

L’IA dans le sport, tout le monde en parle. Le player tracking en NBA, les analyses xG en football, les capteurs GPS dans les maillots… Mais, quand on creuse un peu, on se rend compte que certains sports restent les grands oubliés de cette révolution. Le rugby en fait partie.
Je me suis confronté à ce constat en travaillant sur un projet de vision par ordinateur appliqué au rugby. L’objectif : partir d’une vidéo de match brute et en extraire automatiquement des données exploitables pour les entraîneurs — détection des joueurs, identification individuelle, reconnaissance des actions, génération d’un rapport stratégique.
Dans cet article, je partage les choix techniques, les pièges rencontrés et les leçons apprises. L’idée n’est pas de présenter une solution parfaite, mais un retour d’expérience honnête sur ce que signifie réellement construire un pipeline de computer vision de bout en bout.
Avant de plonger dans le code, un peu de recul sur l’architecture. J’ai découpé la solution en cinq modules indépendants qui s’enchaînent séquentiellement sur chaque frame de la vidéo : détection des joueurs et du ballon (YOLOv11), classification des équipes par couleur de maillot (K-means), identification individuelle (DeepFace + numéros de maillot), détection des actions de jeu (YOLO fine-tuné + PySlowFast), et enfin extraction de statistiques avec génération d’un rapport via un LLM.

Ce découpage n’est pas un hasard. Il permet de faire évoluer chaque brique indépendamment, de tester des alternatives sans tout casser, et de livrer de la valeur incrémentalement. Bref, du Software Craftsmanship appliqué au machine learning.
Détection des joueurs : YOLO, pragmatisme et fausses bonnes idées
Le parcours de YOLOv5 à YOLOv11
La détection est le socle de tout le pipeline. Si elle est mauvaise, tout le reste s’effondre. J’ai naturellement commencé par la famille YOLO (You Only Look Once), connue pour son excellent compromis vitesse/précision en détection d’objets.
Mon parcours a été tout sauf linéaire. J’ai successivement testé YOLOv5, YOLOv8, puis YOLOv11. Entre-temps, sur les conseils de mon encadrant, j’ai tenté Mask R-CNN via Detectron2 (Meta). Ce dernier, théoriquement plus précis pour la segmentation d’instances, s’est révélé être un cauchemar d’intégration : problèmes de compatibilité TensorFlow/Keras sur Apple Silicon, dépendances obsolètes, code plus maintenu… Deux mois de travail pour zéro résultat.
La leçon : ne tombez pas dans le piège du modèle « théoriquement meilleur ». Un modèle bien intégré, maintenu et documenté bat toujours un modèle plus précis mais inutilisable en pratique.
Transfer learning vs fine-tuning : le choix du pragmatisme
J’ai d’abord tenté un fine-tuning de YOLOv11-large sur 1 800 images annotées spécifiques au rugby (100 epochs). Les résultats étaient corrects mais insuffisants — les contraintes GPU de Google Colab gratuit limitaient fortement la qualité de l’entraînement.
Finalement, j’ai opté pour YOLOv11-xl pré-entraîné sur le dataset COCO (330 000+ images, 80 catégories), en filtrant les classes person et sports ball. Les résultats se sont révélés nettement supérieurs. Parfois, le meilleur modèle est celui qu’on n’a pas besoin d’entraîner.
Détection et filtrage avec Ultralytics
from ultralytics import YOLO
model = YOLO('yolo11x.pt') # Pré-entraîné COCO
PLAYER_CLASS, BALL_CLASS = 0, 32
def detect_players_and_ball(frame, conf=0.5):
results = model(frame, conf=conf, verbose=False)
players, ball = [], None
for box in results[0].boxes:
cls = int(box.cls[0])
coords = box.xyxy[0].cpu().numpy()
if cls == PLAYER_CLASS:
players.append({'bbox': coords, 'conf': float(box.conf[0])})
elif cls == BALL_CLASS:
ball = {'bbox': coords, 'conf': float(box.conf[0])}
return players, ball
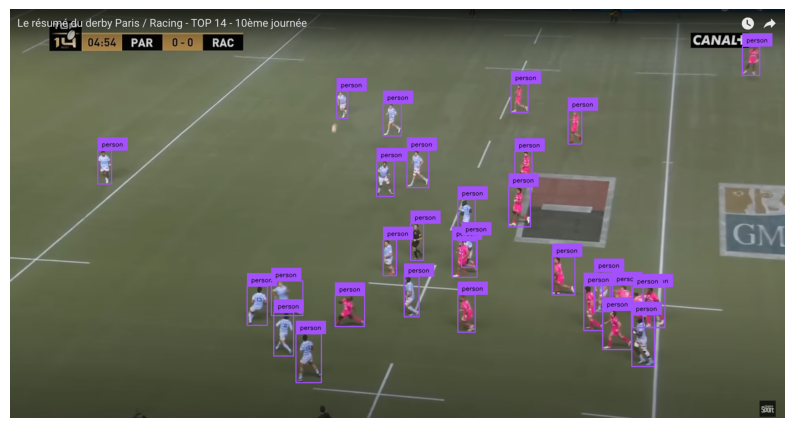
Classification des équipes par K-means
Une fois les joueurs détectés, il faut différencier les deux équipes et les arbitres. Plutôt que d’entraîner un classifieur supervisé, j’ai opté pour une approche non supervisée basée sur le clustering K-means des couleurs dominantes dans chaque bounding box. L’astuce : exclure les coins de la bbox (généralement du gazon) pour ne garder que la zone du maillot, puis appliquer un premier K-means (k=2) pour séparer maillot/fond, et un second K-means global (k=3) pour regrouper tous les joueurs en trois catégories (équipe 1, équipe 2 et arbitres).
Après quelques ajustements sur la zone d’intérêt dans la bounding box, les résultats sont devenus fiables même en conditions de match réelles.
Extraction de la couleur dominante du maillot
import numpy as np
from sklearn.cluster import KMeans
def get_jersey_color(frame, bbox):
x1, y1, x2, y2 = map(int, bbox)
roi = frame[y1:y2, x1:x2]
h, w = roi.shape[:2]
center = roi[h//4:3*h//4, w//4:3*w//4] # Zone centrale uniquement
pixels = center.reshape(-1, 3)
km = KMeans(n_clusters=2, n_init=10, random_state=42).fit(pixels)
labels, counts = np.unique(km.labels_, return_counts=True)
return km.cluster_centers_[labels[np.argmax(counts)]].astype(int)
Identification des joueurs : visage ou numéro, selon l’angle
Détecter qu’un joueur est présent, c’est bien. Savoir qui il est, c’est ce qui rend les statistiques exploitables. J’ai adopté une stratégie duale : reconnaissance faciale quand le visage est visible, détection du numéro de maillot quand le joueur est de dos.
DeepFace et FaceNet512
La reconnaissance faciale utilise la bibliothèque DeepFace avec le modèle FaceNet512 (précision mesurée : 98,4 %). Le processus fonctionne en deux temps : d’abord détecter un visage dans la bounding box du joueur, puis comparer ce visage à une base de données de 600+ joueurs constituée par scraping. Une fois identifié, le joueur est tracké et n’a plus besoin d’être réidentifié à chaque frame — ce qui évite les appels coûteux à DeepFace.
Identification avec DeepFace
from deepface import DeepFace
def identify_player_face(face_crop, db_path):
try:
results = DeepFace.find(
img_path=face_crop, db_path=db_path,
model_name='Facenet512',
enforce_detection=False, silent=True
)
if len(results) > 0 and len(results[0]) > 0:
best = results[0].iloc[0]
return {'identity': best['identity'],
'distance': best['distance']}
except Exception:
pass
return None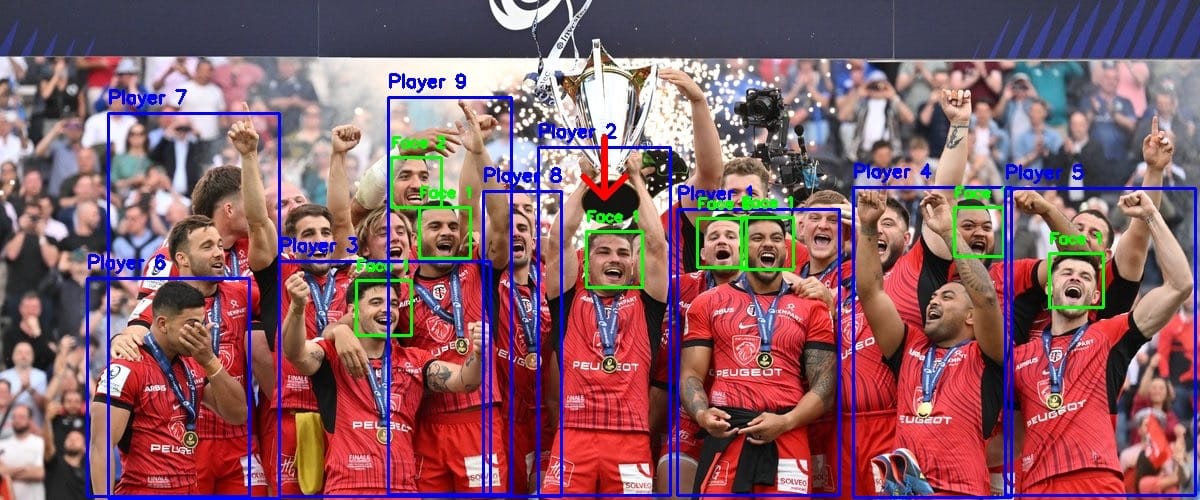
Quand l’OCR échoue : pivoter vers YOLO pour les numéros
Pour les joueurs de dos, mon premier réflexe a été l’OCR classique (PyTesseract). Résultat : un échec total. L’OCR est conçu pour du texte sur fond uniforme — face aux textures de maillots, aux plis et aux mouvements, il est complètement dépassé.
J’ai donc pivoté vers un modèle YOLO fine-tuné sur la détection de chiffres, entraîné via Roboflow sur des datasets d’autres sports (volley, handball) faute de données rugby annotées. Les résultats sont très encourageants : mAP 98,4 %, Precision 95,9 %, Recall 96,9 %. Roboflow s’est révélé un excellent accélérateur quand on manque de GPU — annotation, augmentation et entraînement directement dans le cloud.
Le pipeline intégré frame par frame
L’intégration de tous ces modules en un pipeline cohérent a été l’étape la plus délicate. Le processus suit un algorigramme de décision précis : pour chaque joueur détecté, on vérifie d’abord s’il est déjà identifié (si oui, on skip). Sinon, on cherche un visage. Si un visage est trouvé, on lance DeepFace. Sinon, on tente la détection du numéro. Ce design évite les appels répétés à DeepFace (très coûteux en temps de calcul).
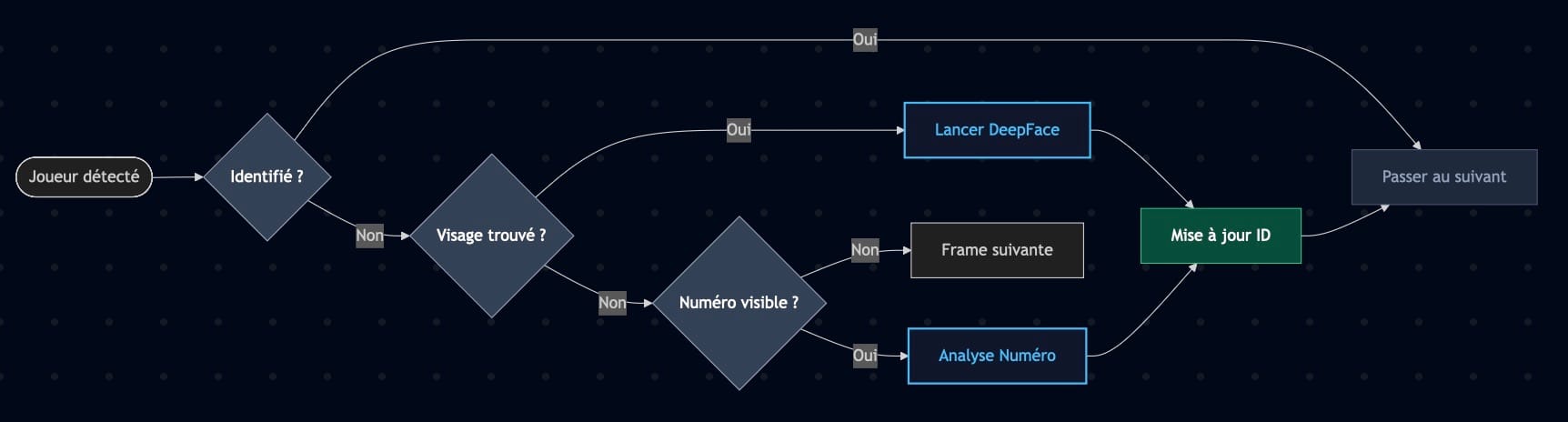
Pipeline principal
def process_frame(frame, tracker, player_db):
players, ball = detect_players_and_ball(frame)
for player in players:
bbox = player['bbox']
track_id = tracker.update(bbox)
if tracker.is_identified(track_id):
continue # Déjà connu, pas besoin de réidentifier
face = detect_face_in_bbox(frame, bbox)
if face is not None:
identity = identify_player_face(face, player_db)
if identity:
tracker.assign_identity(track_id, identity)
else:
number = detect_jersey_number(frame, bbox)
if number:
team = classify_team(frame, bbox)
identity = lookup_by_number(number, team)
if identity:
tracker.assign_identity(track_id, identity)
return players, ball
Reconnaissance des actions : le vrai défi
Toutes les actions de rugby ne se valent pas en termes de complexité visuelle. J’ai identifié deux catégories fondamentalement différentes.
Les actions « simples » (mêlées, touches) ont une structure visuelle constante : un regroupement de joueurs dans une formation spécifique. Un YOLO fine-tuné peut les reconnaître avec d’excellents résultats — mAP de 99,5 % pour les mêlées, 99,6 % pour les touches.
Les actions « complexes » (plaquages, passes, essais) sont intrinsèquement variables. Un plaquage peut impliquer un ou plusieurs défenseurs, s’effectuer à différentes hauteurs, avec des chutes très différentes. Un modèle basé sur des images fixes est démuni face à cette variabilité.
Pour ces actions dynamiques, la clé est d’analyser des séquences vidéo, pas des images isolées. J’ai exploré PySlowFast (Meta Research), un framework qui exploite deux flux temporels — un rapide pour les mouvements instantanés, un lent pour les évolutions progressives. L’approche est prometteuse mais se heurte à un obstacle de taille : elle nécessite un dataset massivement annoté, ce qui est un travail colossal que nous avons dû mettre en pause.
Des pixels aux statistiques : rendre le tout concret
C’est l’étape qui rend le projet utile pour l’entraîneur. À partir des positions des joueurs et du ballon sur chaque frame, on calcule la possession de balle (quel joueur est le plus proche du ballon, avec une règle de stabilité pour éviter les faux positifs), les passes (changement de porteur de balle avec continuité), et on identifie les joueurs clés par croisement de ces données.
Extraction de statistiques par frame
class MatchStatistics:
def __init__(self):
self.ball_possession = {} # {player_id: frame_count}
self.passes = []
self.current_holder = None
self.stability_counter = 0
def update(self, players, ball):
if ball is None: return
ball_center = get_center(ball['bbox'])
closest = min(players,
key=lambda p: distance(get_center(p['bbox']), ball_center),
default=None)
if closest and distance(get_center(closest['bbox']),
ball_center) < THRESHOLD:
pid = closest.get('track_id')
self.stability_counter += 1
if self.stability_counter >= 5: # Règle de stabilité
if self.current_holder and pid != self.current_holder:
self.passes.append((self.current_holder, pid))
self.current_holder = pid
self.ball_possession[pid] = \
self.ball_possession.get(pid, 0) + 1
else:
self.stability_counter = 0
Plutôt que de livrer des tableaux de chiffres bruts, j’ai intégré un LLM qui transforme ces statistiques en un rapport structuré : durée de la partie, joueurs identifiés, analyse des passes, et surtout des recommandations tactiques. Le coach reçoit un document concret, pas une pile de data.

Ce que la théorie ne dit pas : les leçons du terrain
Sur le matériel. Google Colab gratuit comme seul GPU, c’est insuffisant pour de l’entraînement sérieux. En production, l’accès à des GPU dédiés (SageMaker, Google Cloud AI, Azure ML) est quasi indispensable. Roboflow est un bon paliatif pour du prototypage.
Sur les datasets. Le rugby est le parent pauvre de la computer vision sportive. Contrairement au football ou au basket, il n’existe quasiment pas de datasets publics. J’ai dû composer avec des datasets généralistes (COCO), cross-sport (volley, handball) ou les construire moi-même. L’annotation manuelle reste un goulot d’étranglement majeur.
Sur la maintenabilité. Ma tentative avec Mask R-CNN est un cas d’école : modèle non maintenu, dépendances cassées, deux mois perdus. La maintenabilité d’un outil compte autant que ses performances. C’est un principe fondamental du craft, et il s’applique aussi au ML.
Et demain ?
Plusieurs pistes me semblent particulièrement prometteuses. D’abord, le déploiement sur des dispositifs edge (type NVIDIA Jetson) : une caméra bord de terrain qui analyse le match en direct, avec des modèles optimisés (quantification, export TensorRT). Ensuite, l’analyse prédictive en combinant CNN (analyse spatiale) et RNN/LSTM (dimension temporelle) pour identifier des faiblesses défensives répétitives et générer des stratégies adaptées à chaque adversaire. Enfin, le coaching personnalisé par joueur en croisant les statistiques individuelles sur plusieurs matchs.
En résumé
Ce projet m’a confronté à une réalité clé du craft appliqué au ML : la valeur ne réside pas dans la complexité du modèle, mais dans la pertinence de la solution. Un YOLOv11 pré-entraîné sur COCO, couplé à un clustering K-means et un pipeline bien pensé, délivre aujourd’hui plus de valeur qu’un Mask R-CNN théoriquement supérieur mais inutilisable.
Le rugby, sport de stratégie et d’intelligence collective, mérite des outils à la hauteur de sa complexité. La computer vision n’en est qu’à ses débuts dans ce domaine — et c’est ce qui rend l’aventure passionnante.
Pour aller plus loin n'hésitez pas à lire mon article : “L'IA débarque sur le banc de touche : comment la tech transforme le rugby” qui explique comment faire adopter une solution IA à des coachs, une équipe et un projet sportif.
Cet article vous a plu ? N’hésitez pas à nous contacter pour échanger sur vos projets de computer vision ou de data engineering.
