
Tout le monde écrit des skills. Presque personne ne les teste. On rédige quelques centaines de lignes d'instructions, on lance un prompt une fois, on voit que ça passe, et on merge. Sans tests, sans suite de régression. Le vibe check, non?
Le problème est plus sérieux qu'il n'y paraît. Les skills peuvent déclencher des déploiements, rédiger des contrats, bootstrap des apps, parlent à vos APIs. Quand un skill casse, et il cassera à la prochaine mise à jour modèle, ça se passe en silence. Pas de stack trace. Le skill se trompe simplement, avec assurance, face à un utilisateur qui lui fait confiance.
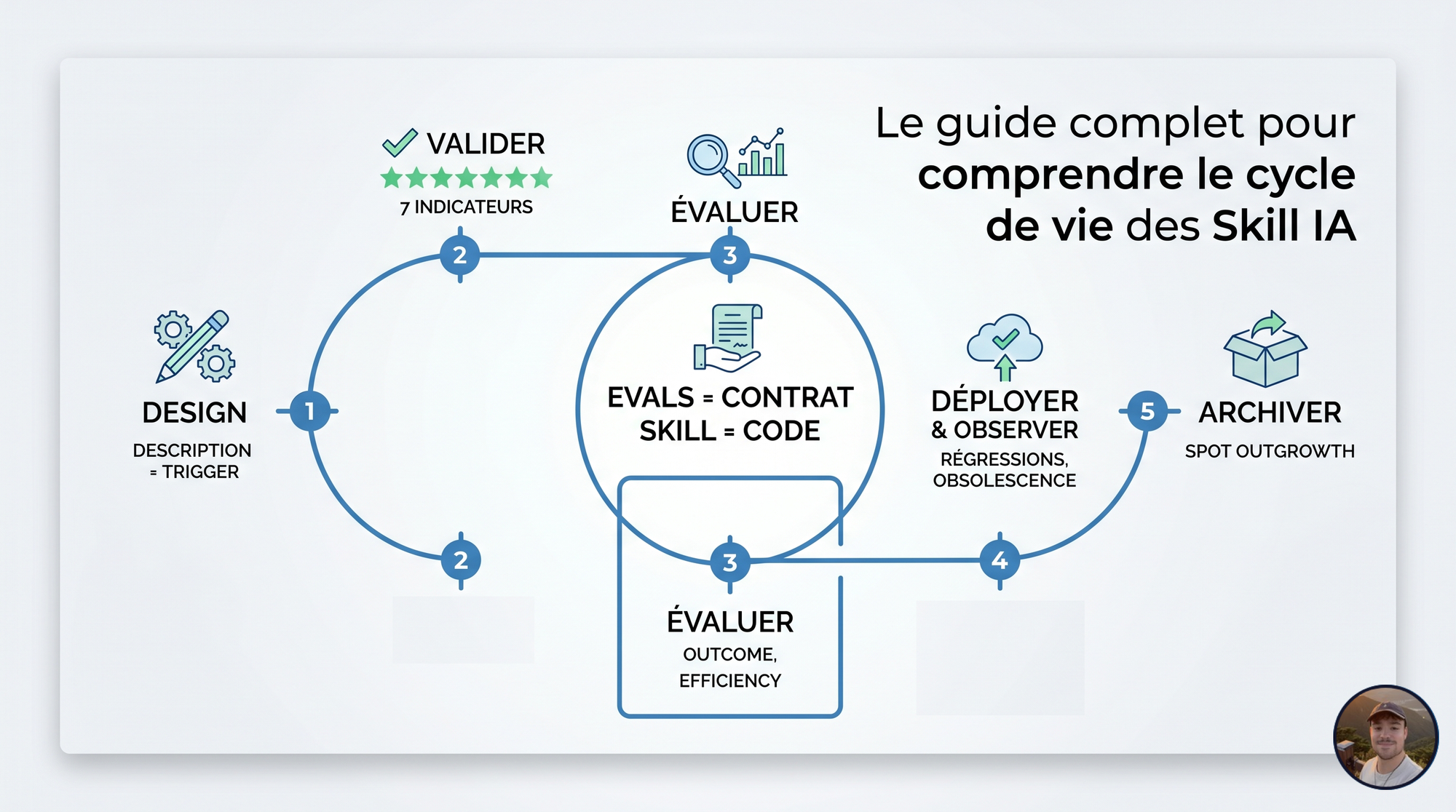
Le constat est simple ! Si vos skills sont du code, traitez-les comme du code. Design, validation, évaluation, archivage. C'est ce que permettent les evals.
Ce qu'est un skill, vraiment
Un skill, c'est un dossier. À sa racine : un fichier SKILL.md. Ce fichier contient un en-tête YAML (le frontmatter) suivi d'un body en Markdown. L'en-tête dit quand utiliser le skill. Le corps dit comment faire le travail.
Le format est un standard ouvert, né chez Anthropic, disponible en open source sur agentskills.io, adopté par Claude Code, GitHub Copilot, Cursor, Mistral, OpenAI Codex, Gemini CLI, Goose et la plupart des outils agentiques actuels. Considérez les skills comme des packages npm de l'écosystème agentique.
Le mécanisme central a un nom compliqué mais une explication simple. Il s'appelle la divulgation progressive. Les agents chargent les skills en trois temps.
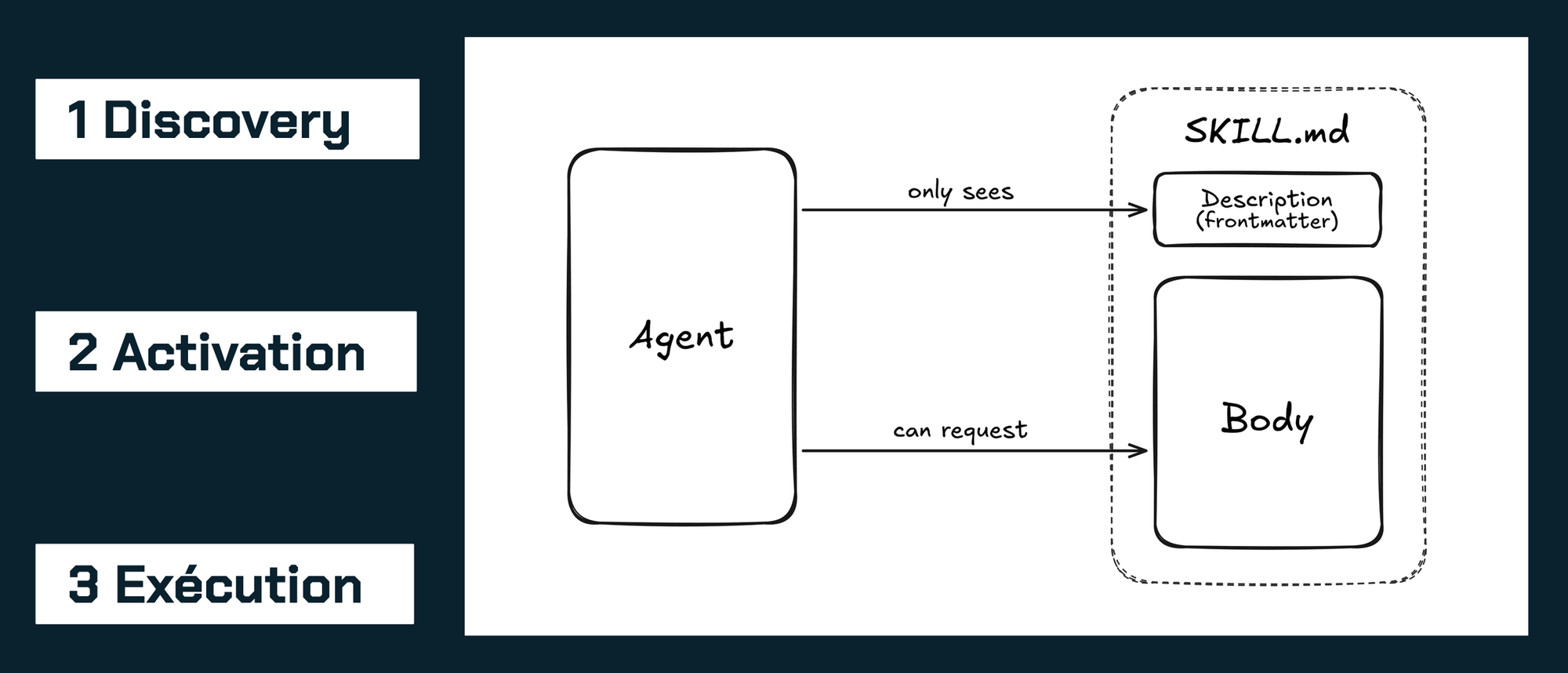
À la découverte, l'agent ne lit que name et description de chaque skill, ce qui équivaut à une centaine de tokens par skill.
À l'activation, quand une requête matche un frontmatter, le corps complet du SKILL.md est injecté.
À l'exécution, scripts, templates et références sont chargés à la demande.
C'est ce mécanisme qui permet de maintenir des dizaines de skills sans exploser le contexte. La pollution existe, mais elle est limitée : seul le skill actif coûte des tokens.
Conséquence directe : l'agent ne lit jamais le corps au moment du choix du skill. Il ne voit que la description. La description n'est donc ni un commentaire, ni de la doc. C'est le trigger. La majorité des skills qui "ne se lancent jamais" n'ont pas un problème de code. Elles ont un problème de description.
Deux catégories de skills
Anthropic distingue deux types de skills, parce qu'elles vieillissent différemment.
Les capability uplift skills apprennent à l'agent quelque chose qu'il ne fait pas bien seul : extraire des tableaux d'un PDF, générer un Word respectant un template. Ils vieillissent vite. Ce qu'un modèle ne sait pas faire en 2024 peut être intégré nativement en 2026.
Les encoded preference skills ne lui apprennent rien de nouveau, le modèle connaît déjà chaque étape. Mais ils séquencent ces étapes selon votre process.
Ils sont durables : ils vivent tant que votre process vit.
Les deux ont besoin d'evals, pour des raisons opposées : détecter l'obsolescence côté capability uplift, vérifier la fidélité au workflow côté encoded preference.
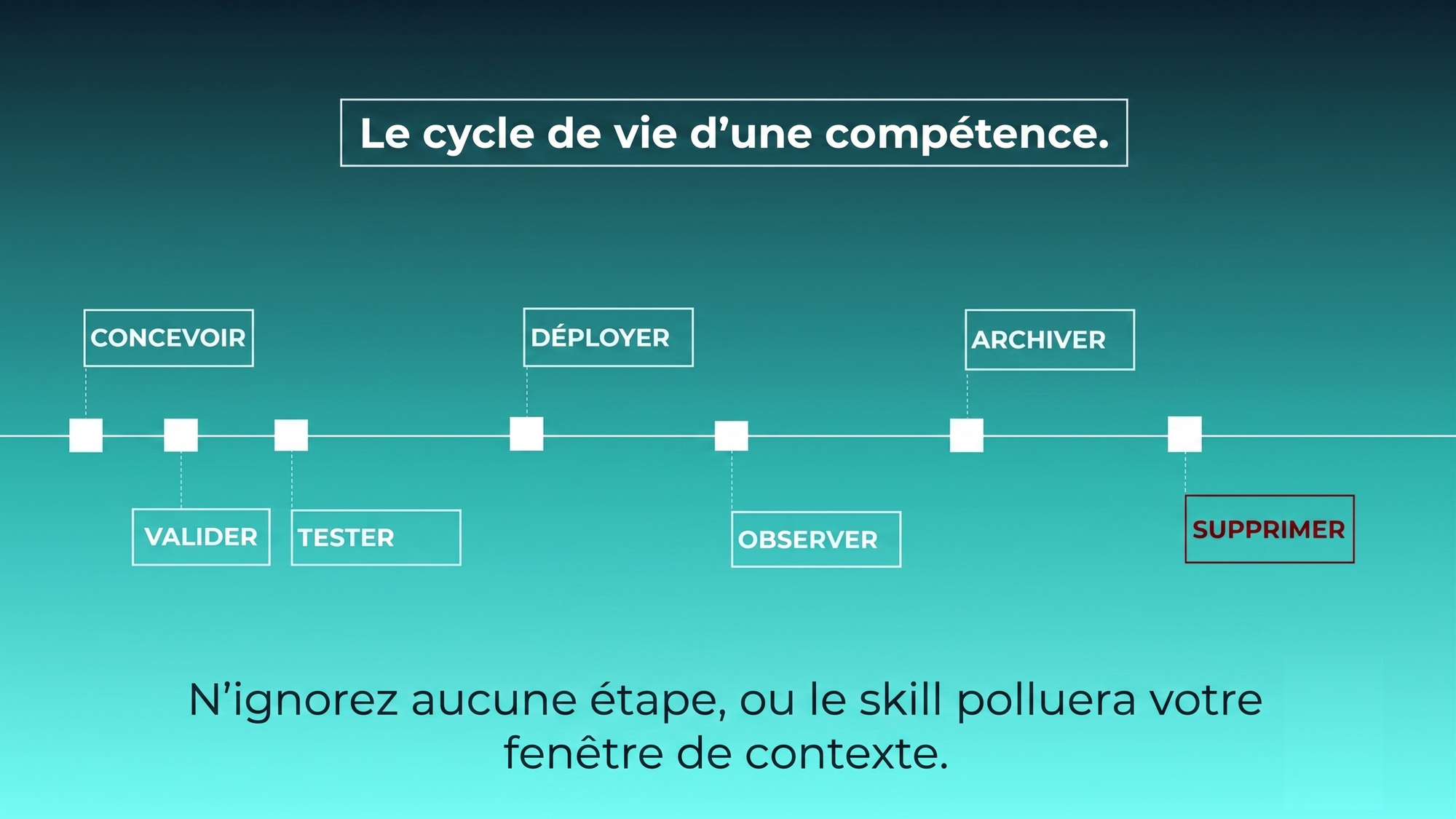
Un skill a un cycle de vie : design, test, déploiement, observation, archivage, suppression. Sauter une étape, c'est garantir le skill rot : des dossiers qui s'empilent, des descriptions qui polluent la découverte.
Concevoir un skill
La mauvaise entrée, c'est de commencer par le body. Le beau Markdown, les étapes bien formatées. Ça semble naturel et c'est exactement à l'inverse.
Il faut commencer par la description. Dites ce que fait le skill, quand l'utiliser, et surtout quand ne pas l'utiliser.
L'astuce, c’est d’imaginer le prompt que l'utilisateur taperait s'il pouvait appeler directement votre skill. Mettez ces mots dans la description.
Ensuite expliciter les hypothèses cachées avant que le modèle ne les découvre à l'exécution. Il y a trois familles à interroger :
- Les hypothèses de trigger : quels prompts doivent matcher, et surtout, lesquels ne doivent pas matcher?
- Les hypothèses d'environnement : le skill suppose un dossier vide, un gestionnaire de paquets précis, un accès réseau? Écrivez-le, et vérifiez-le depuis le skill avant de lancer du vrai travail.
- Les hypothèses d'exécution : dépendances déjà installées, ordre des étapes ? Les bugs vivent entre “le modèle sait quoi faire ensuite” et “le modèle sait ce qui vient avant”.
Ensuite seulement, écrivez le body. On veut des étapes numérotées. Des directives, pas d'information. “Utilise toujours method()” fonctionne mieux que “La method() est recommendée”. Le modèle obéit mieux qu'il ne comprend.
Valider un skill
La validation se place entre le design et l'évaluation : ce skill est-elle suffisamment propre pour mériter un vrai test ?
C'est une étape humaine, une quality gate. Sept indicateurs à vérifier :
- Frontmatter complet et précis.
- Description qui se lit comme un trigger, pas comme un commentaire.
- Section “quand appliquer” avec triggers et anti-triggers dans le corps.
- Méthodologie structurée avec étapes numérotées. Aucun TODO.
allowed-toolsréduit au strict nécessaire : un skill qui ne fait que lire
des fichiers n'a pas besoin d'autorisations bash.- Format de sortie documenté.
- Single responsibility : un skill, un domaine.
Cette liste ressemble à celle d'un package bien conçu ! API publique claire, minimum de périmètre, pas de dead code, le moins de privilèges possibles, un output défini.
Évaluer un skill
Une eval pour un skill n'est pas un benchmark. C'est un test simple, ciblé, reproductible.
Quatre éléments : un prompt, un run (la trace de l'agent et les artefacts produits), un ensemble de checks, un score comparable dans le temps.
Définir le succès
Avant d'écrire la moindre eval, définissez ce que "réussi" veut dire. Pour cela, il y a quatre dimensions à avoir en tête :
- L'outcome : la tâche est-elle complète ? L'app tourne-t-elle ?
- Le process : l'agent a-t-il invoqué le bon skill, suivi les bons outils, touché les bons fichiers ?
- Le style : la sortie respecte-t-elle vos conventions, vos imports, votre nomenclature ?
- L'efficiency : l'agent y est-il arrivé sans rejouer trois fois la même commande, sans brûler dix fois les tokens nécessaires ?
L'efficiency est la dimension la plus sous-évaluée. Deux runs peuvent produire la même sortie correcte. L'un consomme 3 000 tokens, l'autre 12 000. C'est une régression invisible dans le run, visible uniquement dans la trace.
Un test set complet
Pas besoin de milliers de prompts ! Dix à vingt suffisent pour un skill. Démarrez petit et enrichissez sur les échecs réels : chaque fois qu’un utilisateur rencontre un problème avec le skill, ajoutez le prompt.
Quatre catégories à couvrir :
- Invocation explicite : le prompt nomme le skill.
- Invocation implicite : le prompt décrit le scénario sans nommer le skill.
- Invocation contextuelle : du bruit autour de la requête, plus proche de la
réalité. - Contrôle négatif : prompts qui ne doivent pas déclencher le skill.
Le grading en trois couches
Les graders déterministes
Rapides, reproductibles, ils lisent la trace de l'exécution du prompt (souvent un flux JSONL d'événements) et répondent à des checks par oui ou non.
L'agent a-t-il lancé npm install ? package.json est-il sur disque ? Les imports utilisent-ils le bon SDK ? Le code appelle-t-il method() plutôt que la méthode dépréciée ?
C’est souvent du regex, quelques vérifications d'existence de fichiers, quelques dizaines de lignes de Node ou Python. L’équivalent des tests unitaires : tout ce qui peut être déterministe doit être écrit.
Le LLM-as-a-Judge
Les graders déterministes ont un plafond. Ils répondent à “est-ce que les basiques sont là”, pas à “est-ce que c'est fait comme je voulais”.
Pour le qualitatif, on renvoie l’output à un modèle qui note la sortie contre une rubric (un ensemble d'instructions ou de règles).
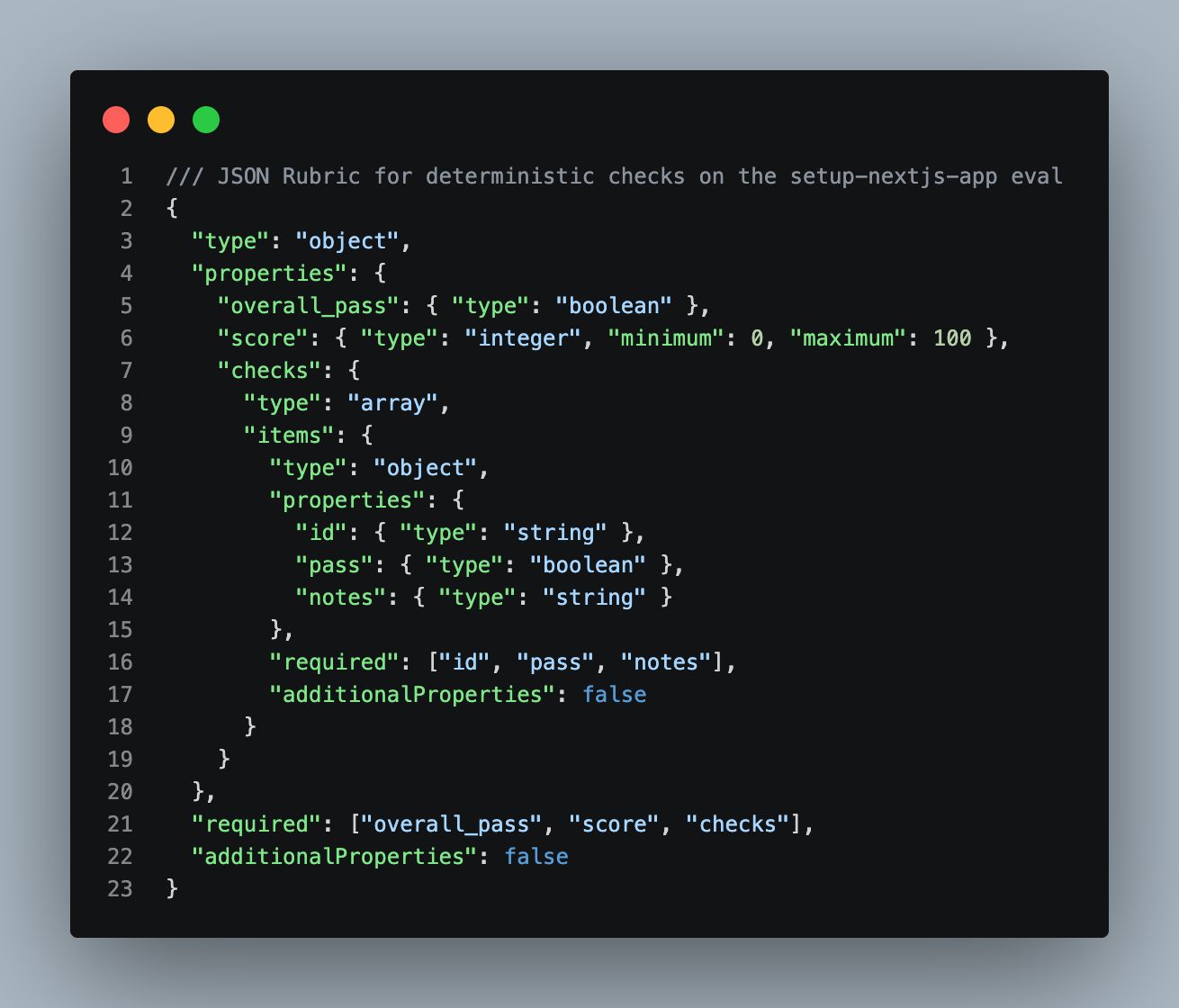
Deux règles impératives : imposez un schéma JSON précis pour pouvoir agréger et tracer ; exécutez le LLM juge trois à cinq fois et regardez la distribution, car le juge est lui aussi non déterministe. Serrez la rubric pour limiter la dérive.
Les checks avancés
D'autres vérifications sont possibles pour aller plus loin :
- Compter le nombre de commandes exécutées pour détecter le thrashing.
- Lire le nombre de tokens en entrée et en sortie pour traquer la dérive de prompts entre les versions.
- Lancer une analyse statique (
npm run build) pour attraper les imports cassés. - Vérifier
git status --porcelain. - Lancer un
curlau serveur.
Chaque vérification est plus couteuse que le précédent. N'ajoutez que celles qui couvrent un risque réel.
Quelques principes structurants pour ces tests avancés :
- Un comportement par test.
- Inclure les cas limites.
- Définir le succès d’un test précisément.
- Seuil de passage initial à 80 %, à monter pour les skills critiques.
- Graduer des résultats et pas des chemins.
- Plusieurs essais par cas.
- Isolation entre runs.
- Tester le skill dans chaque harness qui le consomme car le même skill peut se comporter différemment dans Claude Code et dans Copilot.
Graduer vos evals
Un skill neuf passe peut-être à 60 ou 70 % sur toutes ces couches. C'est
normal. Vos evals vous donnent une montagne à gravir. Une fois gravie, elles
changent de rôle : de capability evals en regression evals. Mêmes tests,
nouveau contrat.
Les solutions toutes faites
Bonne nouvelle ! Vous n'avez pas à partir de zéro. Deux références directement utilisables.
Du côté de Claude Code : Anthropic propose un Evaluation Tool intégré nativement. L'outil vous force à sortir du vibe check en vous demandant de définir des variables dynamiques ({{variable}}), de générer des jeux de tests et de lancer des comparaisons side-by-side. La plateforme intègre un système de notation qualitative (échelle 1 à 5) pour suivre l'évolution des performances et gérer le versioning de vos prompts.
Du côté de GitHub Copilot : le skill open-source officiel agentic-eval/SKILL.md est un cas d'école. Il montre comment orchestrer des boucles de réflexion (Generate → Evaluate → Critique → Refine), comment coder des fonctions de notation basées sur des rubrics pondérées, et fournit une checklist pour implémenter des pipelines d'optimisation.
Interface managée ou approche déclarative : l'objectif est identique, c'est automatiser votre suite de tests.
Archiver un skill
La plupart des équipes écrivent des skills et oublient de les supprimer. Les vieux skills s'empilent dans **/skills/, consomment des tokens de découverte, brouillent le routage. C'est la même pollution que le code mort ou que les fonctions commentées qu'on n'enlève jamais.
Il existe deux patterns importants pour savoir quand archiver :
- Catch regressions : le skill marchait il y a un mois, le modèle a été mis à jour, elle se comporte autrement. Sans evals, vous le découvrirez via un incident en prod. Avec une eval programmée, vous le verrez au prochain run.
- Spot outgrowth : vous avez écrit un skill capability uplift en 2025 pour combler un gap. En 2026, le modèle gère ça nativement. Le test est tout simple ! Relancez l'eval avec le skill désactivé. Si l'agent passe quand même, le modèle a absorbé le skill. Archivez-le.

Une dernière checklist avant d’archiver le skill :
- Lancer l'eval sans le skill.
- Vérifier la date de dernière activation.
- Pour les encoded preference skills : contrôler que le process explicité n'a
pas changé. - Déplacer vers
archive/avec une note datée avant suppression définitive.
Les deux patterns reposent sur le même instrument. L'eval.
Bonnes pratiques et regard vers l'avenir
Les skills sont du code. Ce tableau le rend explicite.
Aujourd'hui, un SKILL.md est un plan d'implémentation : il dit au modèle comment faire, étape par étape. Mais regardez ce que contiennent vos evals : des prompts qui doivent déclencher, des artefacts attendus, des conventions à respecter, des prompts à ignorer, un budget d'efficience. Vos evals décrivent déjà le what. Elles sont silencieuses sur le how. C'est exactement la forme d'une spécification, ou d’un contrat !
Dans l'histoire du logiciel, chaque fois qu'on passe de “dis à la machine comment” à “dis à la machine quoi”, les capacités augmentent et la friction tombe. Exemple: les scripts impératifs ont cédé à l'infrastructure déclarative. Le SQL artisanal a cédé aux query planners.
À mesure que les modèles deviennent meilleurs (si on en croit la force de Fable, ou Mythos), le how migre dans le modèle. La majorité des capability uplift skills deviendront superflues. Beaucoup d'encoded preference skills se réduiront à un paragraphe avec simplement l’intention, quelques sorties d'exemple, et un test set qui asserte les contraintes.
Le body du skill rétrécit. L'eval reste!
Aujourd'hui, l'eval vérifie le skill. Demain, l'eval pourrait être le skill. La description du succès suffisamment précise pour qu'un modèle suffisamment fort en devine l'implémentation.
Écrire des evals aujourd'hui n'est donc pas qu'un acte de qualité. C'est un investissement.
Arrêtez de deviner si vos agents fonctionnent : mesurez !
Sources et lectures complémentaires
Pour aller plus loin sur le cycle de vie et l'évaluation des compétences des agents IA, voici les ressources et standards qui ont inspiré ce guide :
- [Anthropic Claude Blog] Improving Skill Creator: Test, Measure, and Refine Agent Skills > Le framework initial sur la création et le raffinement des compétences.
- [Blog Ippon - Gokhan Kabar & Djamel Bougouffa] Spec-Driven Development (SDD) : de la spécification au code avec l’IA (exemple complet avec Kiro) > Une exploration concrète de la bascule du "comment" vers le "quoi", où les spécifications et exigences formalisées deviennent l'artefact de vérité pilotant l'IA.
- [Blog Ippon - Hippolyte Durix] Du PDD au multi-agent : mon premier REX avec Liza > Un retour d'expérience terrain montrant comment un cadre "Craft" et des skills bien rodés sont indispensables pour alimenter un système multi-agent autonome capable de s'auto-corriger.
- [OpenAI Developers] Eval Skills & Agentic Frameworks > La vision d'OpenAI sur la standardisation des évaluations de skills.
- [Philipp Schmid] Testing AI Agent Skills in Production > Guide pratique et technique pour mettre en place des tests automatisés.
- [ArXiv Research] Evaluation and Lifecycles of Agentic Skills > La publication scientifique de référence détaillant les patterns de régression et d'obsolescence (outgrowth).
- [Ultimate Claude Code guide Bruniaux] Learning Path: Skill Lifecycle & Open Standards > Le guide méthodologique sur le standard ouvert SKILL.md et les principes de divulgation progressive.
- [Anthropic Docs] Using the Evaluation Tool in Console > Le guide officiel pour concevoir des matrices de tests et grader quantitativement les réponses du modèle.
- [GitHub Awesome-Copilot] Official agentic-eval Skill Standard > L'implémentation de référence en standard ouvert pour concevoir des workflows de self-critique et de grading structuré en JSON.
