
Introduction
L’objet de ce document est de fournir des recommandations pour mieux utiliser, configurer, opérer et superviser la solution Snowflake dont Ippon est partenaire depuis début 2019.
Ces recommandations ne remplacent pas une étude détaillée pour répondre du mieux possible à vos besoins.
Il faut profiter du fait que l’utilisation de Snowflake ne soit pas encore généralisée dans un groupe pour mettre en place les bonnes règles de gouvernance.
Ces règles doivent permettre une meilleure organisation des objets, une sécurité adaptée et rendre possible la rétro-facturation si nécessaire.
Pour mieux comprendre les spécificités de Snowflake, cet article de Christophe Parageaud est à votre disposition sur le blog Ippon.
Sujets étudiés
Choix de l’édition de Snowflake
Les éditions suivantes sont disponibles (avec indication du prix de compute par édition) :
- Standard - $2.50 / crédit
- Premier - $2.80 / crédit : ajoute le support 24x365
- Enterprise - $3.70 / crédit : ajoute possibilité de 90 jours de Time Travel (qui permet d’accéder des versions précédentes des données), multi cluster warehouse et les vues matérialisées
- Enterprise for Sensitive Data - $5 / crédit : augmente la sécurité notamment grâce au Private Link, peut être nécessaire pour les données RH
- Virtual Private Snowflake - sur demande : si on veut être mono-tenant
À ces prix il faut ajouter $23 / TB / mois pour le stockage, dans l’hypothèse d’un contrat capacitaire (Achat de crédits à l’avance).
La documentation est disponible ici et le pricing ici.
Recommandation :
80% des clients de Snowflake utilisent l’édition enterprise car elle permet d’utiliser toutes les fonctionnalités de Snowflake comme le Time Travel ou le Private Link (pour connecter Snowflake à votre propre VPC, en option) et de bénéficier de toutes les nouvelles fonctionnalités rajoutées chaque mois.
Si on venait à stocker de plus en plus de données critiques, on orientera le choix vers la version Enterprise for Sensitive Data, notamment pour disposer de la fonctionnalité de gestion de clés de cryptage à 3 parties.
Séparation des comptes
Un compte Snowflake correspond à une ligne de facturation et à une région de déploiement chez un fournisseur Cloud (AWS ou Azure, aujourd’hui, GCP annoncé pour début 2020).
Deux approches sont possibles :
- mono-compte :
- Description : le groupe gère une seule souscription utilisée pour ses besoins mais aussi ceux des filiales.
- Avantages : simplicité d’utilisation et de partage des données par création de vues ou de “zero-copy-cloning” (explication au paragraphe suivant) par exemple.
- Inconvénients : si besoin de refacturation, il faut suivre les usages et pouvoir les facturer en interne.
- multi-comptes :
- Description : On crée un compte pour le groupe puis un compte par filiale. On peut imaginer un seuil d’utilisation à partir duquel cela est pertinent.
- Avantages : la séparation des comptes entraîne une séparation de la facturation
- Inconvénients : obligation d’utiliser la fonction de data sharing pour partager des données du groupe vers les filiales.
Recommandation :
D’après l’utilisation actuelle, il semble préférable de continuer à utiliser un seul compte.
Par contre, le nommage des objets doit permettre la séparation des objets dans des comptes différents le jour où cela s’avèrera nécessaire.
On utilisera donc un préfixe [COMPANY] qui composera le nom de l’objet database.
De la même manière, il faudra utiliser ce préfixe pour le nommage des rôles (c.f. paragraphe sur les rôles).
Séparation des environnements
La séparation des objets entre les environnements de DEV, de TEST et de PROD est primordiale.
Avec Snowflake, il ne s’agit pas de séparer ces environnements avec plusieurs comptes mais plutôt d’utiliser une nomenclature adaptée.
Rappel de la hiérarchie des objets avec Snowflake :
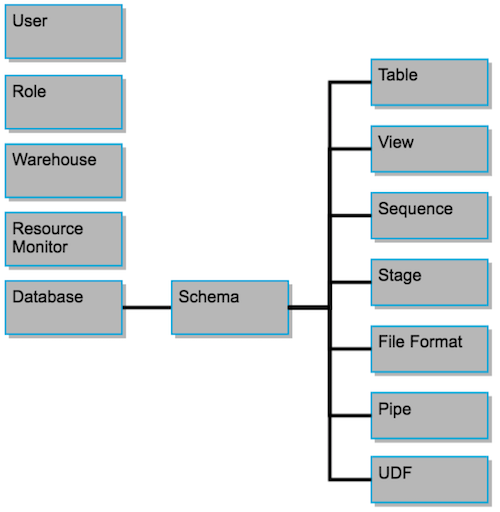
Recommandation :
Utiliser un suffixe désignant l’environnement [ENV] dans la règle de nommage de l’objet database qui aura donc la forme [PREFIXE]_[ENV]_DB.
Par exemple :
- PROD_DB
- TEST_DB
- DEV_DB
- FILIALE_PROD_DB
- FILIALE_TEST_DB
- FILIALE_DEV_DB
Pour gérer les données entre ces différents environnements, vous pouvez utilisez l’excellente fonctionnalité appelée “fast-cloning” ou “zero-copy-cloning” telle qu’elle est décrite dans cet article.
Couplé à un outil de gestion de cycle de vie du modèle de données comme Sqitch, on peut construire un solide pipeline de CI/CD.
Séparation des domaines fonctionnels
Comme vu dans la figure précédente, les schémas permettent de regrouper les objets au sein d’une database.
Recommandation :
Pour séparer les domaines fonctionnels, nous préconisons de créer différents schémas.
Le nom du schéma ne portera pas la mention de l’environnement, qui est déjà portée par la database.
Par exemple :
- FOURNISSEURS_SCH
- CLIENTS_SCH
Séparation des différentes workloads
Ce qu’on appelle “workload” correspond à une catégorie d’usage.
Avec Snowflake, on peut séparer les workloads grâce aux virtual warehouses (WH).
Il est intéressant de les séparer pour trois raisons :
- Dimensionnement : adapter la puissance de calcul en fonction des besoins
- Facturation : savoir combien de crédits consomme chaque virtual warehouse
- Isolation : pour que les requêtes des uns n’impactent pas celles des autres
Au niveau du coût c’est équivalent car les WH non utilisés ne coûtent rien dès lors qu’il se sont automatiquement arrêtés (au bout de 5 minutes minimum sans requête).
On retrouve régulièrement les 4 workloads suivantes :
- LOAD : Le chargement des données planifié quotidiennement.
- EXTRACT : Le déchargement des données (vers un outil de data visualisation par exemple) planifié quotidiennement.
- QUERY : L’interrogation de Snowflake par les data scientists et data analysts pour faire de l’exploration de données.
- LIVE : L’interrogation de Snowflake par des outils de data visualisation branchés en live (comme par exemple Superset).
Nous préconisons de séparer ces 4 workloads sur 4 virtual warehouses et ce pour chaque société et environnement pour lesquels cette workload serait utile.
Par exemple, si une filiale ne consomme que des données qui ont déjà été chargées niveau groupe, elle n’aura pas de WH de type LOAD.
Exemple :
- Pour le groupe, on aurait les virtual warehouses suivant :
- PROD_LOAD_WH
- PROD_EXTRACT_WH
- PROD_QUERY_WH
- PROD_LIVE_WH
- Pour une filiale, qui ne fera à priori pas de live dans un premier temps, on aura seulement :
- FILIALE_PROD_LOAD_WH
- FILIALE_PROD_EXTRACT_WH
- FILIALE_PROD_QUERY_WH
Sur les environnements de DEV et TEST, on ne créera que les virtual warehouses nécessaires.
Et pour les filiales qui n’auraient que de faibles besoins, on pourrait commencer en utilisant les virtual warehouses du groupe.
Gestion des rôles
Dans Snowflake on gère la sécurité en attribuant des rôles aux utilisateurs.
Recommandation :
Nous préconisons d’avoir par défaut :
- 1 rôle ADMIN par database, par exemple
- PROD_DB_ADMIN_RL
- FILIALE_DEV_DB_ADMIN_RL
- 2 rôles par schémas, un rôle ADMIN et un rôle READ :
- FOURNISSEURS_SCH_ADMIN_RL
- FOURNISSEURS_SCH_READ_RL
On notera que le type d’objet (DB ou SCH) a été conservé dans le nom, ainsi on sait tout de suite sur quel niveau de la hiérarchie d’objet on se positionne.
Convention de nommage des objets
Le nom des tables doit si possible décrire le domaine fonctionnel des données qu’elle contient.
Par exemple : CODES_PAYS
C’est pareil pour le nom des vues mais on suffixera le nom avec _VIEW.
Par exemple : CLIENTS_NOUVEAUX_VIEW
Méthode de partage des données entre les filiales
Pour partager les données entre les filiales, la mise à disposition de vues est une bonne solution.
Si un jour on crée plusieurs comptes Snowflake, on pourra utiliser le data sharing.
Suivi des coûts
Pour suivre les coûts plus finement (par exemple : par utilisateur, par rôle) que ce qui est proposé dans l’interface de Snowflake (par warehouse), on pourra construire des tableaux de bords avec un outil comme Superset.
Par exemple la vue SNOWFLAKE.INFORMATION_SCHEMA.WAREHOUSE_METERING_HISTORY permet de suivre les crédits consommés sur chaque virtual warehouse.
Une meilleure connaissance des coûts permet de mieux prévoir les crédits à provisionner.
Conclusion
Avec l’ensemble de ces recommandations, on peut atteindre une meilleure organisation des objets avec en particulier une bonne identification des environnements et des différentes filiales. L’utilisation des rôles permet d’assurer un niveau d’accès fin aux utilisateurs.
La séparation des virtual warehouses permettra de mieux séparer les coûts d’utilisation de Snowflake et facilitera le reporting financier.
