

Cet article a été co-écrit par Tom BOY et David RENOUF
Conférence de Oussama Kandakji, Solutions Architect at Amazon Web Services
Introduction
L’émergence de l’intelligence artificielle et plus particulièrement des outils qui permettent au grand public de générer du contenu rend de plus en plus difficile l’analyse sur la fiabilité et la véracité des informations observées notamment sur les réseaux sociaux. Ce contexte est propice aux propagations de “fake news” ainsi qu’aux diffusions de campagnes de désinformation.
Auparavant, l'analyse du contenu des publications sur les réseaux sociaux était pertinente, aujourd'hui, elle est biaisée. Ce biais est induit par la capacité des outils utilisant l’IA à produire des images et/ou du texte avec une proximité importante de ce que fait l’être humain.
Alors, il est intéressant de faire intervenir une autre méthode d’estimation permettant de qualifier l’information présente dans une publication. Cette fois-ci, au lieu d’analyser le contenu, l’indication porte sur l’analyse du contexte autour de la publication. Le contexte est décrit par les personnes ayant publié ou relayé l’information, ainsi que l’environnement autour de ces personnes : leur travail, leur employeur, leurs relations et bien d'autres.
Cette analyse permet de saisir la proximité d’une publication avec une autre dont on connait la fiabilité et donc de déduire une tendance pour la publication analysée. Si la tendance est plus proche d’une publication contenant de fausses informations, il est plus probable de penser que cette publication contient elle aussi de fausses informations. Au contraire, si la tendance se rapproche d’une publication contenant de vraies informations, alors il est plus probable que l’information véhiculée soit vraie.
Cet article présente une méthode permettant d’établir cette proximité entre deux publications par l’usage d’outils AWS et le langage Python.
Définition du contexte social d’une publication :
Une publication en plus de son contenu est définie par son contexte social. Le contexte social est l’ensemble des éléments qui entourent une publication, d’un point de vue organisationnel et utilisateur. Par exemple, pour un tweet, le contexte social peut être représenté par l’agence de publication qui a publié le tweet, par l’auteur qui a écrit le tweet, par les utilisateurs qui ont commenté le tweet ainsi que par les influenceurs qui ont partagé la publication, ce sont toutes ces entités qui forment le contexte social et c’est cet ensemble de données qu’il faut analyser.
Technologie utilisée
La première question à se poser lorsque l’on veut analyser des données, c’est de savoir quel format utiliser pour ces données ou autrement dit, quel format de données est optimal pour stocker, analyser, traiter et naviguer au travers de ces données de contexte social.
D’après notre conférencier Oussama Kandakji, le meilleur format serait le format “Graphe”.
Pour justifier cela, il s’appuie notamment sur la publication en open source de l’algorithme de recommandation de Twitter qui lui-même utilise la technologie graphe.
L’algorithme est consultable sur le lien suivant : https://github.com/twitter/the-algorithm
Mais qu’est-ce le format de données “Graphe” ?
Prenons un exemple de graphe de données concernant le contexte social d’un tweet :
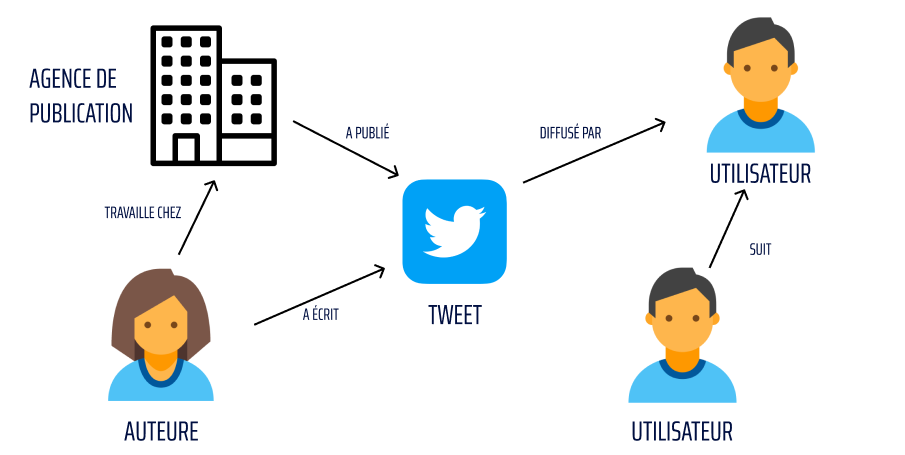
Ce schéma reprend tous les acteurs du contexte social défini précédemment : l’auteure qui a écrit le tweet, l’agence de publication pour laquelle l’auteure travaille, un utilisateur ayant retweeté la publication et un utilisateur suivant l’utilisateur ayant retweeté. Chacune de ces différentes entités représente dans le modèle “Graphe” un nœud. Les liens entre les différents nœuds sont appelés des arcs. Ce sont les principaux objets associés au modèle de données en “Graphe”. Les nœuds sont donc la représentation d’un objet réel et les arcs représentent la relation entre ces différents nœuds.
De plus, les nœuds et les arcs peuvent disposer de propriétés pour apporter de la donnée supplémentaire.
Dans ce contexte, il est possible d’obtenir plus d’informations pour chaque acteur et donc plus de propriétés pour chaque nœud de ce tweet :
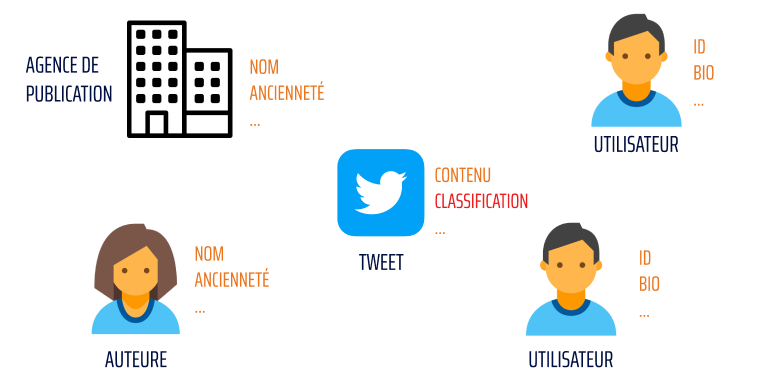
Chaque nœud dispose de diverses propriétés pouvant servir à analyser la véracité du tweet. Grâce à l'analyse du contexte social autour de celui-ci, par exemple un compte avec plus d’ancienneté et beaucoup de tweets considérés comme vrais à son actif, il sera plus facilement susceptible de publier un tweet relayant une vraie information. Inversement, un compte sans publications précédentes et avec une faible activité antérieure au tweet (like, retweet, etc), sera plus susceptible de relayer de fausses informations.
La propriété qui indique la probabilité d’une publication d’être vraie et la propriété “Classification” du nœud “Tweet”. La classification est utilisée pour déterminer si la publication appartient ou non à une campagne de désinformation.
L’objectif est de savoir s' il est possible d’utiliser un graphe existant et exploiter les propriétés des nœuds et des arcs pour effectuer une prédiction sur une publication future.
L’exemple suivant montre le processus de classification d’un tweet inconnu pour répondre à cette question.
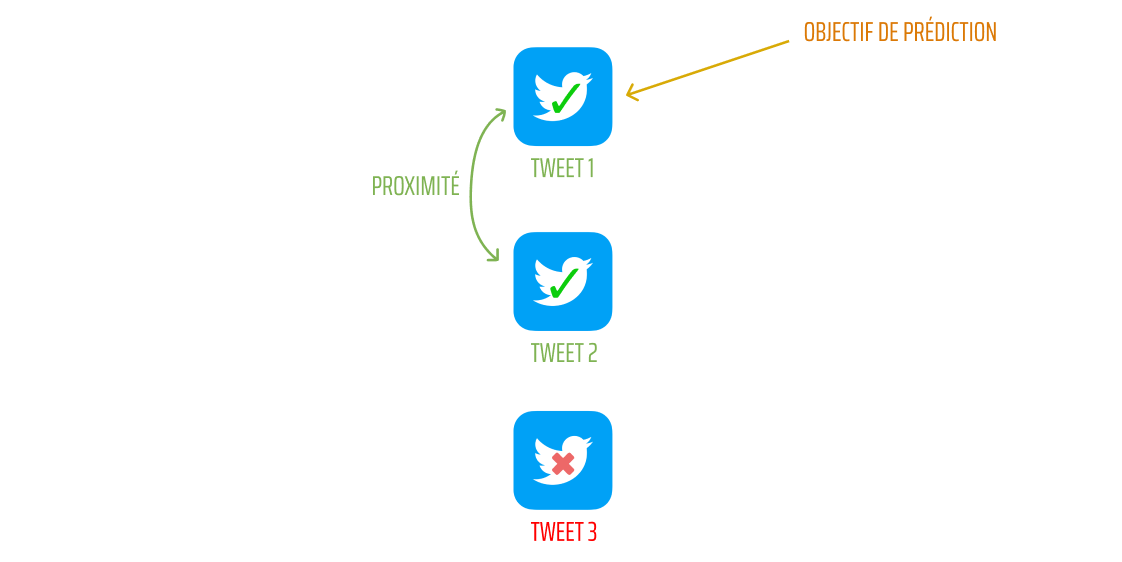
Voici un exemple de classification de publication à une échelle de 3 tweets de référence :
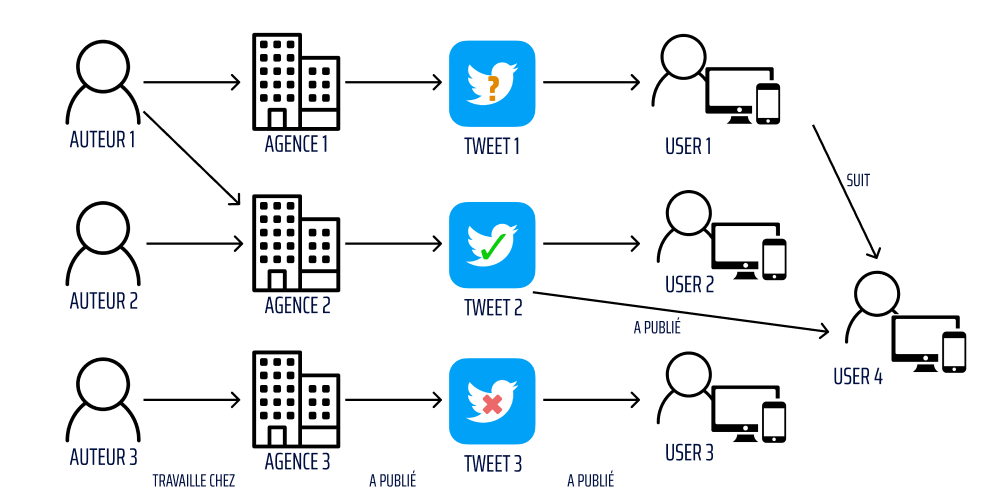
Les 3 tweets considérés ont les propriétés suivantes : un dont l'information est vraie, un dont l’information est fausse et un autre dont on cherche à déterminer sa classification et donc prouver sa véracité ou non. Les tweets ne sont pas classifiés indépendamment les uns des autres, ils influent entre eux.
Premièrement, il est possible d’observer que les tweets 1 et 2 ont plusieurs points de liaison alors que le tweet 3 n’a aucune liaison avec les autres tweets.
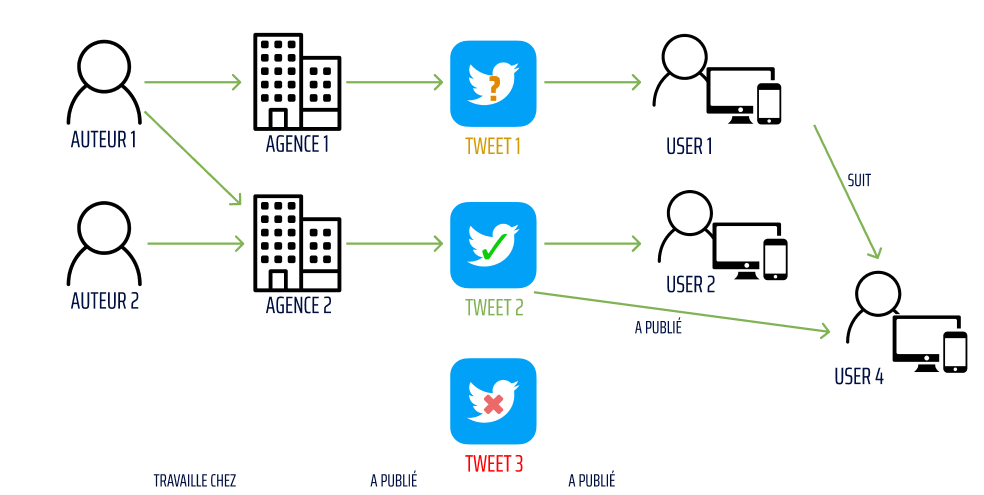
Il apparaît que l’auteur 1 a participé à la rédaction des deux tweets et que l’utilisateur 1 qui a retweeté le tweet 1 suit l’utilisateur 4 qui a retweeté le tweet 2.
On peut donc voir que ces tweet ont une certaine proximité et l’objectif de prédiction de ce tweet sera de dire qu’il relaie des vraies informations.
En plaçant ce cas-là dans un GNN (Graph Neural Networks), on peut voir la proximité des tweets sur un plan 3D :
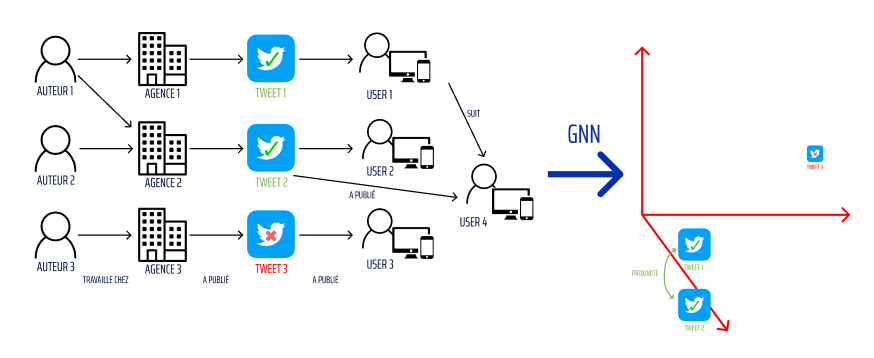
Ceci est bien sûr un exemple grandement simplifié et dans un cas concret les calculs sont bien plus compliqués mais le principe reste le même.
Architecture AWS
Amazon Web Services peut porter cette solution et propose des moyens de la mettre en œuvre. Tout d'abord, AWS dispose du service AWS Neptune pour le stockage de données sous format graphe
Ce service est managé par AWS et est facturé à la demande. Amazon gère de son côté la haute disponibilité du service, les mises à jour, l’installation des patchs de sécurité, les sauvegardes, le chiffrement, … Actuellement, AWS Neptune est en mesure de stocker 128 To de données en graphe par cluster. Pour un niveau d’interopérabilité élevé, AWS Neptune prend en charge les standards du marché permettant l’interaction avec des données graphe (TinkerPop Gremlin, SparQL et OpenCypher).
AWS Neptune ML quant à lui est un service qui permet d'effectuer des prédictions sur des jeux de données en graphe en utilisant les réseaux de neurones en graphe.
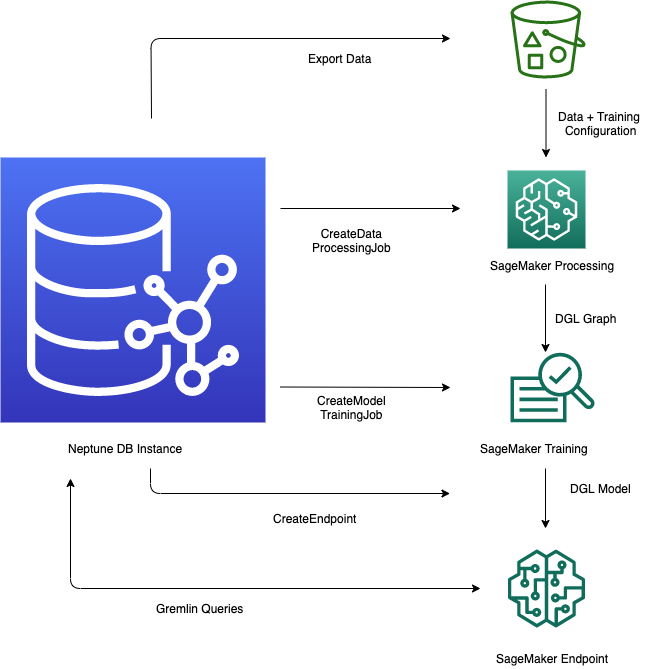
Ce schéma extrait de l'article d'Oussama Kandakji propose l'implémentation qui permet d'arriver à une prédiction pour l'exemple décrit plus haut dans cet article.
Il propose une analyse en 5 phases :
La première phase permet d'exporter les données de AWS Neptune au format CSV dans un S3.
La seconde phase traite les données précédemment exportées de manière à les rendre exploitables pour entraîner un modèle de machine learning pour effectuer des prédictions. Cette étape est possible grâce à l'implémentation d'une tâche SageMaker.
La troisième phase n'est autre que l'entraînement du modèle en question. En utilisant encore une fois SageMaker, on obtient un modèle entraîné qui va servir à effectuer une prédiction sur les données inconnues.
La quatrième phase consiste en la création d'un point d'inférence. Ce point de terminaison SageMaker peut être appelé par différents outils pour fournir le modèle de données entraîné pour effectuer la meilleure prédiction possible.
Finalement, la 5ème étape est celle qui consiste à effectuer une requête avec l'outil choisi (pour notre conférencier gremlin) pour obtenir la prédiction.
Pour plus d'informations sur l'implémentation technique concernant Gremlin, l'article d’ Oussama Kandakji est disponible dans les sources de cet article.
Conclusion :
L'implémentation d'une solution d'analyse et de machine learning sur AWS est possible pour effectuer une analyse qualitative d'une publication. Cette analyse peut permettre de déterminer la proximité d'une publication inconnue avec une dont la propriété de véracité est vérifiée. Cette méthode est pertinente grâce à l'analyse du contexte d'une publication et peut venir compléter ou appuyer une analyse sur le contenu d'une publication pour détecter au mieux l'appartenance à une campagne de désinformation par exemple.
Sources :
- Conférence AWS Summit 2023, Utiliser l'IA pour détecter les fake news, par Oussama Kandakji
- Article AWS https://aws.amazon.com/fr/blogs/machine-learning/detect-social-media-fake-news-using-graph-machine-learning-with-amazon-neptune-ml par Oussama Kandakji
- Documentation AWS
- Github repository : https://github.com/aws-samples/amazon-neptune-ml-fake-news-detection#detecting-social-media-fake-news-with-amazon-neptune-ml
- Dataset utilisé pour entrainer le modèle : https://github.com/KaiDMML/FakeNewsNet