

TL;DR
Un LLM peut apprendre à estimer sa probabilité de réussite sur une tâche pour décider d’agir, d’escalader ou de déléguer. Le futur des LLM passe moins par la taille que par des agents ancrés dans des environnements/outils, capables de se fixer des objectifs, de s’auto-évaluer et de collaborer, en s’appuyant sur des représentations internes structurées qui reflètent au mieux leurs capacités réelles.
Cet article s’inscrit dans une série dédiée à mieux comprendre les LLMs, en parcourant les grandes trends du moment (agents, RAG, outillage, évaluation), et en confrontant ce qui émerge dans la littérature aux retours d’expérience.
- Dans cet article : exploration de la métacognition des LLM comment un modèle peut estimer sa probabilité de réussite sur une tâche pour choisir une stratégie adaptée (agir, déléguer, escalader), avec des exemples comme GLAM et MAGELLAN.
- Article suivant : “L’évaluation des LLMs est-elle morte ?”analyse des benchmarks actuels et sur les approches d’évaluation plus pertinentes en conditions réelles. Restez connectés, ça arrive très bientôt !
1. LLM everywhere
Les grands modèles de langage (LLMs) sont partout. Une analyse récente portant sur 168 331 papiers (2019–2024) issus de 77 conférences majeures identifie 16 193 articles traitant de la thématique des LLMs, avec une explosion en 2024 (7 109). La part atteint environ ~20% dans les grandes conférences de l’IA (NeurIPS/ICLR/ICML) et dépasse 60% en NLP (traitement du langage). Cet intérêt reflète un mouvement profond, alimenté par des usages industriels concrets.
2. Les limites qu’on ne peut plus ignorer
Avant de fantasmer des applications toujours plus avancées, il faut admettre que les LLMs ont des faiblesses structurelles (liste non exhaustive) :
- Ils coûtent cher (en entraînement comme en inférence)
- Ils hallucinent parfois des réponses fausses, mais très plausibles
- Ils ne peuvent pas expliquer pourquoi ils répondent ce qu’ils répondent (problème de l’explicabilité plus généralement)
- Leur performance est très sensible à la formulation du prompt
Tant qu’on reste dans une logique de génération textuelle, ces défauts peuvent être atténués, mais dès qu’on cherche à fiabiliser ou automatiser des actions, ils deviennent bloquants.
3. Quand le LLM devient un agent
Plutôt que de lui faire simplement générer du texte, on peut insérer un LLM dans une boucle agentique : il perçoit une situation, prend une décision, agit dans un environnement, et reçoit un retour. Dans ce cadre, le LLM devient un composant décisionnel.
Ce changement est profond : il ne s’agit plus seulement de produire du texte convaincant, mais de résoudre une tâche. Cette approche permet des usages plus ambitieux et utiles :
- Un agent de développement lit un ticket, code, teste, pousse une PR commentée.
- Un collectif d’agents se répartissent l’implémentation, la revue, les tests, la doc.
- Un agent analytique explore des tables, génère des hypothèses, rend compte de ses doutes.
- Un agent support suit une procédure, agit, et escalade si besoin.
- etc.
Mais pour que cela fonctionne, il faut résoudre des problèmes nouveaux : comment l’agent sait-il ce qu’il peut accomplir ? Comment apprend-il ? Quand doit-il demander de l’aide ?
Et surtout, dans les systèmes multi-agents où plusieurs LLMs spécialisés coopèrent : comment s’assurer qu’ils interagissent efficacement en coordonnant leurs actions via le langage ? Et qu’un agent coordinateur puisse sélectionner le “bon” agent, capable de sélectionner celui qui a la capacité de réaliser la tâche transmise avec succès.
👉 Mais au fait, c’est quoi une “représentation interne” ?
Quand on parle de représentation interne dans un LLM, on désigne la manière dont il encode, structure et manipule l’information dans ses couches cachées. Par exemple, deux instructions très proches comme “tourne à gauche” et “va à gauche” activeront des régions similaires dans l’espace latent du modèle.
Ce genre de structure n’est pas “donnée” au modèle : elle émerge pendant l’entraînement. Et plus cette organisation interne reflète fidèlement la logique de la tâche, plus le modèle sera capable de généraliser, d’expliquer ses choix, ou de faire des liens pertinents.
Dans les travaux présentés ici, ces représentations ne sont pas seulement linguistiques, elles sont fonctionnelles : elles traduisent ce que le modèle “comprend” de son propre comportement, de ses actions, de ses réussites.
4. Nouveaux défis, nouvelles questions
Exploiter les LLM dans un système multi-agents soulève des défis majeurs :
- Décider dans l’incertitude : quand continuer, quand s’arrêter, quand déléguer ?
- Apprendre : comment tirer des leçons de ses succès ou erreurs ?
- Travailler en groupe : comment coordonner des agents via le langage ?
- S’auto-évaluer : comment savoir ce qu’on est capable de faire, ou pas ?
La recherche s’intéresse à tous ces points, et je vais essayer de vous donner quelques pistes !
5. Une thèse, pour prendre un peu de recul
J’ai eu la chance d’assister à la soutenance de Clément Romac, à Inria Bordeaux, en collaboration avec Hugging Face, autour de la thèse « Grounding LLMs as Autotelic Reinforcement Learning Agents ».
Le propos ? Cesser de voir le LLM comme un simple outil d’inférence textuel, mais comme agent dans l’apprentissage par renforcement. Le reconsidérer comme un apprenant actif, guidé par des objectifs internes, à la manière d’un enfant curieux.
Notamment, deux moteurs sont mis en avant :
- La curiosité épistémique : chercher à mieux comprendre ou prédire
- L’intention autotélique : se doter de buts atteignables pour développer ses compétences
Ces deux mécanismes permettent au LLM de devenir acteur de son développement, en sélectionnant activement les tâches qui feront grandir sa compétence, non pas parce qu’un superviseur l’y contraint, mais parce qu’il en anticipe les bénéfices pour sa progression future.
6. Une brique technique clé : GLAM
L’une des premières contributions majeures de la thèse est GLAM (Grounded LAnguage Models).
👉Petit(e) introduction/ rappel : le renforcement (reinforcement learning) (RL) est un cadre d’apprentissage où un agent explore un environnement en recevant des récompenses selon les actions qu’il entreprend. Il apprend par essai-erreur, en ajustant ses décisions pour maximiser une récompense cumulative sans supervision explicite.
Explication illustrée d’un agent en RL qui peut effectuer des actions dans un environnement et recevoir des récompenses en fonction de ces actions. Au fur et à mesure des simulations, on ajuste le comportement de l’agent pour réaliser les “meilleures” actions.
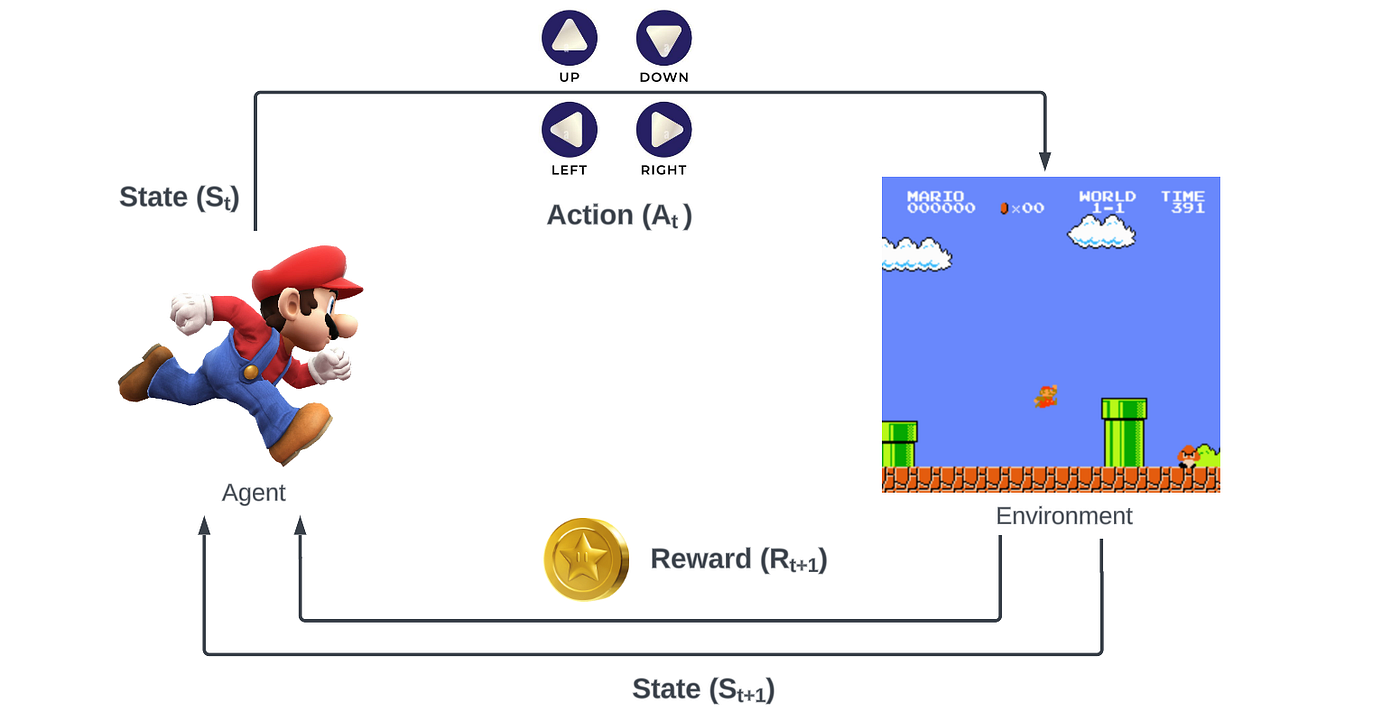
➡️ Ici, un LLM est utilisé comme agent dans une tâche de renforcement.
L’objectif est de faire en sorte que le modèle sélectionne l’action la plus adaptée à une situation donnée, à partir d’une liste d’actions possibles. Pour cela, le LLM est entraîné en apprentissage par renforcement à prédire, pour chaque situation, quelle action maximise la récompense attendue.
L’environnement utilisé ici est BabyAI-text, un cadre simplifié d’instructions en langage naturel où l’agent doit naviguer, se déplacer, interagir. L’intérêt : un environnement contrôlé mais suffisamment riche pour observer l’apprentissage d’actions, de concepts et de leur enchaînement logique.
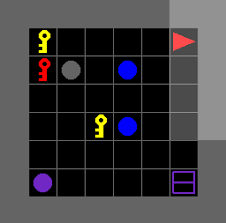
Concrètement, cela revient à ancrer le langage du LLM dans un environnement physique ou simulé : le grounding. Par exemple, “tourner à gauche” ne doit pas être seulement compris comme une suite de mots, mais comme une action concrète dans une tâche donnée.
Ce cadre permet aussi d’observer que le modèle construit des représentations internes structurées, où des concepts proches (tourner à gauche / à droite) s’organisent naturellement dans des zones voisines de l’espace latent. Cela montre que le LLM apprend non seulement à agir, mais aussi à “comprendre” les relations sémantiques entre actions.
GLAM représente donc un changement important : le LLM n’est plus seulement évalué sur la forme de ses sorties, mais sur sa capacité à interagir efficacement avec un environnement
➡️ sources : Grounding_LLMs_with_online_RL
7. MAGELLAN : apprendre à se fixer de bons objectifs
L’article MAGELLAN (Metacognitive predictions of learning progress guide autotelic LLM agents in large goal spaces) pousse plus loin : si l’espace des tâches possibles est immense, comment un LLM peut-il choisir des objectifs utiles ?
L’idée centrale ? Doter le modèle d’une capacité métacognitive : il apprend à prédire sa propre compétence à réussir une tâche donnée, avant même de la tenter. Cela lui permet ensuite de prioriser les objectifs les plus formateurs.
Concrètement, MAGELLAN permet au LLM de :
- Estimer la probabilité de réussite d’un objectif exprimé en langage naturel
- Choisir activement des objectifs adaptés à son niveau actuel
- Reconfigurer ses représentations internes pour regrouper les objectifs similaires (clustering)
Ce mécanisme donne lieu à un apprentissage progressif et autonome, où l’agent apprend à éviter les tâches trop simples ou hors d’atteinte, et à se concentrer sur celles qui maximisent ses gains d’apprentissage (à l’image d’un enfant qui apprend).
En structurant l’espace des objectifs atteignables, MAGELLAN fait émerger une forme de planification implicite : le LLM apprend par étapes, comme un humain qui s’entraîne d’abord à courir 5 km avant de viser un marathon.
➡️ source : MAGELLAN
8. Et pour les projets industriels ?
8.1 Savoir quand demander de l’aide
L’agent intelligent n’est pas celui qui fait tout tout seul. C’est celui qui sait quand il vaut mieux déléguer, escalader ou appeler un outil tiers.
MAGELLAN et la recherche de manière plus générale, apportent ici un levier crucial : en estimant sa propre compétence, l’agent peut choisir quand passer la main s'il n’est pas en capacité d’effectuer la tâche. Cela a des implications fortes sur la fiabilité (éviter les hallucinations coûteuses) et les coûts (ne pas mobiliser un humain trop tôt).
Ce cadre change les règles du jeu. On n’évalue plus un LLM sur la fluidité de sa réponse, mais sur sa capacité à agir avec efficacité et prudence.
8.2 Le miroir de nos propres organisations
Cette transition vers des systèmes multi-agents capables de déléguer et de collaborer résonne avec la psychologie sociale et le management humain, dont les travaux nous aident à modéliser la collaboration entre agents. Pour qu'un collectif d'agents fonctionne, nous sommes forcés de modéliser ce que nous pratiquons parfois intuitivement (et souvent mal) en équipe : la définition claire des objectifs, la mesure des compétences et la gestion de la confiance.
En cherchant à automatiser la délégation entre machines, nous mettons en lumière un paradoxe : l'IA nous oblige à devenir plus rigoureux dans la formulation de nos propres exigences (et c’est ce que nous mettons en évidence dans notre démarche PDD). Cela est d’autant plus important dans des scénarios ou des agents collaborent avec des humains.
9. Une frontière technique
Ce mouvement s’inscrit dans une dynamique plus large de la recherche en IA, en phase avec la conviction défendue par Yann LeCun : dépasser le “tout-génératif” et le “tout-supervisé” pour construire des systèmes qui apprennent des représentations du monde, capables de prédire, planifier et agir, plutôt que de seulement produire du texte.
En apprenant aux LLMs à mieux s'évaluer pour mieux collaborer, nous ne faisons pas que créer de meilleurs outils ; nous affinons notre compréhension de l'intelligence collective, qu'elle soit artificielle ou humaine.
10. Conclusion
Le futur des LLMs ne se résume pas (que 😁) à des modèles toujours plus gros. Il s’écrira avec des agents capables de s’ancrer, de se fixer des objectifs, de s’évaluer et de collaborer.
Les travaux présentés ici montrent que les LLMs peuvent apprendre à agir, pas seulement à parler. Et surtout, qu’ils peuvent construire des représentations internes cohérentes, ancrées dans leurs capacités réelles. Ces représentations permettent non seulement de mieux raisonner, mais aussi d’anticiper ce qu’un agent saura faire, ou non. Cela ouvre la voie à des interactions plus robustes, moins sensibles aux formulations exactes des prompts, et plus proches d’un raisonnement incarné.
Cet article est le premier jalon de la série : la suite abordera notamment la question de l’évaluation des LLMs, et ce qu’il faut mesurer quand on vise des usages réels. À très vite !