

Malgré le “boom” autour des technologies de la data, les bases de données relationnelles restent la technologie la plus répandue dans les systèmes informatiques des entreprises. Passé le cap de l’hégémonie d’Oracle, PostgreSQL, en tant que base de données relationnelle open source, s’est imposée sur la dernière décennie.
Grâce à “l’infrastructure As Code”, le déploiement des bases de données PostgreSQL est devenu simple, automatisable et intégrable dans les pipelines CI/CD. Toutefois, d’après mon expérience, c’est à partir de ce moment que les vrais problèmes commencent, tout du moins, du point de vue de la sécurité.
Avant de rentrer dans le dur, quelques mots sur la démarche. J’ai récemment publié sur la terraform registry un module de mon cru : jparnaudeau/database-admin.
Vous pourrez retrouver l’intégralité du code parcouru dans ces articles en consultant l’exemple full-rds-example disponible dans le module.
Ce 1er article couvre l’aspect théorique de la sécurité autour d'une base PostgreSQL :
- L'encryption at Rest
- L'encryption at Transit
- La gestion des Secrets
- La gestion des rôles et des permissions
- Le principe du "Least Privilege"
Les 3 articles suivants décriront pas à pas l’application de ces principes :
- Comment créer proprement les rôles, les permissions et les users,
- Comment appliquer le principe de Least Privilege,
- Comment déployer un système d’auditabilité, parfois nécessaire pour les entreprises exerçant dans des activités soumises à des réglementations (domaine médical par exemple) ou à des contraintes liées à la régulation des marchés (domaine financier ou assurance).
A titre de démonstration, on couplera ce système d'auditabilité avec un outil de “SOC” (Security Operation Center), en l’occurrence Elasticsearch dans notre cas. J’ai choisi le cloud provider AWS pour me fournir l'infrastructure et une instance de base. Néanmoins, le module fournit un “docker-compose” qui vous permettra de réaliser vos tests directement depuis une image PostgreSQL. Le module est indépendant de l’infrastructure sous-jacente.
Effectuons un tour d’horizon de “ce qu’il faudrait faire” en terme de sécurité.
Encryption at Rest
On commencera par sécuriser le stockage des données. Cela peut se faire de différentes manières :
- en chiffrant le système de fichiers sur lequel les données de la base seront conservées. Ce sera au niveau de l’OS qu’il faudra gérer la clé privée vous permettant de chiffrer/déchiffrer.
- en utilisant les fonctionnalités de chiffrement (disponibles au moins depuis la version 8) offertes par le moteur PostgreSQL.
- en utilisant une solution tiers comme CipherTrust Data System Security de chez Thales.
Encryption at Transit
On continuera par sécuriser l’accès à la base de données PostgreSQL, en établissant une connexion sécurisée TLS. Quitte à exécuter des requêtes pour récupérer des données sensibles, autant que celles-ci soient faites à travers une connexion chiffrée. Le moteur PostgreSQL supporte bon nombre de mécanisme avancé pour l'authentification des clients (cf doc officielle ici).
Si vous souhaitez approfondir ces aspects, vous trouverez de nombreux articles sur Internet. Celui-ci est une très bonne synthèse :
https://www.cybertec-postgresql.com/en/setting-up-ssl-authentication-for-postgresql/
Maintenant qu’on a sécurisé “la maison”, établi un protocole permettant de gérer les identités des personnes pouvant y entrer, reste à gérer proprement les permissions de ces personnes.
Principes de Sécurité à appliquer pour la gestion des utilisateurs
Ces principes sont expliqués dans l’article suivant :
https://aws.amazon.com/blogs/database/managing-postgresql-users-and-roles/
Illustrons cela avec un schéma :
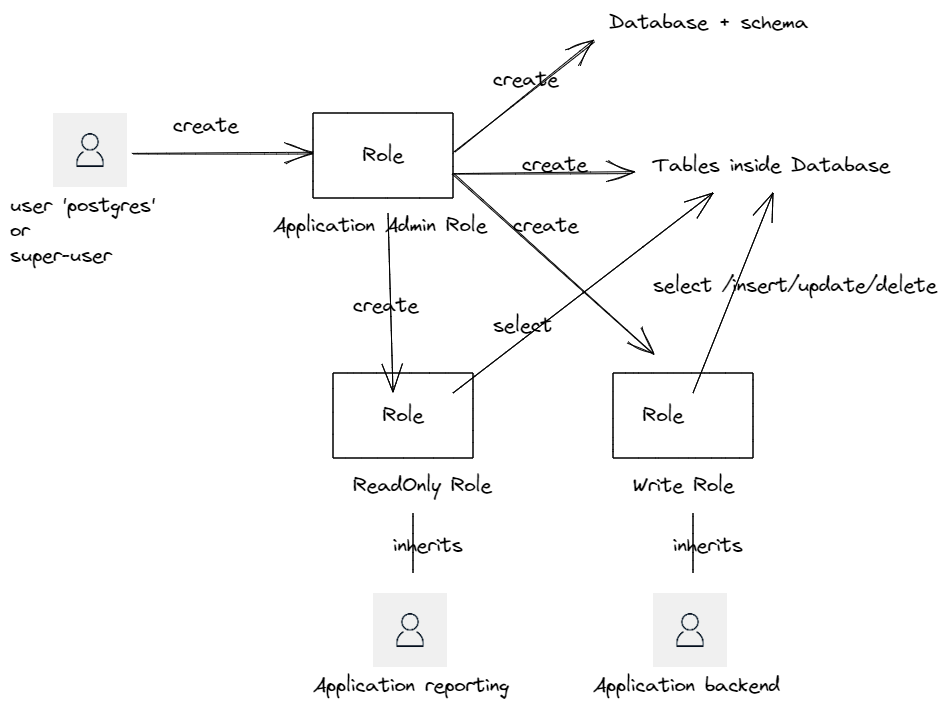
Lors de l’installation d’un serveur PostgreSQL, un utilisateur postgres est créé par défaut. Il est possible de lui donner un autre nom. Quoiqu’il en soit, c’est un super-user, avec les droits les plus élevés. Cet utilisateur sera conservé par l’équipe ops et ne doit pas être connu des équipes devops affectées aux développements des produits/applications.
La première étape est de créer un rôle “admin” qui possédera des droits élevés d’administration d’une instance de base. Cet utilisateur sera utilisé dans les tâches d’administration et sera en charge de :
- créer la database PostgreSQL (“create database”). Il sera owner de la base.
- créer éventuellement des schémas (si vous ne souhaitez pas utiliser le schéma “public” par défaut).
- créer tous les objets type tables, fonctions, procédures que vous définirez.
- créer des rôles qui serviront dans les différents composants de votre application.
Le schéma montre la création de 2 rôles pour une application :
- un rôle “write” avec l’attribution des permissions permettant de faire des select/insert/update/delete sur les tables de la database.
- un rôle “read” permettant uniquement les “select” sur les tables de la database.
Notez également que j’emploie le mot “rôle” et pas “user”. Dans le modèle PostgreSQL, les users sont des rôles avec la propriété login = true. Les rôles peuvent hériter d’autres rôles, récupérant les permissions associées à chaque rôle. Même s’il existe la commande create user, il s’agit d’un alias pour la création d’un rôle. Utilisez \du+ pour lister l’ensemble de vos rôles et users de votre base.
Pour terminer, on crée 2 users héritant l’un du rôle “write”, l’autre du rôle “read”. Ces 2 users seront utilisés dans le cadre d’un composant, par exemple, en charge de faire du reporting de la base, ne nécessitant que les droits “read”, et l’autre pour un composant backend nécessitant des droits d’écriture sur les tables.
Remarques :
Certaines applications (par exemple confluence d’Atlassian) génèrent à la volée des schémas et des tables. Il faudra donc leur donner des droits équivalents à celui de l’utilisateur admin, mais sans le droit de création de rôle. Selon vos besoins, vous pourrez rencontrer différents cas :
- le cas où une application a besoin d’accéder à 2 databases différentes (mais créées au sein de la même instance PostgreSQL). Dans ce cas, créer des rôles pour chaque database et créer un user qui héritera des rôles. Par exemple, le rôle “write” de la database1 et le rôle “read” de la database2.
- De même, vous pourrez rencontrer le cas où 2 applications différentes auront besoin d’accéder à la même database. Dans ce cas, un rôle par application vous permettra de cloisonner ces applications à leur périmètre respectif.
Pour ce qui concerne le "troubleshooting", l’analyse post-mortem, ou tout simplement une mise en production nécessitant des opérations effectuées manuellement, il est acceptable de créer des users avec les permissions nécessaires et suffisantes (mais pas plus). Par contre, ces users utilisés par des “humains” devront avoir une date d’expiration.
Least Privilege
A l’instar de ce qui se fait dans la gestion des permissions dans le cloud, les rôles que vous définissez devraient respecter le principe du “moindre accès”. Par exemple, si votre database contient 4 tables, vous pouvez créer un rôle ayant la permission “write” sur 2 tables, la permission “read” sur une 3eme table. Sans déclaration explicite, ce rôle ne permettra ni le read ni le write sur la 4eme table.
Donner les permissions “write” sur toutes les tables devrait être l’exception et pas la règle.
Chaque composant d’une application devrait avoir un rôle dédié avec des permissions minimales et suffisantes. Ainsi, si une faille de sécurité était découverte par un attaquant, le fait de minimiser les permissions permet de contenir la surface d’attaque.
Avoir un module permettant de simplifier la gestion des permissions permettra aux devops / équipe en charge des bases, d’assurer plus facilement l’application du “least privilege”, ou tout du moins n’auront plus d’excuses pour ne pas le mettre en œuvre !!
A noter : pour permettre une gestion fine des droits sur les tables dans le schéma public, il sera nécessaire de révoquer les privilèges par défaut. Vous trouverez une explication détaillée dans le Readme du module, ici. Quoiqu’il en soit, le module révoque par défaut ces privilèges, vous pouvez donc utiliser le schéma public sans crainte.
Gestion des Secrets
La gestion des secrets pourrait faire l’objet d’un article en soi. Énonçons rapidement les avantages des “coffres-forts numériques”, tels que Vault d’Hashicorp, AWS SecretsManager pour AWS ou Azure Key Vault pour Azure :
- d’abord une seule source de vérité : c’est dans le coffre-fort que sont stockés les mots de passe, les clés ssh etc … Cela permet d’homogénéiser votre SI, d’éviter la duplication des mots de passe, gagner en cohérence.
- Avec l’API que propose le coffre-fort, il sera possible de récupérer la valeur du mot de passe en référençant son emplacement dans le coffre-fort. Cela évite d’avoir à mettre les mots de passe en clair dans les fichiers de configuration de vos composants techniques ou de les stocker de manière chiffrée dans votre outil de gestion de configuration. C’est parfaitement intégré dans la gestion de la configuration de vos clusters kubernetes, ECS, etc... Pour les stacks Java plus traditionnelles, il existe également des “wrappers” au-dessus des drivers JDBC permettant de récupérer la valeur du mot de passe à la volée. Il existe l’équivalent pour le domaine .Net.
- Il est possible de mettre en œuvre la rotation des mots de passe. Autant il est simple, côté coffre-fort, d’effectuer cette rotation, autant il est plus compliqué de propager une modification de mot de passe au sein des backends sans provoquer d’interruption de services. Néanmoins, notons qu’à partir du moment où la connexion est établie, le changement de mot de passe n’aura pas d’influence tant que la connexion persiste.
Quelques pointeurs si vous souhaitez approfondir le sujet :
- https://medium.com/4th-coffee/on-devops-11-secret-management-an-introduction-to-secret-manager-and-best-practice-da74c6f03aa7
- https://github.com/aws/aws-secretsmanager-jdbc
- https://docs.aws.amazon.com/secretsmanager/latest/userguide/rotating-secrets_strategies.html
- https://nimblegecko.com/how-to-securely-store-and-retrieve-passwords-in-dot-net-core-apps-with-azure-key-vault/
Quelques mots sur la gestion des secrets dans Terraform : C’est un peu le talon d’achille de cet outil. C’est assez frustrant mais quelque soit la façon dont vous décidez de passer un mot de passe à une ressource, ces secrets se retrouveront toujours en clair dans le tfstate de votre composant terraform !
Il s'agit d'une issue ouverte depuis plus de 6 ans maintenant, sans qu'aucune vraie solution ne soit prévue. Pour mitiger cette problématique, vous devrez penser à :
- Stocker le “terraform state” dans un backend qui prend en charge le chiffrement. Terraform supporte bon nombre de backends faisant cela, tels que S3, GCS et Azure Blob Storage.
- Contrôler strictement qui peut accéder à votre backend Terraform avec une politique stricte de permissions. Par exemple, limiter uniquement à votre serveur CI que vous utilisez pour le déploiement en production).
Si vous souhaitez approfondir le sujet, je vous conseille cet excellent article de chez gruntwork :
https://blog.gruntwork.io/a-comprehensive-guide-to-managing-secrets-in-your-terraform-code-1d586955ace1
Avant de clore ce chapitre, revenons à notre problématique initiale : le module terraform crée des users en spécifiant leur mot de passe. Il faut donc générer un mot de passe aléatoire, l’affecter au user et le stocker dans un endroit sécurisé.
Dans la conception du module, n’ayant pas d’a priori sur l’endroit où le mot de passe doit être stocké, un système de post-processing playbook est disponible. Ce playbook exécute un script (python, shell, ..) que vous devrez écrire. Ce script devra faire 3 choses : premièrement, générer un mot de passe aléatoire, deuxièmement mettre à jour le mot de passe du user dans la base PostgreSQL et enfin, stocker le mot de passe dans un endroit sécurisé.
Cela a 2 avantages :
- d’une part, la génération du mot de passe dans un script permet de ne pas le rendre visible dans le tfstate.
- d’autre part, le stockage du mot de passe peut se faire dans n’importe quel endroit puisque c’est vous qui scriptez l’endroit où vous voulez les mettre.
Je vous propose une mise en pratique de l'ensemble de ces principes dans les prochains articles :
Construction de l'environnement et création de notre utilisateur admin : article 2.
Stay Tuned,
