
Matillion est un ELT qui, depuis 2015, s’est installé parmi les plus en vogue du moment. Forte de ses 5 années d’expérience et après avoir levé 35 millions de dollars, l’entreprise britannique (située à Manchester) a recueilli les demandes de ses clients et sondé les besoins changeants des acteurs du marché pour finalement annoncer la sortie fin 2019 de son nouvel outil : Matillion Data Loader. En effet, selon leurs recensements, de plus en plus de parties prenantes aux différents projets IT ne sont pas issus de formations IT, et le besoin de solutions no-code qui permettraient à ces acteurs de pouvoir apporter leur expertise malgré leur manque de connaissances techniques est grandissant. Ainsi, d’après un sondage de IDG Research et Matillion, 87% des entreprises ayant des équipes silotées (ou partiellement silotées) prévoient de centraliser le management de la BI et de l’analytics, ce qui ferait graviter autour du même sujet des personnes issues d’horizons bien différents (IT mais aussi marketing, finance, etc.). L’idée est que tout le monde puisse avoir un accès rapide à un modèle de données démocratisé.
PRÉSENTATION
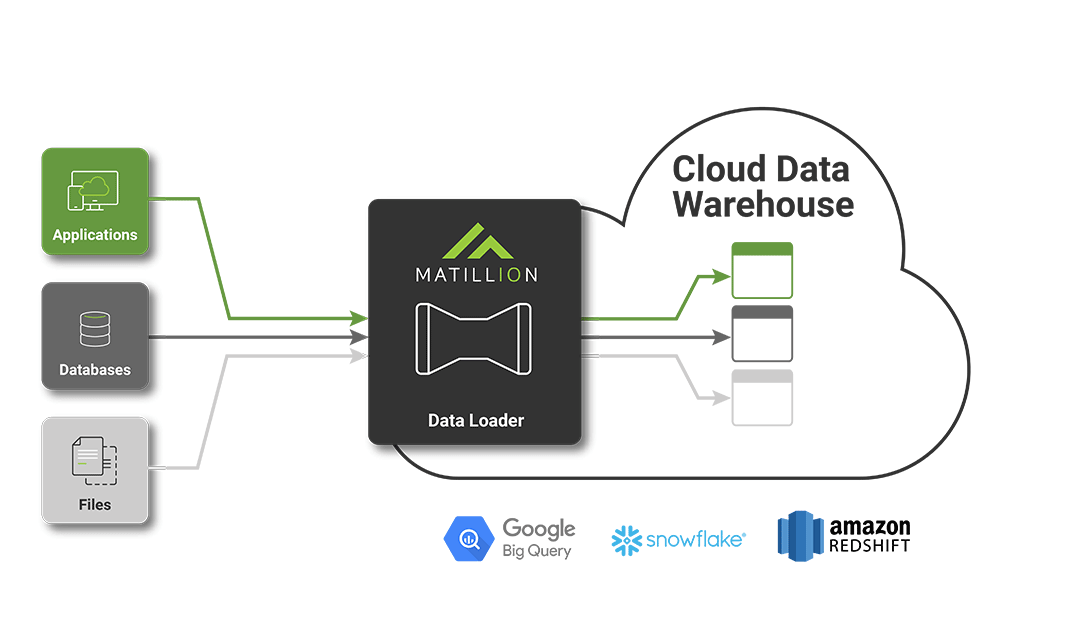
Les acteurs du marché ont exprimé le besoin d’avoir un outil centré sur l’intégration facile, rapide et économique de données dans le cloud. Ce besoin s’exprime également dans un contexte où l’objectif est de casser les silos de données existants pour tout regrouper dans un unique élément : le data warehouse. Matillion Data Loader (MDL) est donc un outil de pipeline de données (Extract, Load) en SaaS, permettant essentiellement de copier des données depuis des sources dites classiques (bases de données relationnelles notamment) vers des data warehouses dans le cloud. Voici la liste des différentes sources et cibles disponibles :

On trouve à l’heure actuelle dans la documentation 13 composants différents permettant de connecter sa/ses source(s) à un des 3 data warehouses présentés. On retrouve ainsi dans les cibles les 3 plus gros acteurs du marché du virtual data warehouse en ce moment : Redshift d’AWS, BigQuery de GCP et Snowflake (qu’il soit basé sur AWS ou Azure). De plus, MDL est en cours d’intégration de 4 nouvelles sources de données :
- Facebook AdAccounts ;
- Facebook AdInsights ;
- Facebook Content Insights ;
- HubSpot.
On imagine que d’autres encore sont à venir, mais Matillion n’a pas encore dévoilé de noms à ce propos. Par ailleurs, un plus grand nombre de sources sont disponibles dans la version ELT de Matillion.
Côté facturation, c’est très simple : l’outil est totalement gratuit. De base, l’entreprise comptait offrir le service gratuitement dans la limite de 250 millions de lignes transférées par mois, mais depuis peu cette limite a disparu et l'entièreté du service est gratuit. Il n’y a pas de possibilité d’abonnement Premium (ou équivalent) qui permettrait d’avoir accès à un support personnalisé, à plus de fonctionnalités ou à de meilleures performances. Pas de stratégie de format propriétaire utilisable seulement par l’ELT Matillion qui forcerait les utilisateurs de Data Loader à souscrire à l’ELT. Enfin, l’outil scale horizontalement automatiquement et il n’y a pas de limite sur le nombre maximal d’instances.
Une communauté (récente) et de la documentation sont accessibles ici. Le support semble assez actif et répond aux questions des utilisateurs dans la journée. On y retrouve également une FAQ et des bugs connus et en cours de traitement par Matillion.
A noter que MDL est optimisé pour (dans l’ordre) Google Chrome et Mozilla Firefox, mais fonctionne également avec HTML5 Canvas et WebSockets.
PLUS TECHNIQUEMENT
L’interface MDL est basée sur AWS Fargate dans un VPC AWS administré par Matillion. Les métadonnées des utilisateurs sont stockées dans un AWS Aurora sous-jacent. Ces métadonnées correspondent aux pipelines, aux planifications, aux identifiants et à des métriques concernant l’utilisation du produit. Pour l’instant il n’y a des serveurs disponibles qu’en Europe et aux USA. D’après Matillion, ils n’ont pas sur leur roadmap la volonté de s’étendre à d’autres continents comme l’Asie.
Le fonctionnement est le suivant :
MDL se connecte à la source en utilisant les credentials fournis. Ces credentials sont envoyés au service lorsqu'un pipeline est déclenché. Le service envoie les données à un runner isolé dans le VPC de Matillion. Le runner place ensuite les données dans une zone de staging (par exemple Amazon S3 si le data warehouse cible est Redshift), avant de les charger dans la table cible dans le datawarehouse cible.
Le fonctionnement peut être complété par le schéma suivant :
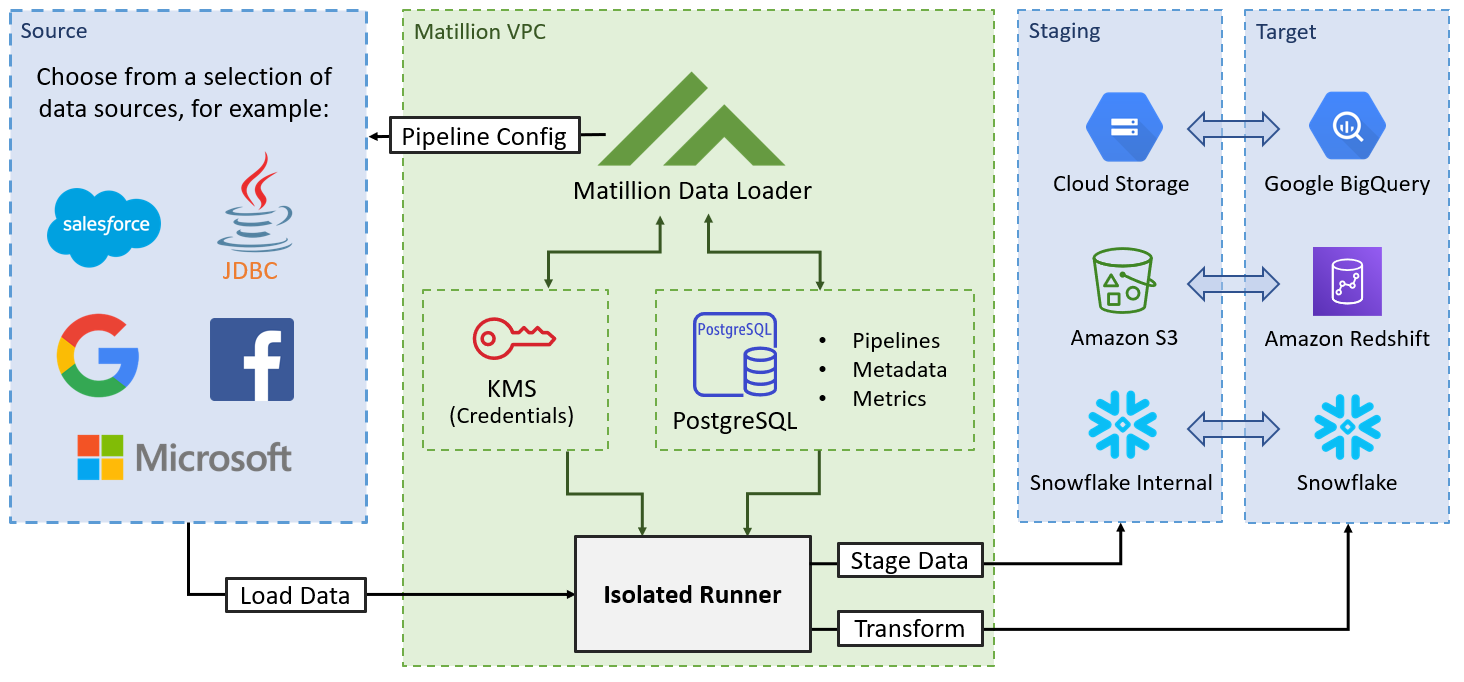
De plus, le runner existe dans un container temporaire isolé au sein du VPC de Matillion qui ne reçoit que les metadata et les références nécessaires pour accéder à une source unique et à un data warehouse cible. Un seul container est utilisé pour chaque exécution du pipeline et est détruit une fois l'opération terminée. Les utilisateurs n’ont pas directement accès au runner. La communication entre le runner est les datawarehouses se fait via JDBC en SSL pour Snowflake et Redshift, et en TLS (HTTPS) pour BigQuery.
MDL ajoute des colonnes “flags” qui permettent de suivre le Change Data Capture de chaque ligne. Ces colonnes sont par défaut un _id de run _et une date de dernier update.
Concernant la sécurité, lorsque les données sont en transit entre la source et MDL, la responsabilité de la protection de celles-ci revient à la source elle-même. Lorsque les données sont dans la zone de staging, la protection des données est à la charge du user qui a le contrôle sur l’environnement du data warehouse cible (qui définit la zone de staging).
Une fois les données chargées depuis la zone de staging vers les tables cibles, les données sont supprimées de cette zone. C’est la même chose une fois les données arrivées dans le data warehouse : c’est le user qui est en charge de définir ses règles de protection de données. De plus, au sein de l’outil, on trouve une gestion des mots de passe avec un système de clef:valeur où la valeur est le mot de passe (encryption KMS, non visible en clair) et la clef est le nom associé au mot de passe. Cet ensemble clef:valeur est accessible à l’outil lorsqu’il est nécessaire de rentrer des identifiants, pour paramétrer un composant par exemple.
MISE EN PLACE D’UN PIPELINE
Mise en place de l’environnement
La création d’un compte se fait facilement. On peut s’enregistrer avec son compte Google, Microsoft ou alors avec une simple adresse mail. Il est ensuite nécessaire d’accorder certains droits aux users de services dédiés à Matillion Data Loader pour chaque type de data warehouse. Ces droits à octroyer sont visibles ici. De plus, j’ai dû whitelister les adresses IP de MDL pour que l’outil puisse se connecter à mon instance PostgreSQL (pour la région EU) :
52.214.186.180
52.49.22.171
52.31.2.16
Création d’un pipeline
L’entité de base de MDL est le pipeline, qui est décrit par une source, une cible et sa fréquence de run. Ces éléments sont à paramétrer lorsqu’on crée son pipeline :

- D’abord, le choix du type de source (PostgreSQL ici) ;
- Ensuite, le choix du type de cible (Snowflake ici) et du nom du pipeline ;
- Enfin, le paramétrage de la connexion :
- Credentials de connexion
- Options de connexion
- Sélection des tables à charger
- Sélection des colonnes à charger
- Définition de l’environnement de Staging (où sont temporairement stockées les données)
- Définition de l’environnement de Landing (où les tables finales sont stockées)
- Réglage de la fréquence de run et test de la connexion.
Une fois le pipeline créé et les premières 24h passées, voici un aperçu de ce qu’on peut voir :

On peut voir ici par exemple que 9001 lignes ont été chargées le 19/02 et 8000 le 20/02. Un total glissant sur plusieurs périodes est disponible en bas. Par ailleurs, on peut activer et désactiver un pipeline avec le bouton switch en haut à gauche.
Management du pipeline
En plus d’avoir accès aux informations du pipeline, il est également possible de redéfinir la fréquence de run et le nombre d’erreurs à partir duquel un mail de notification est envoyé à l’utilisateur :

Voilà, une fois le pipeline paramétré comme souhaité, il suffit de le laisser activé pour que la migration des données en source soit effectuée vers la/les cible(s).
QUELS SONT LES AVANTAGES DE MDL ?
Le premier avantage et non des moindres est que l’outil est disponible en SaaS, ce qui élimine de nombreuses contraintes d’installation et de maintenance. Ensuite, le pricing est plus qu’intéressant : c’est totalement gratuit. Vient ensuite un argument à double-tranchant : il faut passer par un wizard (une interface graphique qui guide l’utilisateur pas à pas) pour configurer ses connexions. Cela s’inscrit pleinement dans la volonté de Matillion d’élargir son spectre d’utilisateurs. En effet, l’UI est relativement intuitive et claire. Cependant, cela frustrera forcément les plus puristes d’entre nous puisqu’il n’est pas possible de coder en dur ses connexions : le passage par le wizard est obligatoire. Dans la version ETL de Matillion, c’est la même chose, même s’il est possible d’accéder au code SQL équivalent au composant que l’on est en train de configurer. De plus, les sources disponibles sont parmi les plus populaires du marché. On pourrait ajouter à ça des features de monitoring des jobs et un système d’alerte et notification, mais ces éléments restent assez basiques.
CONCLUSION
MDL est un EL (Extract, Load) performant mais basique, qui suffira lorsque le besoin est simplement de migrer des données de sources différentes vers un endroit unique. Cependant, dès que des transformations sont à envisager, il est nécessaire de passer à un ETL/ELT plus complet comme Matillion ETL. D’ailleurs, Matillion offre un service qui permet de passer de Matillion Data Loader à Matillion ETL en transférant le travail effectué de l’un à l’autre.
Par ailleurs, il existe également des solutions concurrentes, dont voici quelques exemples :
Toutes ces solutions proposent plus de sources différentes, souvent plus de cibles, mais toutes sont payantes. Je ne me suis pas penché sur les performances de chacune. En conclusion, MDL sera une bonne option si le use case est simple (pour un POC par exemple) et si la diversité de sources de l’entreprise est faible. Sa facilité d’utilisation, sa gratuité et son utilisation en SaaS restent des avantages indéniables qui font de MDL une solution idéale pour le chargement de données. Quand un projet s'élargit et que plus de connecteurs sont nécessaires, on pourra s'orienter vers Matillion ELT ou une autre solution de transformation. Matillion Data Loader reste un outil très jeune, qui sait s’il saura s’imposer comme leader dans l’intégration de données ?
