

L’année 2020 est déjà bien entamée et la liste des bonnes résolutions est peut-être déjà loin derrière vous. Si par chance une de ces résolutions était de mettre un pied dans le monde moderne de la Data, cet article peut vous permettre de vous rattraper ou en tout cas de vous donner quelques pistes. En ce qui me concerne, j’ai développé au cours de l’année 2019 un intérêt grandissant pour le domaine de la Data. Ce terme est à prendre au sens large, avec un grand D, car j’entends par là les technologies qui y sont liées mais aussi tous les concepts qui gravitent autour (gouvernance des données, protection de ces données, green data, ...).
Mon objectif en 2020 est donc de continuer dans cette direction et je me suis dit qu’il serait intéressant de rappeler dans un article plusieurs éléments qui ont été abordés récemment au sein de la communauté Ippon Data, et qui pour moi méritent d’être connus par un data-néophyte. Qu’il s’agisse de releases récentes, de technologies qui ont pris de l’importance ou encore de concepts qui émergent, le but de cet article est de faire un petit résumé - non exhaustif - de tout ça. Dès que possible, je complèterai mon propos en redirigeant le lecteur curieux vers des articles plus détaillés parus sur ce blog Ippon.
Les technologies
Spark 3.0

Pour commencer, un classique qu’il n’est plus nécessaire de présenter : Spark, le framework open-source permettant de faire des traitements sur de larges volumes de données de manière distribuée. Un élément important dans le couteau-suisse d’un data engineer.
La preview de la version 3.0 de Spark est sortie le 31 octobre 2019. Dans cette version majeure, on retrouve des nouveautés comme par exemple les langages supportés (Python 3, Java 11, Scala 2.12, dépréciation de Python 2.x), l’ajout de modules (SparkGraph) ou la lecture des fichiers au format binaire. Elle propose aussi une amélioration des performances (Dynamic Partition Pruning, ...) et une meilleure intégration de plusieurs technologies de l’écosystème (Delta Lake, Kubernetes, Apache Arrow, …). C’est assurément une release importante qu’il va falloir suivre en 2020.
Pour plus de détails sur les nouveautés du framework, voici un lien vers l’excellent article de Lucas Landry : Spark 3.0 : Évolution ou révolution ?
Matillion et la méthode ELT

Là on arrive sur un outil moins connu du grand public que Spark, mais dont j’ai énormément entendu parlé en 2019 au sein de la communauté Data d’Ippon : Matillion. Avec notamment l’article de Jean-Baptiste Leblanc qui m’a vraiment mis le pied à l’étrier : Introduction à l'ELT et à la solution Matillion.
Dans cet article, il commence par nous expliquer la nuance entre le paradigme classique ETL (Extract Transform Load) et la “nouvelle génération” ELT (Extract Load Transform). Pour résumer rapidement, l’ELT permet un gain de temps dans les traitements en limitant les transferts de données et en se basant directement sur la puissance de calcul des data warehouses. Ensuite, il présente Matillion et notamment la simplicité de son interface qui est semblable à des outils plus connus comme Talend. Matillion s’intègre aujourd’hui avec les 3 cloud data warehouses suivants : Amazon Redshift, Google BigQuery et Snowflake.
La release 1.42 de Matillion ETL est sortie en décembre dernier. Le même mois, un autre produit a été présenté : Matillion Data Loader. Celui-ci se concentre uniquement sur les aspects Extract et Load ce qui en fait un outil simple et destiné à un public plus large. Enfin, il profite d’un pricing très avantageux puisqu’il est totalement gratuit. Tout cela est détaillé dans l’article très complet de Marin Six : Matillion Data Loader : gadget ou réelle utilité ?
On a hâte de suivre l’évolution de ces produits en 2020.
Snowflake

J’ai évoqué un peu plus haut Snowflake en tant que cloud data warehouse s’interfaçant avec Matillion. Pour rappel, un data warehouse est comparable à une base de données relationnelle classique, stockant des données de manière structurée mais en favorisant les analyses sur celles-ci (OLAP) et non les opérations de lecture/écriture (OLTP). À ne pas confondre non plus avec un data lake qui lui va stocker les données de manière brute, non structurées/agrégées.
J’estime que Snowflake a sa place dans cet article car cette solution a aussi fait l’objet de nombreuses discussions au sein de la communauté Data Ippon en 2019/2020. Snowflake a été mis en place avec succès chez plusieurs de nos clients et suscite de l’intérêt chez une bonne partie de nos consultants. Ses récentes levées de fond prouvent aussi que la licorne franco-américaine a un bel avenir devant elle.
Pour en témoigner, voici une série d’articles publiés sur notre blog cette année :
- Une introduction à Snowflake par Ramya Shetty et pour aller plus loin, une présentation “in-depth” par Pooja Krishnan (en anglais)
- Dans les ressources en français, on retrouve un excellent comparatif de Redshift vs Snowflake par Christophe Parageaud. Je recommande particulièrement cet article pour un néophyte en Data car il rappelle clairement les différentes notions que j’ai citées précédemment (data warehouse, data lake, avantages du Cloud, etc.)
- Enfin Arnaud Col a écrit un article concernant la gouvernance avec Snowflake. L’article est bourré de bonnes pratiques et de recommandations pour la mise en place de la solution. Un must-read!
Kafka & ksqlDB

Ces dernières années, Kafka est devenu un élément clé dans la construction d’architectures modernes. Le broker de messages performant et résilient profite désormais d’un écosystème riche (Kafka Streams, Kafka Connect, …) dont KSQL fait partie depuis 2017. Il est depuis possible de requêter un stream de données en SQL sans passer par des langages de programmation comme Python ou Java.
En novembre 2019, Confluent a annoncé la sortie d’une nouvelle version de KSQL, comprenant deux nouvelles fonctionnalités majeures : la possibilité de faire des pull queries et l’intégration des connecteurs Kafka dans KSQL. Au final, on se retrouve avec une technologie capable de stocker, processer et requêter des flux d’événements en SQL et c’est ce qui a conduit Confluent à renommer leur produit en ksqlDB. Attention toutefois : ksqlDB reste un outil de requêtage et n’a pas pour vocation de remplacer une base de données classique.
L’article de Rémy Olivet “ksqlDB change la donne” détaille parfaitement les différences entre l’ancien KSQL et sa nouvelle version ksqlDB. Dans les nouveautés à venir, Confluent a déjà annoncé le support d’une plus grande variété d’expressions (“range queries” et “complex grouping” par exemple) ainsi que des optimisations dans le traitement des flux. La version 0.8.0 est attendue dans les semaines à venir.
Les concepts
Après une première partie centrée sur des outils en vogue, je vais aborder dans cette seconde partie des concepts qui ont émergé récemment et qui vont selon moi continuer à occuper une place importante dans les discussions autour de la Data.
Data lakehouse
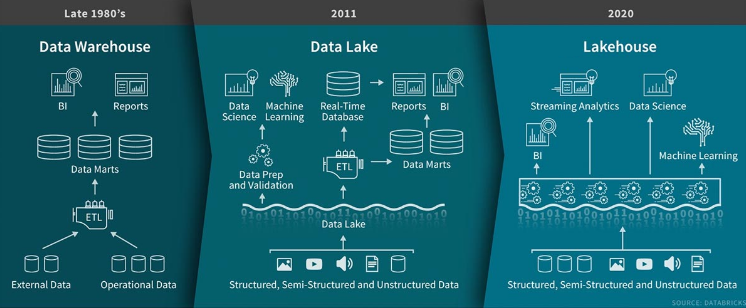
Ce terme ne désigne pas un produit en particulier mais plutôt un paradigme qui profite d’une certaine hype en ce début d’année 2020. Popularisé fin janvier par un article de Databricks, il correspond à la contraction des termes “Data Lake” et “Data Warehouse”. En pratique, il s’agit d’unifier le meilleur des data lakes et data warehouses au sein d’un même système, afin d’en simplifier l’architecture et de réduire les coûts. Cela est rendu possible par l’utilisation de solutions de stockage à faible coût (AWS S3, Azure Blob Storage, …) couplées à des outils comme Delta Lake, Apache Drill, Google Bigquery ou Amazon Athena.
Toutefois, comme le rappelle Simon Whiteley, il est peu probable qu’une solution unifiée puisse répondre à tous les besoins complexes. Pour résoudre des problèmes simples, un data lakehouse pourra être une solution à faible coût, mais d’autres problèmes spécifiques devront toujours être adressés par une architecture “classique” découplant data warehouse et data lake.
Au sein de la communauté Data Ippon, nous avons déjà initié le débat sur ce nouveau terme, qui mériterait à lui seul un article dédié. En attendant, il est possible d’écouter l’épisode 94 du Big Data Hebdo qui aborde longuement ce sujet. Les discussions autour de des lakehouses se poursuivront sans aucun doute tout au long de l’année à venir.
DataOps
Peut-être encore plus émergeant que le terme précédent, le mouvement DataOps s’inspire fortement de DevOps en l'appliquant au monde de la Data. Beaucoup de choses restent encore à définir, mais on peut déjà imaginer que le DataOps permettra de favoriser la collaboration entre les différents acteurs d’un projet Data (data scientists, data engineers, data analysts, ...) dans le développement et l’exploitation des applications. Un manifesto existe (mais peu reconnu il faut l’avouer) et définit quelques-unes de ces guidelines permettant la bonne réalisation des projets Data.
Reste à voir comment en pratique le mouvement DataOps réussira à casser les silos entre développement et exploitation, comme a pu faire DevOps il y a quelques années dans le monde applications “classiques”.
Je compte personnellement rester à l’affût de la littérature qui sortira à ce sujet, tout en gardant à l’esprit que pour l’instant, il s’agit plus d’un buzzword que de réels outils.
Green Data / Green IT
J’ai choisi de regrouper ces deux termes ensemble car pour moi les principes “Green” applicables à la Data s’inscrivent plus largement dans une démarche globale au niveau IT. Ces mesures peuvent intervenir à différentes échelles : au niveau des choix techniques faits lors de la conception d’un produit jusqu’à l’organisation physique même d’un SI ou d’une entreprise. Cela est très bien expliqué dans l’article de Nicolas Martin : Concilier architecture, data et écologie, c'est possible ? Une introduction au green IT.
L’article est illustré de nombreux exemples permettant de rendre le numérique plus responsable, à toutes les échelles. On comprend bien que ces enjeux vont devenir de plus en plus conséquents au fil des années et qu’il y a de réels bénéfices à en tirer (réduction des coûts, optimisation du stockage et des temps de traitement, ...).
Arnaud Col a quant à lui détaillé certains principes plus spécifiques au monde de la Data dans sa présentation donnée à Bordeaux : Green Data is the New Big Data. Son expérience associée à quelques règles de bon sens donnent des architectures inspirantes lorsqu’on souhaite découvrir la Data tout en respectant certains principes responsables.
Conclusion
J’espère que cet article aura été une bonne base pour aborder une petite partie du monde actuel de la Data. Il est évidemment impossible de passer en revue chaque nouveauté et chaque concept dans cet écosystème en constante mutation. Néanmoins j’espère avoir compilé quelques pistes qui me paraissent prometteuses, qui auront fait débat au sein de notre communauté Data et sur lesquelles nous allons continuer de capitaliser durant l’année à venir.
Les choses ne s’arrêtent pas là puisqu’il existe d’autres notions à explorer et qui devraient exploser en 2020 et après : par exemple l’application de l’IA à l’analyse des données (“augmented analytics”, “conversational analytics”, etc.) ou encore l’émergence de la Continuous Intelligence (CI) grâce à la démocratisation du cloud et de l’IoT. Et chacun de ces concepts apportera son lot d’outils et de technologies que nous attendons avec impatience. Stay tuned!
