

Pas de surprise : on y était !
La Practice Mobile a de nouveau répondu à l'appel des conférences d’Android Makers édition 2026. Et comme toujours, on ne repart pas les mains vides, pour vous on a fait chauffer nos stylos (ou nos claviers) pour vous proposer une compilation des talks qui nous ont marqués.
Bonne lecture !
AI Agents Face-Off: Same App, Multiple Frameworks
Kotlin, React Native ou Flutter ? La question revient régulièrement dans la communauté mobile ainsi que dans les entreprises lors d’un démarrage de projet. Les comparatifs que l’on trouve habituellement sont presque toujours orientés en fonction de l'expertise technologique de leur auteur. Elaine, senior engineer chez SFEIR et Google Developer Expert pour Flutter, a décidé de prendre le problème à contre-pied : et si on retirait l'humain de l'équation pour confier la construction d'une même application à des agents IA ?

Le protocole
Pas question de comparer des "Hello World" un peu trop simples à concevoir. L'app choisie par Elaine est un vrai projet sur le papier : authentification Firebase, appels API avec autorisation, cache en base locale, filtres, vue carte avec marqueurs et bottom sheets, redirection vers YouTube… Bref, un cahier des charges réaliste avec tous les points de friction que cela implique. Et pour garantir l'objectivité, Elaine (qui maîtrise très bien l’Android natif et Flutter, mais un peu moins React Native) n'a apporté aucune expertise personnelle. Tout a été délégué à 100% aux agents, chacun recevant les mêmes inputs : les specs de l'app et des guidelines spécialisées générées à partir de projets open source de référence. trouvés sur Github. Enfin, pour comparer l’efficacité des différents outils IA sur le marché, Elaine a choisi trois agents différents : Claude Code, Gemini, Codex (initialement Junie dans la version 1).
Trois itérations, une progression fulgurante
L'expérience s'est étalée sur près d'un an. La V1 (juin 2025) a produit neuf apps en plusieurs semaines, avec douze heures allouées par technologie. La V2 (mars 2026), grâce à des specs retravaillées, des guidelines normalisées et des modèles plus récents, a vu certaines apps construites en moins de dix minutes, plus de la moitié des runs étant "one shot". Selon ses calculs, cela fait trois fois plus de projets en trois jours seulement. La V3 (avril 2026) pousse l'optimisation encore plus loin en intégrant les erreurs récurrentes détectées dans les V1 et V2 directement dans les instructions et en ajoutant un système de notation, système créé par un agent IA. Cela conduit à la création de neuf applications évaluées via un double système (technique : taille de l’apk, utilisation RAM, lignes de code, etc; et fonctionnel : fonctionnement des features), chaque évaluation étant confiée à trois agents différents pour éviter tout biais.
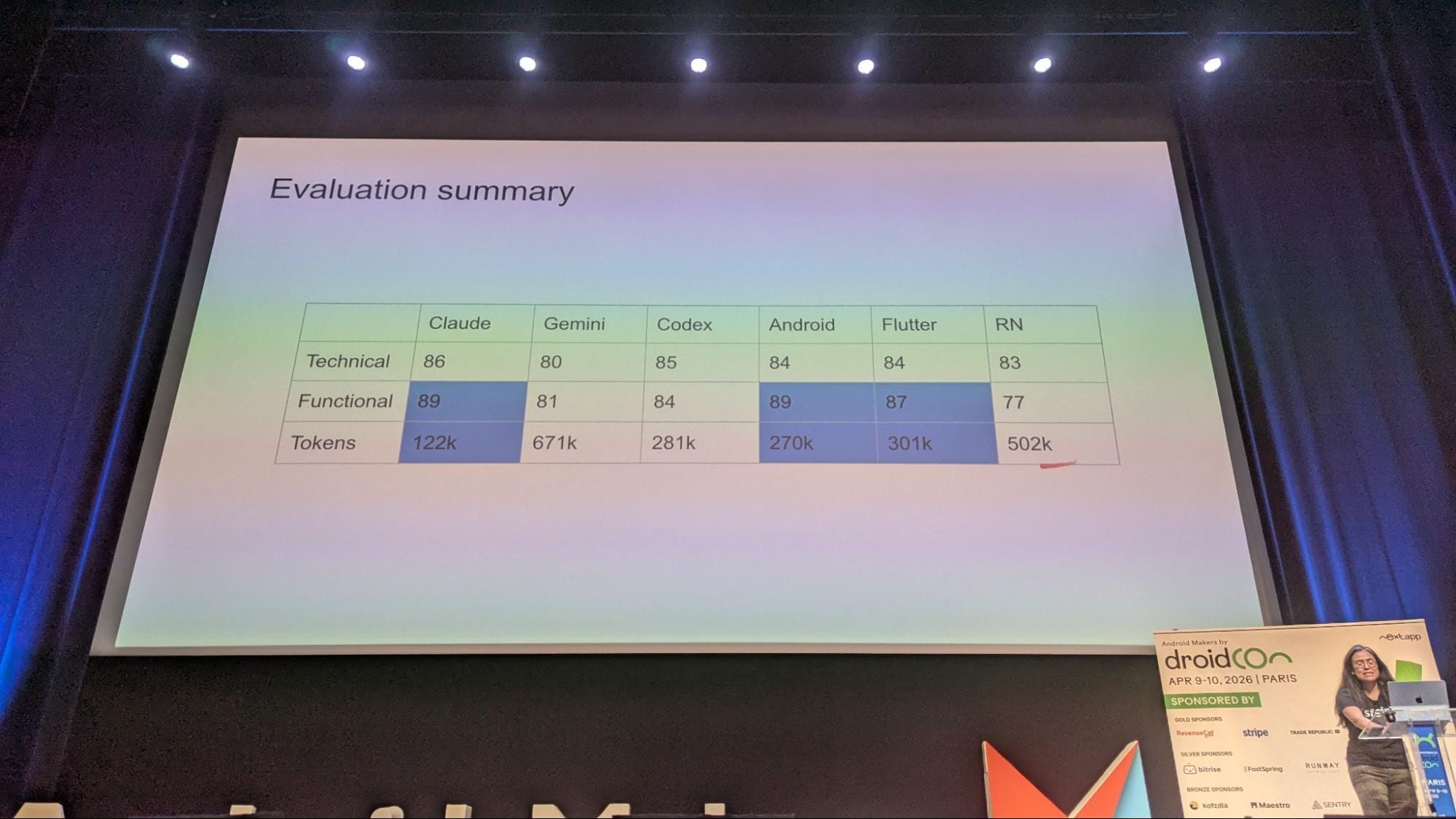
Ce qu'il faut en retenir
Pas de révolution dans la hiérarchie : le natif arrive en tête, devant Flutter et React Native. Mais la vraie leçon est ailleurs. Elaine confie que son intérêt s'est progressivement déplacé du comparatif de frameworks vers l'optimisation du travail avec les agents IA. La qualité des guidelines et des specs s'est révélée être le facteur déterminant, bien plus que le choix du framework lui-même.
Sa conclusion est simple : avec les outils disponibles aujourd'hui, n'importe quel développeur peut construire, tester et évaluer des solutions avec ses propres critères. Un bémol tout de même : six mois entre la V1 et la V2 ont suffi pour une accélération massive. Ces résultats ont donc une date de péremption assez courte et le futur réserve sûrement des (bonnes) surprises. À garder en tête.
Offline should be the norm: building local-first apps with CRDTs & Kotlin Multiplatform
par Renaud Mathieu
Cette conférence nous rappelle une réalité que l’on oublie souvent : il y a de nombreuses situations où le réseau nous fait défaut et cela signifie, la plupart du temps, des applications mobiles inutilisables. Alors qu’il existe des solutions pour garantir le service de nos applications même en mode hors ligne, en présentant des données locales immédiatement et en synchronisant les changements de manière transparente dès le retour de la connexion.
Une architecture robuste centrée sur la donnée
Il faut obligatoirement pouvoir compter sur une Single Source Of Truth (SSOT). C’est la source locale (base de données SQLite/Room, DataStore, etc.) qui devient l'unique référence pour l'UI. La couche UI ne communique jamais directement avec le réseau. Pour éviter un couplage fort, il préconise d'utiliser trois modèles de données distincts : un pour le réseau, un pour l'entité locale et un pour le domaine. Bien que cela génère du boilerplate, cette séparation a pour objectif de protéger les couches externes des changements mineurs dans les sources de données.
Stratégies de lecture et d'écriture
Lectures réactives : Utilisez des types observables comme Flow. Le Repository observe la base locale et émet une nouvelle valeur dès qu'une mise à jour (réseau ou locale) survient.
Écritures asynchrones : Utilisez des fonctions asynchrones suspend. L’écriture étant une partie sensible dans une app offline-first, il faut donc choisir la stratégie d’écriture la mieux adapter à nous besoin :
- Online Only : L'écriture n'est tentée que via le réseau. En cas d'échec, l'UI doit bloquer l'action ou afficher une erreur explicite.
- File d'attente : L'objet à écrire est inséré dans une file gérée par un outil comme Work Manager. La file est vidée progressivement dès que le réseau revient.
- Local-first avec CRDT : C'est la stratégie la plus complexe mais la plus fluide. On écrit d'abord localement, puis on synchronise en arrière-plan dès que possible. C'est ici que les CRDT interviennent pour résoudre les conflits de manière mathématique et automatique lors de la fusion avec les données du serveur.
Stratégies de Synchronisation : Pull vs Push
Le passage d'une application en offline-first nécessite de choisir comment réconcilier les données locales avec le serveur dès que la connexion avec le réseau est rétablie.
Synchronisation Pull-based (à la demande) : L'application contacte le réseau pour lire les dernières données uniquement lorsqu'elle en a besoin.

Synchronisation Push-based (proactive) : La source locale tente de répliquer la source réseau le plus fidèlement possible. L'application télécharge un volume important de données au premier lancement, puis s'appuie sur des notifications serveur pour savoir quand les données locales sont périmées.

Résolution de conflits : La puissance des CRDT
Le plus grand défi auquel nous pouvons être confrontés lorsque l’on met en place un mode hors-ligne est le conflit de données, et c'est là que les **CRDT (Conflict-free Replicated Data Types) **interviennent. Fondées sur des propriétés algébriques (commutativité, associativité, idempotence), ces structures de données garantissent que tous les appareils convergeront vers le même état final, quel que soit l'ordre de réception des mises à jour, sans intervention manuelle.
Delta-state CRDTs : L'optimisation consiste à n'envoyer que les changements récents (deltas) plutôt que l'état complet, préservant ainsi la batterie et la bande passante.
Types courants :
- G-Counter : un compteur à incrémentation simple. Chaque replica comptabilise ses propres incréments, et le total correspond à la somme de tous les incréments des replica. A utiliser pour des éléments tels que le nombre de vues ou de likes
- G-Set : un ensemble qui ne peut que s'agrandir. On peut y ajouter des éléments, mais on ne peut jamais en supprimer. Cela peut sembler restrictif, mais c'est parfait pour les logs ou les événements en mode lecture seule.
- OR-Set : ajoute et supprime, en privilégiant les ajouts en cas de conflit.
- LWW-Register : la dernière écriture gagne, à utiliser pour les champs simples.
L'avantage de Kotlin Multiplatform (KMP)
Le moteur de synchronisation et la logique des CRDT sont complexes et critiques. KMP permet de partager ce code entre Android, iOS et le Web. Cela garantit une logique de convergence identique sur toutes les plateformes et facilite grandement les tests unitaires de cette logique complexe.
Points à retenir
- Écrire localement, puis synchroniser en arrière-plan.
- Les CRDT garantissent la convergence grâce à leur conception mathématique.
- Delta-state CRDT est le meilleur compromis pour le mobile.
- KMP permet de partager cette logique entre toutes les plateformes
- Les défis concrets (tombstones, pruning, UI glitch) ont des solutions connues
- Résultat : une application fiable même en l'absence de réseau
Note : Pour approfondir, consulter le projet "Now in Android" de Google pour l'architecture et les travaux de l'INRIA (2011) sur les CRDT.
From beats to bytes : what music production can teach about programming ?
par Benjamin Gonin
Si vous pensez que coder une application et composer un morceau de musique sont deux mondes opposés, détrompez-vous.
Benjamin Gonin (développeur Android et producteur de musique) a animé un talk original où à travers son expérience avec son application musicale Omasa, il a mis en lumière les parallèles frappants entre ces deux disciplines.
Le but est de comprendre comment les processus créatifs de la musique peuvent faire de nous de meilleurs programmeurs.
Le miroir parfait
La première révélation de ce talk, c'est à quel point nos outils et nos cycles d'itération se ressemblent. Jugez plutôt :
| Développement | Musique |
|---|---|
| IDE (Environnement de dev) | DAW (Station de travail audio) |
| Langage de programmation | MIDI |
| Debugging | Mixage |
| Principes de code (Clean code) | Théorie musicale |
| Architecture | Arrangement |
| Bibliothèques & Packages | Banques de samples |
| Mise en production (Shipping) | Mastering |
| Code → Test → Refactoring | Maquette → Écoute → Ajustement |
Les 4 leçons clés à appliquer dans votre code
Pour Benjamin, tout part d'une idée fondatrice. Que ce soit pour une feature ou un refrain, la question primordiale est : "Quelle est mon intention ?". À partir de là, voici les principes à retenir :
- Les contraintes boostent la créativité
Les limites techniques ne sont pas vos ennemies. Tout comme le tempo ou la tonalité guident un musicien, les restrictions obligent le développeur à innover.
- Le chaos est l'ennemi de l'art
Une organisation stricte est indispensable. La règle d'or ? Demandez-vous toujours : "Si je rouvre ce projet dans 6 mois, est-ce que ce sera compréhensible ?" Des fondations solides valent toujours mieux qu'une quête immédiate de perfection.
- La règle du 90/10
Les détails et les transitions sont cruciaux. Ces 10 % de polish final (finitions, animations subtiles, gestion des erreurs) représentent en réalité 90 % du ressenti de l'expérience utilisateur !
- La distribution est une vraie guerre
Publier du code ou un morceau est devenu facile. Mais obtenir de vrais utilisateurs (ou auditeurs) et les fidéliser (la rétention) reste le test ultime. Le shipping est une compétence à part entière.
Que retenir du talk ?
La grande conclusion de cette conférence est porteuse d'espoir : la créativité paie toujours. L'itération, le raffinement et l'approche artistique de la résolution de problèmes sont des compétences profondément humaines que l'intelligence artificielle ne peut pas répliquer.
Alors la prochaine fois que vous ouvrirez votre IDE, n'oubliez pas que vous n'êtes pas seulement en train de taper du code, vous êtes en train de composer votre prochaine œuvre.
Automatiser ce que tu répètes : du boilerplate à l'automatisation
par Julien Bajon
On connaît tous cette petite voix intérieure qui soupire quand il faut créer, pour la énième fois, la même structure de fichiers, les mêmes classes, le même squelette de feature. Le speaker est parti d'un constat simple et universel : sur un projet multi-modules avec des conventions architecturales strictes, créer une nouvelle feature MVI, c'est environ six fichiers quasi identiques à écrire. Multiplié par 39 features dans son projet, cela fait 234 fichiers de boilerplate. Autant de copier-coller, autant d'occasions de se tromper, autant de temps qui ne sert ni au produit, ni aux utilisateurs. Sa conférence raconte comment il a transformé cette répétition en deux outils d'automatisation maison, pragmatiques et immédiatement utiles.
Premier chantier : un plugin Gradle pour scaffolder une feature MVI
La première réponse, c'est un template. Mais pas n'importe lequel : un plugin Gradle embarqué en composite build. Le choix est assumé et plutôt malin : pas de publication sur un repo interne, pas de configuration alambiquée. Un nouveau développeur clone le projet, et le plugin est immédiatement disponible. Ça marche, tout simplement.
Le plugin expose une tâche generateFeature avec deux modes d'utilisation :
--modulecrée un module Gradle autonome dansfeatures/, avec sonbuild.gradle.kts, son State, ses Events, ses Actions, son ViewModel, son Screen et son Module d'injection de dépendances.--pathgénère la même feature, mais dans un dossier existant quand on ne veut pas ajouter un nouveau module.
Le résultat est sans appel : environ trois secondes pour tout générer, zéro copier-coller, et une feature 100% conforme aux conventions du projet. La démo live est parlante : une commande, sept fichiers créés, le settings.gradle.kts mis à jour automatiquement, et c'est prêt.
Deuxième chantier : générer le client API depuis la spec OpenAPI
La deuxième automatisation répond à une douleur que beaucoup connaissent : le backend fait évoluer son API, et il faut une fois de plus modifier à la main des dizaines de fichiers côté mobile. Le speaker s'attaque donc à un générateur de client API Kotlin à partir de la spec OpenAPI.
Avant de coder quoi que ce soit, il regarde l'existant. OpenAPI Generator ? Il essaie, mais se heurte à un mur : sa spec contient du polymorphisme dans les inputs (des oneOf), et OpenAPI Generator ne le supporte pas proprement. Swagger Codegen ? Même souci, et un outil qui commence à dater. La conclusion s'impose : les solutions génériques ne couvrent pas son cas. Il va le faire lui-même.
Le pipeline tient en quatre étapes :
Spec OpenAPI (yaml) → Parse (SnakeYAML) → Group (Tags OpenAPI) → Generate (KotlinPoet) → Client Ktor (.kt)
La première étape transforme 7000 lignes de YAML en un arbre Kotlin entièrement typé grâce à SnakeYAML. Chaque Schema.Object est modélisé proprement :
Schema.Object(
name = "OrderDto",
properties = mapOf(
"id" to Property("id", StringType),
"status" to Property("status", EnumType(
"waiting_for_payment", "persisted", ...
)),
"items" to Property("items", ArrayType(
OneOf("OrderItemV1Dto", "OrderItemV2ArticleDto")
))
)
)La deuxième étape regroupe tout par domaine métier en s'appuyant sur les tags OpenAPI : un tag = un package Kotlin. L'arborescence du code généré reflète directement la structure fonctionnelle de l'API.
La troisième étape, la génération, utilise KotlinPoet. Chaque schéma devient une data class. Le polymorphisme est résolu élégamment : pour chaque oneOf, il crée un OneOf group qui agrège la liste des bodies possibles, et produit en sortie une sealed interface qui couvre tous les cas. Côté endpoints, un endpoint Ktor = une interface + son implémentation, que le code applicatif appelle directement.
Le résultat : il suffit de pointer le générateur sur la spec OpenAPI, et toute la couche API est régénérée automatiquement, typée, et cohérente.
Ce qu'il faut retenir
Trois idées fortes ressortent de ce talk, et elles dépassent largement le cadre Android :
- Les solutions génériques ne sont pas toujours la bonne réponse. Parfois, le meilleur outil c'est la solution, celle taillée exactement pour ton contexte. Quelques jours de dev bien investis valent mieux qu'un outil générique qu'on doit contourner en permanence.
- Investir dans le Developer Experience paie vite. Ce qui coûte quelques jours en amont se rembourse en sérénité sur toute la durée du projet : moins d'erreurs, moins de revues de code pour du boilerplate, un onboarding plus rapide pour les nouveaux arrivants.
- Automatiser ce qui est stable et répétitif, garder la main sur ce qui est variable. C'est la ligne directrice : le template MVI et la couche API changent peu dans leur structure, donc on les génère. La logique métier, elle, reste écrite à la main, là où l'intention du développeur compte vraiment.
Une conférence très concrète, qui donne furieusement envie de regarder son propre projet et de compter combien de fois on a écrit la même chose sans s'en rendre compte.
Koin + Kotlin Compiler = ♥️
par Arnaud Giuliani
Arnaud, le créateur de la bibliothèque d’injection de dépendances Koin nous a présenté en détail les nouveautés apportés par la venue du plugin de compilation Koin, le Koin compiler.
Exit l’utilisation du processeur d’annotations KSP qui est à la fois plus lent et plus limité en termes de fonctionnalités qu’un plugin gradle.

Parmi les bonus apportés par ce nouveau plugin, le fait d’avoir un DSL plus sûr et plus simple à écrire : les définitions d’injections sont automatiquement vérifiées et simplifiées à la compilation. Le plugin est aussi compatible avec les annotations Koin, pour ceux qui préfèrent cette approche au DSL. Notons d’ailleurs que Koin est aussi compatible avec les annotations au format JSR-330, pour par exemple migrer depuis des frameworks comme Hilt. Le compiler plugin profite du compilateur kotlin K2 pour optimiser sa compilation, ce qui favorise la scalabilité de votre codebase. En revanche, il n’y a pas encore de support comme d’autres systèmes de build comme Bazel.
Arnaud nous a ensuite parlé du produit de son entreprise Kotzilla, une plateforme d’observabilité tout en un, qui est nativement crossplatform via la compatibilité complète avec KMP. La plateforme se base justement sur Koin et la suite d’injection pour fournir des stacks d’erreurs plus précises. Elle intègre l’IA avec par exemple une analyse automatique des erreurs et un serveur MCP à disposition de votre agent favori.
En bref, un super talk de la part d’un fondateur français, qui fournit une solution adoptée par 25% des applications Android de toute taille. Le replay sort bientôt, restez en alerte ! En attendant, vous pouvez déjà tester le plugin en suivant la documentation. Bon dev !
Teaching agents to pay : what devs need to know.
par Benjamin Smith
Dans ce talk, Benjamin Smith, nous explique une des futurs utilisations d’un agent IA : le e-commerce.
La question clé est : comment payer sans exposer les données de l'utilisateur. Benjamin nous présente l’emergence de plusieurs protocoles pour répondre à cela : L’ACP (Agent Communication Protocol) et L’UCP (Universal Commerce Protocol). Lancés fin 2025 / début 2026, ils permettent aux marchands d’exposer un endpoint standardisé pour déclencher le paiement. De plus, un autre protocole, le MPP (Machine Payments Protocol) gère les paiements pour l’utilisation d’outils ou de service spécifique.
Dans tous les cas, le mécanisme est le même : l'agent génère un jeton à usage limité (montant plafonné, date d'expiration), transmis au marchand, qui finalise la transaction via un processeur comme Stripe, sans que ni l'un ni l'autre ne voie jamais les coordonnées bancaires complètes.
Ce qui change, ce sont les taux de conversion, environ 4 fois supérieurs à une solution classique. De plus, la Gen Z utilise déjà à près de 50% l’IA comme point de départ d’un achat. L’agent IA empêche les abandons pendant les tunnels de paiement en limitant les frictions.
Pour éviter des erreurs, on n’envoie pas un agent parcourir le catalogue, c’est trop couteux en token. Il faut utiliser des endroits de recherche pour que l’agent envoie une requête ciblée, le site marchand renvoie ensuite les produits pouvant correspondre au besoin et l’agent affine ensuite avec l’utilisateur au fur et à mesure des interactions.
Enfin le speaker parle des persona, un enjeu éthique autant que technique.** **Le prompt système, les instructions cachées qui gouvernent le comportement de l'agent, est aussi stratégique que le code lui-même. C'est lui qui définit, concrètement, les valeurs de l'entreprise. Deux postures s'affrontent. L'agent honnête assume sa nature d'IA, respecte les refus de l'utilisateur et reconnaît sans détour quand il n'a pas le bon produit. L'agent malhonnête, lui, fabrique de la fausse urgence, se fait passer pour un humain et invente des informations pour forcer la vente. Le gain à court terme est illusoire : ce chemin mène à plus de litiges, plus de retours, et une marque durablement abîmée.
Build intelligent Android apps with Google's AI
par Jolanda Verhoef
Nouveaux modèles et AI Edge Gallery
Dans ce talk, Jolanda Verhoef nous montre comment on peut aujourd'hui créer des applications Android intelligentes avec Google AI. On a commencé par découvrir les nouveaux modèles Gemma 4 et Gemini Nano 4, tous les deux en early access via AICore.
On a aussi eu droit à la présentation de AI Edge Gallery, une application dispo sur le Play Store qui permet d'exécuter Gemma et d'autres LLM open-source directement en local sur son téléphone : https://play.google.com/store/apps/details?id=com.google.ai.edge.gallery
Côté performances, ces nouveaux modèles sont 4x plus rapides et consomment 60% moins de batterie. De nouvelles features arrivent également, notamment le Thinking mode qui va permettre à l'IA de raisonner step by step.

In-App Intelligence : quatre stratégies pour intégrer l'IA dans nos applications
On a ensuite vu comment Google structure l'intégration de l'IA dans nos applications. L'approche repose sur trois piliers :
- OS agentique
- Intelligence intégrée aux applications (In-App Intelligence)
- Productivité des développeurs.
Le talk s'est surtout concentré sur la partie In-App Intelligence, qui se découpe en quatre stratégies :
| Stratégie | Description |
|---|---|
| On-device inference | Les modèles tournent directement sur l'appareil de l'utilisateur via AICore, sans aucun appel serveur. Idéal pour le offline, la privacy et la réduction des coûts. |
| Hybrid inference | Combine l'inférence locale et cloud derrière une API unifiée via Firebase AI Logic. Le SDK gère automatiquement le fallback entre les deux selon la connectivité et la disponibilité du modèle. |
| Cloud inference | Exploite toute la puissance des modèles Gemini via les API cloud (Gemini Developer API ou Vertex AI) pour les tâches qui nécessitent des capacités supérieures à ce que le device peut offrir. |
| Agents in the cloud | Permet d'orchestrer des systèmes multi-agents côté serveur avec l'ADK (Agent Development Kit), où l'app Android devient un thin client qui communique via des protocoles de streaming bidirectionnels. |
On-device inference : exécuter l'IA sans réseau et sans coût additionnel
Via AICore et les ML Kit GenAI APIs, on a vu qu’on pouvait accéder à Gemini Nano à travers une couche système qui gère le modèle pour nous.
Pour le mode offline les données restent sur le device, et surtout : aucun coût additionnel lié à des appels API. Pour les applications qui fonctionnent dans des contextes réseau instables, ou pour les use cases sensibles côté privacy, le mode offline devient une nécessité qui maintenant est prise en compte.
Côté APIs, on a déjà accès à pas mal de choses : la Prompt API pour l'interaction textuelle, la Speech Recognition API pour le speech-to-text, et d'autres arrivent.
Et on ne se limite pas à Gemma. On a aussi vu LiteRT-LM, qui permet de choisir et de finetuner son propre modèle. Via son portail, on peut vérifier si un modèle est compatible avec le device ciblé avant de l'embarquer dans l'app. Cela permet de garder le contrôle sur le choix du modèle tout en restant on-device.
Hybrid inference avec Firebase AI Logic : une API unifiée entre le device et le cloud
On nous à introduit à Firebase AI Logic, un SDK qui combine l'on-device et le cloud derrière une seule API hybride. Le SDK qui décide quelle l'inférence s'exécute. Plus besoin de gérer la logique de fallback nous-mêmes. On peut définir un prefer mode pour contrôler le comportement :
| Mode | Description |
|---|---|
| PREFER_ON_DEVICE | Privilégie le local, bascule sur le cloud si besoin. |
| PREFER_ON_CLOUD | Privilégie le cloud, fallback local si hors ligne. |
| ONLY_ON_DEVICE | 100% local, aucune requête cloud. |
| ONLY_ON_CLOUD | 100% cloud, connexion obligatoire. |
Cloud inference : les API Providers et l'accès direct depuis le mobile
Pour les cas qui demandent plus de puissance, on a vu deux API providers côté cloud :
- Gemini Developer API: Pour des petites équipes, permet une itération rapide via Google AI Studio
- Vertex AI: Pour les enterprise, permet la scalabilité, disponibilité, contrôle de la localisation
Le Direct Mobile-to-Cloud API Access via Firebase permet de passer directement par Firebase pour atteindre les API providers, avec AppCheck activé par défaut pour vérifier que c'est bien un utilisateur légitime.

Agentic systems : orchestrer des agents depuis le cloud avec l'ADK
Google introduit l'ADK (Agent Development Kit) et le protocole AG-UI pour la communication entre les agents cloud et l'interface mobile. L'app Android devient un client léger qui communique avec un système agentique centralisé via des protocoles de streaming bidirectionnels (websockets, SSE). L'ADK permet d'orchestrer plusieurs agents, de partager des connaissances entre eux et de standardiser la communication avec l'UI mobile.
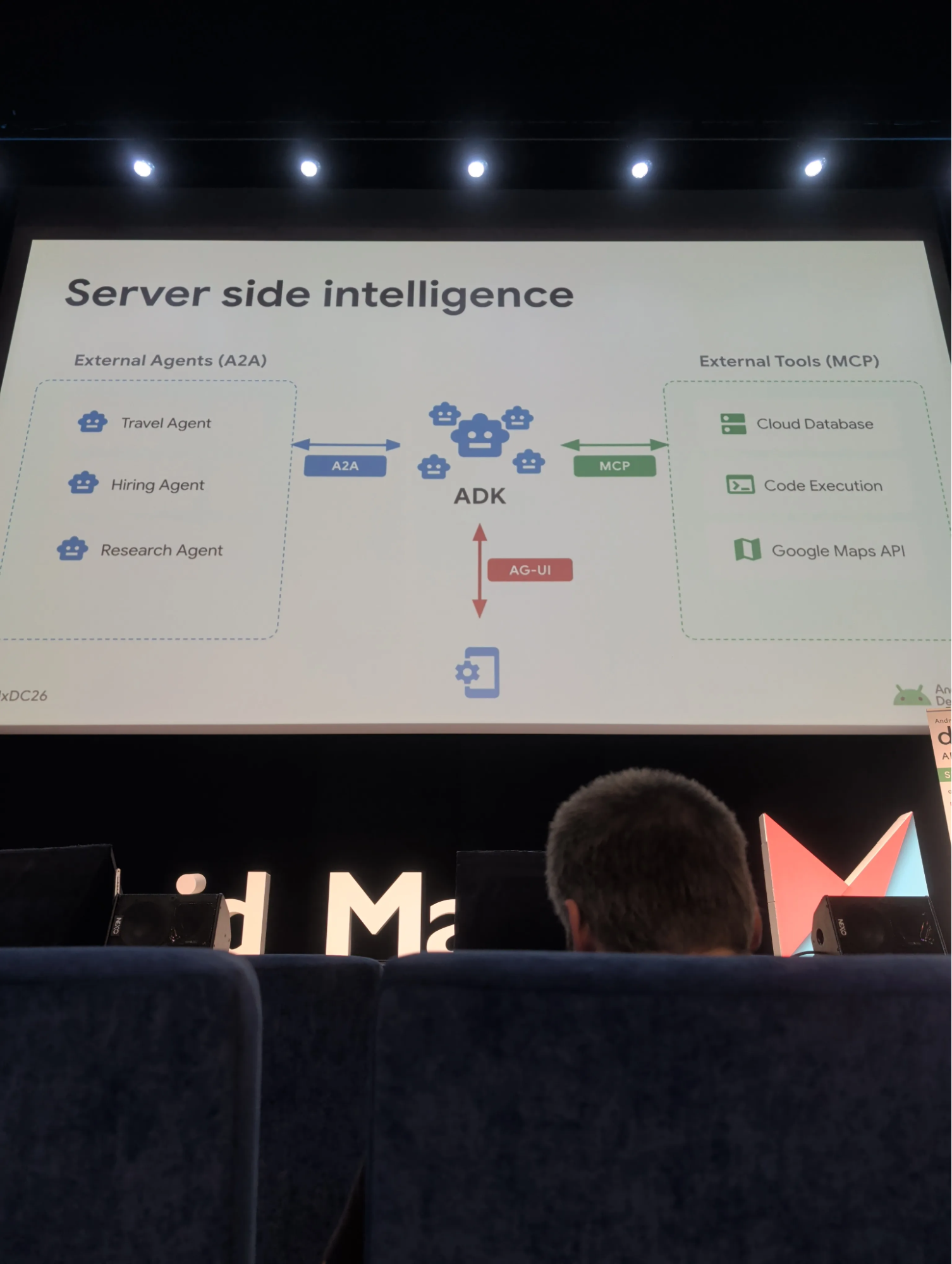
Ce talk donne une vision très claire de l'IA sur Android. Avec Firebase AI Logic et le système de prefer mode, on peut démarrer en full offline, ajouter le cloud quand c'est pertinent, et tout ça avec un seul SDK. également la documentation détaillée de tous les events par rapport aux différentes catégories permettant aux développeurs de créer des applications avec Google AI.

Conclusion
L'édition 2026 d'Android Makers a placé la barre haute! Entre l'ascension fulgurante de l’IA dans le mobile, la nécessité de construire des applications fiables grâce au Local-First et aux CRDTs, et l'arrivée en force des outils d'automatisation et d'IA On-Device de Google, le futur du développement mobile s'annonce passionnant.
N'oublions pas les leçons de créativité tirées de la production musicale et les avancées d'outils incontournables comme Koin Compiler. L'innovation est partout et le métier de développeur mobile n'a jamais été aussi riche et stimulant.
On se dit à l'année prochaine pour le prochain cru ! En attendant, on a hâte de mettre en pratique toutes ces nouvelles idées.





