

Lorsqu'on apprend les paradigmes Objets, on nous enseigne que les Objets que l'on code représentent des choses du monde réel. Les attributs en sont l'état et les méthodes les actions.
Alors pourquoi trouvons-nous BEAUCOUP plus de Data classes (classes avec uniquement des attributs et des getters et setters) dans nos solutions que d'Objets effectuant des traitements métier ? Dans certaines équipes, faire des traitements métier dans des Objets représentant le métier est même interdit parce que : "les traitements doivent être faits dans des services !".
Depuis quelques temps j'ai pu utiliser vraiment des Objets dans mon quotidien de développeur : voici mes retours !
Du coup, les Objets c'est bien ?
Pour dire vrai, ça dépend : lorsqu'on veut utiliser les fonctionnalités d'un framework manipulant des données et ne sachant travailler qu'avec des "Objets" exposant tous leurs attributs il faut admettre que ce n'est pas idéal...
Faire des Objets sera bien plus pertinent si on veut :
- avoir un code qui représente clairement le métier pour lequel il a été écrit,
- assurer la cohérence des états de nos objets métier,
- faire des traitements métier,
- assurer la pérennité d'une solution en limitant les effets de bord, en facilitant la compréhension, en autorisant les refactorings et en permettant des évolutions sans chute de vélocité.
Pour bénéficier de ces avantages il faut :
- Assurer la cohérence de nos objets ;
- Faire des méthodes effectuant des traitements métier ;
- Passer d'Objets adaptés à un besoin technique donné aux Objets représentant notre métier ;
- Designer notre code.
Assurer la cohérence de nos objets
Coder des Objets qui peuvent être dans des états qui n'existent pas est une très mauvaise idée ! Nos Objets ne doivent pouvoir être que dans des états qu'ils savent correctement traiter, et ça commence dès la construction.
Faire des types
La première manière d'éviter des situations que l'on ne saura pas traiter est de faire des types. Si on utilise essentiellement des primitives alors on doit accepter toutes les valeurs possibles de ces primitives : un dictionnaire Klingon est une valeur tout à fait acceptable pour une String.
En faisant des types on va améliorer la sémantique, s'assurer que l'on reçoit le bon type de donnée mais on facilitera aussi l'utilisation de nos APIs (il n'est jamais évident d'invoquer une méthode qui prend 3 Booleans et 2 Strings...).
En fait vouloir faire ces traitements en se basant essentiellement sur des types primitifs est un anti-pattern très répandu (et extrêmement nuisible) : primitive obsession. Faire apparaître des types est un refactoring très simple à faire et qui vous apportera rapidement beaucoup.
Vous pouvez essayer de faire un Objet Username qui contiendra l'identifiant de votre utilisateur connecté et utiliser cet objet plutôt qu'une simple String. De cette manière, vous pourrez simplement vous assurer de ne pas logger le vrai identifiant de votre utilisateur mais une version obfusquée en changeant l'implémentation de toString() (vous vous faciliterez ainsi le droit à l'oubli en n’ayant pas à parser vos logs).
Vérifier les données en entrée
Un autre point essentiel pour assurer la cohérence est de vérifier les données en entrée de nos Objets (que ce soit lors de la construction ou les paramètres de methods).
Je ne peux que vous conseiller de vous fabriquer une petite API d'assertions (qui sera plus ou moins complexe à faire en fonction du langage et de vos besoins). Je vous conseille aussi de créer une API fluent qui facilitera les multiples contrôles sur un même champ.
Par exemple on peut imaginer faire ces contrôles dans un constructeur :
Assert.notNull("id", id);
Assert.notBlank("key", key);
Assert.field("name", name).notBlank().maxLength(100);
Pour ce faire on aurait la class Assert suivante :
public final class Assert {
private Assert() {}
public static void notNull(String fieldName, Object input) {
if (input == null) {
throw MissingMandatoryValueException.forNullValue(fieldName);
}
}
public static void notBlank(String fieldName, String input) {
if (input == null) {
throw MissingMandatoryValueException.forNullValue(fieldName);
}
if (input.isBlank()) {
throw MissingMandatoryValueException.forBlankValue(fieldName);
}
}
public static StringAsserter field(String fieldName, String value) {
return new StringAsserter(fieldName, value);
}
public static class StringAsserter {
private final String fieldName;
private final String value;
private StringAsserter(String fieldName, String value) {
this.fieldName = fieldName;
this.value = value;
}
public StringAsserter notBlank() {
Assert.notBlank(fieldName, value);
return this;
}
public StringAsserter maxLength(int maxLength) {
if (value != null && value.length() > maxLength) {
throw StringSizeExceededException
.builder()
.field(fieldName)
.currentLength(value.length())
.maxLength(maxLength).build();
}
return this;
}
}
}
Les exceptions pour cet exemple sont basées sur Problem (de Zalando) :
public class MissingMandatoryValueException extends AbstractThrowableProblem {
private MissingMandatoryValueException(String message) {
super(ErrorConstants.DEFAULT_TYPE, message, Status.INTERNAL_SERVER_ERROR);
}
public static MissingMandatoryValueException forNullValue(String fieldName) {
return new MissingMandatoryValueException(defaultMessage(fieldName) + " (null)");
}
public static MissingMandatoryValueException forEmptyValue(String fieldName) {
return new MissingMandatoryValueException(defaultMessage(fieldName) + " (empty)");
}
public static MissingMandatoryValueException forBlankValue(String fieldName) {
return new MissingMandatoryValueException(defaultMessage(fieldName) + " (blank)");
}
private static String defaultMessage(String fieldName) {
return "The field \"" + fieldName + "\" is mandatory and wasn't set";
}
}
public class StringSizeExceededException extends AbstractThrowableProblem {
private StringSizeExceededException(StringSizeExceededExceptionBuilder builder) {
super(ErrorConstants.DEFAULT_TYPE, builder.message(), Status.INTERNAL_SERVER_ERROR);
}
public static StringSizeExceededExceptionBuilder builder() {
return new StringSizeExceededExceptionBuilder();
}
static class StringSizeExceededExceptionBuilder {
private String field;
private int currentLength;
private int maxLength;
public StringSizeExceededExceptionBuilder field(String field) {
this.field = field;
return this;
}
public StringSizeExceededExceptionBuilder currentLength(int currentLength) {
this.currentLength = currentLength;
return this;
}
public StringSizeExceededExceptionBuilder maxLength(int maxLength) {
this.maxLength = maxLength;
return this;
}
private String message() {
return "Length of \"" + field + "\" must be under " + maxLength + " but was " + currentLength;
}
public StringSizeExceededException build() {
return new StringSizeExceededException(this);
}
}
}
Un autre intérêt de la class Assert ici est de normaliser les exceptions et leurs messages, on pourra ainsi simplement les adapter en fonction des besoins.
Vous l'avez certainement remarqué mais différents Design Patterns de construction (static factory et builder en l'occurrence) ont été utilisés dans les exemples précédents : c'est aussi un moyen très important d'assurer la cohérence en ne permettant la construction d'un objet que lorsque tous les éléments sont renseignés !
Un autre point essentiel : nos Objets ne renvoient pas de valeures null, on renverra des Collections vides ou des Optional vides pour les Objets qui peuvent être ne pas être renseignés !
Faire des objets immuables
Assurer la cohérence d'un objet est relativement simple si on sait que ces différents éléments ne peuvent pas changer. En revanche quand tous les objets changent, assurer la cohérence de chacun d'entre eux peut être très compliqué.
Pour éviter cette complexité le plus simple est encore de ne permettre les modifications que lorsque c'est nécessaire et de faire des objets immuables dans tous les autres cas.
Cependant, en Java, l'API Collection ne nous aide pas vraiment car elle ne présente pas d'interface permettant simplement la consultation des Collections. Nous sommes alors obligés de casser le Principe de Substitution de Liskov en utilisant Collections.unmodifiableXXX(...) (ce qui reste un moindre mal).
Dans tous les cas, faire des types immuables est souvent une très bonne solution pour éviter des effets de bord indésirables (il est par exemple peu probable que la mise à jour du Username d'un User n'ai pas d'autres impacts qu'un simple changement dans User).
Faire des traitements métier
Dès lors que nos Objets assurent leur cohérence, on peut commencer à faire des traitements métier et non pas uniquement de la manipulation de données !
Une des premières étapes essentielles pour faire des traitements métier est d'exposer des methods qui explicitent ce qui est fait, pas comment c'est fait. Dans cette optique on trouvera vraiment très peu de setters dans nos Objets métier : changer une valeur est rarement un traitement métier !
Exposer des opérations fonctionnelles et non pas techniques facilitera grandement :
- L'utilisation des API ;
- La compréhension du métier pour les nouveaux arrivants ;
- Le refactoring : on fait toujours la même opération mais d'une manière tout à fait différente (cela n'affecte pas les appelants) ;
- La réponse aux changements métier : comme on expose des opérations métier un petit changement métier se traduira dans la grande majorité des cas par un petit changement dans le code (et non pas une refonte de l'application).
Les traitements métier faits dans nos Objets ont très souvent besoin de déclencher des actions ailleurs dans notre produit. Par exemple, la validation d'un compte utilisateur va modifier l'Objet représentant cet utilisateur mais on peut vouloir lui envoyer un mail ou changer ses rôles dans le système de gestion de droits. Ces actions peuvent être vues comme des événements qui vont être envoyés pour être traités par des handlers dédiés. Cependant, se pose souvent la question de la propagation de ces événements, plusieurs stratégies sont envisageables :
- Injecter un Objet permettant de faire cette propagation lors de la construction de notre Objet métier. Dans la majorité des cas, cette stratégie n'est pas très bonne car on met un élément purement technique dans quelque chose représentant du métier. De plus, il est fort probable qu'on ne se serve de cet outil de broadcast que dans quelques traitements (compliquant alors la construction dans tous les cas là où il ne sera utile que dans des cas bien précis).
- On peut aussi injecter cet Objet permettant la propagation en paramètre des méthodes en ayant besoin (en vérifiant toujours sa présence). De cette manière c'est notre Objet métier qui va assurer la construction des événements et leur diffusion. C'est une stratégie tout à fait viable !
- On peut enfin renvoyer un événement comme résultat de notre traitement métier et laisser une couche d'orchestration (qui fera l'appel pour le traitement métier) faire la propagation de l'événement. Cette stratégie est aussi viable et permet de ne pas du tout ajouter de dépendance à des éléments techniques dans nos Objets métier.
Les événements dont il est question ici sont des objets métier comme les autres. Ils décrivent ce qui s'est passé. Ils sont forcément immuables (un événement est quelque chose qui s'est passé, il ne peut pas être modifié).
Passer d'une version à une autre
Maintenant que nos Objets métier assurent leur cohérence et font vraiment des traitements métier, nous avons développé la majorité de la valeur de notre solution. Cependant, on devra bien souvent transformer ces Objets pour les persister ou pour les exposer à l'extérieur.
Il existe plusieurs stratégies pour faire ces mappings. Après quelques années à tester différentes stratégies, ma favorite est maintenant de faire les conversions dans les objets dédiés à un usage particulier (par exemple une exposition REST ou une persistance en utilisant un ORM). Avec une class Branch dans mon code métier et sa version pour l'exposition RestBranch, j'aurai :
class RestBranch {
// Fields and constructor
static RestBranch from(Branch branch) {
// Build a RestBranch from a Branch
}
// Getters to expose my JSON model
Branch toDomain(...) { // Sometimes i need extra parameters to build my domain here
// Build a Branch from a RestBranch and extra parameters
}
}
Je n’ai jamais été convaincu par les différents frameworks de mapping automatique. Dans tous les cas, on teste ces mappings et je trouve qu'on passe plus de temps à comprendre pourquoi tel ou tel mapping ne se fait pas qu'à gagner du temps à ne pas écrire une ligne de code. Certains de ces Frameworks ne fonctionnent pas avec les visibilités package alors que c'est typiquement le besoin que j'ai sur ce type d'Objets qui sont souvent dans un package dédié à une feature et un usage donné.
Designer notre code
Tout ça n'a pas d'intérêt si on garde un design pauvre de notre code. Là aussi j'ai essayé plein de méthodes de design. Peu de temps après ma sortie d'école, je soutenais même qu'il ne fallait surtout pas se lancer dans l’écriture du code sans avoir pensé un design sur papier (ou tableau) !
J'ai maintenant une approche différente (même si je me remets au tableau de temps en temps). En fait, en faisant un design au tableau, on ne peut avoir qu'une vision d'ensemble, on va forcément oublier des choses qui seront nécessaires pour l'implémentation ou certains cas qu'on ne verra que pendant la réalisation.
Ma méthode de design favorite est actuellement le TDD : et oui, le TDD est avant tout une méthode de design et non pas une méthode de test ! Pour rappel, le TDD est très simple à définir, c'est un cycle en 3 étapes :
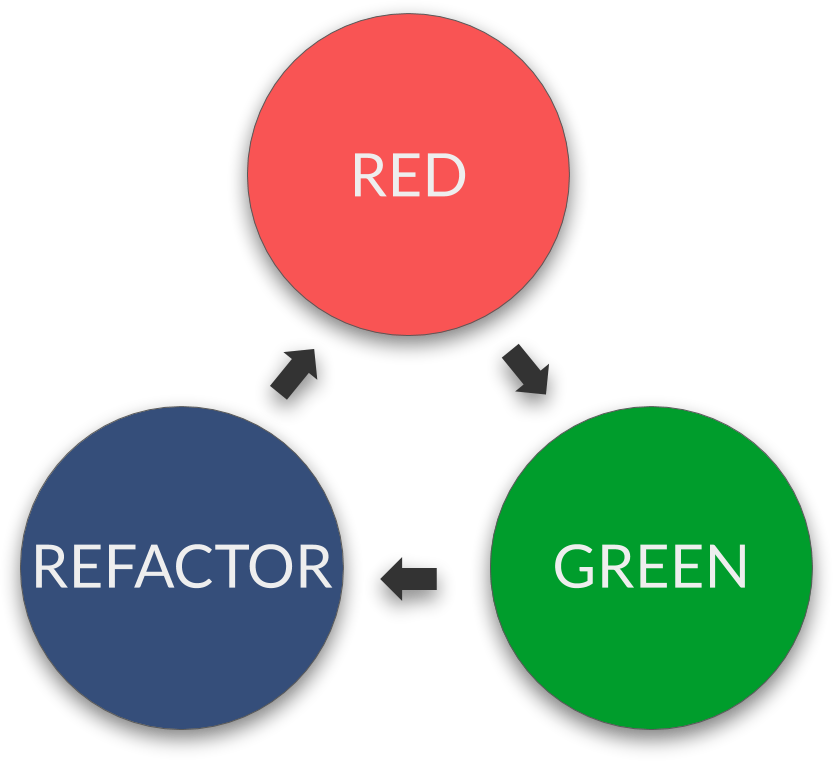
Pendant la phase RED, on écrit un premier test qui ne passe pas (si il ne compile pas il ne passe pas).
Pendant la phase GREEN, on écrit le code le plus direct permettant à notre test de passer (sans casser les tests précédents).
Pendant la phase REFACTOR, on travaille notre code pour qu'il soit plus élégant, qu'il exprime mieux le métier, qu'il apporte une meilleure réponse…
Ce cycle se répète toutes les quelques secondes ou minutes (on en fait plusieurs centaines dans une journée). Ces cycles permettent l'émergence du design. De cette manière, notre code sera bien meilleur qu'un code désigné au tableau puisqu'on :
- Prendra en compte tous les cas qu'ils soient métier ou technique ;
- Répondra clairement au besoin en étant capable d'invoquer simplement nos méthodes (on ne peut pas faire la phase RED sinon) ;
- N'aura pas de code superflus ou inutile : si on n’a pas de test RED, on n’écrit pas de nouveau code !
Cependant, même si cette manière de travailler se résume en quelques minutes sa maîtrise prendra beaucoup plus de temps.
Vivre dans un monde d'objets
Quand on commence à faire des Objets dans nos applications il est difficile de revenir en arrière tant les apports sont évidents au quotidien :
- vélocité,
- qualité,
- facilité d'évolutions,
- compréhension des traitements,
- ...
On ressent alors rapidement le besoin de mettre en place une Clean Architecture mais ça, c'est une autre histoire...
