

Vous connaissez la règle : un projet peut être rapide, de bonne qualité ou peu cher, mais il ne sera jamais les trois à la fois.

L’utilisation des Coding Agents a une influence évidente sur la rapidité du projet. Mais comment être sûr qu’il n’existe pas de contrepartie négative sur les autres aspects ? La réponse est assez simple : il suffit de sacrifier un peu de temps pour comprendre en profondeur ces nouveaux outils.
Si vous avez lu nos précédents articles, vous avez déjà une assez bonne idée de ce dont il retourne : ce que sont les “Coding Agents” et comment les obliger à écrire du code de qualité. Vous saurez également bientôt comment écrire des prompts efficaces grâce à un article sur le Prompt Engineering. Cette connaissance est applicable à l’ensemble des modèles et des outils qui nous permettent de les utiliser. Mais lequel choisir ? Évidemment, il n’y a pas de réponse universelle, que vous privilégiez les coûts, la qualité du code, la sécurité de vos données ou encore les vibes. Dans cet article, je vais essayer de vous donner un maximum d’éléments de réponse pour que vous puissiez adapter votre workflow piloté par IA à vos besoins.
Il n’y a pas de meilleur modèle, en tout cas à l’heure où j’écris ces lignes. Claude Sonnet 3.7 semble être ce qui s’en rapproche le plus si on se fie aux benchmarks, mais une analyse un peu plus poussée - grâce à des sites comme https://livebench.ai/ - nous montre que la réponse est plus nuancée :

En tant que développeur, est-ce qu’on doit utiliser o3-mini, qui est meilleur en coding ?
Si on se base sur cet autre benchmark issu de l’outil de codage agentique Aider, et donc un cas d’usage plus proche du nôtre, o3-mini se trouve à la 5ème position :

Donc, est-ce bien Claude 3.7 Sonnet qu’il faut prendre ? On obtient des performances quasiment égales en combinant Deepseek R1 et Claude 3.5 Sonnet pour un tiers du prix. Malheureusement, Deepseek R1 ne supporte pas les images et notre workflow se base sur des maquettes… Bref, vous l’aurez compris, pour choisir son modèle, il faut comprendre nos propres contraintes et comment chaque modèle peut nous aider.
Bon, faire une veille aussi active peut faire peur. Si le temps n’est pas de votre côté, se rabattre sur l’intelligence collective et utiliser les modèles les plus populaires sur OpenRouter est un pari assez peu risqué. À l’heure actuelle, il s'agit de Claude 3.7 sonnet. Cependant, dans cet article, nous parlons d’optimisation et choisir le modèle le plus populaire n’est pas forcément optimal. Alors, comment optimiser notre choix de modèle ?
Les métriques Clés
On ne peut pas vraiment juger objectivement un développeur, mais là, on recrute un robot : on est donc libéré du poids de l’éthique et on n’est pas obligé de s’assurer que le robot soit sympa.
De plus, certaines métriques concrètes existent pour caractériser les modèles. On ne peut pas se baser uniquement sur celles-ci pour déterminer si un modèle est bon ou non. Par contre, elles vont pouvoir nous aider à choisir le modèle qui correspond le mieux à nos contraintes.
En général ces métriques sont facilement accessibles depuis votre provider API, par exemple pour Claude 3.7 Sonnet sur OpenRouter :

Le Token
Dans les métriques liées à un LLM, on compte souvent en “Token”. Le token est une unité de texte qui est vectrice d’information. Souvent, un mot est un token, mais ce n’est pas toujours le cas.
Le principe pour le LLM c’est de ne pas avoir à retenir tous les mots. Par exemple, le mot "incroyable" peut notamment se diviser en "in" et "croyable". Le préfixe “in” étant très fréquent, en faire son propre token peut avoir du sens pour optimiser l’apprentissage.
Pour les mêmes raisons, certains groupes de caractères courants pourront être considérés comme un seul token. Par exemple “123” ou “...”.
Plusieurs algorithmes de “tokenisation” existent. Si vous souhaitez jouer avec celui d’OpenAI, il est disponible ici. Sur leur page, sl est spécifié qu’on a approximativement 100 tokens pour 75 mots. Cependant, de notre côté, nous trouvons qu’avec du code on est plus proche des 100 tokens pour 50 mots :

En bref, avec des Coding Agents qui ont accès à notre workspace entier, le nombre de tokens augmente vite.
Peut-être qu’un jour, on verra émerger une étape de compression avant de faire notre requête au LLM ? Ça existe certainement déjà.
La Context Window
Par francisation et abus de langage, nous avons beaucoup utilisé le mot “contexte” pour parler de ce concept dans cette série d’articles, et nous allons probablement continuer. Pour chaque modèle, le contexte a une taille maximale, qui correspond au nombre maximum de tokens dont le modèle peut se “souvenir”. On peut le voir comme la mémoire du modèle.
Dans notre cas, plus l’IA lit des fichiers, plus elle en écrit, plus le contexte se remplit.
C’est probablement la caractéristique la plus limitante de Claude 3.7 Sonnet par exemple. Claude a un contexte maximal de 200 000 tokens.
Comme ça, c'est assez dur à mettre en perspective, mais si on prend l’exemple de la vidéo du premier article, une fois la tâche de création du tableau de bord terminée, on a :

C’est déjà plutôt bien rempli, en un seul prompt. D’autant plus qu’empiriquement, il semblerait que les hallucinations augmentent significativement si le contexte est trop rempli. Nous essayons d’éviter de dépasser 75%.
Cela nous laisse deux options : soit on change de modèle et on utilise, par exemple, Gemini Flash 2.0 avec sa Context Window à 1 million de tokens, soit on commence une nouvelle tâche. Ce n’est pas trop problématique, notamment si on suit certaines pratiques de développement, comme la Separation Of Concerns, mais c’est rarement idéal. Dans cet article, nous verrons d’autres techniques plus spécifiques aux Coding Agents comme la Memory Bank ou des fichiers de configuration.
Max output
C’est le nombre de tokens qu’un appel API peut retourner. 128k c’est beaucoup et nous n’avons jamais atteint cette limite. Nos outils ont plutôt tendance à multiplier les appels API.
Par rapport à Claude 3.5 Sonnet, il y a eu une amélioration massive, probablement, car Claude 3.7, à l’instar de DeepSeek R1, est capable de “raisonner”. En pratique, le raisonnement, c'est le LLM qui va réfléchir sur le problème en se posant de nombreuses questions, ce qui implique la génération de beaucoup de tokens. C’est également pour ça que les modèles de raisonnement ont tendance à être significativement plus chers.
Input/Output Cost
On rentre dans l’un des aspects les plus importants liés à l’utilisation des LLMs, le coût. Utiliser un LLM, ça coûte cher. Surtout si ce LLM est Claude Sonnet. Le coût est exprimé en $/Million de tokens.
Mais, si on reprend l’exemple précédent, on peut déceler un problème :

Rien qu’en considérant uniquement les tokens envoyés au LLM (en input pour le LLM donc), on devrait avoir payé au moins 5,4 x 3 = 16,2 $. Mais ce n’est pas ce qu’il se passe, et heureusement. En fait, Claude Sonnet supporte le caching de prompt, ce qu’on peut voir au choix du modèle dans les paramètres de Cline :

Maintenant si nous reprenons cette même conversation désormais vieille de 20 jours, nous devrons fournir le contexte en entier. En essayant, on voit sur Cline que la requête a coûté particulièrement cher :
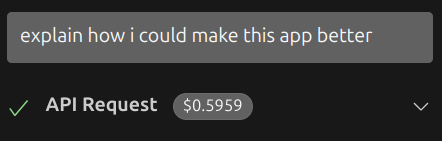
et si nous observons le détail de la requête sur OpenRouter :
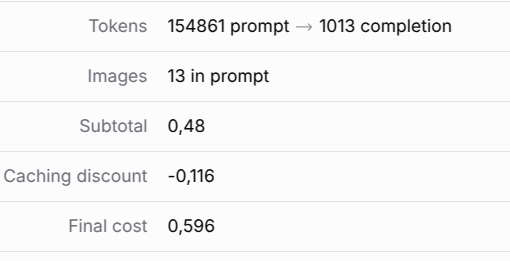
Cela fait cher l’exemple, mais on va dire que ça vaut le coût. Si on fait le calcul avec les tarifs de Claude Sonnet (avec MT = Million de Tokens) :
0,154861 MT x 3 $/MT + 0,001013 MT x 15$/MT = 0.479778 $ ≈ 0.48 $
On retombe sur nos pieds.
À cela s’ajoute la caching discount, qui n’en est pas un puisqu’on est sur une majoration de 25% du prix de la requête. C’est tout simplement parce qu’Anthropic facture l’écriture de tokens dans le cache. Pour une requête isolée, on aurait pu s’en passer, mais à l’échelle d’une conversation entière, on est gagnant.
Heureusement, pour maîtriser vos coûts au fur et à mesure de l’avancement d’une tâche, Cline nous aide en affichant le coût de chaque requête et le coût total de la tâche en cours.
Latency / Throughput
Ces deux métriques reflètent la rapidité du modèle. La latence mesure le temps avant la génération du premier token, tandis que le throughput correspond à la rapidité de génération des tokens suivants. Par exemple avec Claude, si on fait une requête il prendra 1.35 seconde avant de générer un token, puis il les génèrera à un rythme de 59,73 tokens/seconde.
En réalité, ces valeurs ne sont pas intrinsèques au modèle mais au provider. Par exemple, si on reprend notre page OpenRouter, plusieurs providers sont disponibles pour Claude. À noter que c’est transparent pour l’utilisateur, OpenRouter s’occupe du routing (qui l’eût cru ?).

En général, les différences entre les providers restent mineures. Un modèle rapide sera rapide dans tous les cas.
Les métriques de la communauté
Au-delà de la performance du modèle, d’autres aspects peuvent influencer votre choix :
Open-Source
Un modèle Open-Source peut être le seul choix possible pour certains, notamment car qui dit Open-Source, dit qu’on peut héberger sa propre instance du modèle. Cela implique qu’on est certain de garder la souveraineté de nos données.
La plupart des providers comme Anthropic garantissent que les données utilisateur ne sont pas utilisées à des fins d’entraînement. Sur OpenRouter c’est ce que signifie le pictogramme ci-après :

Mais peut-on en être sûrs ? L’illégalité n’a pas l’air d’être un frein à l’entraînement de modèles pour les géants de la tech.
Les Vibes
Les Vibes : cela peut prêter à sourire, mais c’est le terme qui revient le plus souvent pour décrire le ressenti à l’utilisation d’un modèle. Certains utilisateurs jurent par des modèles objectivement moins bons, mais qui paraissent meilleurs, ou l’inverse.
Pour nous par exemple, Gemini Flash 2.0 nous a déçu, on s’attendait à pouvoir économiser beaucoup sans perdre trop de performance, mais en pratique, nous sommes vite retournés sur Claude. Même si comme souvent, nous aurions probablement pu retomber sur nos pattes en faisant un effort de prompting.
Des benchmarks subjectifs comme https://lmarena.ai/ existent. Le principe est que l’utilisateur choisit sa réponse préférée à un prompt donné parmi deux réponses, sans savoir quel modèle est à l’origine de chaque réponse.
Conclusion
Vous parlez maintenant couramment le LLM et vous devriez pouvoir choisir le modèle qui correspond le mieux à vos besoins. Cependant, le modèle ne fait pas tout. Il vous reste à maîtriser les différents outils qui sont à votre disposition pour devenir le développeur augmenté que vous n’aviez jamais rêvé d’être, mais que la société vous oblige à devenir. Ne vous inquiétez pas, c’est l’objet de la deuxième partie de cet article.
