

Le 26 mars dernier se tenait la seconde édition des Data Days Lille. Dans la lignée de l'année précédente, cette journée s'est révélée riche en apprentissages et en échanges avec la communauté data lilloise. Preuve de son succès grandissant, l'événement a d'ailleurs rassemblé 40 % de participants en plus par rapport à l'an passé !
Si l'intelligence artificielle est sans surprise restée un sujet phare, elle était loin d'occuper tout l'espace. Enjeux autour de la qualité de la donnée, évolution des métiers ou encore sujets plus pointus comme l'utilisation de dbt-duckdb pour la collecte : le spectre des thématiques abordées était vaste.
Retour sur les conférences qui ont le plus marqué notre équipe.
15 ans de Data: du métier le plus sexy du 21e siècle à une fragmentation impossible à suivre [Benjamin Dubreu]
Le marché de la donnée traverse une période de turbulences. Autrefois défini par une pénurie de talents et des salaires en hausse constante, l'écosystème fait aujourd'hui face à une saturation de profils juniors et à une prolifération technologique étourdissante. Face à des dizaines de rôles distincts et des centaines d'outils, comment les professionnels de la donnée peuvent-ils rester pertinents ?
Dans sa présentation, Benjamin Dubreu propose une ligne directrice claire : pour survivre à cette fragmentation, il faut cesser de vouloir tout apprendre. Sa thèse soutient que la résilience professionnelle repose sur une maîtrise absolue de fondamentaux techniques intemporels, suivie d'une spécialisation pointue en début de carrière, et couronnée par une capacité à traduire les résultats analytiques en véritable valeur métier.
La fin de l'océan bleu
En 2012, la Harvard Business Review qualifiait la Data Science de "métier le plus sexy du siècle". S'en est suivie une ère d'abondance où maîtriser quelques algorithmes suffisait à s'assurer un poste convoité. Cependant, la multiplication des formations express a saturé le marché des profils débutants. Conséquence directe : les salaires d'entrée stagnent depuis 2020. Le "mouton à cinq pattes" recherché par les entreprises s'est fragmenté en une multitude de spécialités (Data Engineer, Analytics Engineer, etc.), rendant le paysage illisible.
L'illusion de la formation exhaustive
Tenter de maîtriser l'intégralité du panorama des outils data est une erreur stratégique menant à l'épuisement. Au lieu d'accumuler des connaissances superficielles en prévision de besoins hypothétiques, la stratégie recommandée repose sur la "théorie de l'entonnoir". L'objectif est d'ancrer solidement un socle technique fondamental (SQL, Python, Git, ligne de commande), puis de se spécialiser profondément sur un rôle précis pour s'insérer sur le marché.
L'impact de l'IA et le retour au business
Si l'intelligence artificielle générative automatise une part croissante de la production de code, cette compétence technique reste le prérequis indispensable pour évaluer les résultats produits par la machine. Toutefois, le véritable différenciateur n'est plus la technique pure. La compétence la plus précieuse devient la traduction : la capacité à s'extraire de la complexité technique pour communiquer avec les décideurs dans un langage orienté sur la résolution de problèmes métier.
Perspectives
L'histoire des métiers, à l'image de celle des empires, oscille toujours entre concentration et éclatement. L'intégration croissante de l'intelligence artificielle annonce-t-elle un nouveau cycle de concentration, où des professionnels augmentés pourront assumer la charge d'équipes entières ? Ou bien la complexité inhérente aux infrastructures de données imposera-t-elle une hyper-spécialisation encore plus stricte dans les grandes organisations ?
dbt-dubckdb dans k8s - un data lakehouse souverain à la main [Cedric OLIVIER - Orange B2B & Antoine GIRAUD - Ippon]
Orange France - B2B doit réaliser une migration d’une de ses 3 plateformes données (GCP, Teradata, Hadoop). C’est l’occasion de s’affranchir de la stack vieillissante Cloudera, Hadoop, HDFS et favoriser des solutions open-source… Seul Spark subsistera pour les croisements de données volumineuses.
Cédric OLIVIER (Orange) & Antoine GIRAUD (Ippon) ont proposé un zoom sur la partie collecte & normalisation des données réalisée à l’aide de dbt-duckdb déployé dans kubernetes (k8s) & orchestré par Airflow. Des contrats de données ODCS (OpenDataContractStandard) sont utilisés pour générer les artefacts dbt-duckdb eux-mêmes convertis depuis les spécifications existantes d’Orange.
DuckDB comme ETL SQL & vrai couteau suisse
Antoine GIRAUD avait présenté les usages de DuckDB à l’édition 2025 des Data Days Lille. Il a présenté qq astuces pour lire de nouveaux types de fichiers (.csv.gz, .json(l), .zip, .xlsx, .gsheet, .xml, .html, .yml) grâce aux contributions d’une communauté bien active. Communauté qui a créé cette année 3 nouveaux connecteurs de base de données (BigQuery, Teradata, SQL Server) en plus des 3 premiers (PostgreSQL, MySQL, SQLite). Il a donné qq billes pour travailler avec des json forts imbriqués !
Une convergence du standard des contrats de données : ODCS
Cédric OLIVER avait introduit les contrats de données lors de l’édition 2025 des Data Days Lille. Il y a eu du nouveau depuis où l’entreprise Entropy derrière l’organisation datacontract s’est rabattue vers le standard Open Data Contract Standard maintenu par Bitol.
Ainsi, Entropy offre quelques outils OpenSource bien pratiques comme
- les classes Pydantic des éléments d’un contrat ODCS
- une interface web pour les éditer
- une CLI
Hélas, la CLI n’aura finalement pas convenu aux besoins des équipes d’Orange B2B dans leur conversion des contrats ODCS en artefacts dbt-duckdb, notamment dû à des dépendances trop anciennes à DuckDB v1.1 (vs 1.5).
dbt pour adopter les bonnes pratiques Analytics Engineering
Les équipes d’Orange B2B ont déjà une grande maturité à l’usage de dbt avec BigQuery. Le projet hérite ainsi des bonnes pratiques dès le 1er jour du projet.
Voici quelques add-ons pratiques:
- dbt docs (catalogue & lineage table), dbt colibri (lineage colonne)
- dbt project evaluator (gouvernance et contrôle des bonnes pratiques dbt)
- dbt assertions pour avoir tous les check not_null en 1 colonne récap `exceptions`
- dbt power user pour l’expérience de dév dans VS Code (dbt fusion ne supporte pas DuckDB / MotherDuck)
- dbt loom, utile pour du data mesh, n’est pas requis pour l’instant : mono repo
dbt elementary (& dbt artefacts) pour accumuler les run_results & offrir un rapport d’observabilité (gantt, recap erreurs tests & modèles…)
L’écosystème dbt autour de DuckDB est encore jeune ! Cédric & Antoine ont dû ouvrir le capôt de bcp d’outils de l’écosystème (dbt-duckdb, dbt elementary, dbt artefact, dbt loom, datacontract cli) et jouer au chat & la souris pour trouver les bonnes configurations (ci-après).
Mais l’espoir d’amélioration reste vif, MotherDuck (offre DuckDB managé sur aws) a contribué en début d’année au projet dbt-duckdb en ajoutant la stratégie incrémentale microbatch !
Voici la configuration employée pour qu’un modèle dbt-duckdb travaille en mode “Data Lake” (lire/écrire les .parquet sur un s3)
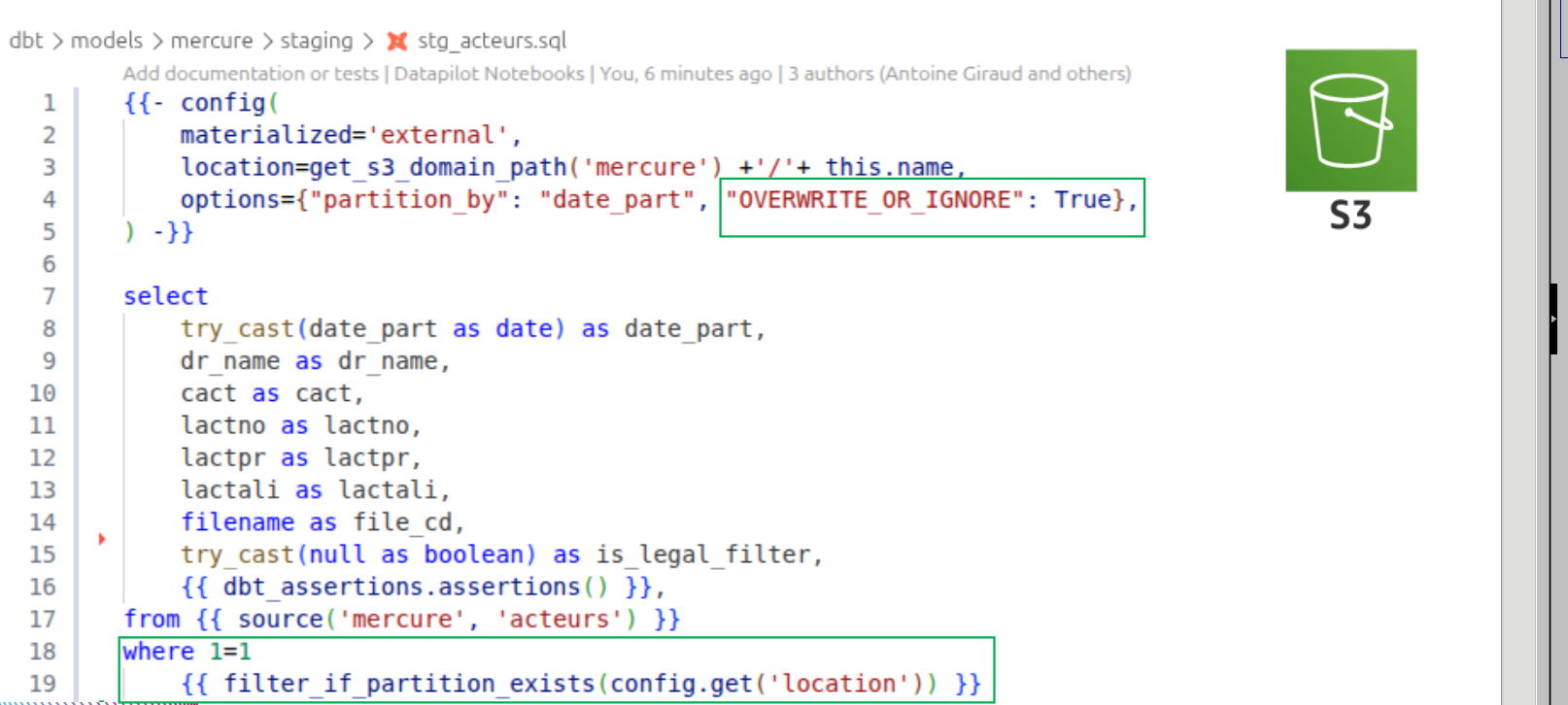
Sans oublier la configuration du profiles.yml. Avec en commentaire un attach à un catalogue DuckLake rangé sur un PostgreSQL.
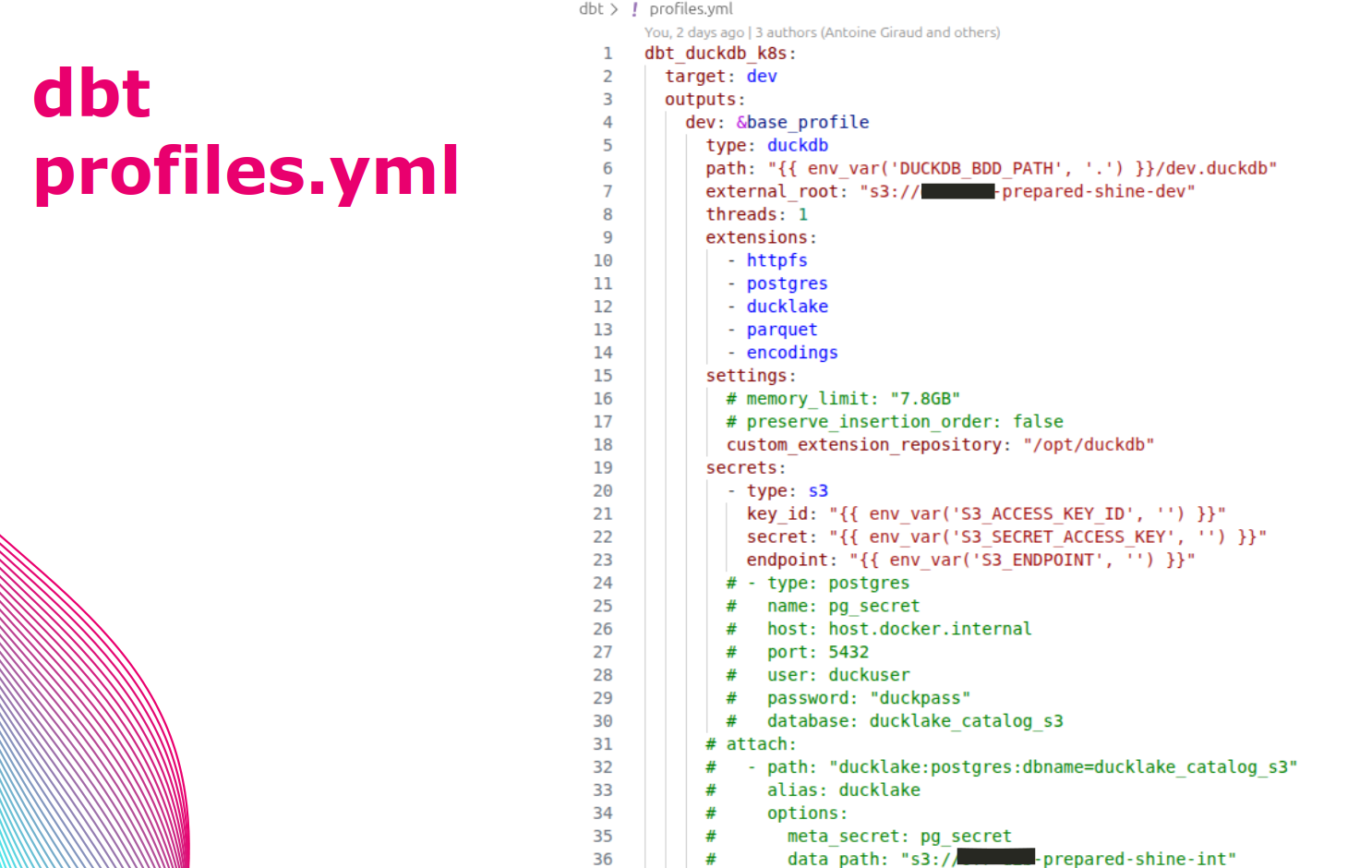
Passage à l’échelle grâce à kubernetes (k8s) & CICD
Pour passer à l'échelle, DuckDB étant mono-noeud, les ~60 sources ~800 tables sont découpées par source/flux, et déployées individuellement vers un k8s souverain d’Orange via un pipeline de CICD. La définition du pipeline de CICD est réalisé à l’aide des template To Be Continuous
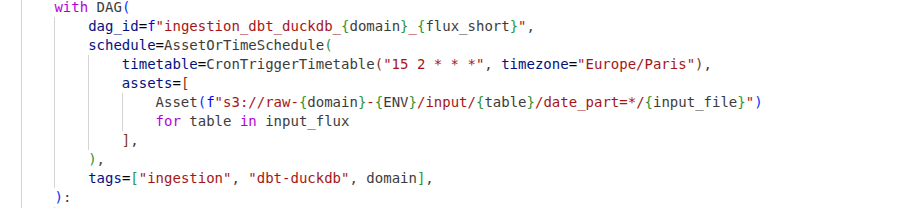
Orchestration via Airflow
L’orchestrateur as code (python) Airflow a été retenu & déployé dans le cluster k8s en version 3.1. Antoine GIRAUD a montré un opérateur k8s pour déclencher les cronjob dbt-duckdb k8s de chaque source/flux. Les équipes d’Orange ont utilisé les Assets pour faire le liant entre les différentes étapes de traitement (python, dbt-duckdb, spark…). Ils ont présenté l’astuce pour planifier un DAG soit à la réception de TOUS les asset events, ou bien un cron en voiture balais grâce à AssetOrTimeSchedule.
Bilan des courses
La migration est encore en cours et bien lancée. L’emploie de technologies open-source pour montrer un datalake souverain fait son effet ! Les retours d’expérience terrain de Cédric Olivier & Antoine Giraud seront précieux pour tout nouveau projet similaire.
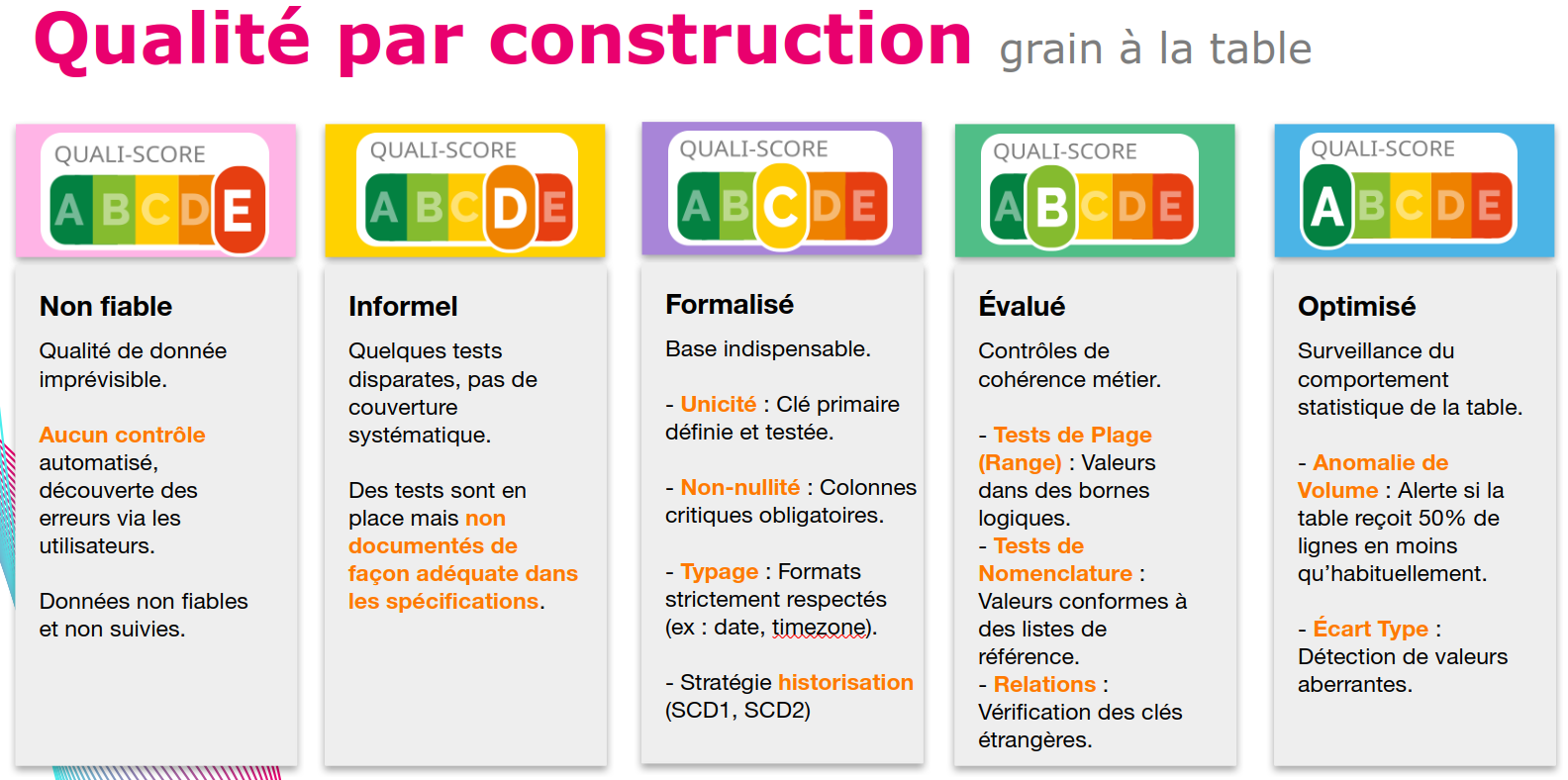
En bonus, Cédric a présenté- une application streamlit qui permet au métier de déposer un référentiel avec une validation automatique basée sur un contrat de données ODCS et DuckDB- une grille d’évaluation de la maturité de chaque source de données appelée qualiscore.
Au-delà du clic : quand les Transformers réinventent le ranking e-commerce [Alex Lenfant, ADEO]
Comment proposer le bon produit au bon endroit dans un catalogue comptant des millions de références ? C’est le défi relevé par Alex Lenfant et l’équipe AAAI (Advanced Analysis and Artificial Intelligence) d’ADEO. Si les systèmes de ranking classiques ont fait leurs preuves, ils atteignent aujourd'hui une limite majeure : le biais de popularité.
Le problème : la dictature du clic
Historiquement, le classement des produits repose sur des signaux comportementaux (clics, ventes, taux de conversion). Résultat : un accessoire peu coûteux mais très cliqué peut remonter en tête d’une catégorie principale, au détriment de la pertinence sémantique. Pour l’utilisateur, cela se traduit par une perte de cohérence dans sa navigation.
La solution : l'approche hybride "Comportemental + Sémantique"
Pour dépasser ce modèle purement statistique, ADEO a mis en place une architecture de reranking hybride qui réconcilie deux mondes :
- Le Machine Learning classique (XGBoost) : Entraîné via BigQuery ML, ce modèle traite les features structurées (prix, promos, notes) et les signaux de performance (CTR, ajout au panier) pour prédire l’attractivité brute.
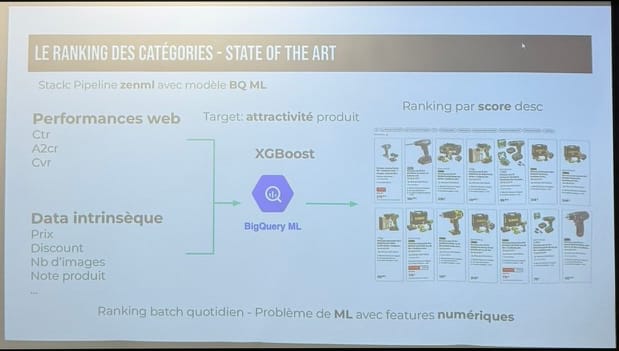
- La puissance des Transformers : En parallèle, une couche sémantique utilise des embeddings (représentation vectorielle des données dans un espace mathématique) pour placer requêtes et produits dans un espace dédié. Cela permet d’identifier les "faux positifs" (des produits populaires mais hors sujet) et d’aligner le résultat sur l’intention réelle de l’utilisateur.

Une stack orientée production
L’enjeu n’est pas seulement la précision, mais le passage à l’échelle. L’architecture s’appuie sur une pipeline robuste :
- Orchestration : ZenML pour structurer les workflows.
- Stockage et Entraînement : BigQuery et BigQuery ML.
- Déploiement : Vertex AI pour scaler sur l’ensemble du catalogue.
L’élément intéressant : Le compromis entre précision et coût de calcul. Si les modèles de type Cross-Encoder sont extrêmement fins pour capturer la sémantique, ils sont trop gourmands pour un catalogue massif. Le choix d'ADEO s'est donc porté sur ce modèle hybride : utiliser le ML classique pour la rapidité et les Transformers pour corriger les biais sémantiques.
En résumé : L'avenir du e-commerce ne se joue plus uniquement sur ce qui est "populaire", mais sur la capacité à comprendre finement le contexte de l'utilisateur pour passer d'un catalogue statistique à un catalogue intelligent.
Arrêtez d’embaucher des experts, cherchez plutôt des responsables ! [Justine Jaffiol]
Dans les systèmes d'information, le chaos de la donnée est la norme. Face à des environnements complexes, la question "qui est responsable de cette donnée ?" se heurte généralement à un silence assourdissant, ou renvoie vers une matrice RACI obsolète et inexploitée au fond d'un répertoire partagé.
Malgré une décennie d'investissements dans la qualité de la donnée, le problème persiste. Pourquoi ? Parce que l'industrie s'est acharnée à soigner des symptômes techniques plutôt que la cause racine. La thèse de Justine Jaffiol : l'enjeu n'est pas technologique, mais décisionnel. Les entreprises n'ont pas besoin d'embaucher de nouveaux experts techniques, elles manquent cruellement de responsables assumés, dotés d'un véritable pouvoir d'arbitrage.

L'autopsie d'un échec collectif
L'explosion des volumes de données laissait espérer une prise en charge naturelle par les équipes. La réalité a prouvé le contraire. Nommer des Data Owners sur le papier ne suffit pas s'ils ne sont ni formés ni accompagnés. Pire, décider expose au risque : modifier la règle de calcul d'un indicateur clé peut déclencher une chute statistique brutale, transformant le décideur en coupable idéal face au management. Enfin, l'absence de boucle de feedback déconnecte la décision de ses conséquences.
Les piliers de la responsabilité
Pour sortir de cette impasse, il faut repenser les conditions entourant la prise de décision.
- Apporter de la clarté : L'incertitude paralyse. Il est impératif de définir précisément qui décide, sur quel périmètre exact, et quelles sont les limites de ce rôle avant d'entamer des projets stratégiques.
- Structurer le droit à l'erreur : L'approche test and learn ne doit pas être une promesse de façade qui se transforme en réquisitoire au premier échec. Ce droit à l'erreur doit s'organiser et s'entretenir collectivement.
- Exiger le courage managérial : Une décision nécessite un soutien hiérarchique solide, capable d'assumer les choix complexes et de protéger les équipes face à la pression.
Reconnecter la décision au terrain
Il faut cesser d'exiger des décisions de la part de responsables éloignés de la réalité opérationnelle. La solution pragmatique consiste à ramener ces décideurs sur le terrain, à leur faire ressentir les irritants et comprendre le véritable "pourquoi" derrière chaque besoin de donnée. C’est en confrontant les objectifs théoriques aux contraintes techniques, avec l'appui d'équipes prêtes à s'investir concrètement, que l'impact réel se matérialise.
Conclusion
La qualité de la donnée agit comme un révélateur des failles de gouvernance d'une organisation. Si aucun collaborateur n'est en mesure de revendiquer et d'assumer publiquement une décision concernant la donnée, le vernis technologique masque un mal plus profond. Les organisations sont-elles véritablement prêtes à déléguer ce pouvoir de décision de manière claire ? Et les directions sont-elles disposées à assumer les conséquences des choix de leurs équipes opérationnelles sans chercher immédiatement des coupables ?
DevOps vs IA/ML: le jour où le Time-To-Market a rencontré le Time-To-Value [Sophie Pruvost]
L'objectif historique du DevOps était clair : réduire le Time-To-Market pour innover rapidement. Une usine logicielle automatisée livre une fonctionnalité en production, et si elle fonctionne techniquement sans erreur, la valeur est créée. Dans le monde de la Data et du Machine Learning (ML), livrer un modèle techniquement viable ne suffit plus. Les données évoluent en continu, rendant les modèles rapidement obsolètes, même s'ils tournent parfaitement sur les serveurs.
Sophie Pruvost démontre que les freins culturels et techniques rencontrés lors de l'adoption du DevOps il y a dix ans se reproduisent aujourd'hui dans l'écosystème Data/ML. L'enjeu bascule du Time-To-Market vers le Time-To-Value : la capacité à maintenir une valeur réelle et continue en production. Transposer les pratiques DevOps à l'IA est indispensable pour lutter contre l'obsolescence silencieuse des modèles et garantir la pérennité des services automatisés.

Le défi du vivant et la menace du "Drift"
Contrairement au code statique, les données et les modèles sont vivants. Un modèle de Machine Learning entraîné pour modérer des insultes sur un réseau social devient inutile dès que les utilisateurs inventent de nouveaux codes linguistiques. C'est le phénomène de dérive (drift).
Il prend deux formes principales : la dérive des données (le référentiel d'entrée change) et la dérive de concept (l'environnement ou le comportement utilisateur évolue). Un modèle victime de drift prédit correctement, mais pour un monde qui n'existe plus. Ce décalage entraîne une perte de valeur, une rupture de confiance avec les métiers, et des pertes financières.
Transposer les piliers du DevOps à la Data
Pour combattre la dérive, l'approche "one-shot" de la culture projet doit céder la place à une culture produit itérative. Cela implique de réadapter les piliers du DevOps :
- Automatisation étendue : Intégrer une étape de Build & Train systématique. Sans automatisation du réentraînement, la dérive est inévitable.
- Boucles de rétroaction courtes : Le cycle "Data - Modèle - Production" doit être évalué en continu. Le temps qui passe fige le modèle et crée la dérive.
- Mesure spécifique : L'observabilité ML diffère du monitoring logiciel classique. Il faut évaluer la qualité de la donnée et la dégradation de la pertinence des prédictions, pas seulement les temps de réponse.
- Pizza Teams décloisonnées : Casser les silos en réunissant Devs, Ops, profils Data, et impérativement le département juridique. Les évolutions réglementaires rapides autour de l'IA transforment la conformité légale en un risque de dérive majeur.
L'organisation avant la technique
Concrètement, la mise en œuvre de cette stratégie exige des pratiques fondamentales : pipelines de réentraînement programmés, versioning systématique, déploiements de type canari, et intégration de garde-fous immédiats (comme la capacité de rollback ou de retour à un traitement manuel).
L'approche purement technique est cependant insuffisante. Selon la loi de Conway, l'architecture d'un système reflète la structure de l'organisation qui le conçoit. Instaurer des rituels hebdomadaires de coopération entre les équipes génère le tempo nécessaire pour forcer et maintenir la mise en place des pipelines techniques. La transformation doit d'abord s'opérer sur l'organisation humaine.
Conclusion
Si la gestion de la dérive des modèles n'est pas un problème technique mais avant tout un défi organisationnel, les entreprises sont-elles prêtes à revoir leurs hiérarchies internes ? Comment les équipes IT, Data, Métier et Juridique vont-elles s'aligner durablement pour transformer cette maintenance continue en véritable avantage compétitif ?
Agents & GenAI : Comment nous avons boosté un projet de data engineering à l’échelle de 150 microservices [Emmanuel-Lin Toulemonde]
Les agents de code génératifs excellent dans le prototypage rapide. Mais sont-ils viables à l'échelle d'un projet "brownfield" existant depuis plusieurs années, comptant plus de 250 microservices en production, sans risquer d'altérer la stabilité du système ?
Emmanuel-Lin Toulemonde démontre que l'intégration d'agents IA accélère massivement le développement et la documentation en data engineering, à condition d'imposer des garde-fous stricts. Pour l'industrie, l'enjeu est stratégique : l'IA ne remplace pas les bonnes pratiques d'ingénierie logicielle (le craft), elle les rend obligatoires. La validation statique de code ou les tests d'architecture automatisés deviennent des prérequis indispensables pour canaliser ces nouveaux outils.
Automatisation de l'ingestion et des data contracts
L'agent brille dans l'exécution de tâches répétitives et sans ambiguïté. À partir d'un simple fichier de configuration YAML, il génère le code d'une nouvelle Azure Function, met à jour les pipelines de déploiement et applique les standards de nommage du projet. L'IA résout également le problème de la documentation technique. La rédaction chronophage des data contracts est automatisée. En fournissant à l'agent uniquement le schéma technique via un script (pour bloquer l'accès direct aux données), celui-ci génère une documentation exhaustive, éliminant ainsi un goulot d'étranglement historique.
Refactoring et validation par l'AST
Déléguer la modification du code existant exige une sécurité maximale. L'approche s'appuie sur des tests de caractérisation : le comportement actuel du code est figé par un test, l'IA effectue le refactoring, et la validation continue garantit l'absence de régression. L'apport technique majeur réside dans la génération de tests d'architecture. L'agent écrit des scripts capables d'explorer l'AST (Abstract Syntax Tree) du code Python. Ces tests vérifient sur l'ensemble du mono-repo la présence d'arguments obligatoires ou le respect des règles de conception, bloquant les erreurs de design avant même l'étape de revue.
Conclusion

L'intégration d'agents IA transforme le métier d'ingénieur data, déplaçant l'effort de la production pure de lignes de code vers la conception architecturale et la définition de standards stricts. Ce basculement soulève cependant des défis structurels : comment garantir la progression et l'apprentissage des développeurs juniors si la machine absorbe la phase de pratique basique ? Et comment adapter les processus de revue de code lorsque les agents produisent instantanément un volume de modifications dépassant la capacité de relecture humaine ?
A|A: Comment Libérer les Agents de l’Orchestration Centralisée [Olivier Wulveryck]
Les systèmes d'IA actuels souffrent d'un goulot d'étranglement majeur : l'orchestration centralisée. Lorsqu'un agent principal pilote chaque tâche de bout en bout, agissant comme le chef d'orchestre exclusif, il limite drastiquement la scalabilité et la réactivité de l'ensemble du système.
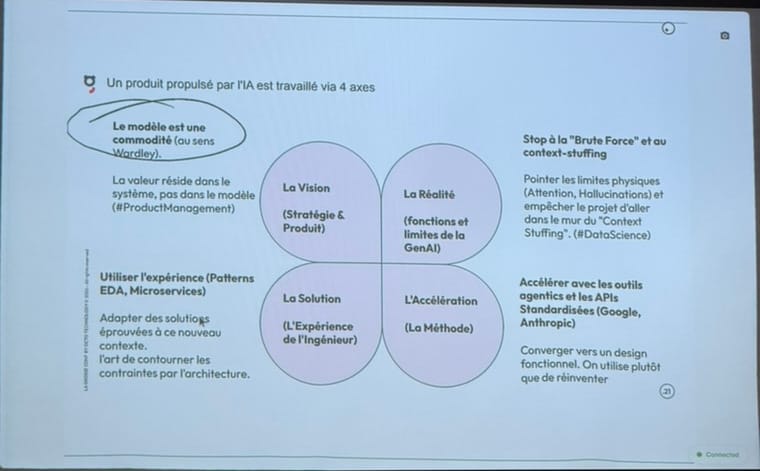
La solution ne réside pas dans l'augmentation de la taille des fenêtres de contexte, mais dans l'architecture. En appliquant les principes de l'intelligence collective et de l'architecture orientée événements (event-driven), il est possible de concevoir des écosystèmes d'agents spécialisés, autonomes et décentralisés. Cette approche déplace la valeur technologique du modèle d'intelligence artificielle brut vers la conception du système global, ouvrant la voie à des applications viables à l'échelle industrielle.
Le piège du "Context Stuffing"
La tentation actuelle consiste à injecter l'intégralité des données d'un problème (comme un fichier audio massif) dans des fenêtres de contexte toujours plus grandes. Cette méthode est inefficace. Les modèles subissent une dégradation de leurs performances, retenant principalement les informations situées au début et à la fin de la requête, tout en diluant celles du milieu. De plus, cette approche centralisée s'avère extrêmement coûteuse en tokens et complexe à maintenir à grande échelle.
L'ère de la commodité des modèles
L'évolution des modèles de langage (LLM) suit la logique de la carte de Wardley : d'innovations de rupture, ils sont devenus des commodités standards. La compétition axée uniquement sur la puissance brute des modèles n'est plus le véritable enjeu. Le levier de différenciation réside désormais dans la capacité à construire des architectures robustes autour de ces modèles de base, répliquant le schéma où l'orchestration a maximisé le potentiel des conteneurs applicatifs.
L'architecture événementielle au service des agents
Pour briser la centralisation, l'architecture "publish-subscribe" s'impose. Au lieu qu'un agent principal distribue les instructions de manière synchrone, un bus d'événements (message broker) centralise les requêtes. Des agents spécialisés (par exemple, un agent de transcription et un agent de synthèse) s'abonnent à ce bus, récupèrent les tâches de manière autonome, les traitent, et publient le résultat. L'utilisation de standards de communication émergents, comme le protocole open source agent-to-agent de Google, permet à ces systèmes hétérogènes d'utiliser un format d'enveloppe commun.
Maintien de l'état et observabilité
Dans ce système découplé, les agents opèrent sans état (stateless). Ils ne s'appuient pas sur une mémoire centrale partagée, qui recréerait un point de blocage. Le contexte strict nécessaire est transmis directement dans l'enveloppe du message, couplé à un identifiant de corrélation (correlation ID) pour isoler et suivre le flux d'informations. En parallèle, une observabilité rigoureuse demeure indispensable pour auditer et mesurer l'efficacité de ces échanges asynchrones.
Conclusion
L'avenir de l'IA générative s'éloigne du modèle unique omniscient pour se diriger vers des réseaux d'agents collaboratifs. Si les standards de communication multi-agents s'imposent dans les processus industriels ou commerciaux, comment les entreprises structureront-elles leur gouvernance face à des systèmes de prise de décision décentralisés ? Jusqu'où la délégation d'autonomie à ces réseaux peut-elle aller sans compromettre la prédictibilité de la chaîne de valeur ?
- L’Histoire du Deep Learning : quand les machines ont commencé à apprendre
- La Couche Sémantique : Le Chaînon Manquant de la Valorisation des Données d'Entreprise
- De la Data Platform à la Data Viz - Le chaînon manquant de votre stratégie data
- Model Context Protocol (MCP) : Comprendre le standard et retour d’expérience pour exposer un CLI Rust dans votre IDE
Vous souhaitez accélérer sur la data et l'IA ?
Nos experts vous accompagnent sur l'implémentation de solutions d'IA
