

Introduction
La société Matillion édite un outil de traitement de données permettant de récupérer, préparer et transformer les données en utilisant la méthode ELT : Extract, Load and Transform (vs. ETL classique).
Comme son nom l’indique, l’ELT consiste à charger les données dans un entrepôt de données avant d’y appliquer les éventuels traitements.
Cette méthode est une alternative de l’ETL. Cette dernière extrait les données depuis la source vers une machine de traitement (Spark, Hadoop etc…) puis une fois le traitement effectué déplace une nouvelle fois les données vers les bases de données d’exposition.
Comprenons rapidement les différences entre ces deux méthodes.
ELT vs ETL
Dans ces deux méthodes on commence par l’extraction des données provenant d’une ou plusieurs sources : API, base de données, ERP, fichiers plats...
Ces méthodes se différencient ensuite puisque l’ELT procède directement au chargement des données dans le ou les entrepôts de données.

Les données sont insérées brutes dans des bases de données de l'entrepôt de données. On qualifie généralement ces bases de « base de staging ».
Les données sont dès la première étape dans les bases qui serviront à leur exploitation, ce qui est l’un des avantages par rapport à l’ETL :
On ne “déplace” qu’une seule fois la donnée.
Les traitements seront écrits en SQL puisque les données sont dans des bases.
La puissance de calcul de l'entrepôt de données étant à disposition, pourquoi s’en priver ? C’est donc celui-ci qui exécute les traitements.
On réussit donc à mutualiser les ressources de calculs pour le traitement des données et pour l’exposition/stockage.
C’est un avantage supplémentaire de l’ELT face à l’ETL, qui nécessite le provisionnement d’une machine intermédiaire pour les traitements, puis de charger ensuite les données dans une autre plateforme.
L’ELT applique les traitements sur les bases de staging souvent non typées, puis réécrit les données dans des bases propres, persistantes, où la donnée est prête à être utilisée.
Comme vous l’aurez compris, cette méthode contraint néanmoins à écrire le traitement en SQL, ce qui n’est pas forcément intuitif, répandu, pratique, efficace ...
Et c’est là que Matillion entre en jeu : il permet de se passer du développement de requêtes SQL imbriquées et illisibles et d’optimiser les connexions aux diverses sources.
Utilisation de Matillion
L’utilisation de Matillion est très simple. Depuis l’interface, on choisit des composants qu’on dépose sur l’espace de travail et que l’on relie dans l’ordre d'exécution voulu. Ces composants permettent d’effectuer différentes actions telles que :
- Créer des tables ;
- Charger des données ;
- Gérer les flux de données ;
- Transformer les données ;
- Écrire les données ;
- Etc.

L’interface est composée de 5 parties :
- Arborescences des jobs créés ;
- Liste des composants disponibles ;
- Espace de travail du job ouvert ;
- Caractéristique du composant sélectionné ;
- Liste d’exécution des tâches et logs.
En résumé, des actions classiques de manipulation de données.
Jusque-là rien d’extraordinaire, Matillion permet à première vue de faire ce que proposent déjà d’autres outils sur le marché tels que Talend, Dataiku et autres … Mais en ELT !
Regardons ce qu’il se passe réellement derrière tout cela.
Ces actions disponibles dans l’interface sont en fait traduites par l’outil en code SQL et transmises à un entrepôt de données qui sera responsable de l'exécution du code.
Matillion est un générateur de SQL
Si vous souhaitez vous familiariser avec les entrepôts de données du cloud, je vous invite à lire l’article très complet de Christophe Parageaud : « Data Warehouse dans le cloud : Redshift vs Snowflake », qui traite de deux entrepôts de données dans le cloud dont je vais vous parler dans l’article.
Matillion ne peut fonctionner sans entrepôt de données !
C’est un point crucial qui est parfois mal compris : Matillion n’est pas le moteur des traitements et des transformations des données, il est l’orchestrateur.
L’évolution des offres cloud et l’apparition des services d’entrepôts de données managés ont notamment permis l’apparition de l’ELT et de Matillion, qui se sert de la puissance de calcul des solutions d’entrepôt de données du cloud pour traiter les données et les exposer.
Matillion facilite la connexion à ces entrepôts de données et permet de profiter de leurs avantages tels que la puissance de calcul disponible à moindre coût, la tarification sur mesure de ces solutions ou bien le couplage avec les autres services managés dans le cloud.
En résumé, l’outil est intéressant pour les points suivants :
- Managé dans le cloud ;
- S’appuyant sur des outils eux-même managés dans le cloud ;
- Des vitesses et des puissances de calculs modulables et grandissantes ;
- Prise en main possible par des équipes “peu techniques” ;
- Une installation et une configuration rapides et faciles ;
- Présentation très visuelle des projets.
C’est le type d’outil qui facilite la vie des Data Engineers souhaitant utiliser la méthode ELT ou bien des équipes peu techniques sur certains projets.
Caractéristiques de Matillion
Matillion se décline ainsi en trois différentes solutions, chacune faite pour se connecter à un service d’entrepôt de données dans le cloud :
- Redshift de Amazon Web Services ;
- Big Query de Google Cloud Plateform ;
- Snowflake, solution indépendante reposant sur AWS, Azure ou GCP.

Ces solutions mettent à disposition différentes fonctionnalités propres aux services d'entrepôts de données concernés.
Cela permet à l’utilisateur de pouvoir choisir sa version de Matillion en fonction de son hébergeur cloud et de ses préférences, chacun des entrepôts de données ayant ses avantages et ses défauts.
Par exemple Snowflake gère l’auto extinction des machines après un temps d’inactivité choisi par l’utilisateur depuis l’interface, ce qui permet un gain d’argent considérable contrairement à Redshift qui (pour le moment) ne le permet pas.
On définit dans la console de Snowflake des “warehouses” (entendre par là “clusters”) en choisissant quel type de machine et combien de machines vont effectuer les traitements et on choisit aussi un temps d’inactivité pour l’auto-stop. L’article d’Arnaud Col « Gouvernance Snowflake » décrit entre autre cela.
Les trois solutions de Matillion possèdent exactement la même interface. Les composants d’orchestration et de traitement sont aussi les mêmes, mais peuvent se différencier par les fonctionnalités que chacune des offres d'entrepôts de données propose.
Installation et facturation
Matillion se lance rapidement depuis la marketplace d’Amazon Web Services, Google Cloud Platform ou bien Microsoft Azure.
Le démarrage de l’outil se fait par le lancement d’une instance dans le cloud, dont la taille détermine certaines caractéristiques du produit (fonctionnalités, nombre de connexions simultanés) et bien évidemment la tarification (serveur + prix licence).
Matillion s’installe sur l’instance avec les configurations choisies par l’utilisateur (le guide d’installation oriente néanmoins vers les configurations recommandées par l'éditeur).

De même, l’utilisateur peut choisir de payer sa licence à l’année ou bien de payer au temps d’allumage de la machine (à l’heure).
Le choix de paiement est souvent réalisé en fonction de la disponibilité nécessaire de Matillion ; si l’on doit effectuer des traitements aléatoires dans le temps et assez souvent dans la journée, il faudra privilégier la licence à l’année. A l’inverse, si les traitements sont effectués à instant précis dans la journée, le paiement à l’heure peut être très économique en mettant en place l’allumage et l’arrêt automatique de Matillion.
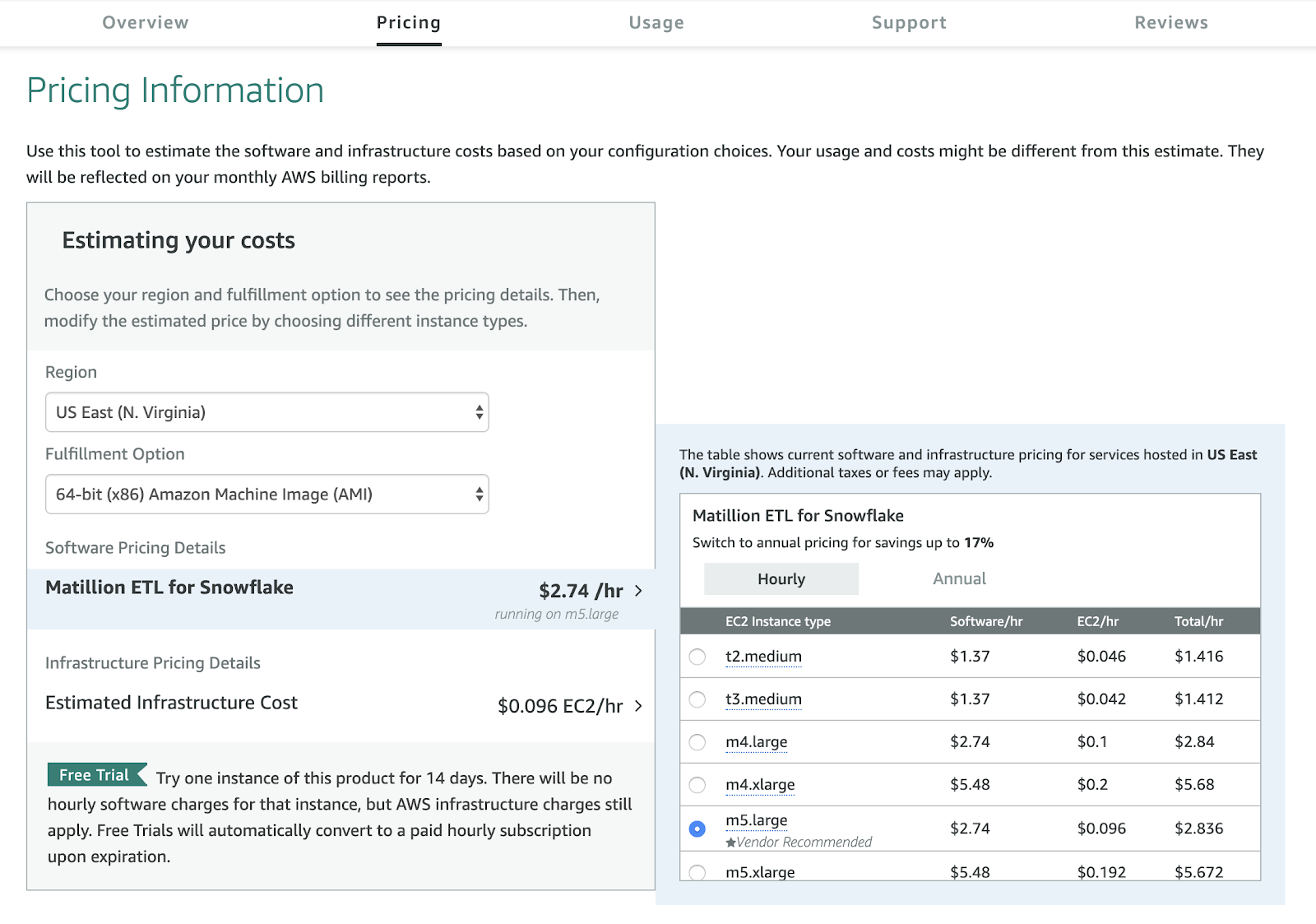
La facturation se fait directement depuis la facture du fournisseur cloud (AWS dans l’exemple), ce qui permet d’avoir premièrement un suivi des dépenses, de bénéficier de la prévision des dépenses de la plateforme et en plus de mutualiser les factures avec tous les autres coûts de plateforme.
Organisation des Jobs Matillion
Matillion propose donc d’effectuer plusieurs actions de manipulation de données, scindées en deux catégories : l’Orchestration et la Transformation.
Très simplement, les jobs d’orchestration vont concerner l’extraction, la connexion aux sources, la création des tables, le chargement et aussi l’orchestration des traitements.
Les jobs de transformation concernent, eux, la lecture des données à traiter, la jointure entre différentes tables, les calculs à réaliser et l’écriture des données.
Orchestration
| Create Table Component | |
|---|---|
 |
Ce composant permet la création de table dans l'entrepôt de données avec tous les avantages que celui-ci propose. Cela va des fonctionnalités indispensables comme du schéma de la table, jusqu’à certaines précisions du :
|
| S3 Load Component | |
|---|---|
 |
Lorsque l'on travaille sur AWS, ce composant permet de charger les données depuis S3 dans une table en question. Il est possible de charger des données sous différents formats de fichiers, différents encodages, des fichiers zippés, sur un ou plusieurs nœuds, en répliquant la donnée ou non. Un composant additionnel permet en plus d’explorer les données dans les fichiers S3, en obtenant un échantillon afin de détecter automatiquement le schéma de la table à créer. |
| Table Update Component | |
|---|---|
 |
Matillion propose de faciliter la connexion à de multiples API, ERP, base de données distante, telle que l’API de Facebook. Le composant indique tous les champs nécessaires à remplir afin de pouvoir requêter correctement l’API Facebook. L’onglet Help du composant indique comment remplir les champs et contient un lien vers la documentation. |
| SQS Message Component | |
|---|---|
 |
Ce composant permet d’envoyer un message dans une queue SQS d’AWS. La configuration est facilitée pour envoyer le message le plus facilement possible vers les queues existantes et accessibles du compte AWS. Cela permet de créer une orchestration basée sur les queues pour déclencher les différents services impliqués, ou bien aussi pour récupérer les logs des exécutions. |
Transformation
| Join Component | |
|---|---|
 |
On joint au minimum deux flux de données à ce composant. On définit la table principale, les tables secondaires, le type de jointure, les clefs de jointure. Matillion effectue une vérification à chaque modification du composant, impossible donc de faire des erreurs sur le nom des colonnes, sur la manière de joindre et sur le nom des tables. |
| Calculator Component | |
|---|---|
 |
Permet la création ou la modification de colonne sur une table. Une multitude de fonctions sont disponibles depuis le composant, avec la doc écrite directement dans l’outil. Ainsi pour calculer le produit de deux colonnes, modifier le type d’un champ, faire un “CASE WHEN”, tout est à portée de main. De même, les checks de validation sont constants afin d’anticiper les erreurs de syntaxe sur les fonctions utilisées. |
| Aggregate Component | |
|---|---|
 |
Matillion facilite l'agrégat de lignes en évitant de passer par de grosses requêtes SQL, avec 10 colonnes en clefs et des erreurs de nommage de colonne. Ici on choisit sa table, on choisit parmi la liste des colonnes celles à prendre en compte pour l’agrégat, on choisit les colonnes à conserver et la fonction d’agrégat sur ces colonnes. |
| Table Update Component | |
|---|---|
 |
Ce composant permet de faire une mise à jour sur une table. En renseignant un set de colonnes qui sert de clefs, Matillion va chercher dans la table visée si la ligne existe. Si oui, les champs de cette ligne sont mis à jour, si non, la ligne est insérée. |
Avantages
Différents outils ressemblent à Matillion dans l’utilisation (anciens tels que Talend, Dataiku ETL, Informatica, MaleSoft) : drag and drop de composants afin de manipuler les données, connexion dans un ordre logique des composants afin d’effectuer les traitements, disponibilité de nombreuses fonctions et de librairies. C’est pourquoi un Data Engineer ou un développeur ETL n’aura pas de mal à prendre l’outil en main et comprendre son utilisation s’il a déjà utilisé un outil similaire.
Pour les novices, je pense qu’ils comprendront rapidement la logique et la méthode d’utilisation de Matillion pour plusieurs raisons.
La solution Matillion est très visuelle et permet une organisation claire des jobs que l’on souhaite créer. Il est facile de présenter ou de léguer son travail.
On a une réelle idée du flux de données dans notre projet, contrairement aux traitements dans les langages classiques de traitement de données, ou bien dans un script exécutant des requêtes SQL les unes à la suite des autres. Les blocs s'enchaînent dans l’ordre défini tel qu’il apparaît à l’écran.
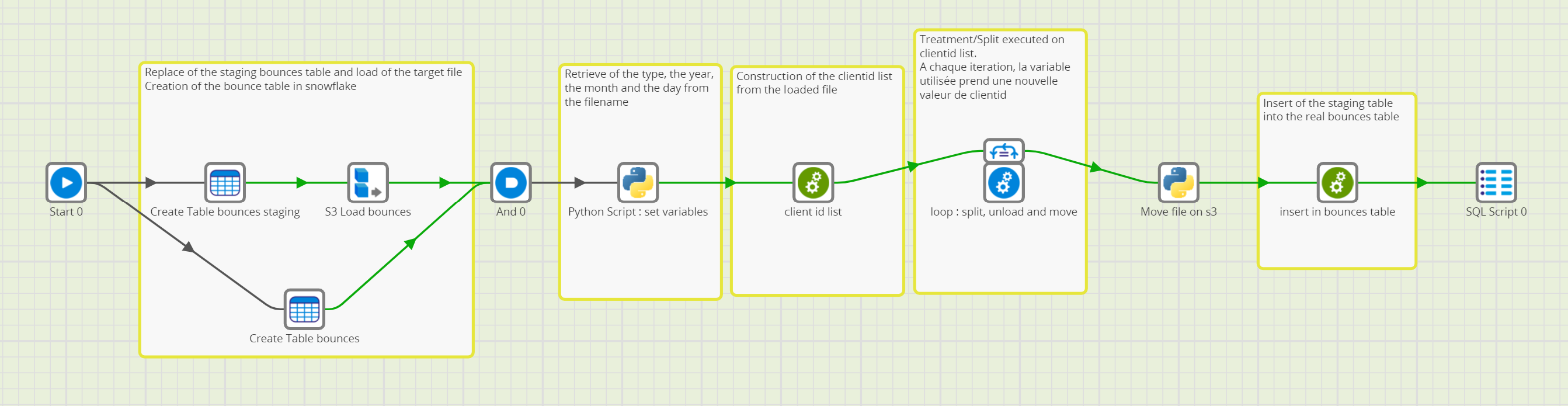
On sait clairement quelles données sont chargées dans quelles tables, quels types de traitements on effectue, étape par étape, et comment on ré injecte les données dans notre entrepôt de données.
De plus, l’outil fait en sorte que le moins de bugs possible se produisent lors des exécutions en effectuant des checks de validation systématiques à chaque modification. Cela facilite le travail et permet de voir si le composant est bien paramétré avant même d’essayer de l’exécuter. Pouvoir corriger ses bugs avant même qu’ils ne se produisent est gain de temps considérable. On comprend mieux l’utilisation des composants et on apprend plus vite.
En dehors de son utilisation, Matillion est facile à installer et à connecter à l'entrepôt de données. Les solutions Redshift et Snowflake, lancées depuis la Marketplace AWS (et donc installées sur une instance AWS EC2) offrent des endpoints aux différents services tel que S3, SQS, SNS, DynamoDB etc... On peut mettre en place une architecture intéressante en couplant ces services facilement.
Matillion enrichit régulièrement sa palette de connecteurs natifs permettant de se connecter plus facilement à une multitude de sources de données différentes telles que des ERP (Salesforce, SAP), des bases de données (ElasticSearch, SDK), des API (Facebook, Twitter, Instagram) et bien d’autres.
Partenariat IPPON
Après trois missions passées à utiliser Matillion dans des contextes différents, je pense l’outil opérationnel pour certains types de projets.
L’interface graphique facilite l’organisation et l’avancée du projet en gardant une vision macro des traitements. Cela permet de plus de faire des présentations interactives aux clients ou aux équipes métiers, en montrant des échantillons de données après chaque étape de traitements, et surtout en leur partageant notre vision élargie du projet, en montrant les différents flux, les jointures nécessaires, les différentes tables utilisées et les outputs.
Il faut garder en tête que les traitements sont effectués par l'entrepôt de données auquel se connecte Matillion et que tout n’est pas réalisable pour autant, certains projets seront plus adaptés à du traitement ETL classique.
Pour l’ELT, Matillion est un gros plus, il permet notamment :
- Un gain de temps en développement lorsque les sources de données sont nombreuses ;
- Une transmission des connaissances facile ;
- Une économie en mutualisant le stockage et le traitement ;
- Le bénéfice de la puissance de calculs des solutions d'entrepôt de données disponibles ainsi que leurs avantages.
Les points qui m’ont le plus bloqués sont les suivants :
- Communauté restreinte car peu d’utilisateurs ;
- Messages d’erreur parfois très vagues ;
- Bugs d’interface ;
- Frustration liée à la limitation des fonctionnalités de la version de Matillion la moins chère.
Alors que les solutions d'entrepôt de données dans le cloud ne font que s’améliorer, on peut penser que Matillion est un outil à potentiel, tout comme la méthode ELT qui va prendre de plus en plus sens dans les années à venir.
