

L’objet de cet article est de présenter et partager mon retour d’expérience sur l’outil Airbyte, fraîchement sorti en juillet 2020. La documentation met en avant le fait de pouvoir acheminer de la donnée vers un entrepôt de données de manière simplifiée. Est-ce vraiment le cas ? Et au niveau de l’intégration dans mon architecture ? Il me manque un connecteur, l’implémentation se fait-elle réellement en deux heures ?
Dans cet article, je répondrai à ces questions en me basant sur mon expérience personnelle lors d’une mission chez un client. En effet, j’ai eu l’occasion de monter une plateforme de données “from scratch”, une occasion idéale pour intégrer l’outil dans mon architecture.
Dans un premier temps je présenterai Airbyte, puis l’intégration dans mon architecture, pour enfin finir sur un retour d’expérience.
Présentation Airbyte
Airbyte est une solution open source permettant d’effectuer de l’intégration de données en s’occupant seulement de la configuration des sources et des destinations sans se préoccuper de l'implémentation de l’ingestion. La volonté des créateurs est de répondre à un manque de standardisation dans le processus d’ingestion de données dans une data plateforme.
L’application fournit le nécessaire afin d’être autonome et ne plus dépendre d’un service de support mais plutôt d’une communauté. En effet, sur le site officiel, une documentation complète permet de prendre en main l’environnement technique. Toute l’implémentation est centralisée dans un seul dépôt GitHub.
Concernant les détails techniques, Airbyte est développé en Java et Javascript (React). Une présentation exhaustive ainsi qu’une explication des choix techniques est disponible sur le site officiel.
La prise en main est très intuitive ! L’application est ergonomique, le principe est simple : configurer des sources, destinations et connexions puis les scheduler afin de construire des pipelines de données.
- Source
La source se charge de la partie connexion et authentification (API REST, base de données …). Chaque source possède sa propre documentation ainsi qu’une configuration sous la forme d’un formulaire.
- Destinations
La destination est l'entrepôt dans lequel les données sont écrites. Comme pour les sources, chaque destination possède sa documentation ainsi que son formulaire de paramétrage.
- Connexions
Une connexion est le lien entre une source et une destination, son paramétrage permet de sélectionner les données, choisir un type d’ingestion (full, incremental) et ajouter un coordinateur. Une transformation via DBT peut être ajoutée ainsi qu'une normalisation des données.
À l’aide de simples paramétrages, il est possible d'extraire, normaliser et nettoyer des données provenant de différents types de sources. Cela permet d’avoir une standardisation des pipelines provenant de sources hétérogènes tout en ayant un visuel facilitant la maintenance. Ce gain de temps sur la construction ainsi que la maintenance de nos pipelines permet de se focaliser plus sur l’analyse et la valorisation des données ingérées.
Concernant le déploiement, aucune perte de temps ! Nous sommes libres de récupérer et déployer l’application que ce soit en local ou sur un cloud provider. L’application est Docker-Based et une documentation contenant plusieurs types de déploiements est disponible.
En parlant de déploiement, une solution Airbyte Cloud est proposée, il s’agit d’un service hébergé de l’application. L’application est managée, l’utilisateur effectue ses ingestions à l’aide d’une simple application web. De plus, un module d’authentification est intégré contrairement à la version open source.
Un nouveau type de tarification inhabituel est proposé basé non pas sur le volume de données mais sur la durée de calcul (pay-as-you-go). Cette nouvelle tarification lui permet de se démarquer des autres services ETL/ELT. Une estimation ainsi qu’un comparatif est disponible sur le site officiel en répondant à une série de questions, j’ai effectué le comparatif, en effet sa tarification est intéressante. Je pense que ce n’est pas nécessaire de passer par cette solution lorsque l’on a peu de connecteurs et que l’on souhaite avoir la main sur l’application pour ajouter des fonctionnalités (création d’un connecteur sur-mesure).
Ce qui m’a surtout plu sur le produit est son côté extensible. En effet, j’ai souvent eu la frustration d’avoir un outil performant à ma disposition mais qui nécessite une adaptation afin que cela puisse être utilisé dans mon contexte. Ce qui conduit souvent à un va-et-vient avec le support pour in fine abandonner et trouver une solution de contournement. Par conséquent, il est difficile de trouver une solution technique permettant d’intégrer tous types de données tant les sources sont hétérogènes. Les utilisateurs sont souvent confrontés à un cas particulier qui nécessite un connecteur sur-mesure. Le kit de développement proposé, accompagné d’une documentation détaillée, permet la création de son propre connecteur sans difficulté. Personnellement cela m’a pris une journée pour le premier connecteur et une seule heure pour le deuxième. Selon la documentation, un connecteur peut être créé en deux heures en étant libre de choisir son langage de programmation (Docker-Based) : Libre choix sur le langage de programmation tant que les spécifications sont respectées !
Je pense avoir fait le tour niveau présentation, le but de cet article n’est pas de s’étendre sur une présentation détaillée qui est disponible sur le site du produit mais plutôt sur un retour d’expérience :).
Cas d’utilisation
Dans mon cas d’usage, j’ai créé une data plateforme open source sur Google Cloud Platform (GCP) afin de produire un tableau de bord sur des KPIs d’organisation d’une entreprise. L’objectif était d’avoir un visuel pour cibler des axes d’amélioration comme le temps que met un nouvel arrivant pour effectuer sa première pull request, le temps que met un développeur pour faire une revue de pull request, comment est géré le backlog ...
Airbyte a été intégré comme brique technologique afin d’extraire les données GitHub, Asana et Google sheet puis effectuer le chargement dans l’entrepôt de données.
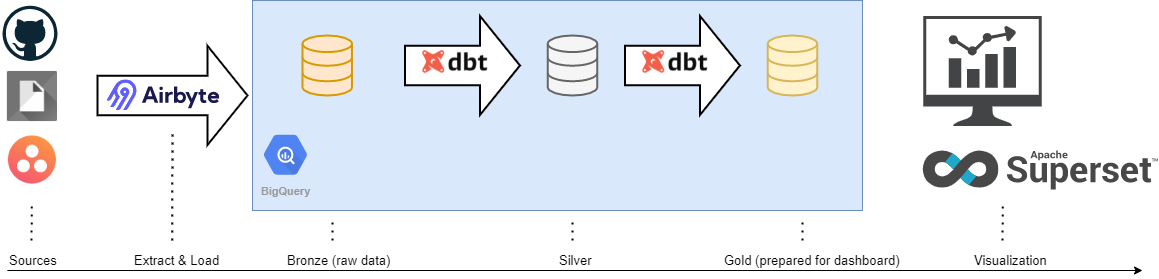
Afin de récupérer toutes les données et construire les KPIs, j’ai utilisé les connecteurs disponibles pour GitHub, Asana et Google Sheet. Cependant certains endpoints n’étaient pas supportés par le connecteur GitHub, une modification à été nécessaire afin d’ajouter les endpoints liés aux GitHub actions ainsi que les vulnerabilities alerts.
Pour faciliter la maintenance et avoir une organisation des transformations de la donnée, j’ai utilisé le pattern Bronze, Silver, Gold.
- Bronze : les données brutes ingérées sans aucune transformation
- Silver : nettoyage, anonymisation, typage des données
- Gold : Agrégation et croisement des données.
Dans notre cas, l’outil Superset est utilisé afin de construire nos tableaux de bord interactifs. L’application consomme les données présentes dans la partie Gold et fournit le visuel adapté.
Bonne surprise
Tout est Docker-based, on comprend très vite le fonctionnement, plusieurs images docker pour l'application et une image par connecteur. J'ai été surpris par l'aisance de son déploiement, une documentation précise et complète est fournie sur différents providers (GCP, AWS, Azure ...).
Concernant la modification de l'application, une documentation nous encourage et fournit tous les outils nécessaires pour contribuer à son évolution. De plus le Slack est dynamique et contient des _canaux _dédiés aux différents types d'améliorations (development, connector-development, troubleshooting ...), je ne vous cache pas que je ne m’en suis pas privé.
Airbyte propose une normalisation des données permettant d’avoir des données propres, prêtes à être analysées et croisées dans la destination configurée. J’ai trouvé cette normalisation performante notamment sur le parsing des réponses des APIs, lorsque la réponse contient des JSON imbriqués ou des tableaux, la normalisation se charge de mettre les données à plat dans différentes tables avec des IDs intégrés afin d'effectuer des jointures par la suite. Quel bonheur de ne pas à avoir à ajouter des scripts de parsing à modifier après chaque mise à jour d’une API REST. Cependant, cela impacte la robustesse des pipelines. En effet, lors de la normalisation, une inférence de schéma est effectuée afin d’écrire les tables dans l’entrepôt de données. En cas de changement au niveau de la source, les pipelines incrémentaux peuvent être fragilisés. Je pense que cet outil est intéressant dans le cas où une source de données ne change pas ou que l’utilisateur a la main dessus.
De par son côté extensible, je me suis rendu compte que je n’avais plus le réflexe de regarder si l'application propose un connecteur adéquat pour me connecter à une source particulière mais plutôt regarder si la source de données possède une API ou base de données le permettant.
Mauvaise surprise
Cependant j'ai rencontré quelques soucis dus à son manque de maturité. En effet nous sommes à la version 0.35.3, quelques bugs sont encore présents notamment sur l’import de configurations qui ne fonctionne pas. Pas très agréable de s’en rendre compte la veille d’une démo. Une solution est de passer par l'API. De plus, l'application ne peut être exposée par souci d'authentification intégrée.
Des fonctionnalités sont en mode beta ou comming soon. Les connecteurs sont catégorisés en 3 parties :
- Alpha: Le connecteur n’est pas assez mature, faiblement testé et présente des fonctionnalités limitées.
- Beta: Le connecteur est testé et fonctionnel mais peut présenter certains défauts pour des cas particuliers dus à sa sortie récente. Pour finir dans la catégorie Verified.
- Verified: Le connecteur est utilisé par une large communauté, testé, robuste et maintenu par Airbyte.
Il est important de prendre en compte ce statut. Une liste contenant tous les connecteurs ainsi que leurs catégorisations est disponible.
Conclusion
En résumé, Airbyte permet d'effectuer une extraction et un chargement de données de manière aisée et standardisée en proposant différents connecteurs. Seul un paramétrage est nécessaire, ce qui permet de consacrer plus de temps sur le côté analyse de données plutôt que construction de l'ELT.
Son côté open source permet une constante évolution. La documentation fournit tout ce qui est nécessaire pour s'approprier l'application et ajouter des éléments. La communauté active ainsi que la disponibilité des développeurs Airbyte dans le Slack est un plus.
Airbyte est conscient que l'application n'est pas "production-ready" et fourni une roadmap des changements classés en différentes catégories :
- Coming within a few days
- Coming within a few weeks / months
- Coming within a few quarters / years
Il est intéressant de suivre son évolution et de l'intégrer dans une plateforme de données moderne. Cela pousse néanmoins à se poser quelques questions :
Le coût de maintenance est-il conséquent ?
L’outil est open source, la communauté est-elle active ?
La courbe d’apprentissage de l'implémentation de l'application est-elle conséquente ?