
L’IA comprend. Mais elle n’agit pas.
Les agents IA sont désormais intégrés à nos IDE. Ils savent analyser du code, expliquer des erreurs, suggérer des refactors.
Mais dès qu’il faut exécuter une action réelle, la limite apparaît.
Dans les équipes, les capacités qui font vraiment gagner du temps, scripts internes, outils métier, générateurs, validateurs, services maison existent déjà. Elles sont robustes, éprouvées, parfois critiques. Mais elles vivent souvent à côté de l’IDE : dans un terminal, un service interne, une API, un outil historique.
Résultat : une boucle inefficace.
L’agent propose une action. On l’exécute ailleurs. On récupère une sortie textuelle. On la recolle dans le chat. Et au moindre problème, on repasse en debug manuel.
Le paradoxe est simple : l’IA comprend le contexte, mais n’a pas accès aux capacités d’exécution qui incarnent l’expertise de l’équipe.
Le Model Context Protocol (MCP) vise à combler ce fossé : proposer un standard pour exposer ces capacités qu’elles soient CLI, API ou services internes via un contrat structuré, directement consommable par un IDE ou un assistant IA.
L’idée derrière MCP : exposer des capacités, pas construire des intégrations
Quand une équipe veut “mettre son outillage dans l’IDE”, le réflexe classique est de construire un plugin (VSCode, JetBrains…), d’ajouter une UI, puis d’orchestrer l’exécution en arrière-plan. Ça peut marcher… mais on finit vite avec un second produit à maintenir : compatibilités, distribution, bugs, et surtout une logique qui finit par diverger de la source de vérité.
MCP inverse la posture : on ne part pas de l’interface, on part des capacités. Une capacité n’est pas “une commande” ou “un endpoint” ; c’est une action décrite comme un contrat : ce que ça fait, quels paramètres ça attend, ce que ça renvoie, comment ça échoue.
Le bénéfice est simple : au lieu d’implémenter une intégration par environnement, on expose des primitives stables une seule fois. Les hosts compatibles les consomment, et l’agent peut les enchaîner selon l’intention utilisateur sans orchestration figée dans un plugin.
MCP en une définition (et une architecture)
MCP décrit comment un host (IDE/app IA) peut se connecter à des serveurs qui exposent du contexte et des actions de manière uniforme. L’objectif n’est pas de vous imposer une UI, ni un framework d’agents, mais un contrat : le host découvre ce qui existe, puis lit et agit via des messages structurés.
MCP vs API REST : pourquoi ce n’est pas “juste une API de plus”
À première vue, MCP peut ressembler à une simple API JSON-RPC. Alors pourquoi ne pas exposer directement une API REST autour de votre CLI ?
La différence n’est pas dans le format des messages. Elle est dans le modèle d’intégration.
Une API REST expose des endpoints. MCP expose des capacités déclarées : tools, resources, prompts.
Avec REST :
- l’orchestration est écrite côté application
- le client est connu à l’avance
- rien ne standardise l’usage par un agent.
Avec MCP :
- le host découvre dynamiquement les capacités disponibles
- l’agent peut décider quelles actions enchaîner
- les réponses sont structurées pour être interprétables et replanifiables.
REST expose des services. MCP expose des actions exploitables par des agents.
Les deux sont complémentaires : REST peut rester votre API métier ; MCP devient la façade standardisée qui rend ces capacités pilotables depuis un IDE ou un assistant IA.
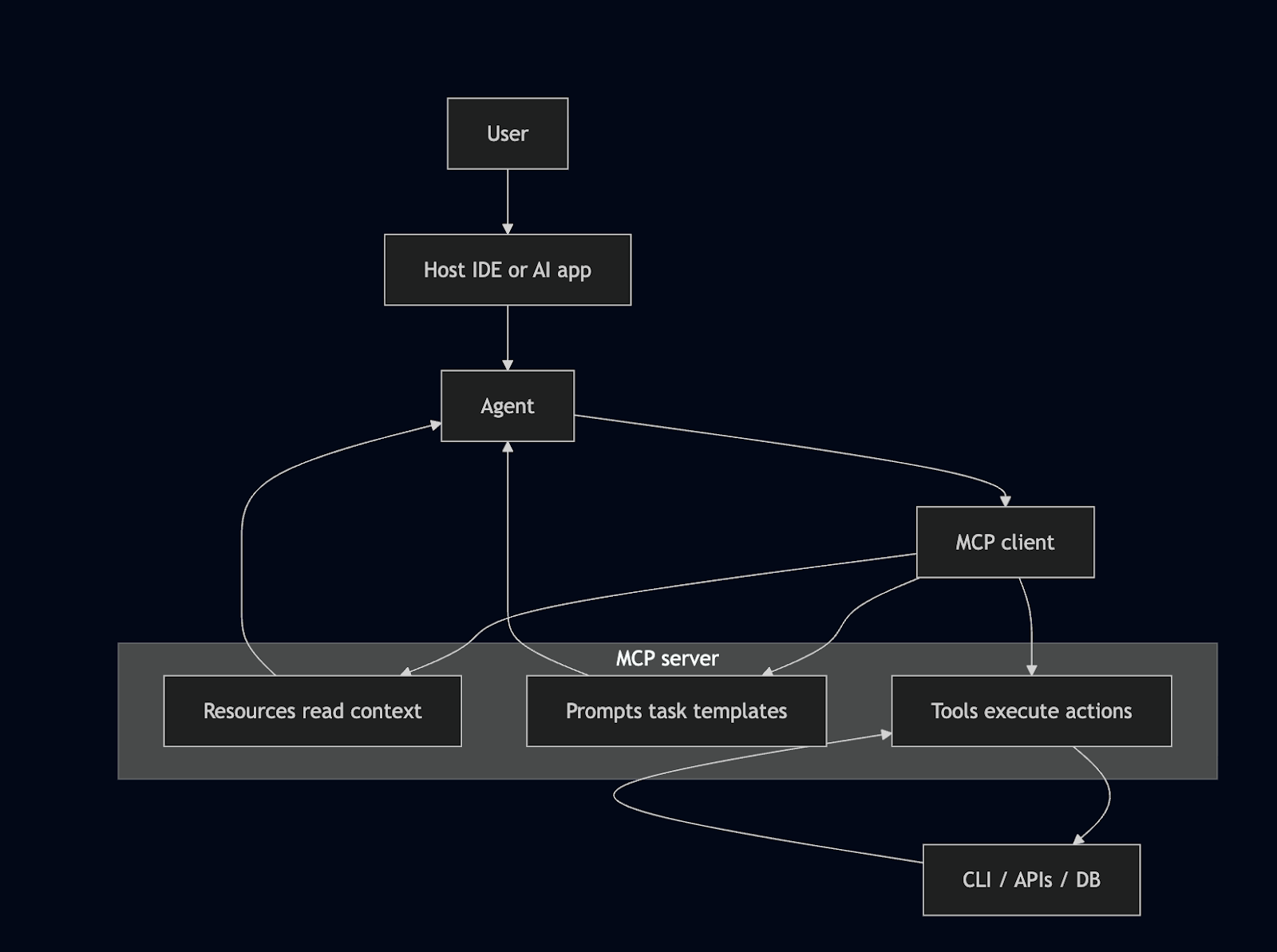
Host, client MCP, serveur MCP : qui fait quoi (et local vs remote)
MCP sépare qui orchestre, qui connecte, et qui exécute. La confusion vient souvent du mot “local” : en MCP, “local vs remote” décrit surtout où tourne le serveur, pas “qui est le client”.
MCP repose sur trois rôles séparés :
- Host : l’application côté utilisateur (IDE ou app IA). Elle porte l’UX, la conversation, et le contexte (repo, fichiers, sélection).
- Client MCP : une brique dans le host qui se connecte à un ou plusieurs serveurs MCP, découvre leurs capacités et effectue des appels structurés.Autrement dit : un IDE est un client MCP, et une application IA (desktop/web) peut l’être aussi.
- Serveur MCP : côté outillage, c’est la façade qui expose des capacités (tools/resources/prompts) et les traduit en actions réelles (CLI, API internes, fichiers, etc.).
Serveur “local” vs serveur “remote”
- Serveur MCP local : tourne sur la machine du développeur (souvent lancé comme un processus par l’IDE/app IA), typiquement pour exposer un CLI lié au repo et à l’environnement local.
- Serveur MCP remote : tourne sur une infra distante, typiquement pour mutualiser une capacité partagée (service interne, CI, données communes).
À retenir : le client est dans le host (IDE ou app IA), et il peut parler à des serveurs MCP locaux et/ou distants selon le besoin.

À ce stade, MCP peut sembler très architectural, presque abstrait.
En pratique, tout se joue dans la manière dont un serveur expose ses capacités.
Tools, resources, prompts : les primitives qui comptent
Un serveur MCP n’est pas “juste un endpoint”. Il déclare des primitives standardisées, que le host peut lister et utiliser.
- Resources : du contexte lisible (doc interne, logs, config, fichiers) que l’agent peut consulter pour réduire l’ambiguïté.
- Tools : des actions exécutables (build, analyse, génération, application, tests), appelées avec des paramètres explicites et un résultat structuré.
- Prompts : des gabarits de tâches réutilisables, pour guider l’usage (diagnostic, préparation de PR, analyse de logs).
Une façon simple de le dire : resources pour comprendre, tools pour agir, prompts pour cadrer.
Data layer vs transport layer : stdio et HTTP Streamable
MCP distingue ce que l’on échange (la couche “messages”) et par où ça transite (le transport). La couche messages s’appuie sur des échanges structurés (JSON-RPC 2.0 dans la spécification), ce qui standardise la manière d’appeler un tool, lire une resource et renvoyer un résultat.
Le transport est flexible :
- stdio : pour du local, l’IDE lance le serveur MCP comme un processus et dialogue via stdin/stdout.
- HTTP streamable : pour du distant, le host se connecte à un serveur et garde un flux de réponse “streamable” (utile pour retours progressifs).
Règle pratique : stdio si votre outillage vit sur la machine du dev (CLI lié au repo), HTTP Streamable si vous mutualisez des capacités (services internes, CI, données partagées).
À noter : si vous passez en serveur distant, la mise à l’échelle et la gestion de session/état peuvent devenir un vrai sujet d’industrialisation.
Replay Webinar : industrialiser l'IA grâce au standard MCP
Ce qui fait une intégration MCP réussie : le design des tools
Le protocole est rarement le point dur. Le point dur, c’est : comment vos tools se comportent quand un agent les consomme.
1) Des outputs orientés décision (pas des dumps d’état)
Un piège fréquent consiste à renvoyer tout ce que le tool sait produire :logs détaillés, métriques internes, états intermédiaires, traces complètes.
Pour un humain, cela peut être utile. Pour un agent, c’est souvent contre-productif.
Un agent ne cherche pas un journal exhaustif. Il cherche à répondre à une question simple :
Quelle est la prochaine action raisonnable ?
Si la réponse d’un tool est trop verbeuse, l’agent doit :
- filtrer
- interpréter
- deviner l’intention
- parfois tenter en essai-erreur
On introduit de l’ambiguïté inutile.
Préférez une réponse orientée décision
Par exemple :
{
"status": "ok",
"summary": "3 problèmes détectés",
"nextActions": ["generate_patch", "review"],
"details": []
}
Ce format donne immédiatement :
- un statut clair
- un résumé synthétique
- des actions possibles explicitement suggérées
- des détails optionnels, consultables si nécessaire.
L’agent n’a pas besoin d’analyser 200 lignes pour comprendre quoi faire.Il peut décider rapidement de la suite.
Le principe clé
Un bon output MCP doit :
- être court par défaut
- exposer une intention claire
- différencier résumé et détails
L’objectif n’est pas de tout exposer. L’objectif est de permettre une décision fiable.
Les détails peuvent toujours être demandés via une autre action. La décision, elle, doit être immédiate.
2) Des erreurs actionnables (pour que l’agent récupère)
Pour un agent, une erreur est un signal de replanification. Si vous renvoyez “fichier manquant” sans structure, l’agent devine. Si vous renvoyez une erreur typée, l’agent peut corriger.
{
"isError": true,
"code": "MISSING_CONFIG",
"message": "config.yaml absent",
"recoveryHint": "Appeler generate_config() puis relancer validate_config()"
}
3) Des tools atomiques et composables
Quand on expose des capacités existantes, la tentation naturelle est de créer un tool “tout-en-un” :
fix_module(module) -> report
Cette commande pourrait :
- analyser le module
- générer un correctif
- appliquer le patch
- lancer les tests
- produire un rapport final
Pour un humain expert, c’est pratique. Mais pour un agent, c’est une boîte noire.
Pourquoi ? Parce que l’agent ne voit pas les étapes intermédiaires. Il ne peut ni observer ce qui a été détecté, ni ajuster sa stratégie, ni s’arrêter avant une action risquée comme l’application d’un patch.
À l’inverse, des tools mono-intention rendent le processus explicite :
analyze_module() -> issues
generate_patch(issues) -> patch
apply_patch(patch) -> success
run_tests() -> report
Chaque action fait une seule chose.Chaque résultat est observable.
Cela change tout :
- l’agent peut analyser les problèmes avant de générer un patch
- il peut demander confirmation avant application
- il peut relancer uniquement les tests si nécessaire
- il peut adapter son plan si une étape échoue.
On ne construit plus une commande “intelligente”. On expose des briques simples que l’agent peut orchestrer.
C’est cette composabilité qui permet à une conversation de devenir un enchaînement d’actions contrôlées, plutôt qu’un appel opaque difficile à piloter.
Newsletter mensuelle
Ce type de contenu, chaque mois dans votre boîte mail
Architecture, IA générative, DevOps — les meilleurs articles Ippon à retrouver chaque mois.
Retour d’expérience : exposer un CLI Rust dans un IDE via MCP
Nous avions un CLI Rust interne robuste, utilisé au quotidien pour automatiser des workflows. Ce n’était pas un prototype : c’était un outil central, rapide, et chargé de règles métier. Le besoin était simple : le rendre accessible depuis l’IDE (là où l’agent et les devs travaillent), sans imposer le terminal comme “interface obligatoire”, et sans remplacer le CLI.
Objectif : rendre ces capacités pilotables
Nous ne cherchions pas à construire une nouvelle interface, mais à obtenir trois propriétés essentielles :
- Pilotable : appelable par un agent avec des paramètres explicites et typés.
- Chaînable : composable en étapes distinctes (analyse → génération → application → validation).
- Observable : produisant des résultats et des erreurs structurés, exploitables sans parsing fragile.
La fausse bonne idée : le plugin IDE “intelligent”
Notre première impulsion a été un plugin VSCode : chat intégré, parsing de stdout, affichage riche. En démo, c’était impressionnant. En production, on s’est heurté à des problèmes structurels :
L’écosystème d’adaptateurs
(effet N-IDE)Chaque IDE/host devient une cible : VSCode aujourd’hui, Cursor demain, JetBrains pour une autre équipe, puis une app desktop. Une évolution du CLI n’est plus “une feature CLI”, c’est “une feature CLI + N adaptations + N tests + N tickets”.
La duplication de logique
Pour rendre l’expérience “smart”, on recode côté plugin des validations, des règles, et l’interprétation des erreurs. Progressivement, l’extension devient un second système : une version partielle de la logique métier du CLI, jusqu’au moment où les deux divergent.
Le parsing fragile (stdout devient une API implicite)
Un CLI parle aux humains : logs colorés, barres de progression, wording contextuel. Dès qu’on dépend de parsing texte/regex, on transforme des logs (non contractuels) en “API” de fait : le moindre changement casse l’intégration.
Le lock-in
L’investissement colle à VSCode (API, packaging, distribution, compat). Si l’équipe change de host, une partie du travail devient difficile à réutiliser.
Cette étape a quand même été utile : elle a clarifié le vrai problème. L’IDE n’avait pas besoin d’une UI spécifique, il avait besoin d’un contrat stable d’exposition.
Le pivot : architecture “moteur / façade / cockpit” avec MCP
On a pivoté vers une séparation nette :
- CLI Rust = moteur : la source de vérité, la logique métier, les performances.
- Serveur MCP TypeScript = façade : le contrat, la validation des paramètres, l’exposition des capacités.
- IDE/agent = cockpit : l’orchestration (enchaînement des étapes) et l’expérience utilisateur.
L’intérêt de MCP, dans ce contexte, est de fournir une cible unique d’intégration (un serveur qui expose des capacités), consommable par différents hosts compatibles, au lieu de maintenir un plugin différent par IDE.
Mise en œuvre : du CLI au serveur MCP TypeScript
Pourquoi TypeScript
Pour la couche façade, TypeScript s’est imposé naturellement. L’objectif n’était pas de réécrire la logique métier, mais de créer une surface d’exposition claire et rapide à faire évoluer : lancer un sous-processus, valider des paramètres, manipuler du JSON, publier un serveur MCP.
L’existence d’un SDK dédié facilite fortement cette étape. On n’est pas en train d’implémenter un protocole bas niveau : on déclare des capacités, on décrit leurs entrées, et on renvoie un résultat structuré.
En pratique, exposer une capacité via MCP reste étonnamment simple. Voici à quoi ressemble la déclaration minimale d’un tool côté serveur :
server.tool("analyze_module", {
inputSchema: {
type: "object",
properties: {
module: { type: "string" }
},
required: ["module"]
}
}, async ({ module }) => {
const result = await runCli(["analyze", module])
return JSON.parse(result)
})
Le point important n’est pas la syntaxe. Ce qui compte, c’est le contrat :
- un nom explicite
- un schéma d’entrée typé
- un résultat structuré exploitable par l’agent
La façade ne contient pas la logique métier. Elle formalise l’accès à cette logique.
Choix de transport : stdio pour un usage IDE local
Pour notre cas (CLI local lié au repo), stdio était le choix évident : l’IDE lance le serveur MCP comme un processus local et communique via stdin/stdout. Cela évite l’infra, minimise la latence, et simplifie le debug.
À noter : “stdio” décrit surtout le mode de connexion côté IDE, pas forcément un traitement 100% local, on rencontre souvent des serveurs stdio qui appellent ensuite des APIs/SDK distants (par ex. AWS via boto3) ou qui servent de proxy local vers un serveur MCP distant (ex. mode proxy FastMCP).
Les 3 changements côté CLI : devenir “agent-ready”
JSON-first
Stdout devient une API machine stable, les logs humains partent sur stderr ou dans un fichier.
Logs séparés
Ne mélangez pas résultat et logs : l’agent doit parser, le dev doit lire.
Erreurs catégorisées
Code d’erreur + message + hint de recovery, l’objectif est de rendre la récupération automatique possible.
Mini scénario end-to-end : analyse → patch → application → tests
Ce que l’on vise côté IDE, c’est une boucle simple :
- L’utilisateur demande : “Analyse ce module et propose un patch”.
- L’agent appelle analyze_module().
- Sur la base du résultat structuré, l’agent appelle generate_patch().
- L’utilisateur confirme, l’agent appelle apply_patch().
- L’agent appelle run_tests() et résume.
C’est ce chainage qui transforme une conversation en exécution réelle, sans copier-coller, sans parsing fragile, sans plugin spécifique.
Conclusion : rendre vos capacités actionnables
MCP ne vous demande pas de reconstruire vos outils, ni de transformer vos systèmes existants en produits “IA”.
Il vous demande quelque chose de plus fondamental : exposer vos capacités via un contrat clair et structuré.
Qu’il s’agisse d’un CLI, d’un script historique, d’une API interne, d’un moteur métier ou d’un service existant, le principe reste le même :
- séparer la logique métier de sa surface d’exposition
- formaliser les actions en tools atomiques
- produire des résultats structurés et exploitables
- rendre les erreurs compréhensibles et récupérables
MCP n’est pas “mieux que REST” par nature : il standardise l’exposition de capacités pour des agents (découverte + tools/resources/prompts), là où en REST tu dois définir ces conventions toi‑même. Elle est dans le changement de posture qu’il impose :
Ne plus intégrer par environnement. Ne plus parser des logs pour en faire des API implicites. Ne plus dupliquer la logique pour l’adapter à chaque host.
À la place, on expose des capacités stables que des agents peuvent découvrir, composer et enchaîner.
REST expose des services. MCP expose des capacités pilotables par des agents.
Dans un écosystème où les assistants deviennent capables de planifier et d’orchestrer, la question n’est plus “comment ajouter de l’IA à nos outils ?”
La question devient :
Comment rendre nos outils actionnables par l’IA sans créer de dette supplémentaire ?
MCP apporte une réponse pragmatique : exposer proprement, commencer petit, itérer, puis étendre.
Ce n’est pas une refonte. C’est un levier.
Sources et références
- What is the Model Context Protocol ? – Site officiel MCP
- Architecture overview – Model Context Protocol
- Specification - Model Context Protocol
- Introducing the Model Context Protocol – Anthropic
Vous intégrez des agents IA dans vos outils ?
Nos consultants accompagnent vos équipes sur l'architecture et l'implémentation MCP.

