Lyon. On venait de présenter un live-coding avec Clément Virieux sur le développement augmenté. Dans la foulée, je discute avec Tangi Vass, développeur lyonnais qui bosse sur un outil open source appelé Liza. Il m'explique le concept : un système multi-agent qui prend en charge l'orchestration de bout en bout, des specs au code mergé. Ça m'a donné envie de tester.
Le lendemain, j'ai repris mon projet de catalogue de bières (le même que j'avais déjà réalisé avec vibe kanban pendant le live coding) et j'ai lancé Liza.
Liza en 30 secondes
Liza est un système multi-agent open source conçu pour produire du code de qualité dès le premier passage. Le principe est simple : on lui donne un objectif et des spécifications, et Liza enchaîne décomposition en epics, rédaction des user stories, planification de l'architecture, écriture de code, revue de code et intégration. À chaque étape, un agent réalisateur produit le travail et un agent relecteur le challenge. Si le relecteur rejette, le réalisateur corrige et resoumet. Chaque décision est tracée et auditable.
Liza n'est pas lié à un LLM en particulier. Il supporte Claude, Codex, Kimi, Mistral, Gemini : d'abord pour que chacun puisse utiliser le fournisseur de son choix, mais aussi pour diversifier les "opinions" entre agents. Un relecteur sur Codex qui relit du code produit par Claude, par exemple.
Mon terrain de jeu
Le projet est volontairement simple : un catalogue de bières avec un back-office d'administration, une page de consultation du catalogue et un système de commande avec gestion de stock. Le tout en full-stack Spring Boot + Vue.js + PostgreSQL, les specs tiennent en quelques lignes.
Ce qui rend le test intéressant, ce n'est pas le projet en lui-même, c'est ce que j'avais déjà en place : des skills et des instructions bien rodées (conventions Spring Boot & Vue.js, stratégie de test, méthodologies craft, conventions Cypress & Cucumber...), une architecture hexagonale appliquée des deux côtés, front et back, une vérification de la couverture de code à 100%, des linters, une pyramide de tests stricte. Tout ce cadre craft que j'ai construit au fil des mois pour le PDD, c'est exactement ce dont Liza a besoin pour fonctionner.
Je ne connaissais pas du tout Liza mais j'ai appris en faisant ce petit projet : la documentation du repo, quelques vidéos officielles, et Claude en pair à côté pour me guider quand je bloquais.
J'ai récupéré mes skills de PDD, installé Liza, et démarré avec un fichier de specs de quelques lignes :
liza init "Créer un catalogue de bière" --spec documentation/spec.md
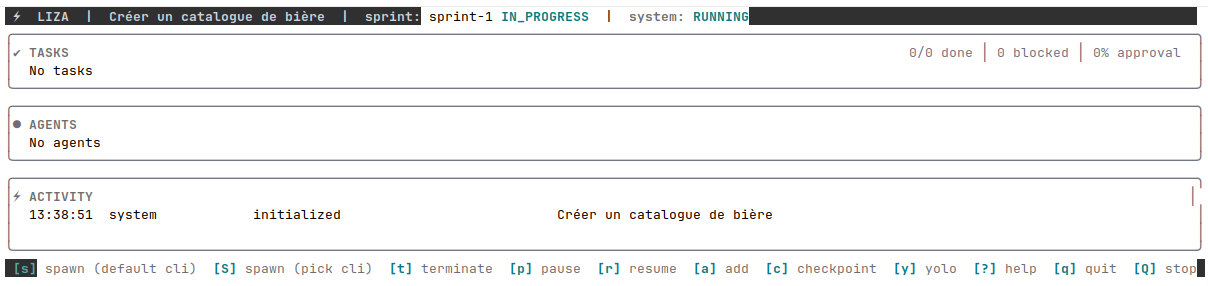
Et voilà à quoi ressemble le TUI (Text User Interface) de Liza au démarrage :
Ce que j'ai observé
L'orchestration et mon rôle
Une fois Liza lancé sur mon objectif et mes specs, le pipeline s'est mis en route. L'orchestrateur a décomposé le projet en deux epics (gestion du catalogue et commandes), puis chaque epic a été déclinée en user stories, en plans d'architecture, en tâches de code. On voit ici l'orchestrateur qui vient de créer les deux epics, et l'epic-planner-1 est déjà au travail sur la première :
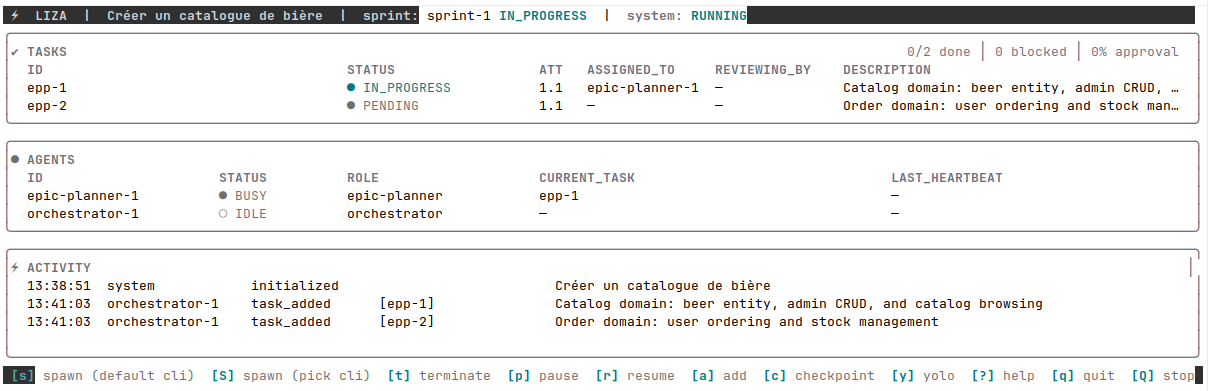
Au total, une trentaine de tâches créées et exécutées sur 5 sprints automatiques.
Ce qui m'a le plus frappé, c'est la capacité du système à s'auto-corriger. Un agent codeur se retrouve bloqué parce qu'une dépendance n'est pas encore prête ? Il remonte le problème, l'orchestrateur réorganise les tâches et relance. Un doublon est créé par erreur ? Il est détecté et supprimé. Tout ça sans intervention de ma part.
Mon rôle a surtout consisté à superviser le tableau de bord et à valider les étapes de planification : la décomposition en epics est-elle pertinente ? L'architecture proposée tient-elle la route et respecte les principes imposés ? La planification du code permet de découvrir les problèmes très tôt, avant qu'un agent ne code dans le vide. Sur un vrai projet avec un⸱e PO, on pourrait probablement raccourcir la phase d'élaboration des specs : Liza permet d'ailleurs de court-circuiter cette phase.
La différence avec le PDD est nette : en PDD, surtout avec des modèles moins puissants comme Haiku, il faut être derrière en permanence. Quand on orchestre les agents manuellement, on porte la charge de toute la coordination. Ici, j'interviens quand c'est nécessaire, pas en continu. Cela me laisse le temps pour écrire un article.
La qualité : le craft amplifié
Chaque tâche de code passe par un agent réalisateur puis un agent relecteur. Sur l'ensemble de l'exécution, cela a représenté 35 verdicts de revue avec 91% d'approbation au premier passage et 3 rejets, à chaque fois corrigés et resoumis automatiquement.
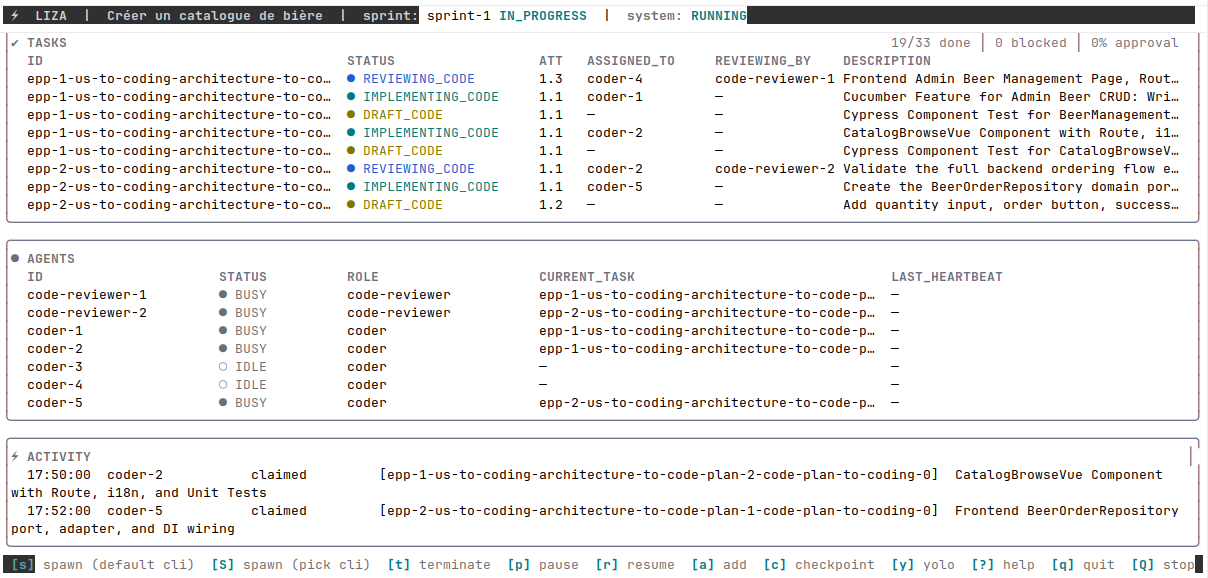
Ce mécanisme de revue change beaucoup de choses. En PDD, c'est le dev qui porte la revue de code en boucle : "tu n'as pas fait la bonne chose", on corrige, on relance, c'est ingrat et ça pèse sur la charge mentale. Avec Liza, les agents se corrigent entre eux et le système boucle jusqu'à ce que le résultat soit satisfaisant. Le relecteur vérifie la cohérence entre les tâches parallèles, pas seulement le code pris isolément. C'est ici que ça se voit le mieux, avec 5 coders et 2 reviewers actifs en même temps, des tâches à tous les stades :
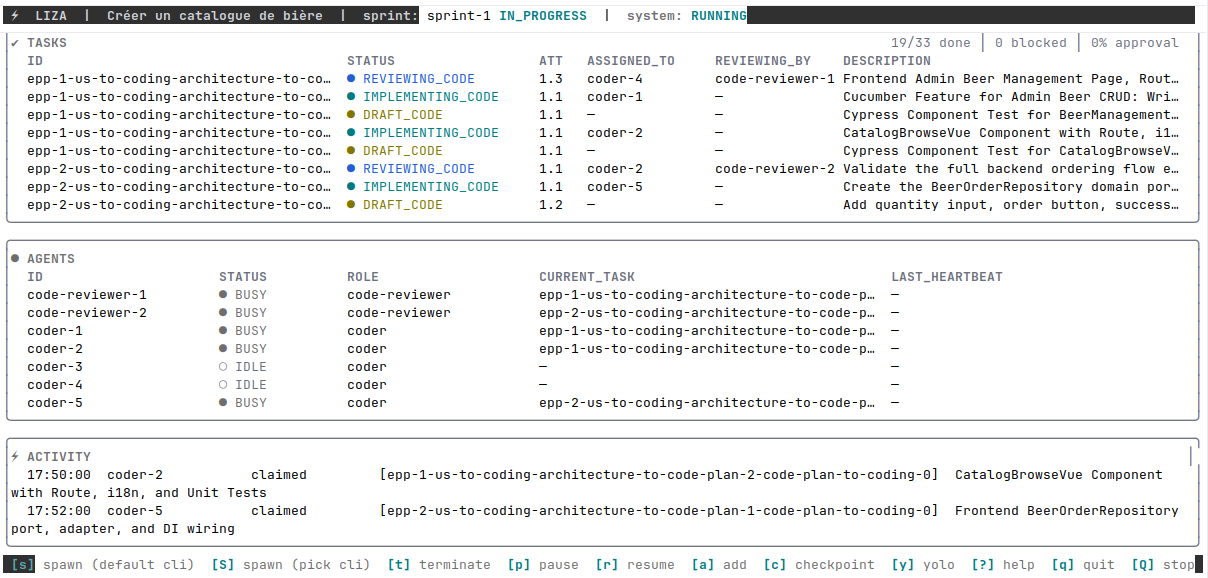
Le code produit au final est similaire à ce que j'obtiens quand j'orchestre les agents moi-même, sans qu'un humain ait codé une seule ligne.
Mais rien de tout ça ne fonctionne sans le cadre craft. Sans les skills qui imposent les conventions, sans la couverture à 100% qui force à tester chaque branche, sans la pyramide de tests qui structure les niveaux de vérification, les agents produiraient du code jetable.
L'IA accélère, elle ne remplace pas les exigences.
Le temps et le coût
En temps humain, j'ai passé 3 à 4 heures sur cette exécution complète. C'est plus long qu'en orchestration manuelle (environ 1h), car Liza passe par beaucoup plus d'étapes (specs, architecture, planification, codage, revue, intégration), mais la progression est plus linéaire, avec moins de va-et-vient, moins de "je repasse derrière pour vérifier" et sûrement plus industrialisable.
Le coût, c'est le vrai sujet. La consommation de tokens est massive. J'ai fait tourner l'ensemble sur Opus 4.6, le modèle le plus cher, mais aussi celui qui génère le moins d'allers-retours. Sur du multi-agent où chaque interaction coûte, un modèle qui comprend du premier coup est un investissement qui se justifie. Un abonnement type Claude Max à 200€/mois est quasi obligatoire, et dans l'idéal il faudrait y ajouter un abonnement Codex pour faire challenger le code par un modèle différent, idéalement d'un autre fournisseur (approche dite adversarial), ce que je n'ai pas pu tester ici.
On ne va pas se mentir : plus on monte en qualité avec ces outils, plus ça coûte cher. C'est un vrai budget, et il faut que les organisations en soient conscientes. La question n'est pas de savoir si c'est rentable par rapport à une journée de développement. Il est trop tôt pour répondre à cette interrogation honnêtement. La question est plutôt : est-ce qu'on est prêt à investir pour explorer ce que ça change dans notre façon de construire du logiciel ?
Et maintenant ?
Ce test m'a donné envie d'aller plus loin. Liza sur un projet simple, ça fonctionne. Mais ce que je veux voir maintenant, c'est ce que ça donne sur un vrai projet client, avec de la complexité métier, une équipe et des modèles différents entre codeur et relecteur pour éviter les biais partagés. C'est sur ce point que je pourrais vraiment constater tout le potentiel.
Si je devais donner un conseil, ce serait de ne pas sauter les étapes :
- Le PDD apprend à structurer ses prompts et ses skills.
- Vibe Kanban apprend à orchestrer plusieurs agents en parallèle et à affiner ses scripts
- Liza, c'est l'étape d'après : l'industrialisation de cet ensemble
Ce que je retiens de cette expérience, c'est une conviction qui se renforce : le développement augmenté franchit encore un palier avec des outils comme Liza. On passe du dev qui utilise l'IA comme un outil au dev qui supervise un système d'agents. Le rôle change, mais l'expertise craft n'a jamais été aussi centrale : c'est elle qui fait la différence entre des agents qui produisent du code jetable et des agents qui produisent du code qu'on peut maintenir.
- Les 4C, votre assurance qualité face au Vibe Coding
- L'IA débarque sur le banc de touche : comment la tech transforme le rugby
- Model Context Protocol (MCP) : Comprendre le standard et retour d’expérience pour exposer un CLI Rust dans votre IDE
- Spec-Driven Development (SDD) : de la spécification au code avec l’IA (exemple complet avec Kiro)
Vous souhaitez inclure l'IA dans vos pratiques de développement ?
Nos consultants accompagnent vos équipes sur l'implémentation de solutions IA.
