

Introduction
Le but de cet article est de vous partager mon retour d'expérience quant à la mise en place d'une solution de sauvegarde pour des applications stateful hébergées sous Kubernetes.
L'utilisation de Kubernetes est principalement axée sur le déploiement d'applications de type stateless, c’est-à-dire sans stockage persistant.
Mais il arrive fréquemment que l'on ait besoin de stockage persistant pour des applications dites stateful, comme par exemple Cassandra, CouchBase, CouchDB etc.
Le cycle de vie (déploiement, provisionnement, maintenance, etc.) est grandement facilité via l'usage de Kubernetes pour ce type d'applications.
Cependant, il reste une problématique à résoudre : comment pouvons-nous sauvegarder ces données dans le cas d'un Disaster Recovery ?
Même si les données sont réparties sur des volumes redondés et séparés, cela ne nous protège pas d'un sinistre majeur. C'est là qu'intervient le besoin de sauvegarder nos données.
Avec l’émergence de l’utilisation d’applications stateful, l'écosystème Kubernetes commence à voir arriver des solutions de sauvegarde pour les données persistantes.
L'une d'entres elle, Velero, anciennement Ark Heptio, est la plus aboutie à ce jour.
Contexte
Aujourd'hui nous hébergeons des applications stateful sur notre Kubernetes on-premise pour lesquelles leurs volumes sont rattachés en mode bloc (RBD) à un cluster Ceph existant.
La jonction entre Kubernetes et Ceph sera expliquée dans un second article. (voir POC 2)
Nous allons voir ensemble comment nous pouvons procéder afin de sauvegarder nos applications stateful sur Kubernetes avec des volumes externes attachés.
Présentation de l’infrastructure
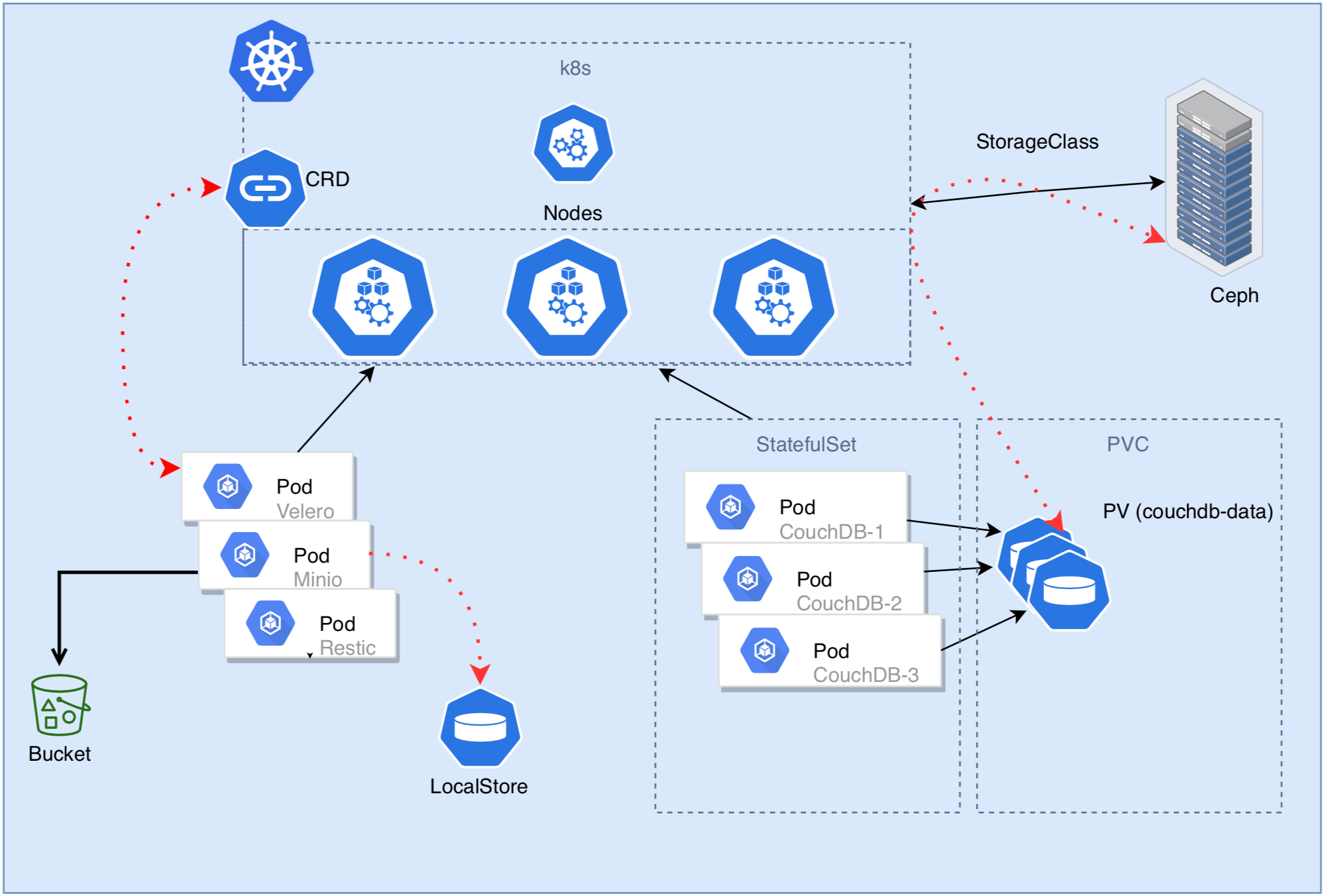
Sauvegarde des volumes persistants k8s avec Velero
Velero est l'outil le plus mature pour sauvegarder les clusters Kubernetes.
Il s'appuie sur des fonctionnalités de snapshots offerts par les cloud providers afin de réaliser des sauvegardes des volumes persistants.
Velero s’utilise pour effectuer des sauvegardes complètes (ex: configmaps, deployment, etc.), ou bien uniquement des sauvegardes de certains namespaces ou types de ressources (ex: pods etc.). Il prend en charge la sauvegarde de presque tous les types de volumes Kubernetes, quel que soit le fournisseur de stockage utilisé.
L'exécution de Velero peut se faire manuellement selon le besoin ou bien via une tâche programmée pour s’exécuter à interval de temps régulier.
Dans notre cas pratique, nous n'utilisons pas les snapshots mais nous couplons Velero avec Restic et Minio afin de réaliser et stocker nos sauvegardes.
Dans sa version 1.2, Velero permet essentiellement d’utiliser un stockage objets pour stocker nos sauvegardes et inclut de nouvelles fonctionnalités et une amélioration de l'intégration avec Restic.
Dans le cas d'une utilisation sur AWS il est recommandé d'utiliser le service S3 afin d’avoir une compatibilité native.
Pour une utilisation on-Prem, nous substituerons le service S3 par Minio (service de storage objets) compatible avec l'API Amazon S3.
Pourquoi Minio et non pas Rook ? Tout simplement parce que Minio est plus simple à mettre en place et nécessite beaucoup moins d'artéfacts.
Pour une utilisation plus avancée du stockage objets il est préférable de se tourner vers Rook qui permet une mise à l'échelle bien plus performante et permet de s’adapter à l’évolution de nos besoins (volumétrie, type de service etc.).
Et Restic alors ?
Restic sera notre clef de voûte, c’est lui qui va nous permettre de faire le lien entre notre orchestrateur de sauvegarde et notre espace de stockage. Il va s’occuper de prendre en charge les sauvegardes de nos volumes persistants.
Pour profiter de cette intégration, il faut utiliser au minimum la version 1.10 de Kubernetes.
Voyons ensemble comment faire pour faire fonctionner tout ce beau monde.
installation de HELM
Nous allons nous appuyer sur HELM afin de réaliser les déploiements des composants Velero et Minio.
L’installation de Restic sera incluse dans l’installation de Velero lors de l’initialisation.
Pour cela il faut s'assurer d'installer les composants nécessaires pour faire fonctionner HELM.
2 étapes sont requises :
- Télécharger Helm sur un client :
brew install kubernetes-helm ou via les binaires présents sur github.
- Initier l'installation de la partie serveur via la commande :
helm init
Cela va installer le pod Tiller sur le namespace kube-system afin que les appels API puissent être interprétés par Kubernetes.
Il se peut que vous rencontriez une erreur lors du lancement du pod Tiller. Veuillez à vérifier les logs et assurez-vous d'avoir les bonnes autorisations (RBAC) configurées.
Ici, un exemple de compte de service et RBAC "type" pour Tiller:
cat << EOF | kubectl apply -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
EOF
helm init --service-account tiller
Une fois le pod Tiller opérationnel, on est en mesure d’utiliser la commande helm pour faire nos déploiements.
Installation de Minio
L'installation de Minio est simplifiée grâce à l’usage de Helm. Le repository stable de Helm inclut les charts nécessaires pour installer Minio, il suffit d'exécuter la commande suivante :
helm install stable/minio --name minio --namespace velero -f minio-aws.yaml --debug
Cela va installer la version stable de Minio dans le namespace velero. Le déploiement est constitué de 2 jobs et d'un pod en mode standalone.
Pour notre cas d’usage nous n’avons pas besoin de faire fonctionner Minio en mode cluster.
L'option -f nous permet de passer un fichier de paramètres qui va surcharger les valeurs initiales afin de coller à notre besoin.
Exemple de surcharge
image:
tag: latest
accessKey: "accessKeyMinio"
secretKey: "secretKeyMinio" ## L'utilisation est semblable au service Amazon S3
service:
type: ClusterIP
defaultBucket:
enabled: true
name: velero ## permet la création du bucket de sauvegarde à l’installation
persistence:
enabled: true ## activation de la persistance du volume
accessMode: ReadWriteOnce
size: 500Gi ## on définit la taille de notre PV dédié à Minio
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: nginx
path: /
hosts:
- notreURL.minio.ext.zone ## On définit une URL d'accès pour la webui Minio à travers notre ingress pour exposer le service minio
Installation de Minio client
L'accès aux données de Minio peut se faire via l’interface web ou bien directement en console via une communication interne.
Nous utiliserons un pod dédié pour installer le client Minio.
Le processus reste simple:
- On télécharge le MC Minio Client (voir ici) :
docker pull minio/mc
- On configure la connexion au serveur :
mc config host add minio-local http://minio-svc:9000 accessKeyMinio secretKeyMinio S3v4
Ne pas oublier de spécifier l’algorithme d'authentification Amazon S3 Signature Version 4 à la fin de la commande mc, sans quoi l'authentification ne sera pas reconnue.
- On effectue les opérations voulues :
mc ls minio-local / mc rb minio-local
Les commandes mc disponibles sont semblables à celle de la commande awscli pour S3 (c’est-à-dire rb bucket / mb / ls etc.)
Nous sommes maintenant en mesure de naviguer dans l’arborescence de notre bucket.
installation de Velero
Nous gardons le même principe d'installation via HELM :
helm install stable/velero --name velero --namespace velero -f velero-aws.yaml --debug
Exemple de surcharge utilisé
image:
tag: v1.2.0 ## Choix de la dernière version de velero (v1.2 à ce jour)
configuration:
provider: aws ## Minio étant compatible avec l’API S3 on laisse aws comme provider
backupStorageLocation:
name: aws
bucket: velero
config:
region: minio ## permet d’informer velero que l’on utilise un endpoint spécifique (non aws)
s3ForcePathStyle: true
publicUrl: http://notreURL.minio.ext.zone ## url utilisé pour l’interface web et l’accès aux logs
s3Url: http://minio.velero.svc.cluster.local:9000 ## url utilisé en interne dans k8s
credentials:
useSecret: true
secretContents:
cloud: |
[default]
aws_access_key_id = accessKeyMinio
aws_secret_access_key = secretKeyMinio
snapshotsEnabled: false ## On n’active pas cette fonctionnalité
configMaps:
restic-restore-action-config:
labels:
velero.io/plugin-config: ""
velero.io/restic: RestoreItemAction
data:
image: gcr.io/heptio-images/velero-restic-restore-helper:v1.2.0 ## Choix de l’image pour la restauration des pods via restic
deployRestic: true ## Permet l’activation et la création des pods Restic
Cela va installer la version stable de velero dans le namespace velero. Le déploiement sera constitué d'un pod Velero gérant les appels API et d'un pod Restic par node gérant les accès aux volumes.

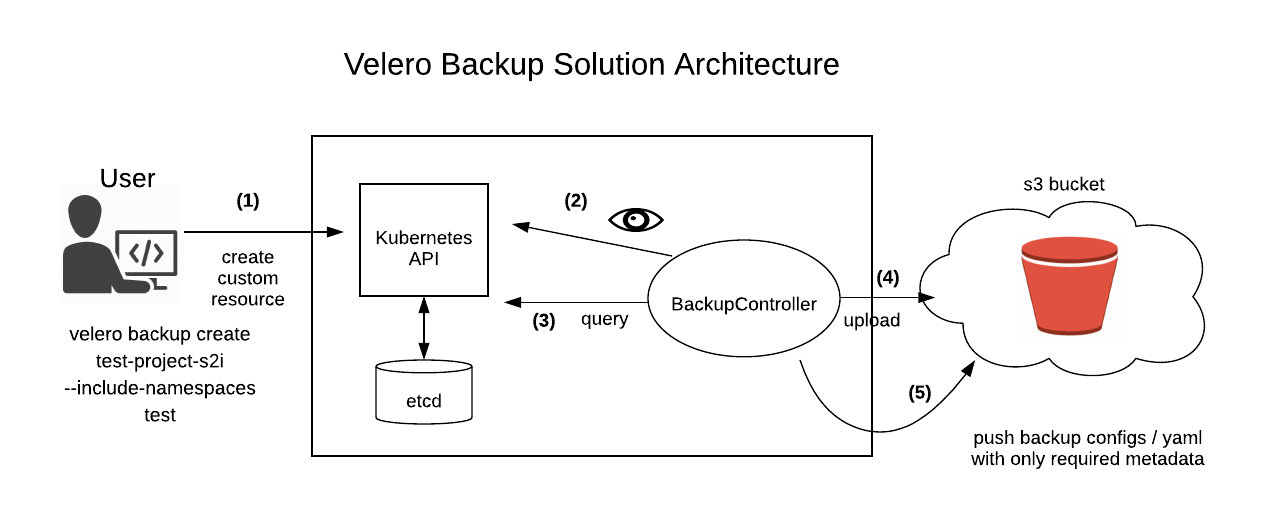
Lors de son déploiement Velero va créer de nombreuses ressources CRD (Custom Resources Definitions).

Les 3 ressources essentielles à connaître sont :
- PodVolumeBackup
Il représente une sauvegarde Restic d'un volume dans un pod.
Ainsi, lors d’une sauvegarde, Velero va créer une ressource de ce type dès qu’il trouvera un pod ayant l’annotation backup.velero.io/backup-volumes.
- PodVolumeRestore
Cette ressource représente une restauration d’un volume pour un pod.
Lors d’une restauration Velero va créer une ressource de ce type et Restic prendra le relai afin de restaurer les volumes associés aux pods.
- ResticRepository
C’est tout simplement la définition de l’endroit où les données seront stockées et la gestion des actions Restic.
installation de Velero client
Nous installons localement la partie cliente de Velero mais cela pourrait très bien être fait directement dans un pod. La partie cliente nous servira à envoyer nos requêtes au serveur Velero afin que nos actions de sauvegardes/restaurations soient effectuées au sein du cluster Kubernetes.
Le processus reste identique à celui de Minio dans les grandes lignes :
- On installe le client :
brew install velero ou via les binaires
- On effectue nos commandes Velero:
velero backups get
velero restore get
etc.

Test de sauvegardes
Une fois l'infrastructure en place, il ne reste plus qu'à effectuer nos premières sauvegardes ;)
Pour l'instant, Velero nous oblige à annoter l'ensemble de nos ressources (PV) afin que la sauvegarde prenne en compte les volumes persistantes.
Pour cela, soit on le fait dans la définition de notre StatefulSet en indiquant le préfixe de nos volumes soit on le fait dans chacun de nos pods avec le nom du volume exact.
Exemple
# Annotation du pod avec velero.io/backup-volumes (volume prefix name: couchdb-data)
kubectl -n couchdb annotate pod/couchdb-0 backup.velero.io/backup-volumes=couchdb-data-couchdb-0
# Création de la sauvegarde pour le namespace complet (avec toutes les ressources présentes)
velero backup create backup-couchdb-test --include-namespaces couchdb
# Obtenir des détails
velero backup describe backup-couchdb-test --details
L’option --details permets de nous assurer que le volume attaché au pod à bien été pris en compte lors de la création de la tâche de sauvegarde. Cette vérification peut également être faite dans les logs de velero.

Il est également possible de vérifier le contenu et la taille du bucket créé par Restic pour notre tâche de sauvegarde est cohérent avec la source via minio-client.
Après quelques heures de manipulations on arrive à bien comprendre le principe de backup et comment les différentes briques s'orchestrent entres elles.
Création d'un job programmé de type autoBackup
Quoi de mieux que des sauvegardes lancées automatiquement ?
Velero nous permet de lancer plusieurs jobs de sauvegarde à interval de temps régulier afin de respecter notre RPO (Recovery Point Objective) vis-à-vis de nos clients. Les sauvegardes seront incrémentales et nous pourrons avoir un retour arrière suffisant pour pallier à une perte de données par exemple.
Voici les 2 tâches programmées :
# Tous les heures avec une rétention de 24h (suppression au-delà)
velero schedule create hourly-cassandra --schedule="@every 1h" --ttl 24h0m0s
ou également :
velero schedule create hourly-cassandra --schedule="0 * * * *" --ttl 24h0m0s
# Tous les jours avec une rétention de 7 jours
velero schedule create daily-cassandra --schedule="@every 24h" --ttl 168h0m0s
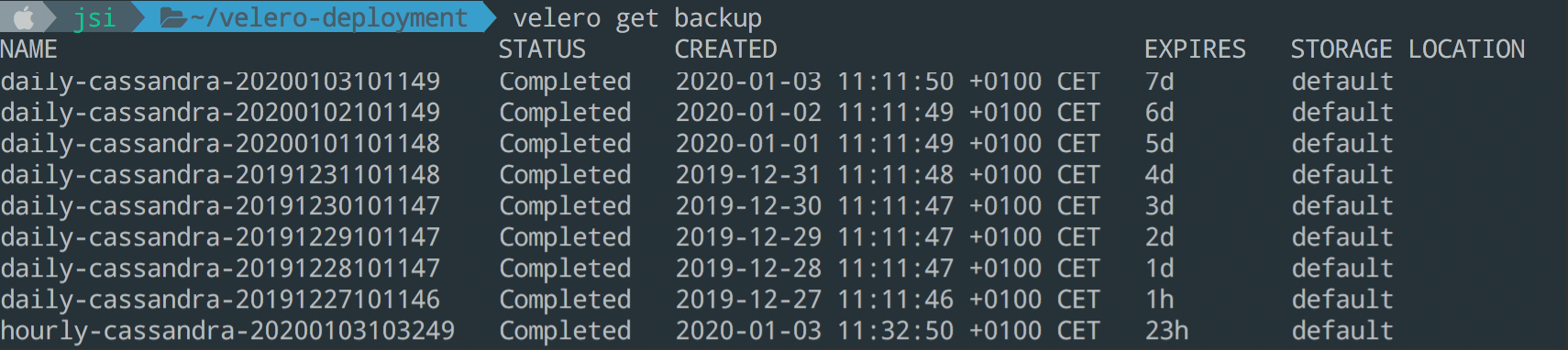
Il est bien évident que l’on peut adapter ce principe aux besoins clients selon les types d’applications que l’on veut sauvegarder, leurs criticités etc.
Test ultime : la restauration
Le moment de vérité. Théoriquement, nos sauvegardes sont opérationnelles. Vérifions cela.
La première chose à faire et de s'assurer que notre backup est Completed avec la prise en compte du volume (PV) dans les logs du backup.
Une fois cela fait, nous pouvons faire notre test de restauration en supprimant complètement notre environnement de test.
kubectl delete ns awsjordan
La policy du StorageClass Ceph est laissée sur "Delete" pour s'assurer que nos volumes sont bien supprimés lorsqu’un pod est détruit sinon il faut s’assurer de faire la suppression manuellement.
# Obtenir les infos sur la sauvegarde
velero backup get
velero backup logs backup-couchdb-test --details
# On initie le processus de restauration, depuis notre dernier backup, verdict ?
velero restore create restore-couchdb-test --from-backup backup-couchdb-test
# Obtenir plus de détails
velero restore describe restore-couchdb-test
velero restore logs restore-couchdb-test --details
Exemple de cas concret :
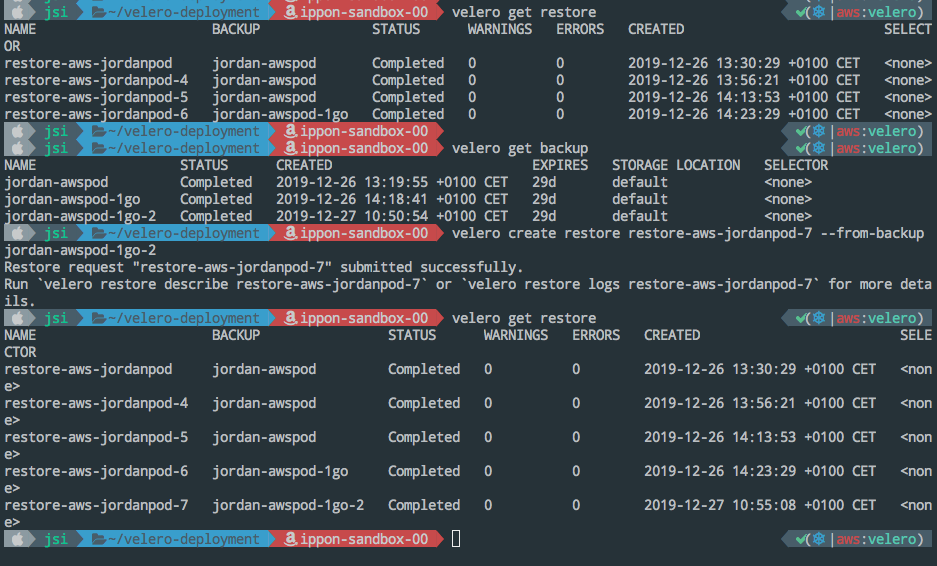
La restauration complète du namespace peut prendre un certains temps mais nous pouvons vérifier sa progression grâce à l’option --details.
Pour les pods, Restic provisionne un sidecar qui va permettre de recréer les volumes originaux présent sur Minio.
Et enfin, une fois le pod à nouveau Running, nous retrouvons la présence des données dans le nouveau pod restauré :

Hourra \o/ nos données sont de nouveau là.
Conclusion
Il s'agit d'un simple retour d'expérience pour vous aider à sauvegarder vos applications stateful sur Kubernetes.
Nous avons pu voir que l’ensemble des composants se configure aisément et correspond à notre besoin, à savoir, sauvegarder les données Stateful de nos apps sur Kubernetes.
Les développements sont actifs du côté de Velero et l’écosystème Kubernetes commence à porter un peu plus d’attention aux apps stateful jusqu’alors mise de côté.
J'espère que cela aura pu aider certains d'entres vous à démystifier l'univers Kubernetes et notamment la sauvegarde de vos applications stateful.
