

Dans les 3 précédents articles, nous avons pu voir :
- article #1 : La théorie relative à la sécurisation des bases de données PostgreSQL
- article #2 : L'application de ces concepts sur un exemple concret avec construction de notre base dans le cloud et création d'un user admin
- article #3 : Le déploiement des rôles, permissions, users pour répondre aux besoins fonctionnels de notre application, ainsi que la gestion et la rotation des mots de passe.
Aujourd'hui, attachons nous à décrire une fonctionnalité, pas toujours nécessaire, l'auditabilité de vos bases de données.
Fonction avancée : SOC et Auditabilité
Quelques mots concernant la mise en œuvre d’un système d’auditabilité dans un moteur PostgreSQL. Cette fonctionnalité est apportée par l’installation d’une pg_extension : pgaudit.
En spécifiant dans le fichier postgresql.conf, la directive log_statement = all, cela vous permettra de logguer une partie des requêtes exécutées sur la base. Cela est acceptable pour la surveillance et d'autres utilisations mais ne fournit pas le niveau de détail généralement requis pour un audit, notamment de pouvoir suivre les requêtes exécutées dans les fonctions ou les procédures stockées. pgAudit répond à cette problématique.
Mon module prend en charge l’installation des pg_extensions, tout du moins sur une base déployée sur AWS. Je n’ai malheureusement pas eu le loisir de le tester sur un moteur de base de données installé manuellement.
A noter qu’il est possible de déployer une pg_extension a posteriori, une fois une instance de base de données existante. Il faudra faire un arrêt-relance de la base pour que celle-ci soit active.
Dans le cadre d’une instance RDS, AWS a packagé la possibilité d’installer différentes pg_extensions. Pour obtenir la liste, exécuter la requête suivante :
select * from pg_available_extensions order by name;
J’en cite 2 que j’ai pu mettre en oeuvre :
- pg_stat_statements pour la mise en œuvre de statistiques sur les tables.
- aws_s3 pour pouvoir faire des dumps de vos données directement sur s3.
Installation & Configuration
Pour activer notre extension pgaudit, dans le fichier terraform.tfvars :
# install extensions if needed
extensions = ["pgaudit"]
Pour que l’extension fonctionne, nous devons passer un certain nombre de paramètres. Cela est fait par l’intermédiaire de la ressource aws_db_parameter_group.
Ce “groupe de paramètres” rassemble 2 types de paramètres que vous pouvez appliquer sur une instance RDS : les paramètres de type immediate et ceux de type pending_reboot.
Les paramètres liés aux pg_extensions sont du second type. Le fichier terraform.tfvars fournit :
parameter_group_params = {
immediate = {
autovacuum = 1
client_encoding = "utf8"
log_connections = "1"
log_disconnections = "1"
log_statement = "all"
}
pending-reboot = {
shared_preload_libraries = "pgaudit",
track_activity_query_size = "2048",
"pgaudit.log" = "ALL",
"pgaudit.log_level" = "info",
"pgaudit.log_statement_once" = "1"
}
}
Se référer à https://github.com/pgaudit/pgaudit#settings pour le détail de la configuration. Le détail de la procédure est disponible dans la documentation officielle AWS ici :
https://aws.amazon.com/premiumsupport/knowledge-center/rds-postgresql-pgaudit/?nc1=h_ls
Les paramètres pending_reboot, comme leur type l’indique, ont besoin d’un arrêt relance de la base afin qu’ils soient pris en compte. Dans notre cas, comme il s’agit de la création, ceux-ci seront pris en compte au démarrage de la base.
Lorsque la base RDS a été déployée, l’extension est active et fonctionne. On peut déjà ausculter les logs qui sont envoyés. D’abord depuis la console RDS : Onglet Logs & Events, trier les fichiers par la colonne Last Written, sélectionner le dernier log et cliquer sur le bouton watch.
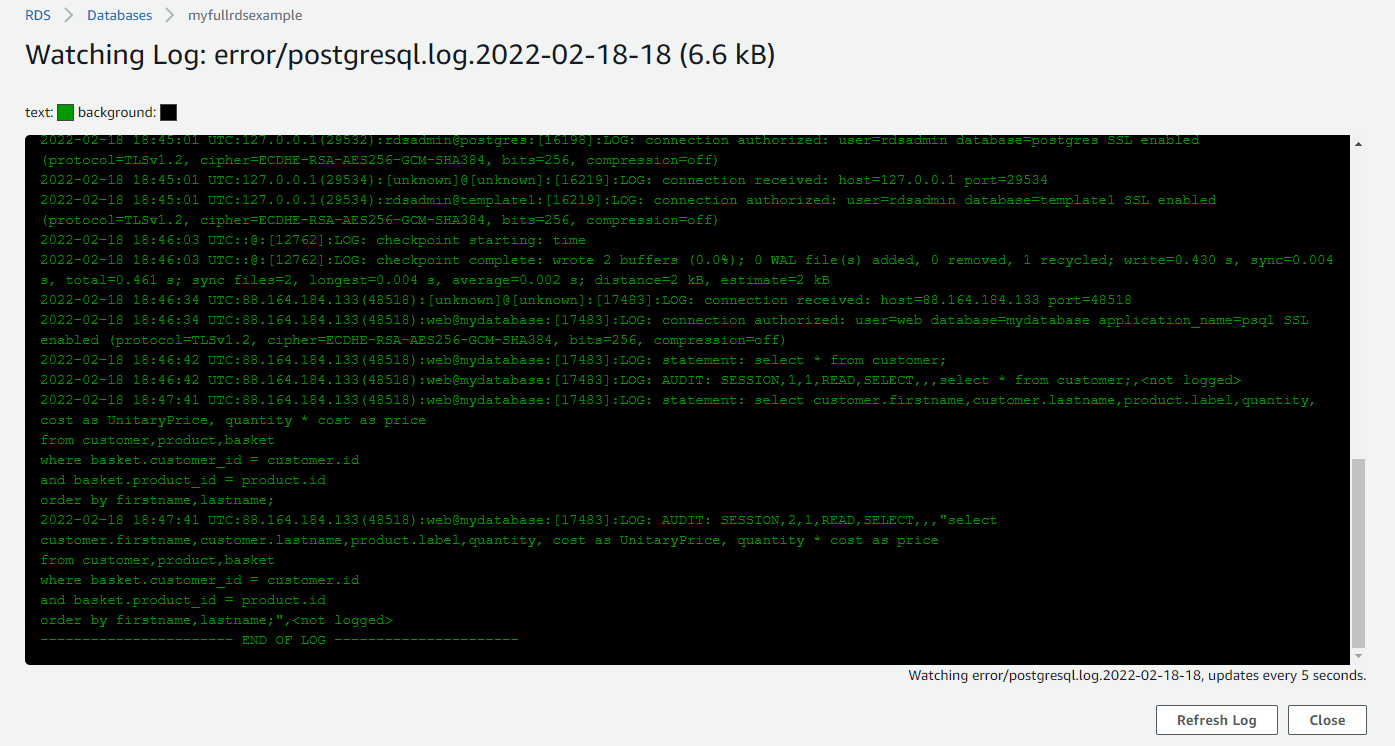
Vous pouvez également le faire directement depuis l’API RDS, comme le montre le script suivant :
#!/bin/bash
export INSTANCE_IDENTIFIER=`terraform output|grep db_instance_id|awk -F '=' '{print $2}'|sed 's/^ *//g'|sed 's/"//g'`
LOGFILE=$(aws rds describe-db-log-files --db-instance-identifier ${INSTANCE_IDENTIFIER} --query 'DescribeDBLogFiles[-1].[LogFileName]' --output text)
echo "LOGFILE = $LOGFILE"
aws rds download-db-log-file-portion \
--db-instance-identifier ${INSTANCE_IDENTIFIER} \
--starting-token 0 \
--log-file-name "${LOGFILE}" \
--output text | grep AUDIT
Le grep AUDIT tronque les requêtes qui comportent plusieurs lignes.
Déploiement Elasticsearch & Indexation des logs
Pour simuler un outil de SOC, qui nous permettra d’indexer nos logs, revenons sur le fichier terraform.tfvars et passons la variable create_elasticsearch à true :
################################################
# Elasticsearch
################################################
create_elasticsearch = true
es_instance_type = "t3.small.elasticsearch"
es_instance_count = 1
es_ebs_volume_size = 10
Comme pour l’instance RDS, le domaine elasticSearch est créé de manière à ce qu’il soit publiquement exposé. Afin de limiter l’exposition, une domain policy est appliquée dans laquelle on restreint les adresses IP source à notre adresse IP de sortie personnelle.
Pour créer le cluster, on utilise le module de la registry écrit par “cloudposse” :
########################################
# Retrieve infos on AWS STS Caller
########################################
data "aws_caller_identity" "current" {}
###########################################
# Deploy an Elasticsearch Cluster
###########################################
module "elasticsearch" {
source = "cloudposse/elasticsearch/aws"
version = "0.35.0"
# create or not all related resources inside the module
enabled = var.create_elasticsearch
# naming
namespace = "soc"
stage = var.environment
name = "es"
# config
vpc_enabled = false
zone_awareness_enabled = false
elasticsearch_version = "7.4"
instance_type = var.es_instance_type
instance_count = var.es_instance_count
ebs_volume_size = var.es_ebs_volume_size
iam_role_arns = [aws_iam_role.lambda-role.arn]
iam_actions = ["es:ESHttpGet", "es:ESHttpPut", "es:ESHttpPost"]
encrypt_at_rest_enabled = "true"
kibana_subdomain_name = "kibana-soc"
create_iam_service_linked_role = false
allowed_cidr_blocks = var.allowed_ip_addresses
advanced_options = {
"rest.action.multi.allow_explicit_index" = "true"
}
}
Une fois que le domaine elasticSearch est déployé, il ne reste plus qu’à souscrire le cloudwatch log group contenant les streams des logs de la base RDS (dont ceux générés par pgaudit) sur l’endpoint de l’elasticsearch.
Il est possible de le faire depuis la console. Suivez ce blog pour le faire “proprement” :
https://aws.amazon.com/blogs/database/analyze-postgresql-logs-with-amazon-elasticsearch-service/
Pour le faire de manière programmatique, j’ai publié un autre module sur la registry qui encapsule les ressources nécessaires :
###########################################
# Deploy a subscription filter on RDS CloudWatch Logs
# to stream logs on an Elasticsearch domain endpoint
###########################################
module "stream2es" {
source = "jparnaudeau/cloudwatch-subscription-elasticsearch/aws"
version = "1.0.0"
for_each = var.create_elasticsearch ? toset(["1"]) : []
# global variables
region = var.region
environment = var.environment
tags = local.tags
# other variables
function_name = local.lambda_function_name
rds_name = var.rds_name
rds_cloudwatch_log_name = format("/aws/rds/instance/%s/postgresql",var.rds_name)
es_domain_endpoint = try(module.elasticsearch.domain_endpoint, "")
source_account_id = data.aws_caller_identity.current.account_id
lambda_role_arn = aws_iam_role.lambda-role.arn
}
Ce module est en charge de :
- déployer une fonction lambda qui va streamer les logs d’un cloudwatch log group. Ici, en l'occurrence, les logs de la base RDS. Le code de la lambda est le code source officiel fourni par AWS. 2 modifications sont apportées : d’une part, le passage de l’endpoint du domaine Elasticsearch en tant que variable d’environnement de la lambda, au lieu de le “hardcoder” comme cela est fait quand vous créez la souscription depuis la console, et d’autre part, le fait de suivre les bonnes pratiques en ayant un index elasticSearch par jour.
- déployer la souscription de la fonction lambda sur le cloudwatch log group. Un
filter patternest appliqué : [date, time, misc, message].
Une fois l’apply terminé, vous devriez pouvoir afficher l’instance kibana (fourni dans les outputs) et voir en quasi temps réel les logs de la base. Si on génère un peu d’activité, vous devriez voir quelque chose comme ceci :
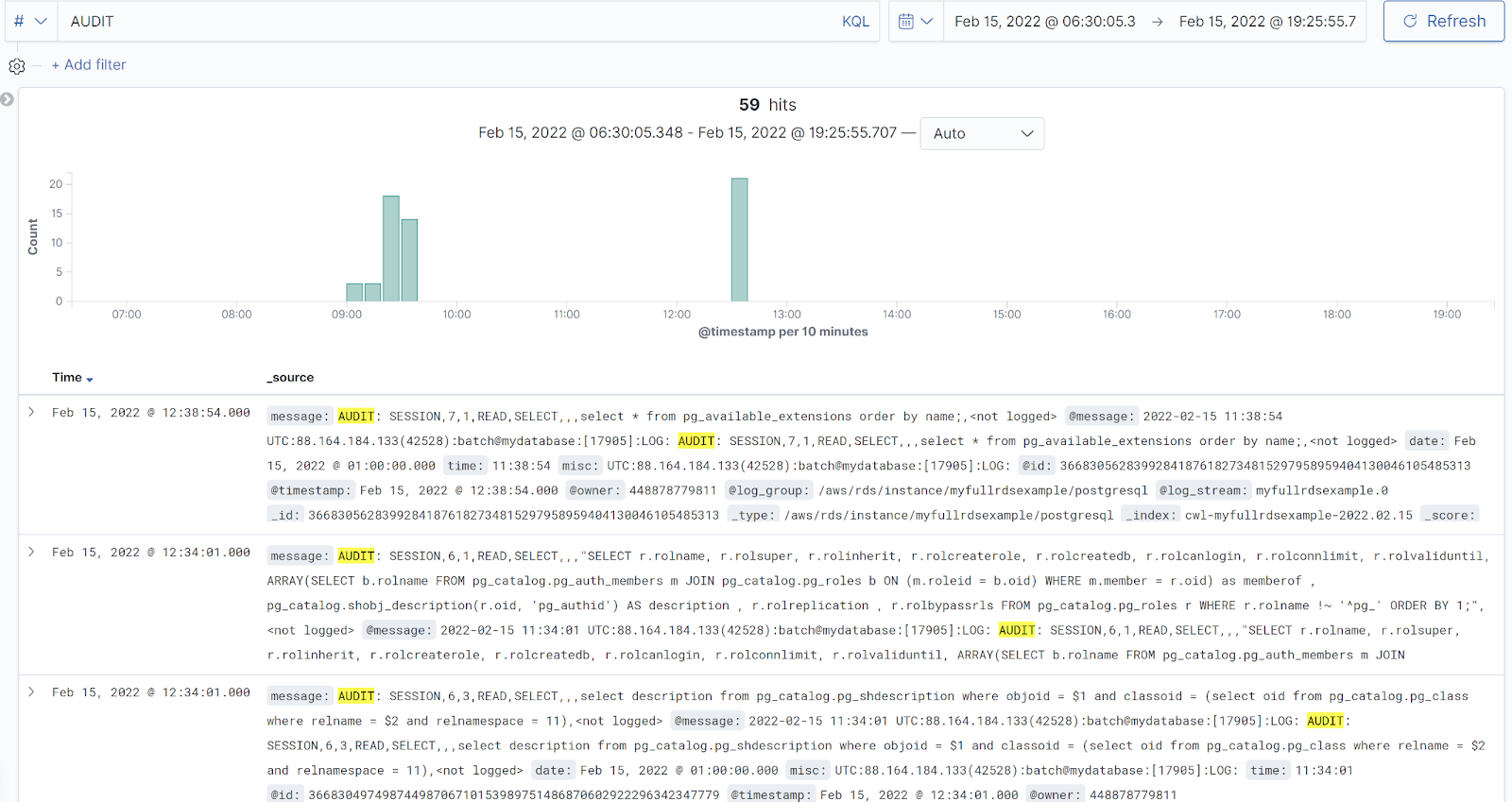
On peut filtrer les logs d’audit pour sortir toutes les requêtes exécutées sur la table customer par exemple : message:*AUDIT* and message:*customer* :

On peut également filtrer les logs d’audit pour sortir toutes les requêtes exécutées par un user donné : message:*AUDIT* and misc:*batch*

Notez que l’on voit toutes les requêtes exécutées, même celles exécutées à travers la procédure stockée, ce qui n’est pas le cas avec le système de logging par défaut.
Conclusion
A travers les fonctionnalités couvertes par mon module terraform, on a vu qu’il est possible facilement de mettre en œuvre une vraie gestion des users dans les bases PostgreSQL. Avec les primitives offertes par le provider PostgreSQL, on a démontré dans cette suite d’articles comment mettre en œuvre les bonnes pratiques de sécurité, voir même comment déployer un système d’auditabilité.
Bien évidemment, il reste encore du travail. D’abord, sur la rétention des logs dans votre outil de SOC. D’autre part, c’est une réponse technique à une problématique. Mais il y a un coût derrière. Mais l’un ne va pas sans l’autre généralement. Notez également que l’activation de l’extension pgAudit génère des logs en plus, qui doivent être pris en compte lorsque vous dimensionnerez la taille du stockage de votre base. L’aspect performance pouvant être également un aspect qui influencera le niveau de verbosité souhaité.
L’ensemble des éléments décrits dans cet article sont disponibles dans l’exemple “full-rds-exampe” dont je vous redonne le lien :
La partie la plus “pénible” du travail consiste à écrire exhaustivement la liste des rôles et des permissions. Vous pouvez néanmoins vous appuyer sur la structure présente dans les fichiers terraform.tfvars de l’ exemple.
N’hésitez pas à me contacter jparnaudeau@ippon.fr si vous souhaitez obtenir plus d’informations.
N’hésitez pas non plus à créer des issues sur mon repo github si vous voyez des améliorations ou des bugs à corriger.
Pour ceux qui seraient intéressés par la fonctionnalité de mapping des users sur des rôles IAM dans AWS, je vous redirige vers l'excellent article de mon collègue Mathieu Regnard ici.
Bon déploiement à tous,
