

Cette douce matinée de novembre s’annonce comme un matin de Noël : la preview de Spark 3.0 est sortie ! Je me demandais justement quand Spark allait sortir des nouveautés qui révolutionneraient le monde de la Data ! Ni une ni deux, je m’empresse d’aller sur la page annonçant les nouveautés : https://spark.apache.org/news/spark-3.0.0-preview.html. Ça y est, je vois une liste peu facile à lire : des changements, accompagnés des liens Jira (me rappelant des souvenirs douloureux). Café, stand-up meeting, réunions et aucune envie de me plonger dans le Jira de Spark, je procrastine et j’abandonne …
Disclaimer : La version de Spark 3.0 dont cet article traite est une preview, donc pas stable et susceptible de changer.
Langages
Spark s’appuie désormais sur scala 2.12.x (enfin !). Java 8 (8u92+) et 11 peuvent être utilisés. Quand on connaît le rythme de releases de Java, ces nouvelles sont les bienvenues si on ne veut pas travailler avec une version obsolète. Cependant d’après l’issue Jira ayant pour but de tester Spark avec le JDK 11, le travail est toujours en cours. Python 2 est déprécié ainsi que les versions de Python 3 inférieures à la 3.6.
Dynamic Partition Pruning (DPP)
Outch, on arrive dans le vif du sujet : les performances de Spark. L’idée, comme beaucoup d’optimisations derrière Spark, est de lire le moins de données possible afin d’optimiser les traitements. Le DPP est très utile pour des jobs de BI.
Imaginons la requête suivante :
SELECT city.name, citizen.name
FROM city
JOIN citizen
ON city.id = citizen.city_id
WHERE city.pop > 1000
En BI classique, on dirait que city est la table de dimension et citizen la table de fait. Avec un Spark < 3, un filtre serait appliqué sur la table city puis le join des deux tables serait effectué.
Avec Spark 3, le filtre est appliqué sur city puis envoyé dynamiquement aux partitions de la table citizen et enfin le join est appliqué.
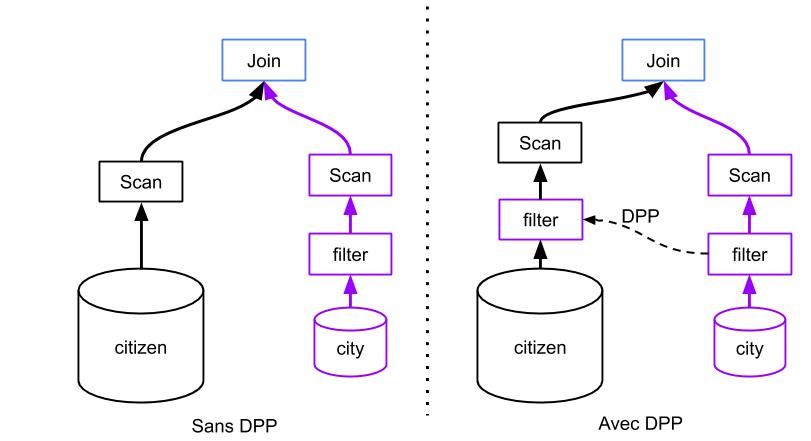
Il y a donc moins d’échanges de données et de traitements !
Attention, cette amélioration est uniquement valable dans le cas où la clé de jointure est la clé de partitionnement de la table de fait.

Exécution adaptative
Par défaut, Spark broadcastait sur les noeuds les Datasets inférieurs à 10MB (paramètre modifiable avec spark.sql.conf.autoBroadcastJoinThreshold). Pour effectuer ces broadcasts automatiquement, il se fiait aux statistiques présentes sur les sources utilisées. Seulement certaines sources avaient des statistiques fausses ou inexistantes, et donc le broadcast n’était pas prévu dans le plan d’exécution. Avec l’exécution adaptative, Spark se donne le droit de modifier son plan d’exécution au runtime en analysant ces datasets et en les broadcastant si possible.
Data Source V2
Ce type de Data Source est disponible depuis la version 2.3.0, donc pas si nouveau que ça mais le but est sa démocratisation en Spark 3.Voilà quelques point intéressants.
- Pluggable Data Catalog : En plus de lire des données directement, Spark peut désormais se référer au DataCatalog présent dans votre environnement.
- Le filtre pushdown et la gestion de partitionnement sont améliorés.
- La possibilité d’écrire les données de façon transactionnelle est ajoutée.
- Le streaming et le batch possèdent exactement la même API.
Pour plus d’informations sur la Data Source V2, je vous conseille ce talk (Spark Summit 2018) : Apache Spark Data Source V2.
Delta Lake

Disponible à partir de la 2.4.2, il ne faut pas attendre la version 3 pour commencer l’utilisation de Delta Lake. La mise en valeur de celui-ci est faite dans Spark 3. Ce sujet mériterait un article à lui seul. C’est une vraie amélioration rendant l’utilisation de Spark plus simple et donc plus abordable. En plus d’être open-source, Delta Lake a rejoint la fondation Linux.
Delta Lake permet de rendre un Data Lake requêtable de manière ACID. Il est donc désormais possible de travailler à plusieurs sur les mêmes données sans se soucier de la consistance et aussi d’upserter des données par exemple. Un journal de logs permet de tracer les données et de ne les modifier qu’une fois la transaction finie. Ainsi, on peut désormais alimenter le Data Lake en batch et en streaming sans avoir à maintenir une architecture lambda.
Bref, Delta Lake est grossièrement une couche d’abstraction qui permet à un Data Lake de ressembler à une base de données. La concurrence des Data Warehouses comme Snowflake oblige Spark, et donc Databricks, à faire évoluer le produit pour qu’il englobe plus de cas d’utilisation.
Pour plus de détails, un Webinar sur Delta Lake a été fait chez Ippon ici.
Koalas

Pandas c’est bien, Koalas c’est mieux. Koalas est une librairie Python imitant Pandas fonctionnant sur du PySpark, donc en ajoutant une couche distribuée. Ainsi Data Scientists et Data Engineers marcheront main dans la main heureux. Néanmoins, Koalas n’embarque pas toutes les fonctionnalités de Pandas. Les fonctions les plus communes de Pandas sont implémentées dans Koalas, mais il reste du travail. Les “Insights” prometteurs sur Github laissent à penser qu’il s’agit d’un projet qui s’améliorera rapidement.
Performances de PySpark
Dans cette version, les développeurs de Spark ont beaucoup travaillé sur une meilleure intégration d’Apache Arrow. Et pour cause, plus de cinq pages de tickets Jira sont sur Arrow. Il s’agit d’un projet Apache offrant un format de données colonne stocké dans la RAM. Il permet à plusieurs composantes de communiquer de manière efficace et rapide. L’objectif final est d’améliorer les performances des échanges entre les jobs Python et la JVM.
Formats binaires
Nos amis Data Scientists seront contents car avec cette version de Spark apparait aussi la manipulation de formats binaires (images, vidéos …).
Petit exemple de code :
val df = spark
.read
.format("binaryFile")
.option("pathGlobFilter","*.jpg")
.load("/path")
À noter l’option pathGlobFilter permettant d’utiliser des regex sur des fichiers sans avoir à la mettre dans le load.
En sortie on aura un DataFrame contenant les données brutes et les metadata :
scala> df.printSchema
root
|-- path: string (nullable = true)
|-- modificationTime: timestamp (nullable = true)
|-- length: long (nullable = true)
|-- content: binary (nullable = true)
Petit hic, on ne peut pas écrire de formats binaires pour le moment.
GPU
Au travers de cette nouvelle sortie, Spark tente de rattraper ses concurrents sur la Data Science. La preuve en est avec cette nouvelle fonctionnalité permettant d’utiliser plusieurs GPU (AMD, Nvidia et Intel) en parallèle.
Cluster Manager
Les clusters managers ont aussi leur lot de nouveautés. La dernière version de Kubernetes est désormais utilisable. L’évolution la plus notable de cette release est l’allocation dynamique. L’intégration de Kerberos, l’utilisation des GPU des pods sont des améliorations notables de cette version.
Web UI
Dans cette version de Spark, de la documentation sur l’interface web de Spark a été ajoutée. Alors oui, ce n’est pas une nouvelle fonctionnalité en soit, mais qui ne s’est jamais arraché les cheveux devant cette interface ? On n’aura plus d’excuses maintenant.

SparkGraph
La version 3 de Spark introduit également SparkGraph, améliorant l’utilisation des Graphes. Il permet d’utiliser le Cypher Query Language développé par Neo4J dans Spark. Des algorithmes de graph processing ont aussi été ajoutés.
Conclusion
Spark était jusqu'alors cantonné à une population de Data Engineers. Avec cette nouvelle mise à jour, Spark a clairement pour objectif de se faire connaître et apprécier par d’autres métiers comme Data Scientist ou Data Analyst. L’amélioration de l’intégration avec Python, l’introduction d’outils pour Data Scientist (GPU, Arrow, Binaires), ou l’arrivée de Delta Lake en sont les témoins. Son ambition est bien plus grande.
Le rôle de Spark était souvent limité à un ETL (sur beaucoup de plateformes il ne fait que ça). Aujourd’hui, Spark tente d’élargir son offre pour couvrir l'ensemble des besoins d'une Plateforme Data (sauf DataViz) afin de faire face à la concurrence grandissante des solutions Cloud-Natives. Spark cherche également à ne pas subir le déclin des écosystèmes Hadoop (qui lui avaient permis de se propager aussi vite) en s'en détachant d'avantage.
