

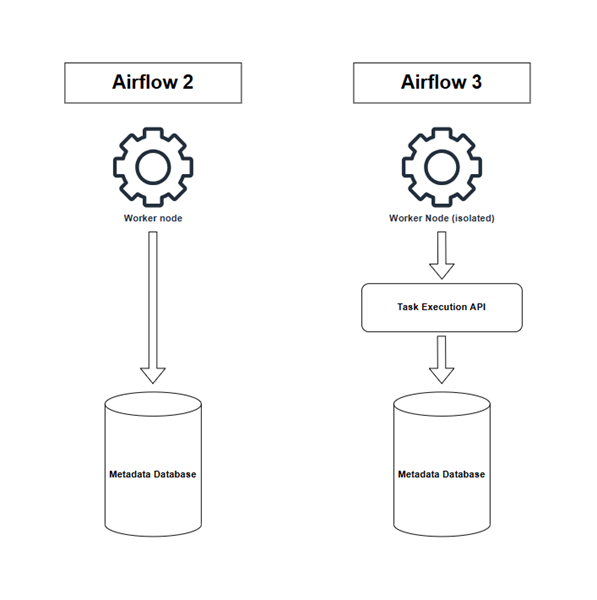
Avec ses 40 millions de téléchargements, sa communauté Slack de 60 000 membres et ses 3 000 contributeurs, Apache Airflow s’impose comme le standard de l’orchestration moderne. Une position renforcée par la sortie d’Airflow 3 en avril 2025. Fruit d’environ un an de travail communautaire, cette version majeure a apporté une refonte totale de l'interface en React, une architecture sécurisée sans accès direct à la base de données et une orchestration facilitée par les Assets.
Afin de célébrer la parution de la nouvelle version 3.2, un rassemblement de la communauté Airflow a eu lieu à Paris, dans les locaux d’Ippon Technologies organisé par l’équipe Astronomer, qui est l’un des principaux contributeurs d’Airflow, proposant sa propre plateforme cloud managée. Au programme : une conférence sur les nouveautés de l'outil et le retour d’expérience d’Ismail MEZZOUR, Data Engineer depuis 5 ans, sur le déploiement d’Airflow au sein d’une Data Platform.
Airflow 3.2 : Les principales nouveautés
Cette nouvelle release, contenant plus de 50 PRs de nouvelles fonctionnalités et environ 80 correctifs, apporte son lot de changements. Parmi eux, deux ont été particulièrement mis en avant lors de la présentation.
La star de la release : Les Partitions
Jusqu'à la version 3.2, faire transiter des paramètres d'un DAG à un autre ou récupérer la donnée d'un asset était une lourde charge de travail. La méthode classique consistait à utiliser la macro « ds » pour extraire la date directement depuis le Run ID. Aujourd'hui, Airflow introduit le concept de Partition Key (généralement un timestamp) qui se propage de bout en bout entre les DAG Runs. Cela permet d’appliquer un suivi chronologique ou d’effectuer un lancement manuel sur un segment précis. Pour offrir encore plus de flexibilité, les Partition Mappers permettent de transformer et de récupérer la valeur des Partition Keys facilement. En bref, c’est une fonctionnalité très attendue qui vient grandement faciliter le partitionnement.
from airflow.decorators import dag, task
from airflow.datasets import Asset
# Déclaration d'un Asset avec une clé de partition spécifique
my_partitioned_asset = Asset("s3://my-bucket/data", partition_key="execution_date")
@dag(schedule=[my_partitioned_asset])
def partition_mapper_dag():
@task
def process_data(partition_key: str = "{{ partition_key }}"):
# Plus besoin de parser le Run ID ou la macro 'ds'
print(f"Traitement exclusif du segment : {partition_key}")
return partition_key
@task
def transform_partition(mapped_value: str):
# Le mapper transforme la donnée à la volée
print(f"Transformation de la partition : {mapped_value}")
# Propagation native de la clé et utilisation d'un mapper
raw_key = process_data()
transform_partition.expand(mapped_value=[raw_key])
partition_mapper_dag()L'Async `@task` : Paralléliser intelligemment
Une autre nouveauté majeure de cette version est l’ajout de l’Async @task qu’il ne faut surtout pas confondre avec les opérateurs asynchrones classiques comme les Deferrable Operators. Ces derniers restent la meilleure option pour optimiser les Workers lors de longues attentes sur des systèmes externes. L'Async @task, lui, brille pour la gestion des tâches concurrentes. Le but est de lancer de multiples petites requêtes en parallèle, sans saturer l'infrastructure. Les chiffres partagés lors du meetup parlent d'eux-mêmes : 2 tâches de 2 secondes s'exécutent maintenant en 2,1 secondes, et 20 tâches de 5 secondes s'exécutent en environ 6 secondes.
C'est un ajout très puissant, à condition de bien réfléchir à son intégration en amont.
import asyncio
import httpx
from airflow.decorators import task, dag
@dag(schedule="@daily")
def async_api_dag():
@task
async def fetch_multiple_apis_concurrently():
urls = [
"https://api.monservice.com/data/segment_A",
"https://api.monservice.com/data/segment_B",
"https://api.monservice.com/data/segment_C"
]
# Le Worker Airflow reste actif mais gère les 3 requêtes en même temps
async with httpx.AsyncClient() as client:
tasks = [client.get(url) for url in urls]
# Exécution parallèle (I/O bound)
responses = await asyncio.gather(*tasks)
for url, response in zip(urls, responses):
print(f"Statut {url} : {response.status_code}")
return "Toutes les requêtes asynchrones sont terminées !"
fetch_multiple_apis_concurrently()
async_api_dag()Autres améliorations diverses
Au-delà de ces évolutions structurelles majeures, la version 3.2 se penche aussi sur l'expérience utilisateur globale pour améliorer le quotidien des développeurs :
Des alertes plus intelligentes : Les Deadline Alerts (AIP-86) font leur apparition en s'appuyant sur trois paramètres précis : référence, intervalle et callback. Cette nouvelle fonctionnalité est très utile pour calculer et monitorer la durée moyenne historique d'exécution d'un job, permettant d'identifier rapidement les dérives de performance.
Ergonomie et fluidité : L'interface utilisateur continue de s'affiner pour faciliter le débogage et les relances. On note une bien meilleure visibilité des différentes versions de DAGs, de meilleurs filtres (DAG, DAG Run, Task Instance) , l'ajout du nouveau paramètre allow_run_type, et une option très pratique : la possibilité de définir manuellement le Data interval directement depuis l'interface utilisateur. On note également le retour de la vue Gantt des tâches d'un DAG run, qui avait disparu depuis Airflow 3.0.
Personnalisation : L'interface supporte maintenant la customisation via des thèmes CSS.
Un écosystème centralisé : Bien que ce ne soit pas exclusif à cette release, le hasard du calendrier fait coïncider la sortie de la version 3.2 d’Airflow avec la mise en ligne du nouveau Provider Registry. Ce catalogue référence déjà plus de 98 opérateurs, prouvant une fois de plus la capacité d'Airflow à se connecter à l'ensemble de l'écosystème data.
REX: Comment intégrer Airflow à une Data Platform ?
Pour la deuxième partie de ce meetup parisien, on s’est éloigné des spécificités techniques des versions pour donner un aperçu de la réalité du terrain lorsque l’on déploie Airflow en entreprise.
Avant Airflow : Quand l'orchestration devient un labyrinthe technique
Ismail MEZZOUR, Data Engineer, nous a partagé son expérience projet : une équipe de 10 Data Engineers devant gérer une Data Platform orchestrée via plusieurs outils et desservant une centaine d’utilisateurs, en promettant d’offrir une autonomie totale aux équipes travaillant sur les services Data.
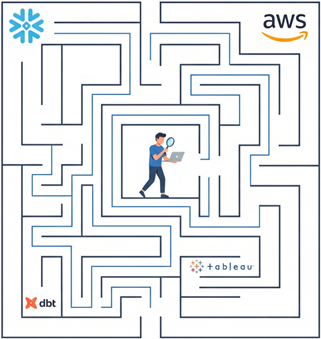
Au début, aucun souci, tout fonctionne bien. Ensuite, la plateforme scale, et les problèmes apparaissent par la même occasion. La moindre gestion de droit devient une lourde tâche, et résoudre une erreur devient un grand jeu de piste. On se retrouve perdu dans un labyrinthe d’orchestrateurs, où rien n’est mauvais, mais l’ensemble n’est pas cohérent.
Ismail a donné l’exemple suivant : un dashboard remonte vide, mais aucune erreur n'apparaît ni sur Snowflake, ni sur Tableau, ni sur AWS. Le problème est finalement localisé sur Control M, mais 5 heures plus tard.
À ce chaos technique s'ajoutent des problèmes humains : les nouveaux arrivants sur la plateforme sont perdus, la documentation ne suit pas, le code est dupliqué par peur de casser l'existant, et le temps perdu explose.
L'intégration d'Airflow a servi à tout recentrer. Plus qu'un simple outil, il est devenu un facilitateur de projet. Avec une vue claire des dépendances et des logs centralisés, le diagnostic est passé de 5 heures à 5 minutes, avec une relance des jobs en un seul clic.
Airflow : Les bonnes pratiques pour l'industrialisation
Avec plus de 200 DAGs aujourd'hui en production, l’équipe d’Ismail MEZZOUR ne s'est pas arrêtée au simple déploiement d'Airflow. Ils ont mis en place un processus rigoureux pour garantir que les erreurs du passé ne se reproduisent pas :
1. Templates et automatisation : Utilisation d'Astronomer Cosmos, extension servant à exécuter du code dbt directement dans Airflow, pour générer dynamiquement les DAGs, permettant aux équipes de se concentrer uniquement sur leur code SQL/dbt.
2. Standardisation : Création d'opérateurs testés, documentés et versionnés. L'objectif : ne plus réinventer la roue à chaque pipeline.
3. Rigueur des environnements : Un cycle de vie strict imposant des tests en environnement personnel, puis un passage en Dev (où les pipelines sont observés sur plusieurs jours), avant d'atteindre la Prod.
4. Gouvernance et observabilité : Mise en place de dashboards de monitoring, conventions de nommage strictes, tagging des DAGs, ownership maîtrisé, et intégration des métriques dans la CI/CD.
Ce retour d’expérience illustre une réalité incontournable : déployer un outil comme Airflow ne suffit pas à lui seul. C’est l’association de cette technologie avec une gouvernance stricte, des processus et une vraie culture de l’observabilité qui a permis à l'équipe d’Ismail de transformer un labyrinthe technique périlleux en une véritable Data Platform fiable et évolutive.
Que faut-il retenir de ce meetup ?
Pour proposer une orchestration plus fine et plus performante, la version 3.2 d’Airflow ajoute une intégration native des Partition Keys pour faciliter le passage de contexte entre les DAGs, un nouveau décorateur Async @task pour paralléliser l'exécution de micro-tâches concurrentes, des Deadline Alerts pour améliorer la surveillance des performances et un enrichissement de l’interface utilisateur avec un retour de la vue Gantt, des filtres avancés, l’édition manuelle du Data interval et une personnalisation CSS. Tous les ajouts de cette release participent à consolider et moderniser grandement l’outil.
Au-delà de la présentation des apports techniques de la version 3.2, ce meetup parisien résume parfaitement ce qui fait aujourd'hui le succès d'Apache Airflow. D'un côté, une communauté et des acteurs clés comme Astronomer qui poussent l'outil toujours plus loin techniquement, en apportant des solutions élégantes à des problèmes complexes. De l'autre, des entreprises sur le terrain, qui démontrent par la pratique que Airflow est devenu un standard de l’orchestration dans une Data Platform moderne.
Pour rencontrer la communauté Airflow, un autre meetup verra le jour le 19 mai 2026 à Bordeaux, fruit de la collaboration entre Astronomer et Ippon Technologies.
Pour plus d’informations sur les nouveautés d’Airflow 3.2, vous pouvez consulter la release note officielle, ou cet article du blog d’Astronomer
Apache Airflow 3.2 official release note
Blog Astronomer : Introducing Apache Airflow 3.2
Si l'architecture présentée dans le REX vous intrigue, Ismail MEZZOUR a détaillé son approche dans les deux articles suivants :
Deploying Airflow at ACCOR for 80+ Data Engineers & Scientists — our lessons learned with Astronomer
The dbt + Airflow Effect: Enhanced Data Deployments at Accor
