

1.Comment moderniser un système legacy sans big bang avec le Strangler Fig Pattern ?
Ce Pattern peut être vu par certains collègues comme un principe d’architecture, on peut faire la distinction entre pattern d’architecture et principe d’architecture, mais cela ferait l’objet d’un autre débat et article. Nous avons inclus ce sujet car il nous semble adapté, on peut dire même que c’est du bon sens, faisons nous la main avec des besoins non critiques et après on migrera le coeur du business.
Le principe
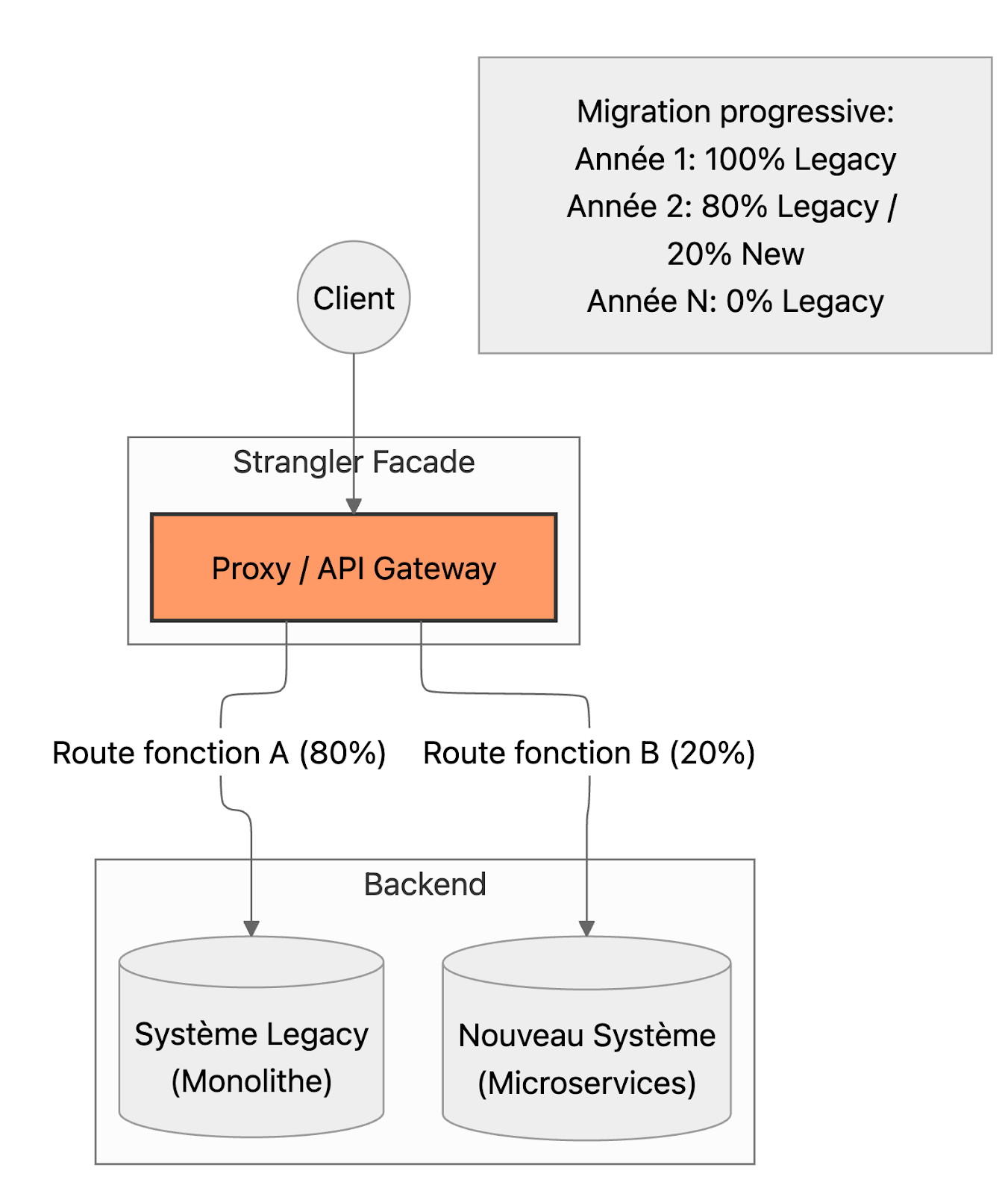
Plutôt que de réécrire tout le système legacy d'un coup (projet qui échoue dans 70% des cas), on l'enveloppe progressivement :
Année 1:
Client → Legacy (100% du trafic)
Année 2:
Client → Proxy/Gateway → Legacy (80%)
→ Nouveau système (20%)
Année 3:
Client → Proxy/Gateway → Legacy (40%)
→ Nouveau système (60%)
Année 4:
Client → Nouveau système (100%)
Legacy décommissionné ☠️
Cas client (Assureur historique)
Contexte :
- Système core insurance sur mainframe (40 ans d'âge)
- 2M de contrats actifs
- Impossible de tout migrer d'un coup
- Modernisation du SI
- Nouveaux cas d’usage métier
Stratégie Strangler Fig :
- Phase 1 : API Gateway devant le mainframe
- Phase 2 : Nouvelles souscriptions sur système moderne (cloud-native)
- Phase 3 : Migration progressive des contrats existants (par cohorte)
- Phase 4 : Décommissionnement mainframe (prévu 2028)
Bénéfices :
- Risque maîtrisé (migration incrémentale)
- Business continuity préservée
- ROI rapide (nouvelles fonctionnalités sur système moderne)
Les patterns techniques associés
Anti-Corruption Layer (ACL) :
- Couche de traduction entre ancien et nouveau monde
- Empêche la "contamination" du nouveau système par le legacy
Feature Flags :
- Bascule progressive du trafic
- A/B testing
- Rollback instantané en cas de problème
Dual Writes :
- Écriture temporaire dans les deux systèmes pendant la migration
- Garantit la cohérence
❌ Piège 1 : Non-Définition Claire des Bounded Contexts
Le succès du Strangler Fig repose sur la découpe efficace du Monolithe en domaines métier distincts.
- Le Problème : Extraire des fonctionnalités de manière arbitraire ou technique sans respecter les Bounded Contexts (contextes limités) du Domain-Driven Design (DDD).
- Conséquence : Les nouveaux services (les lierres) répliquent les dépendances cachées ou le couplage fort du monolithe. La nouvelle architecture devient un « Monolithe Distribué » difficile à gérer.
- Conseil : Passez du temps à analyser les domaines métier (ex: à l'aide d'Event Storming) avant de commencer l'extraction. Chaque nouveau service doit être cohérent et autonome.
❌ Piège 2 : Le Trafic Ne Passe Pas par la Façade (Façade/Adapter Manquant)
Le cœur de ce pattern est de rediriger le trafic des clients vers les nouveaux services, un domaine à la fois.
- Le Problème : Omettre ou mal implémenter la Façade (souvent un Proxy Inversé, une API Gateway, ou le Strangler Adapter) qui intercepte les requêtes.
- Conséquence : Les clients (interfaces utilisateurs, applications tierces) doivent être modifiés à chaque extraction, ce qui augmente le coût et le risque de la migration.
- Conseil : Mettez en place une couche de routage centralisée et intelligente au début du processus. Cette façade doit pouvoir rediriger les appels vers l'Ancien Système pour les fonctionnalités non migrées, et vers le Nouveau Service pour les fonctionnalités migrées, de manière transparente pour le client.
❌ Piège 3 : La Peur de l'Extraction de la Base de Données
Le découplage des services doit idéalement s'accompagner du découplage de la persistance.
- Le Problème : Extraire les services, mais continuer à les faire pointer vers la base de données monolithique partagée.
- Conséquence : Les nouveaux services ne sont pas réellement autonomes et restent couplés à la structure de données de l'ancien système. Les modifications dans le monolithe peuvent casser les nouveaux services, et inversement.
- Conseil : Planifiez l'extraction de la base de données (Database Strangling). Si la migration immédiate est impossible, utilisez le pattern Anti-Corruption Layer (ACL) pour traduire les requêtes entre le nouveau service et la base de données héritée.
❌ Piège 4 : Migration Trop Lente ou Pas Assez Visuelle
Le processus de démantèlement peut être très long et manquer de motivation.
- Le Problème : L'équipe ne voit pas de progrès significatif, ou la migration prend des années sans produire de valeur métier visible rapidement.
- Conséquence : Perte de motivation et difficulté à justifier l'investissement continu dans le projet (le Strangler Fig lui-même). Le monolithe reste un fardeau pendant trop longtemps.
- Conseil : Choisissez des domaines à forte valeur métier et à faible dépendance pour les premières migrations afin de prouver la réussite rapidement. Communiquez clairement le pourcentage de trafic/fonctionnalités qui est passé au nouveau système pour maintenir la dynamique.
❌ Piège 5 : Négliger l'Anti-Corruption Layer (ACL)
Lorsqu'un nouveau service doit parler à l'ancien système (ou vice-versa), la traduction est essentielle.
- Le Problème : Le nouveau service tente d'utiliser directement les modèles de données et la logique du monolithe sans traduction intermédiaire.
- Conséquence : Le nouveau service est "corrompu" par les incohérences et les structures historiques du monolithe. Cela annule l'intérêt de la nouvelle architecture.
- Conseil : Définissez un Anti-Corruption Layer (ACL) entre le nouveau service et l'ancien. L'ACL traduit les appels et les données dans le langage du nouveau service (son propre Bounded Context), garantissant l'intégrité de la nouvelle architecture.
❌ Piège 6 : Ne Pas Retirer le Code du Monolithe
Une fois qu'un domaine a été migré avec succès, l'ancien code doit disparaître.
- Le Problème : Laisser le code des fonctionnalités migrées actif (même s'il n'est plus appelé par la Façade) ou simplement le commenter.
- Conséquence : Le monolithe continue de grossir ou de stagner. La dette technique ne diminue pas réellement, car le code mort complique toujours la compilation et l'analyse de dépendances.
- Conseil : Intégrez le nettoyage du monolithe comme une étape finale et obligatoire du cycle de migration pour chaque domaine. L'objectif est de strangler et de retirer l'ancienne fonctionnalité.
Stack technologique 2026
API Gateway / Reverse Proxy :
- NGINX, Kong, Envoy
- AWS Application Load Balancer avec routing avancé
Feature Flags :
- LaunchDarkly
- Unleash (open source)
- AWS AppConfig
Quand utiliser Strangler Fig
- ✅ Legacy critique qu'on ne peut pas arrêter
- ✅ Migration étalée sur plusieurs années
- ✅ Besoin de délivrer de la valeur progressivement
- ❌ Greenfield project (nouvelle application)
Comment protéger votre domaine métier des systèmes externes avec un Anti-Corruption Layer (ACL) ?
Le Principe
- Isolation du Domaine : L'ACL est une couche de traduction qui agit comme une barrière entre votre Domaine Modélisé (votre nouveau système) et les modèles externes (typiquement des systèmes legacy ou des services tiers).
- Traduction Bidirectionnelle : Elle convertit les objets et les concepts entre le langage et le modèle du système externe et le langage et le modèle de votre propre système (votre Ubiquitous Language).

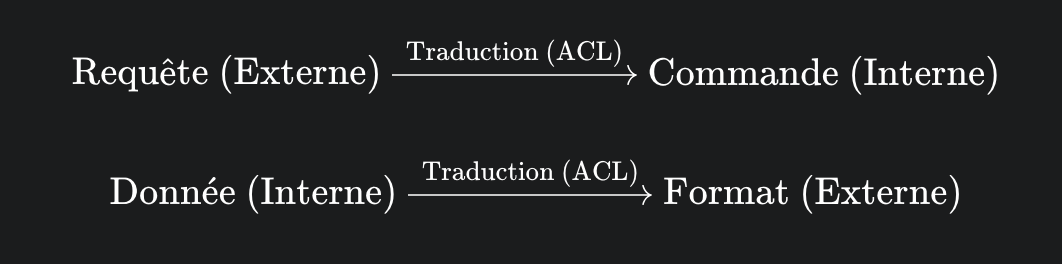
Pourquoi ce Pattern Gagne en Popularité
Cas d'usage 1 : Intégration Legacy (Le "Legacy Strangler")
- Problème : Le système hérité a des noms ambigus (Client_V1), des formats de date incohérents, ou des fonctions qui effectuent plusieurs opérations.
- Solution : L'ACL traduit le Client_V1 en votre objet moderne et propre ContractualParty, empêchant la "corruption" du nouveau modèle par les bizarreries de l'ancien.
Cas d'usage 2 : Qualité et Stabilité du Code
- Votre code métier (le cœur de l'application) ne connaît pas le protocole HTTP, le format JSON ou les tables du système externe.
- L'ACL est responsable de toute cette complexité technique, permettant à votre domaine interne de rester pur, testable, et sans dépendance externe.
Cas d'usage 3 : Flexibilité du Fournisseur
- Vous utilisez un service de paiement tiers (Stripe, Adyen) mais voulez pouvoir changer de fournisseur sans réécrire votre logique métier.
- L'ACL uniformise l'interface du service externe, permettant de basculer vers un autre fournisseur en ne changeant que l'implémentation de l'ACL, sans toucher au code principal.
Architecture Concrète
Cas Client (Grande Distribution)
Contexte : Migration progressive du système de gestion des stocks (Monolithe de 20 ans) vers des microservices modernes.
- Avant : Les nouveaux microservices devaient interroger directement les tables du Monolithe ou appeler ses vieilles APIs SOAP avec des objets complexes. Les développeurs devaient apprendre la structure de l'ancienne base pour travailler sur le nouveau service.
- Après (ACL) :
- ACL : Un nouveau service est déployé pour envelopper l'ancien système.
- Adapter In : Il reçoit les requêtes du nouveau système (ex: GetAvailableStock(itemId)).
- Mapper : Il traduit l'ID produit moderne en l'ID produit du système hérité (Legacy_SKU_ID).
- Adapter Out : Il exécute la requête sur le Monolithe (API SOAP, JDBC direct, etc.).
- Résultat : Le Monolithe renvoie un objet LegacyStockItem. L'ACL le traduit en StockInventory pour le nouveau service.
- Résultats :
- Le découplage a permis le développement de 5 nouveaux microservices sans être ralentis par le code legacy.
- Le jour où la base de données legacy a été remplacée, seule l'ACL a dû être mise à jour.
Les Pièges à Éviter
❌ Piège 1 : Le Mappage 1:1 Simpliste
L'ACL n'est pas qu'une simple couche de mappage de données. Si vous faites un mappage direct de tous les champs, l'ACL ne sert à rien et votre modèle interne est quand même pollué. L'ACL doit modéliser les concepts importants.
❌ Piège 2 : Le Double-Travail
Si le modèle externe est déjà très bien conçu et proche de votre besoin, introduire une ACL peut être une surcharge inutile (comme si l'on utilisait un traducteur entre deux personnes parlant la même langue).
❌ Piège 3 : La Latence Ajoutée
L'ajout d'une couche de traduction est un overhead. Pour les interactions à ultra-haute performance (ex: transactions en temps réel), la latence introduite par l'ACL doit être soigneusement évaluée.
Quand NE PAS utiliser l'ACL
❌ Intégration simple avec une API moderne et stable (modèle standard) : Si vous consommez une API comme un service de météo ou de géolocalisation dont le modèle est peu susceptible de changer.
❌ Systèmes internes développés par la même équipe : Si les deux modèles sont sous votre contrôle et peuvent être alignés.
❌ Cas où la latence de traduction est prohibitive.
2. Comment sécuriser et observer efficacement des microservices avec un Service Mesh ?
Le problème
Avec 50+ microservices, comment gérer :
- La sécurité inter-services (mTLS)
- Le monitoring distribué
- Le retry, timeout, circuit breaker de chaque appel
- Le canary deployment, A/B testing
Mauvaise réponse : Chaque équipe code cela dans son service → Duplication, incohérence
Bonne réponse : Service Mesh
Le principe
Une couche d'infrastructure qui gère toute la communication inter-services :


Fonctionnalités clés
- mTLS automatique : Chiffrement de bout en bout sans code applicatif
- Traffic Management : Canary, blue/green, traffic splitting
- Observability : Métriques, logs, tracing out-of-the-box
- Resilience : Retry, timeout, circuit breaker configurables
Cas client (Fintech)
Contexte : 80 microservices, exigences PCI-DSS strictes
Avant :
- Chaque équipe gère sa propre sécurité inter-services
- Pas de visibilité sur les communications
- Audit de conformité cauchemardesque
Après (Istio) :
- mTLS automatique entre tous les services
- Zero Trust par défaut
- Dashboard centralisé (Kiali) de toutes les communications
- Audit trail complet pour la conformité
Résultats :
- Temps d'audit PCI-DSS : -70%
- Incidents de sécurité inter-services : 0 en 18 mois
- Mean Time To Detection (MTTD) : -60%
Stack technologique 2026
Leaders :
- Istio : Le plus complet, écosystème riche, mais complexe
- Linkerd : Plus simple, performant, bonne option pour démarrer
- Consul Connect : Si vous êtes dans l'écosystème HashiCorp
Alternative légère :
- DAPR (Distributed Application Runtime) : Pas un service mesh complet, mais couvre beaucoup de use cases
Quand NE PAS utiliser un Service Mesh
- ❌ Vous avez <10 microservices
- ❌ Communication inter-services peu fréquente
- ❌ Équipe Ops sans expérience Kubernetes
- ❌ La latency ajoutée (1-5ms par hop *) est inacceptable
3. Pourquoi adopter l’architecture hexagonale (Ports & Adapters) en 2026 ?
Comme pour le pattern Strangler Fig, les puristes diront que c’est plus un pattern d’architecture logicielle, aussi connue sous le nom de Ports et Adaptateurs, c’est l'un des patterns d'architecture les plus influents au niveau logiciel (ou niveau composant).
Le principe
Séparer clairement :
- Le cœur métier (domain logic) : indépendant de toute technologie
- Les ports : interfaces définissant les interactions
- Les adapters : implémentations concrètes (DB, API, message broker)
Architecture concrète
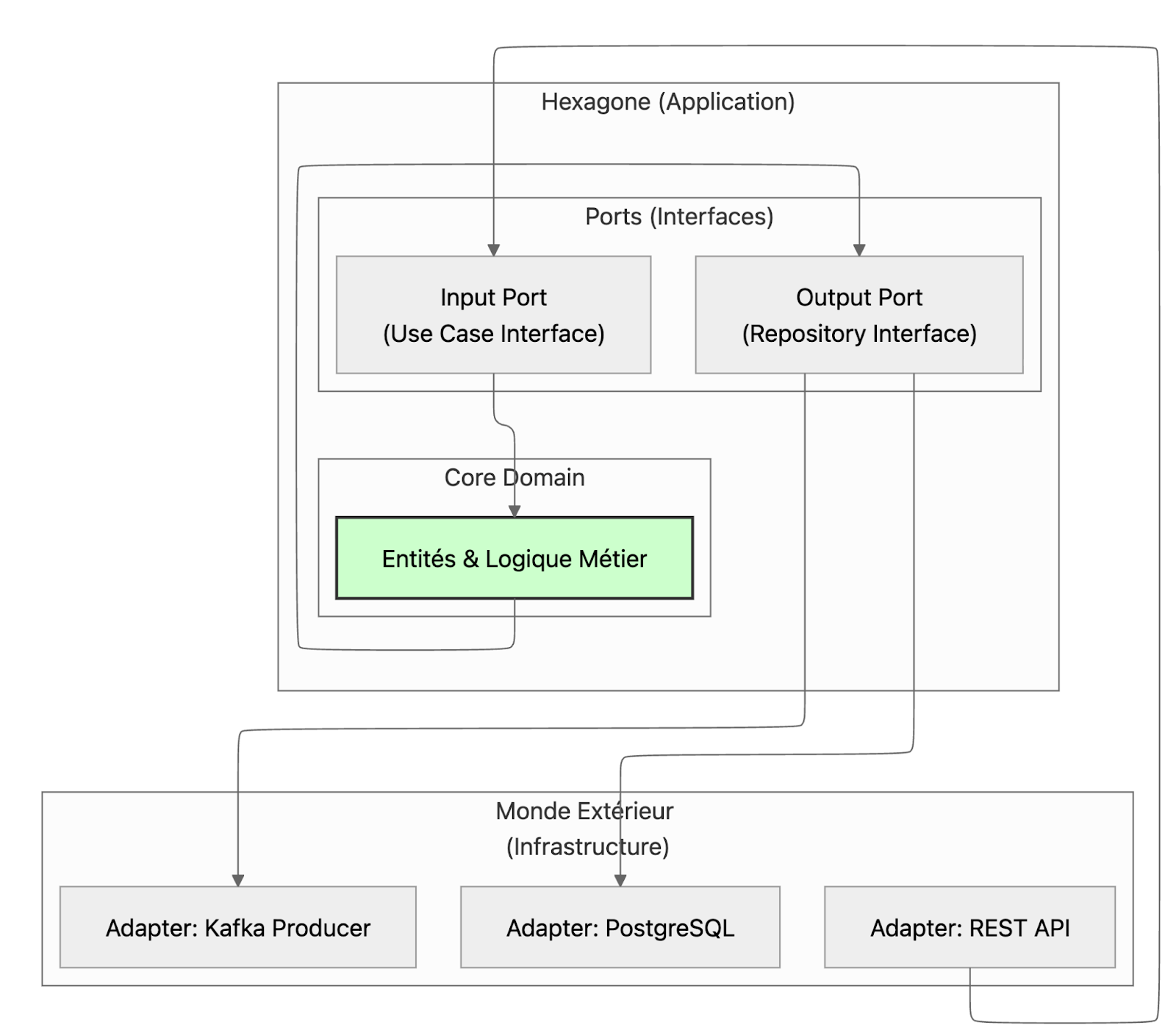
Pourquoi c'est pertinent en 2026
1. Testabilité Le core métier n'a aucune dépendance externe → tests ultra-rapides
2. Évolutivité technologique Changer de base de données ou de framework ? On change juste l'adapter
3. Migration progressive Parfait avec Strangler Fig : on peut avoir des adapters legacy et modernes en parallèle
Cas client (Healthtech)
Contexte : Plateforme de télémédecine, réglementations strictes
Approche :
Domain Core (100% métier, 0% technique) :
- Règles de prescription
- Workflow de consultation
- Logique de tarification
Adapters :
- REST API (pour frontend web)
- GraphQL API (pour mobile)
- PostgreSQL adapter (données structurées)
- S3 adapter (documents médicaux)
- HL7 adapter (interopérabilité hospitalière)
Bénéfices :
- Tests du core métier : 100% de couverture, 0 dépendance externe
- Migration PostgreSQL → Aurora : 2 jours (juste l'adapter)
- Ajout d'un nouvel adapter HL7 sans toucher au métier
Frameworks supportant l'Hexagonal Architecture
- Spring Boot (Java) : Naturellement compatible
- NestJS (TypeScript) : Architecture en layers
- .NET Clean Architecture : Template Microsoft officiel
- Go : Convention de packages (domain/, adapter/, port/)
Quand utiliser Hexagonal Architecture
- ✅ Logique métier complexe qui évolue souvent
- ✅ Besoin de tester le métier indépendamment
- ✅ Multi-canaux (web, mobile, API partenaires)
- ❌ CRUD ultra-simple sans logique métier
Pourquoi les patterns d’architecture sont-ils des solutions éprouvées et non des effets de mode ?
Chaque année, de nouveaux buzzwords architecturaux émergent. Microservices hier, Serverless aujourd'hui, Edge Computing demain. Le risque ? Tomber dans le pattern-washing : utiliser un pattern parce que "c'est moderne" plutôt que parce qu'il résout un problème réel.
En 2026, après des années d'expérimentation (et d'échecs instructifs), nous avons du recul sur ce qui fonctionne vraiment. Voici les patterns d'architecture qui font la différence sur le terrain, avec leurs cas d'usage, leurs pièges, et surtout : quand NE PAS les utiliser.
✅ 7 patterns majeurs couverts avec profondeur :
- Event-Driven Architecture (EDA)
- API-First & API Gateway (+ BFF)
- CQRS + Event Sourcing
- Saga Pattern (Orchestration vs Chorégraphie)
- Strangler Fig Pattern
- Service Mesh
- Hexagonal Architecture
✅ Pour chaque pattern :
- Principe expliqué simplement
- Cas client concret avec résultats chiffrés
- Stack technologique 2026
- Quand l'utiliser / NE PAS l'utiliser
- Pièges à éviter
✅ Bonus :
- Pattern Decision Matrix (tableau comparatif)
- Anti-patterns à éviter (Distributed Monolith, etc.)
- Approche pragmatique "pas de pattern-washing"
Comment choisir le bon pattern d’architecture selon son contexte avec une Decision Matrix ?
Liens et articles :
Définition de "Hop"
Hop (du verbe anglais "to hop" = sauter) désigne un "saut" ou "bond" dans le parcours d'une requête réseau.
Dans le contexte des architectures microservices
Un hop représente chaque passage par un composant intermédiaire entre la source et la destination
La Bible de Gregor Hohpe sur les patterns d’architecture d’entreprise : https://www.enterpriseintegrationpatterns.com/
et la liste des patterns existant : https://www.enterpriseintegrationpatterns.com/patterns/messaging/toc.html
Découvrir les Tech Trends 2026.
Pour aller plus loin sur le sujet :
- Patterns d'Architecture 2026 - Du Hype à la Réalité du Terrain Part. 1/2
- De la Data Platform à la Data Viz - Le chaînon manquant de votre stratégie data
- TOGAF en 2026 - Au-delà du framework, une culture d'architecture
Vous souhaitez aller plus loin sur le sujet ?
Nos experts sont là pour vous accompagner au mieux dans la modernisation de votre SI.
