

Introduction
L’univers Kubernetes n’ayant pas été pensé pour utiliser des volumes persistants à sa conception, il peut s'avérer vite complexe de devoir gérer des données entre les différents nodes.
Dans le cas d’une utilisation d’un Kubernetes managé, cette gestion peut être facilitée via l’usage de volumes répliqués par défaut (ex: gp2 sur aws) mais cela nous oblige à définir des affinités (ex: PodAffinity, NodeAffinity) pour le placement de nos pods sur un node spécifique.
Par ailleurs, le problème n’est pas totalement résolu, car dans le cas d’un ScaleIN/ScaleOut de nos instances, les pods peuvent se retrouver sans leurs volumes persistants. Pour pallier à ce problème, nous devons utiliser un stockage sous-jacent partagé afin de nous affranchir de ce problème récurrent.
Aujourd’hui, Kubernetes prend en charge plusieurs solutions de stockage externe dont GlusterFS, Portworx, NFS, RBD (Ceph) etc.
Contexte
Sur notre infrastructure On-Premise nous avons déjà un cluster Ceph à disposition.
Pour le besoin de ce POC nous allons installer un cluster Ceph sur le cloud AWS et le rendre disponible pour notre cluster Kubernetes (EKS).
Nous aurions pu utiliser le service EFS (NFS) nativement disponible sur AWS mais l’utilisation de ce dernier peut vite engendrer des coûts importants.
Ainsi, nous allons voir comment on peut lier Kubernetes et Ceph afin de pouvoir stocker nos volumes de manière persistant dans un environnement multi-nodes.
Ceph comme stockage externe
Kubernetes supporte le stockage externe Ceph pour ces deux modes : CephFS et RBD. Nous couvrirons essentiellement le mode RBD (Rados block Device) dans cet article.
La première étape à prendre en compte avant l’installation de nos noeuds Ceph est le choix de l’OS.
En effet, Ceph ne supporte pas les AMI "Amazon Linux 2".
Il est donc préférable de partir sur un distribution Ubuntu-like ou RedHat-like avec des ressources systèmes suffisantes.
À part cela, l’installation d’un cluster Ceph n’est pas très différente sur AWS qu’en On-Premise.
Voici tout de même quelques préconisations à respecter afin que le déploiement se passe correctement :
- Vérifiez et ajustez vos securityGroups (ex: port tcp 6789)
- Installez vos instances dans des private subnets de votre VPC
- Renseignez bien vos /etc/hosts ou votre service R53 private hosted zone pour l'ensemble de vos instances
- Créez une keypair dédiée qui sera partagée
- Installez la même version de Ceph sur l'ensemble de vos noeuds et veillez à bien séparer les services sur des instances différentes (ex: mon / osd etc.)
- Renseignez les paramètres public_network / mon_host dans ceph.conf avec vos subnets respectifs
- N'oubliez pas de partager vos keys avec ssh-copy-id et de modifier vos fichiers .ssh_config avec l’utilisateur Ceph dédié et les hostname correspondants
Une fois votre déploiement terminé, vérifiez que votre cluster est fonctionnel :
- Le Ceph status est bien Health OK
- Le Quorum est respecté
- Les OSDs sont bien tous UP/UP et qu'il n'y ait pas d'erreurs
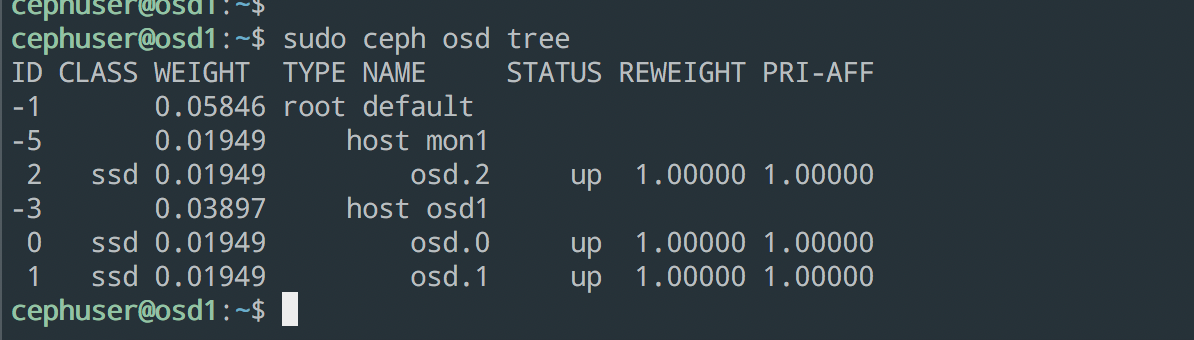
Il est maintenant temps de faire la configuration pour créer un pool RBD dédié à nos applications stateful.
Pour faire la liaison entre Kubernetes et Ceph nous allons devoir créer un pool de stockage dédié pour les applications stateful et également créer différents secrets partagés.
Voici les étapes nécessaires :
# Obtenir l’admin secret global :
ceph auth get client.admin 2>&1 |grep "key = " |awk '{print $3'} |xargs echo -n > /tmp/key
# Créer le admin secret sur k8s
kubectl create secret generic ceph-admin-secret --from-file=/tmp/key --namespace=kube-system --type=kubernetes.io/rbd
Ici, ne pas oublier de mentionner le type de secret, sans quoi, l’authentification ne serait pas fonctionnelle.
# Création du pool Ceph dédié
ceph osd pool create rbdaws 8 8
# Ajout des permissions au pool Ceph
ceph auth add client.rbdaws mon 'allow r' osd 'allow rwx pool=rbdaws'
# Obtenir le secret client
ceph auth get-key client.rbdaws > /tmp/key
# Création du secret client (lié au pool)
kubectl create secret generic ceph-secret --from-file=/tmp/key --namespace=kube-system --type=kubernetes.io/rbd
Après ces étapes, nous avons un cluster Ceph fonctionnel avec un pool RBD dédié prêt à recevoir nos données depuis Kubernetes.

Quant à Kubernetes, il est dorénavant capable de s’authentifier sur Ceph.
Néanmoins, Il reste une étape afin que l’on puisse créer notre premier volume sur Ceph.
Nous devons créer une nouvelle classe de stockage (StorageClass) afin que l’on puisse contacter notre cluster Ceph.
Création du StorageClass pour Ceph RBD
La configuration d'un StorageClass n'est pas des plus difficile mais nécessite une configuration particulière pour Ceph.
En voici un exemple
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ceph
selfLink: /apis/storage.k8s.io/v1/storageclasses/ceph
parameters:
adminId: admin ## Ceph client ID qui est capable de créer des images dans le pool. La valeur par défaut est admin
adminSecretName: ceph-secret ## Nom secret pour l'administration. Il est obligatoire. Le secret fourni doit être de type kubernetes.io/rbd.
adminSecretNamespace: kube-system ## L'espace de noms pour adminSecret. La valeur par défaut est default.
monitors: 172.31.XX.XX:6789,... ## Correspond à nos moniteurs CEPH
pool: rbdaws ## pool dédié
userId: rbdaws ## utilisateur du pool
userSecretName: ceph-user-secret ## Le nom de Ceph Secret pour l'utilisateurId pour cartographier l'image Ceph RBD. Il doit exister dans le même espace de noms que les PVC.
provisioner: ceph.com/rbd ## Pointe vers notre RBD-provisionner et non le provisionner par défaut kubernetes.io/rbd (utilisé on-prem)
reclaimPolicy: Delete
volumeBindingMode: Immediate
Il faut bien évidemment faire correspondre cette configuration avec celle que l'on aura définie sur Ceph.
Il nous est maintenant possible de provisionner notre premier volume persistant sur notre nouveau StorageClass "ceph".
Il suffit d'exécuter le manifest suivant :
cat << EOF | Kubectl apply -f -
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: ceph-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: ceph ## Ici, on choisit notre StorageClass Ceph
EOF
Alors ? Alors ? Ah … finalement, cela ne fonctionne toujours pas …
Provisionnement de volume RBD pour Kubernetes
Actuellement, le provisionnement dynamique des volumes RBD, n’est pas possible avec l’image officielle pour EKS.
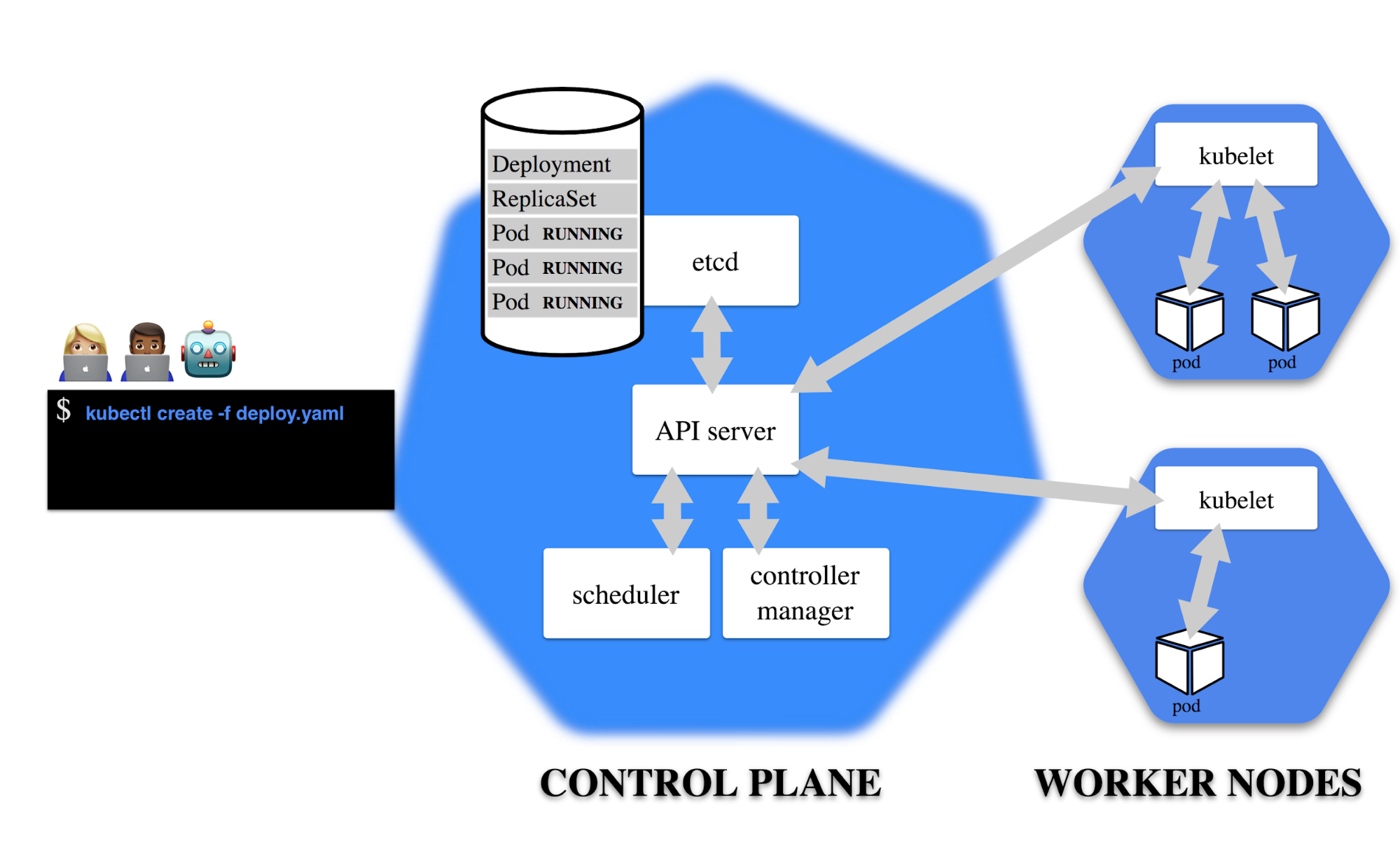
En effet, pour pouvoir faire cela, il faut que le control-plane de Kubernetes (en l'occurrence le controller-manager) puisse effectuer les opérations de map / unmap des volumes RBD.
Cela s’effectue grâce au binaire rbd présent dans le paquet ceph-common.
Exemple de code de retour lors de la création d'un pvc :
Actual results:
Warning ProvisioningFailed 1s persistent volume-controller Failed to provision volume with StorageClass "ceph": failed to create rbd image: executable file not found in $PATH, command output: ...
Mounted By: <none>
Pour résoudre cette erreur, des étapes supplémentaires sont nécessaires :
- Sur AWS, avec un Kubernetes managé nous n’avons pas accès au système gérant le controller-manager, Il faudra donc contourner ce problème en passant par l’installation d’un provisionneur externe.
Dans ce cas, nous aurons recours à un conteneur "RBD-provisioner" ayant l'utilitaire rbd inclus, ainsi le controller-manager n'aura plus besoin d'accéder au binaire rbd pour provisionner des volumes, mais il utilisera le provisionneur créé spécifiquement.
- Sur un Kubernetes On-Premise, il nous suffira d’installer le paquet sur les nodes exécutant le controller-manager.
Nous pourrons alors nous affranchir du RBD-provisioner car nous avons l'accès complet au control plane afin de faire les modifications nécessaires.
Néanmoins, dans les 2 cas, Kubelet, présent sur les workers nodes a besoin d'accéder également au binaire rbd afin d’attacher et détacher les volumes sur les pods.
- Sur AWS, nous utiliserons des AMI personnalisées afin d'inclure le binaire rbd sur les worker nodes.
Nous verrons dans un autre article comment nous pouvons personnaliser ces images.
- On-Prem, nous installerons directement le packages ceph-common sur l'hôte faisant tourner Kubelet.
Une fois ce contre temps passé, nous sommes en mesure de provisionner dynamiquement notre volume sur Ceph depuis Kubernetes.
Voici notre PVC récemment créé sur le StorageClass Ceph :

Et le PV associé à l’état Bound :

\o/ Hourra !!
Bonus: RBD Provisioner pour EKS
Ce provisionner externe reste essentiel pour réussir à faire cohabiter Kubernetes et Ceph sur AWS, sans quoi les volumes persistants ne pourraient ni être créés ni même utilisés.
Extrait de la doc officielle
rbd-provisioner est un provisionneur dynamique out-Tree pour Kubernetes 1.5+. Il permet d’être utilisé rapidement et facilement pour déployer un stockage ceph RBD compatible avec Kubernetes
Les fichiers YAML de déploiement peuvent être trouvés ici pour une gestion avec rbac et ici pour un gestion non rbac.
Voir aussi les explications sur la docs Kubernetes.
Astuce
Il se peut que le conteneur n'arrive pas à se lancer à cause des autorisations RBAC manquantes.
Dans mon cas, il a fallu ajouter l'autorisation "list" pour la ressource "events" dans le ClusterRole.yaml.
Extrait du fichier deployement.yaml
containers:
- name: rbd-provisioner
image: "quay.io/external_storage/rbd-provisioner:latest"
env:
- name: PROVISIONER_NAME
value: ceph.com/rbd ## Cette variable d'env correspond à celle fournie dans le StorageClass (ex: provisioner: ceph.com/rbd)
Bien faire attention à la version de l’image afin qu’elle soit compatible avec votre version de Ceph. (voir ici)
Conclusion
La méthodologie vue dans cet article pour interconnecter Kubernetes et Ceph reste sensiblement la même que pour connecter d’autres sources de stockage externe.
Nous avons ainsi, un cluster Ceph externe relié à notre cluster Kubernetes qui va stocker les données persistantes de nos pods de manière redondée et partagée à l’ensemble des nodes.
Enfin, depuis les dernières releases de Kubernetes, les plugins CSI implémentent maintenant une interface entre le Container Orchestrator (CO) et le cluster Ceph. Cela permet de provisionner dynamiquement des volumes Ceph et de les attacher à des charges de travail tout en restant in-Tree contrairement au provisioner externe.
