
Que ce soit pour effectuer un grand nombre d’insertions en base de données au cours du temps ou pour planifier des tâches périodiques pour du batch processing, on fait souvent appel aux systèmes de files d’attente. Si vous suivez un peu les technologies qui tournent autour de Python, vous avez sûrement déjà entendu parler de la librairie Celery et peut-être même déjà travaillé avec. À titre indicatif, il s’agit d’une librairie Python de files d’attente de tâches distribuées et asynchrones. Je vous rassure, il existe d’autres projets similaires dont certains visent à simplifier l'utilisation de Celery et à répondre à d’autres cas d’usage. Au premier abord, ces systèmes sont relativement complexes à développer et à mettre en place dans la mesure où l’on se retrouve obligatoirement confronté aux problématiques liées à la sérialisation, la concurrence, le stockage, l’accessibilité, le scaling, et j’en passe. C’est pourtant le défi que se sont lancé les fondateurs de Pricing Assistant en créant leur propre task queue fait main, nommée MRQ (Mongo Redis Queue).

Pour commencer
MRQ est un projet open source développé par la société Pricing Assistant (récemment rachetée par Contentsquare) qui permet de transmettre des tâches asynchrones (ou unités d’exécution) par le biais d’un système distribué de files d’attente. Le projet vise à fournir un système unifié et performant, capable de gérer un large volume de tâches. Il est justement utilisé pour la solution Pricing Assistant afin de prendre en charge le crawling de milliards de pages web. Grâce à cet algorithme de crawl, la solution réalise une veille tarifaire automatique permettant aux marques d’optimiser leurs prix.
Les task queues constituent un pattern d’architecture qui permet de planifier et exécuter des tâches en arrière plan de manière à alléger la charge de travail côté front-end. Cette technique s’avère donc utile pour les traitements par lots relativement coûteux en temps et en charge ou pour les tâches qui ne nécessitent pas d’être initiées par une requête côté utilisateur.
Imaginez par exemple une application web ayant besoin d’interroger l’API de Twitter pour récupérer les dix tweets les plus récents publiés par un compte utilisateur. Une task queue permettrait de mettre en file d’attente plusieurs appels à l’API de Twitter qui seront traités les uns après les autres. Les résultats seraient ensuite insérés dans une base de données pour une utilisation future.
Cet article présente la technologie MRQ au travers d’une présentation de ce projet et de comparatifs avec des solutions similaires existantes.
Les systèmes de task queue
Le projet MRQ se positionne parmi les systèmes dits de work queue (ou task queue), par opposition aux systèmes de message queue. Les différences qui existent entre ces deux patterns sont subtiles et portent parfois à confusion, c’est pourquoi mettre en exergue ces points me semble nécessaire.
Premièrement, il va sans dire que les éléments d’une task queue spécifient une tâche à accomplir, ou plus concrètement une fonction de programme (par exemple, retourner le nombre de caractères présents sur une page web), tandis que les éléments d’une message queue sont des messages (par exemple, des évènements que l’on retrouverait dans un fichier de log). Cependant, dans les deux cas, la queue agit comme un médiateur de messages entre les émetteurs et les récepteurs. On parle alors de broker. Son rôle consiste à stocker la donnée et à la délivrer de manière ordonnée, à la demande. Là où la message queue empile les messages qui seront consommés par des abonnés, la task queue empile les tâches qui seront consommées par des jobs.
De plus, MRQ et les autres task queues (Celery par exemple) offrent un niveau d’abstraction plus élevé pour implémenter le producteur et le consommateur des tâches, dans la mesure où il permet de travailler avec les événements des files d’attente sans pour autant devoir écrire les consommateurs et producteurs. La consommation et l’exécution des séquences de tâches sont en réalité gérées par les threads d’exécution du worker. Afin d’éviter toute confusion, on définira un worker comme un processus Python (ou unité de traitement) qui retire puis exécute les jobs en arrière-plan pendant une longue durée (dans la plupart des cas).
Dans la suite de cet article, je ne vais pas établir une liste de généralités qui caractérisent les task queues, chacune ayant ses propres propriétés, qu'il s'agisse de conception voire même de besoin. C’est pourquoi j’ai choisi de présenter MRQ et de le comparer à d’autres librairies de task queues comme Celery, technologie sur laquelle s’est basée MRQ.
Pour la petite histoire...
MRQ est né dans un contexte où la complexité de développement et de personnalisation des éléments de la task queue devenait beaucoup trop contraignante avec Celery. L’implémentation de ce framework reposant sur un nombre de couches d’abstractions et de dépendances relativement important (cf. graphe des dépendances ci-dessous), sa mise en place peut rapidement devenir fastidieuse. Ainsi, les contributeurs de MRQ avaient comme volonté de développer une solution facilitant l’implémentation des tâches et des éléments grâce à une simplification du code et des dépendances de librairies. Ils voulaient également veiller à comprendre tous les évènements liés à l’exécution des tâches. Avant de se pencher sur la présentation des différentes caractéristiques de MRQ, nous allons nous intéresser à son schéma d’architecture global.

pydepsArchitecture globale
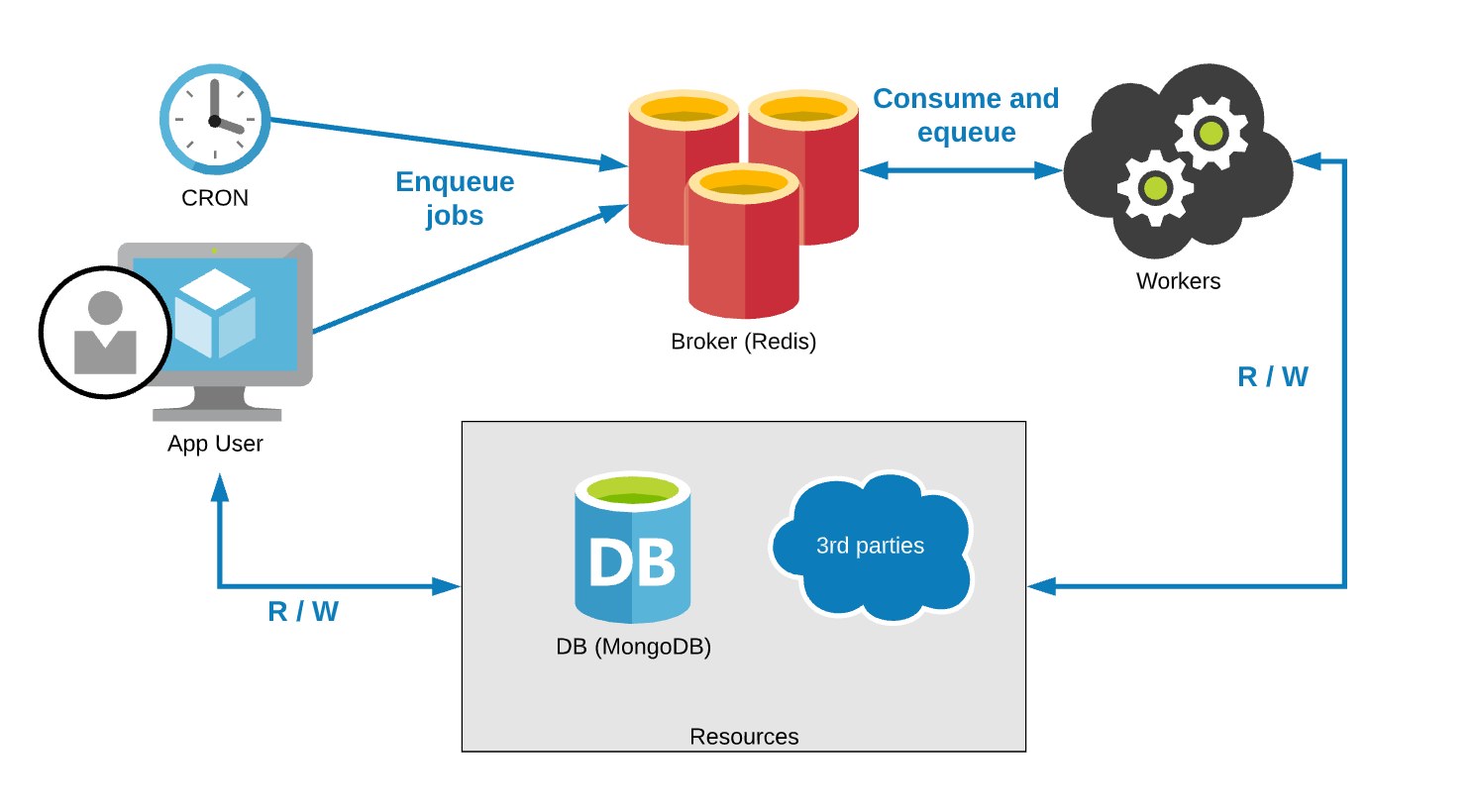
MRQ s’appuie sur la technologie Redis, faisant office de broker, pour établir la médiation entre les clients et les workers. Redis est un système de stockage en mémoire clé-valeur scalable et hautement disponible. Pour initialiser une séquence de tâches, le client insère celles-ci dans la queue et les délivre aux workers de manière synchrone. Pour paralléliser les traitements et diminuer les durées d'exécution, il est judicieux d’instancier plusieurs workers. Cependant, la haute disponibilité et la scalabilité horizontale sont propres à la technologie MRQ puisqu’elle s’appuie sur Redis pour la rétention des messages en transit. Une fois les tâches distribuées aux workers, elles sont exécutées de manière asynchrone sous forme de processus.
Dans le contexte de Pricing Assistant, seuls les jobs en attente sont stockés dans des sorted sets Redis. L'utilisation de Redis comme queue offre des propriétés très intéressantes comme l'unicité, la conservation de l'ordre, l'atomicité des mises à jour ou encore la performance. Les jobs démarrés et réussis ainsi que les métadonnées associées sont quant à eux stockés dans MongoDB (comme le statut ou la stack trace). Cette conception permet ainsi de trouver un équilibre entre performance et visibilité. Je vous invite d’ailleurs à lire, si ce n’est pas déjà fait, l’article de Boris Perevalov dans lequel il expose son retour d’expérience sur MongoDB. Les valeurs de retour des fonctions sont également stockées dans MongoDB.
Vous avez dit asynchrone ?
L’asynchronisme est une notion fondamentale lorsqu’on cherche à exécuter des tâches bloquantes ou de longue durée (notamment des tâches I/O-bound, qui dépendent des entrées/sorties du sous-système) et qui s’avère particulièrement utile et efficace pour des applications Python à forte charge. Ce concept de programmation repose sur le principe d’exécution alternée d’opérations planifiées et consiste à déterminer si une tâche ultérieure peut être lancée avant la fin de l’exécution de la tâche en cours, ou si elle doit attendre. Ce modèle nous aide ainsi à accomplir l’exécution concurrente de tâches. Les deux schémas ci-dessous illustrent ce modèle dans le cas d’un environnement single-threaded, dans un premier temps, puis multi-threaded.
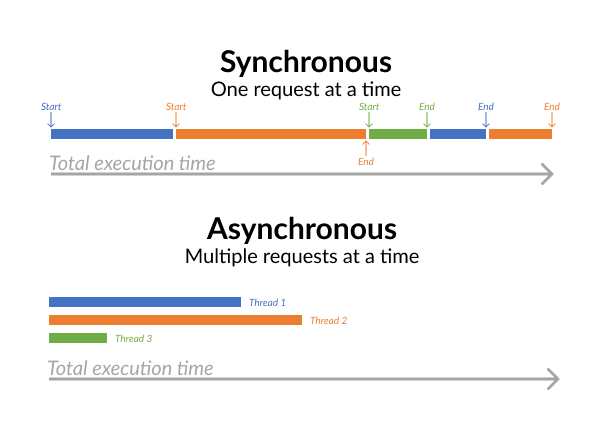
Cependant, tout développeur Python me dira à quel point il est difficile d’utiliser Python pour exécuter des tâches CPU-bound en multi-threaded, en pointant du doigt le Global Interpreter Lock (plus connu sous le nom de GIL), qui empêche plusieurs threads de code Python de s’exécuter simultanément. En effet, le GIL a été implémenté pour faire face aux problèmes de gestion de la mémoire et par conséquent, Python est limité à l’utilisation d’un seul cœur CPU. Ainsi, les langages de programmation « haut niveau » comme Python perdent en efficacité, comparé à d’autres langages comme Java ou C qui prennent en charge nativement l’exécution de tâches multi-threaded sur plusieurs cœurs CPU. Pour pallier à ce problème et exploiter plusieurs cœurs simultanément (et ainsi réduire la contention des threads), vous devrez exécuter vos tâches CPU dans des processus distincts (représentés par vos workers).
Dans un contexte de traitement important de tâches I/O-bound, il existe un autre type de fil d’exécution appelé greenlets qui offre de meilleurs avantages que les threads. MRQ nous donne justement la possibilité d’en profiter grâce à la bibliothèque Python appelée Gevent. C’est pas génial ?
C’est green, donc plus écolo ?
En quelque sorte oui, dans la mesure où les greenlets sont moins gourmands en ressources et plus légers que les threads (en particulier lors de leur création). Autrement dit, le temps de commutation d’un processus à un autre est nettement plus court, ce qui diminue le temps d’exécution. On pourrait ainsi comparer un greenlet à une coroutine légère qui par définition est une unité de traitement permettant d’exécuter du code non-bloquant et asynchrone (cf. article Introduction aux coroutines dans Kotlin par Yannick Jacqueline). Ces derniers ont la particularité d’être planifiés de manière coopérative et non préemptive (évitant ainsi l’interruption inopinée d’une tâche en cours d’exécution par d’autres tâches initiées par le système d’exploitation). Cependant, la commutation des greenlets dans Gevent est faite de manière automatique par le scheduler tandis que celle des coroutines doit être précisées (par exemple, grâce au mot-clé await lorsque vous utilisez asyncio, une autre librairie Python de programmation asynchrone compatible avec la version 3.4 et ultérieure).
Gardez à l’esprit que lorsque vous concevez votre application, il est important de bien séparer vos types de tâches sur des workers différents. En effet, étant donné que Gevent utilise des multitâches coopératives, les tâches CPU-bound ne céderont pas le contrôle au scheduler, ce qui limitera la concurrence et entraînera un blocage lors de l’exécution. Pour cette raison, Gevent est un bon choix pour les tâches qui effectuent beaucoup d’entrées/sorties, mais n’améliorera pas les performances de votre application pour des tâches CPU-bound. Dans ce genre de cas, on préférera augmenter le nombre de processus au nombre de cœurs disponibles et diminuer le nombre de greenlets lors de l’instanciation du worker grâce à la commande suivante :
mrq-worker --greenlets 30 --processes 3
Cette commande lancera 30 greenlets sur 3 processus UNIX où chacun d’entre eux lancera 10 tâches en même temps. Dès que vous utiliserez l’option processes dans votre commande, vous lancerez en réalité un processus supervisor qui aura pour rôle de superviser le nombre de processus UNIX défini au préalable. Le worker en lui-même ne traite pas les tâches mais génère des processus enfants (ou threads) qui les exécuteront. Ces processus enfants sont également appelés pool d'exécution.

Oui, mais…
Évidemment, aucun système de task queue ne nous met à l’abri d’éventuelles interruptions survenant durant l’exécution successive de tâches. C’est pourquoi il est crucial de considérer en amont la conception de nos tâches. C’est justement une des recommandations préconisées dans la documentation de MRQ, qui incite les utilisateurs à implémenter des tâches réentrantes de manière à ne pas corrompre le système ni les données lorsqu’une fonction est appelée successivement ou simultanément. Pour qu’une fonction soit réentrante, elle ne doit pas utiliser des données globales ou statiques, ne doit pas modifier son propre code et ne doit pas appeler une fonction non réentrante. En voici un exemple :
temp = "global"
def non_reentrant_function(x):
global temp
temp = x # print(temp) after calling non_reentrant_function("changed") will display "changed"
def reentrant_function(a):
value = a + random.randint(1,10) # don't affect `temp` global variable
db.insert(value, 0)
De même, vous devez essayer de rendre vos tâches idempotentes, c'est-à-dire obtenir un résultat identique à l'issue de leurs appels respectifs, quel que soit le nombre de répétitions (consécutives ou parallèles). La fonction valeur absolue abs(x) est un exemple de fonction idempotente :
def absolute_value(value):
return abs(value)
>>> [absolute_value(-14) for i in range(10)]
[14, 14, 14, 14, 14, 14, 14, 14, 14, 14]
Voici une liste exhaustive de recommandations supplémentaires à prendre en compte pour favoriser la résilience de votre système :
- Avoir une connaissance suffisante de la technologie utilisée pour le broker de message (et notamment Redis pour MRQ) ;
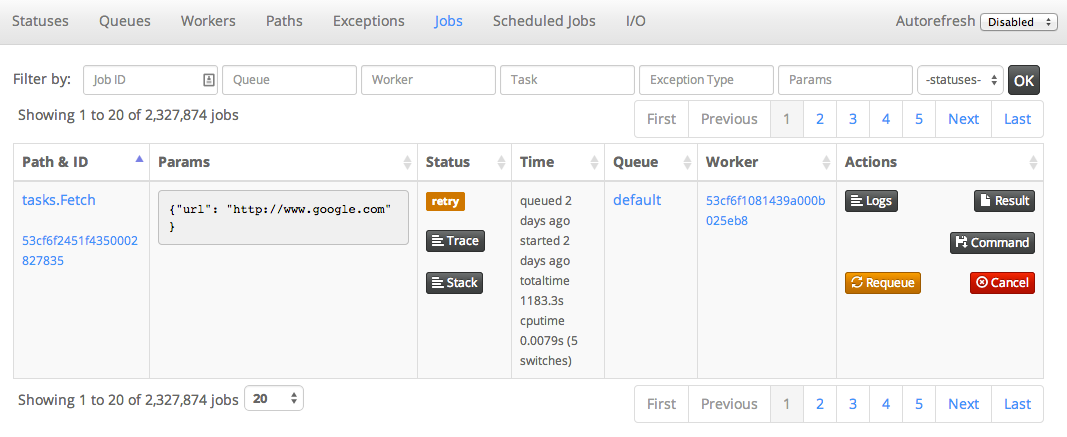
- Superviser les tâches en erreur : pour cela, MRQ fournit une interface permettant de suivre le statut de vos tâches exécutées par vos workers (cf. capture ci-dessous). L’interface offre davantage de visibilité aux utilisateurs sur les tâches ayant échoué, regroupées par type d’exception ;
- Gérer les défaillances potentielles grâce à la reprise sur erreur : les exceptions ne sont pas systématiquement censées entraîner l’échec d’une tâche. Par exemple, l’exécution d’une requête HTTP à un serveur web peut parfois échouer. Dans ce cas, vous voudrez réessayer de l’exécuter ultérieurement. Ici, la fonction
retry_current_job()peut alors s’avérer utile (cf. partie de code ci-dessous).
from mrq.task import Task
from mrq.context import retry_current_job
import requests
class MyTask(Task):
def run(self, params):
try:
response = requests.get(params["url"])
return len(response.content)
except requests.exceptions.HTTPError as e:
log.warning("Got HTTP error %s, retrying...", e)
retry_current_job()
retry_current_job()Et les autres dans tout ça ?
Avant de donner mon verdict sur MRQ, j’ai choisi de présenter trois autres projets Python concurrents connus. Lorsque vous choisissez un système de queue pour votre application, réfléchissez bien en amont à vos besoins (performances, criticité au sein de votre architecture, niveau de visibilité des tâches, langage, tolérance à la panne des workers, notoriété, documentation, etc). Vous vous rendrez compte que de nombreux systèmes de files d’attente sont disponibles sur le marché et qu'il n'existe pas de solution miracle capable de répondre à tous les cas d’usage.
Celery (14,6k ★)
Il s’agit de la task queue Python la plus répandue et utilisée pour gérer des tâches asynchrones et planifiées. Celery offre de la flexibilité, de la robustesse et un nombre important de fonctionnalités comparé aux autres projets, mais au détriment de la simplicité d’utilisation. En effet, Celery devient rapidement complexe dès lors qu’on souhaite personnaliser la configuration de notre file d’attente (par exemple l’envoi de tâches d’un langage à un autre). Par conséquent, si vous souhaitez mettre en place un Celery au sein de votre architecture, je vous conseille de suivre une courbe d’apprentissage raisonnable, car la compréhension de Celery peut demander du temps et de la persévérance.
Celery prend en charge une gamme complète de brokers de messages offrant de la flexibilité à l'utilisateur s’il souhaite changer de système de queue (SQS, Redis, RabbitMQ...). L’interface de monitoring (Celery’s Flower) est relativement simple à configurer et riche en informations.
Cependant, il n’est pas rare de rencontrer des problèmes de fuites de mémoire si la quantité de RAM allouée n’est pas suffisante par rapport à la charge de traitements que vous attribuez à Celery. Chase Seibert a écrit un article à ce sujet que je vous encourage à lire.
RQ (6,8k ★)
Ce projet doit sa notoriété et sa force à sa simplicité d’utilisation et de compréhension de son API, de son code et de sa documentation par rapport à d’autres projets tels que Celery. RQ se situe avec Celery parmi les projets les plus établis et actifs au sein de la communauté. L’interface de suivi des tâches est elle aussi simple à configurer et efficace. RQ prend en charge le modèle de queues prioritaires permettant aux workers de lire les messages dans l’ordre.
Néanmoins, RQ n’est utilisable qu’en Python, ne sait pas gérer plus d’un worker, et ne supporte que Redis comme broker de messages. Cela peut être vu comme un inconvénient au niveau de la garantie de livraison des messages puisque le mécanisme de Redis est fondé sur des sockets et des boucles d’évènements. Cela signifie que si un abonné n’est pas à l’écoute pendant une publication, l’évènement sera perdu. De plus, Redis peut entraîner des latences élevées dans le traitement de messages volumineux. En revanche, il est très adapté pour des « petits » messages. Redis peut aussi être vu comme très avantageux au niveau des performances car il s'agit d'un système rapide et hautement scalable (les structures de données sont mises en cache).
Huey (2,9k ★)
Ce projet est décrit comme étant un système de files d’attente de messages légers codé en Python avec une API similaire à Celery. Comme RQ, Huey utilise Redis comme broker de messages et a été conçu dans le but de simplifier l’utilisation des files d’attente, sans pour autant réduire les fonctionnalités. Huey prend en charge l’exécution de tâches multi-threaded planifiées et périodiques, la reprise sur erreur et le stockage des résultats des tâches. Cette solution est une bonne alternative à Celery pour répondre à des cas d’usages simples comme l’envoi d’emails, la génération de vignettes, des appels d’API ou encore la vérification de spams. Toutefois, notez que Huey n'est pas forcément adapté à des besoins plus complexes comme l'exécution de tâches CPU-bound ou l'attribution de tâches à des workers particuliers. Dans ces cas de figure, Celery est un meilleur choix.
Verdict !
Après quelques mois d'utilisation de l'outil, je pense que MRQ est un bon compromis entre RQ et Celery pour exécuter des tâches hétérogènes, malgré sa faible notoriété. Cette solution vise à la fois à accroître la simplicité d’utilisation comme RQ et à offrir des performances proches de Celery grâce à Gevent. Ainsi, si vous souhaitez profiter d'une souplesse qui vous octroie la liberté d’ajuster la visibilité de vos tâches au détriment de la performance et vice versa, je vous suggère de considérer MRQ pour votre application Python. Autrement dit, si vous avez besoin de hautes performances, vous utiliserez un système plus semblable à Celery mais vous perdez de la visibilité sur les tâches en attente. Au contraire, si vous n’avez pas besoin de hautes performances mais d’une visibilité accrue sur vos tâches, vous disposerez d’un dashboard efficace pour superviser vos jobs principalement stockés sur MongoDB, vos workers, etc.
| Queue type | Regular | Raw | Raw with no_storage config |
| Storage for queued jobs | MongoDB | Redis | Redis |
| Storage for started & success jobs | MongoDB | MongoDB | None |
| Performance | + | ++ | +++ |
| Visibility in the dashboard | Full | After start | Job counts & failed jobs |
| Safety | +++ | ++ | + |
Références
Matt Makai, Task Queues, https://www.fullstackpython.com/task-queues.html
Adrien Di Pasquale, Taskqueue tips, 13 mars 2017, https://getaround.tech/taskqueues-tips/
Sylvain Zimmer, PyParis 2017 - Developer-friendly task queues: what we learned building MRQ, 3 août 2017, https://www.youtube.com/watch?v=RBBQfn8jRMU&t=515s
barnert, Greenlets, threads, and processes, 14 janvier 2015, http://stupidpythonideas.blogspot.com/2015/01/greenlets-threads-and-processes.html
Anurag Jain, Understand the problem with multithreading in python, 15 janvier 2016, http://anuragjain67.github.io/writing/2016/01/15/problem-with-multithreading-in-python
G Abhisek, Concurrency, Parallelism, Threads, Processes, Async and Sync — Related?, 29 décembre 2018, https://medium.com/swift-india/concurrency-parallelism-threads-processes-async-and-sync-related-39fd951bc61d
Rick Copeland, Threads Versus Greenlets in Python Networking Library Gevent, 26 juillet 2012, https://dzone.com/articles/threads-versus-greenlets
Charles Leifer, Huey, a lightweight task queue for python, 02 février 2015, https://charlesleifer.com/blog/huey-lightweight-task-queue-python/
Pros and cons to use Celery vs. RQ, https://stackoverflow.com/questions/13440875/pros-and-cons-to-use-celery-vs-rq
