

Introduction
Kubernetes a révolutionné la façon de gérer ses applications. Cet outil, tout d’abord développé par des ingénieurs de Google et basé sur la conteneurisation, a permis de rendre les infrastructures plus flexibles et plus extensibles. Cependant, plus les infrastructures ont grossi, plus la gestion des configurations s’est complexifiée, les fichiers sont devenus de plus en plus nombreux et cela pour créer des ressources quasiment identiques.
Le GitOps est une pratique qui a permis de centraliser la gestion des configurations autour de gestionnaires de version de code en ligne qui deviennent alors des sources de vérité.
Flux est un outil qui permet d’implémenter du GitOps (en mode pull) dans un cluster Kubernetes et Helm est un package manager, un outil qui permet de créer des ressources Kubernetes à partir de templates.
Dans cette série d’articles, je vous présente ces deux outils dans le cadre d’une utilisation sur Kubernetes.
Mon installation :
- Instance AWS Cloud9
- Instance type : m5.large (8 GiB RAM + 2 vCPU)
- OS : Ubuntu Server 19.04 LTS
- Flux v2
Kubernetes
Qu’est ce que Kubernetes ?
Kubernetes (“timonier” ou “pilote” en grec) ou K8s est ce qu’on appelle un orchestrateur de conteneurs, il a d’abord été développé pour des besoins en interne par des ingénieurs de Google puis confié aux soins de la fondation Linux dans le cadre de la Cloud Native Computing Foundation, un projet qui a pour objectif de faire progresser les technologies liées de près ou de loin à la conteneurisation.
Les conteneurs d’applications sont une sorte d’évolution des machines virtuelles mais contrairement à ces dernières, ils n’embarquent pas de système d’exploitation mais utilisent celui du serveur hôte (qui peut être un serveur physique ou virtuel). Ces conteneurs, qui font office de serveurs hôtes pour nos applications, ont pour avantage d’être plus légers en terme de ressources pour l’hôte puisqu'ils embarquent avec eux seulement le nécessaire pour pouvoir tourner.

Avec Kubernetes, les développeurs et opérateurs système ont eu accès à la création de serveurs virtuels de façon plus simple et sans avoir à toucher au hardware ou de la configuration de serveurs complexes.
Par orchestration de conteneurs on entend la gestion du cycle de vie des conteneurs, la gestion de leur lancement, de leur interconnexion, de leur lien avec l’extérieur, leur sécurité etc.
Terminologie :
Un cluster : Un environnement constitué d’un ensemble de serveurs sur lesquels nos conteneurs peuvent se lancer.
Un noeud : Un des serveurs du cluster
Un pod : La plus petite entité manipulable sur Kubernetes. Elle est généralement composée d’un conteneur mais ça peut être plus.
Comment provisionner un cluster Kubernetes ?
Aujourd’hui il existe 3 façons de provisionner un cluster Kubernetes pour son entreprise :
- Installer Kubernetes soi-même sur un ensemble de serveurs. Il existe des outils permettant de faciliter l’installation et la configuration du cluster comme kubeadm.
- Utiliser un service KaaS (Kubernetes as a Service) de différents fournisseurs comme AWS EKS(AWS), Tanzu (VMware), AKS (Azure), IBM Cloud Kubernetes (IBM), etc… Ces services sont plus faciles à utiliser car les cloud providers gèrent les control planes des clusters pour leur utilisateurs..
- Il existe également d’autres services comme Openshift (RedHat) ou Rancher qui apportent une surcouche par rapport à des solutions KaaS.
Pour des utilisations personnelles, il existe également des solutions pour simuler le comportement de Kubernetes sur un seul nœud (serveur) comme MiniKube ou Kind.
Minikube
Dans le cadre de cette série d’articles, j’utilise Minikube, un outil qui permet de reproduire l’utilisation de Kubernetes mais sur une seule et unique machine. Il exécute un cluster Kubernetes sur un nœud (machine) et repose sur Hyper-V directement.
Afin d’avoir un environnement le plus neutre possible, et pour permettre à tous de suivre à la lettre les étapes de cet article, j’ai utilisé une instance Cloud9 sous Ubuntu Server 19.04 LTS, un IDE directement accessible depuis la console AWS, ce qui a pour avantage de ne rien me faire installer sur ma machine et d’avoir un environnement de travail destructible si besoin.
Installation :
$ curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
$ sudo install minikube-linux-amd64 /usr/local/bin/minikube
Lancer Minikube:
$ minikube start
Voir l’état du cluster:
$ minikube status
Arrêter Minikube:
$ minikube stop
A partir de ce moment-là, il n’est pas nécessaire d’avoir un cluster complexe pour faire des démonstrations.
On peut interagir avec le cluster avec la commande minikube kubectl. Par exemple pour afficher tous les pods du cluster :
$ minikube kubectl -- get po -A
Cette commande est assez lourde mais il est possible de l’alléger en utilisant un alias :
$ alias kubectl="minikube kubectl --"
La commande précédente devient donc :
$ kubectl get pods -A
La commande kubectl est la commande qui permet d'interagir avec un cluster kubernetes.
IAC et GitOps
Lorsque l’on crée des ressources Kubernetes (des pods, des services, des déploiements, des ingress, des secrets etc), on a deux approches possibles:
- L’approche impérative qui consiste à utiliser une commande intégrée dans kubectl :
$ kubectl run busybox --image=busybox --dry-run=client
- L’approche déclarative dans laquelle on passe par des manifestes YAML que l’on applique sur le cluster avec la commande kubectl:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: busybox
name: busybox
spec:
containers:
- image: busybox
name: busybox
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
Pour appliquer le fichier ci-dessus :
$ kubectl apply -f pod.yaml
Cette dernière approche a les avantages de pouvoir appliquer les principes de l’Infrastructure As Code (IAC) et permet notamment de pouvoir versionner l’infrastructure dans un répertoire Git, de pouvoir créer des infrastructures hybrides, permet de garder une trace de la configuration présente sur un cluster Kubernetes voire même de la versionner sur un gestionnaire de version de code tel que Gitlab.

Cependant, le stockage des fichiers arrivant ultérieurement à l’application des fichiers, personne ne peut garantir que ce qui est présent sur le répertoire Gitlab correspond exactement à ce qui existe sur le cluster. Une autre personne peut avoir créé de nouvelles ressources sans avoir prévenu son équipe par exemple. Une solution pourrait être de n’autoriser qu’une personne à créer des ressources sur Kubernetes et cette même personne serait chargée d’assurer le versioning de l’infrastructure. Mais on n’est jamais à l’abri d’une erreur humaine, et n’autoriser qu’une personne à déployer des ressources retire l’intérêt d’un outil comme Kubernetes.
De plus, les entreprises qui utilisent Kubernetes se retrouvent avec un nombre conséquent de ressources créées et donc avec de nombreux fichiers de configuration YAML.
Une solution, pour pallier ce problème, est d’adopter la philosophie GitOps et de faire en sorte que le répertoire Git soit utilisé comme source de vérité et que le cluster soit synchronisé continuellement avec cette source de vérité. En adoptant cette philosophie, il y a plusieurs avantages:
- Documentation en temps réel de l'infrastructure
- Tracking des actions effectuées sur le cluster
- Versioning de l’infrastructure (on peut revenir en arrière en cas de problème)
- Mise en place d’une politique de déploiement directement depuis le répertoire git (en général les déploiements sont déclenchés par une Merge Request vers une autre branche)
On distingue 2 stratégies de déploiement dans GitOps.
GitOps Push
Dans cette approche, à chaque fois que le code source d’une application est poussé sur le répertoire Git, la pipeline CI/CD qui y est reliée va builder une nouvelle image de l’application et la pousser vers l’environnement cible. En ajoutant un plugin XL Deploy à un pipeline Jenkins ou bien en intégrant un stage avec une commande “kubectl apply” dans n’importe quel pipeline de déploiement, on peut adopter cette approche.
Le GitOps Push a certains avantages, notamment la gestion des secrets est simplifiée car on peut se contenter de les stocker dans le répertoire Git (pas dans le code bien sûr, mais dans les variables d’environnement par exemple) et qu’avec des outils comme XL Deploy, aucun agent supplémentaire n’est nécessaire. Mais d’un autre côté, ce mode de déploiement fonctionne seulement si la CI/CD a des accès en écriture sur le cluster ce qui n’est pas des plus sécurisé.
GitOps Pull
Dans cette approche, un agent est présent sur l’environnement cible de chaque déploiement. Cet agent va surveiller un répertoire git et appliquer toutes les modifications qui y seront détectées (changement de configuration, changement d’image) afin de faire correspondre l’environnement avec la source de vérité, Git. Cette approche a de nombreux avantages :
- C’est plus sécurisé car aucun agent extérieur n’a la possibilité d’apporter des modifications sur le cluster, seul l’agent en est capable.
- La mise à jour d’images peut être automatisée en surveillant une forge (un ensemble d’outils permettant le travail collaboratif lors d’un développement informatique: gestionnaire de version de code, gestionnaire d’artefact, gestionnaire de tâches, gestionnaire de documentation)
Pour plus de détails sur le GitOps, je vous encourage à lire l’article d’Amine AIT AAZIZI, “GitOps ? La réponse à vos questions”.
Flux v2
Flux, à quoi ça sert ?
Flux est un outil permettant d’appliquer la philosophie GitOps à Kubernetes. Il permet de synchroniser des dépôts Git à fréquence régulière et d’appliquer des modifications sur les ressources Kubernetes d’un cluster. La première version de Flux est sortie en 2017 et devient obsolète à partir de Novembre 2022. La deuxième version a été mise à disposition en 2020 et le projet est incubé par la Cloud Native Computing Foundation (CNCF) depuis 2021. Il s'agit d'un outil en mode pull, c’est-à-dire qu'une fois installé, il tire les éléments dans le cluster et réalise les opérations nécessaires pour arriver à l'état souhaité. Dans le cadre de cet article, on s’intéresse à la V2 de Flux.

La deuxième version de flux est constituée de 4 composants:
- Le Source-Controller: Permet de construire des artefacts utilisables depuis Kubernetes à partir de différentes sources: un répertoire Git (notre cas dans cet article), un répertoire Helm ou un bucket S3. Ce composant va sonder la source à intervalles réguliers et va créer des artefacts.
- Le Kustomize-Controller: Va se baser sur les artefacts créés par le source-controller afin de détecter d’éventuelles modifications à apporter sur le cluster (changement de configuration, création de nouvelles ressources etc) et va notamment créer les ressources nécessaires.
- Le Helm-Controller: Permet de faire du templating à partir des ressources créées par le Kustomize-Controller.
- Le Notification-Controller: Permet de recevoir ou de générer des événements comme des notifications.
Il existe également les Image Automation Controllers qui permettent de faire du scan d’images Docker et de la mise à jour de fichiers YAML automatiquement dans des répertoires Git lorsqu’une nouvelle image est créée dans un répertoire d’images.
Dans ce premier article, nous utiliserons le Source-Controller et le Kustomize-Controller.
Flux Quickstart
Dans cette section Quickstart, nous allons utiliser Flux afin de créer un déploiement de 3 pods, détaillé dans le manifeste suivant :
deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
minReadySeconds: 5
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Ce manifeste est stocké sur un répertoire Gitlab, “fluxcd-gitops-application” :

Installation de la CLI Flux
Flux CLI est l’interface qui permet d'interagir avec l’API de Flux. Sur notre distribution de Linux, on peut l’installer avec la commande suivante :
$ curl -s https://fluxcd.io/install.sh | sudo bash
Installation de Flux sur le Cluster
Nous partons ici du principe que nous sommes déjà connecté au bon cluster Kubernetes et que le nœud Kubernetes est fonctionnel.
Maintenant, il est nécessaire d’installer flux directement sur le cluster.
Côté Gitlab, on commence par créer un token d’accès qui permettra à flux d’accéder au répertoire Gitlab. On se rend dans la section Edit Profile accessible lorsque l’on clique sur notre avatar, puis dans la section Access Tokens. On crée ensuite un token “fluxcd”, avec les permissions en lecture et écriture sur l’Api.
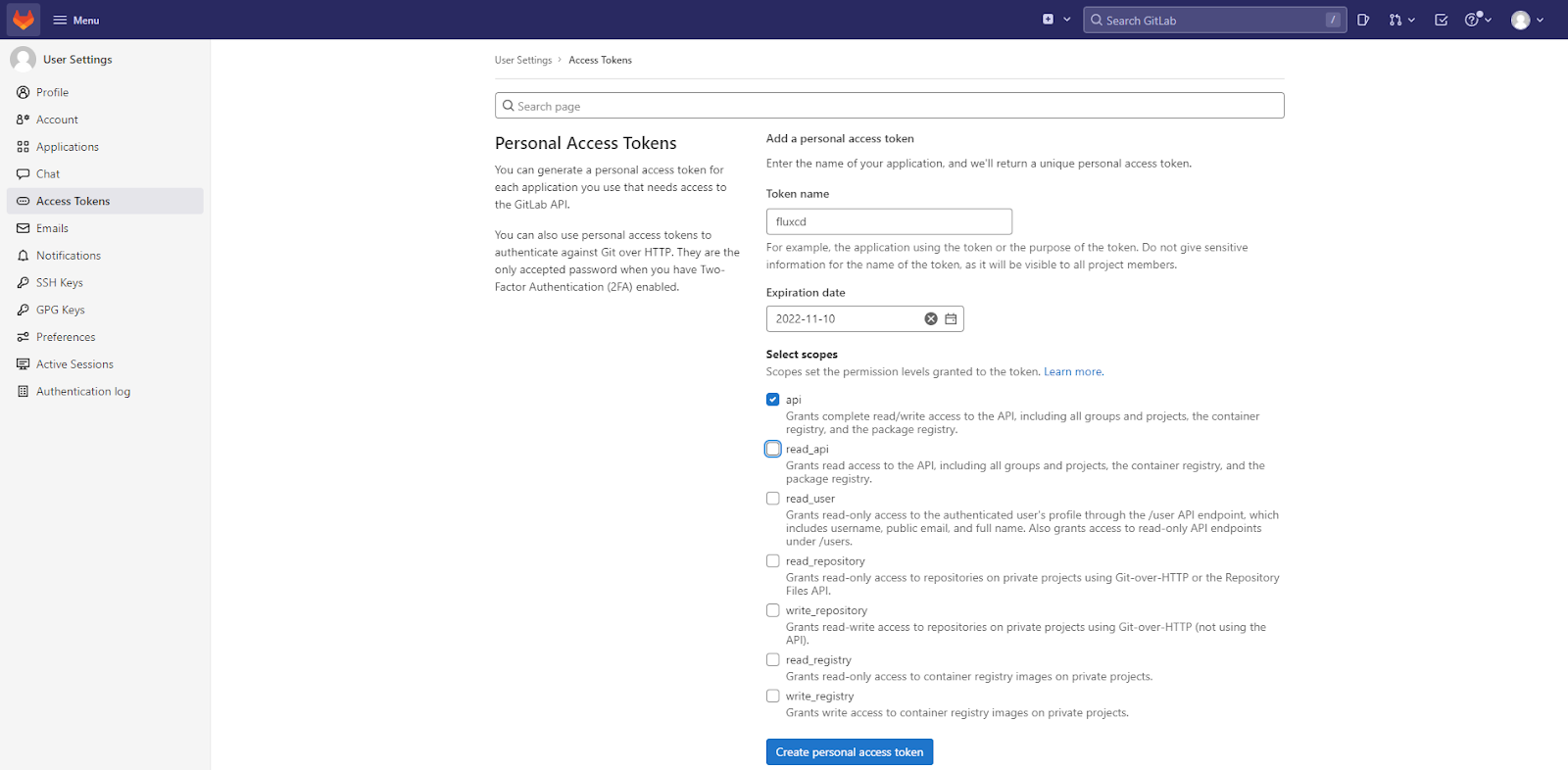
A la fin de la création du token, on a la possibilité de le copier. Maintenant sur l’instance Cloud9, on exporte le token d’accès à Gitlab sous la forme d’une variable d’environnement.
$ export GITLAB_TOKEN=<your-token>
On utilise ensuite la commande bootstrap gitlab pour installer Flux sur le cluster et le configurer pour surveiller un répertoire Git, ici un répertoire Gitlab :
$ flux bootstrap gitlab \
--owner=paulboisson \
--repository=article-gitops-fluxcd-setup \
--branch=main \
--path=clusters \
--token-auth \
--personal
Cette commande permet de :
- Créer le répertoire de code dans notre compte Gitlab si le répertoire n’existe pas déjà
- Ajouter les manifestes YAML des composants de Flux dans le répertoire de code (et va donc effectuer un premier push)
- Déployer les composants Flux sur le cluster Kubernetes
- Configurer les composants Flux présents dans le dossier /clusters dans le répertoire Gitlab d'installation
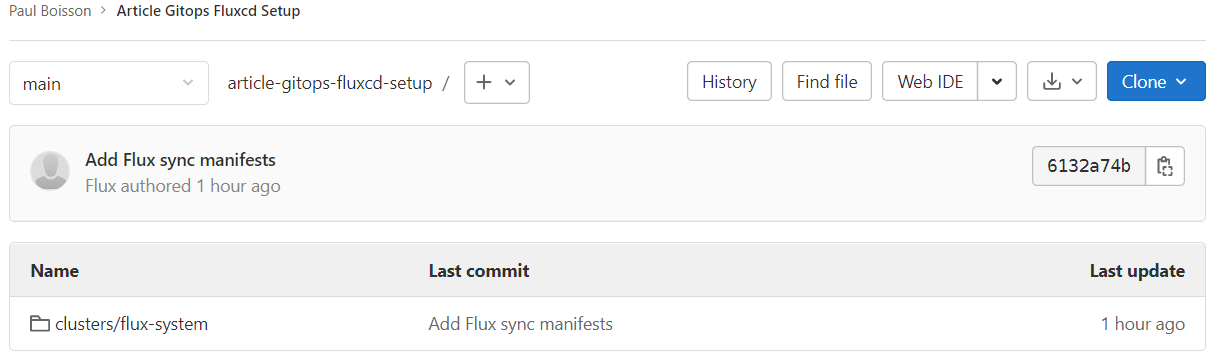
Si on regarde du côté du cluster, un namespace “flux-system” a été créé avec un certain nombre de pods correspondants aux ressources qui constituent Flux.
$ kubectl get pods -n flux-system
NAME READY STATUS RESTARTS AGE
helm-controller-68b799b589-dtrvr 1/1 Running 0 4h10m
kustomize-controller-7ddb8d8f7-lqrx8 1/1 Running 0 4h10m
notification-controller-56bd788f9-hd869 1/1 Running 0 4h10m
source-controller-7d98d6688c-7pnww 1/1 Running 0 4h10m
Dans le cadre de cet article, nous avons 2 répertoires de code:
- Article Gitops Fluxcd Setup (celui dont le path est article-gitops-fluxcd-setup): contenant le nécessaire pour l’installation et le paramétrage de flux dans le cluster
- Article Gitops Fluxcd Application (son path est article-gitops-fluxcd-application): qui contient l’application dont nous souhaitons automatiser le déploiement sur Kubernetes.
C’est sur ce dernier répertoire qu’il faut faire pointer la source git de flux.
Création d’une source Git
On crée donc une ressource “source git” , qui va venir créer un artefact contenant le code de l’application stocké sur la branche “main” sur Gitlab, et cela toutes les minutes :
flux create source git myappsource \
--url=https://gitlab.com/paulboisson/article-gitops-fluxcd-application.git \
--branch=main \
--interval=1m \
--namespace=default
On peut observer les ressources qui ont été créées en utilisant la commande suivante:
$ kubectl get gitrepository
NAME URL AGE READY
myappsource https://gitlab.com/paulboisson/article... 7s True
STATUS
stored artifact for revision 'main/4bce429b553d7081ee758c0e17147b101cfee4de'
Création d’une ressource Kustomization
Un artefact contenant le code stocké sur Gitlab est maintenant créé toutes les minutes. Pour détecter les modifications apportées entre 2 artefacts, nous avons besoin de faire appel au Kustomize-Controller en créant une ressource de type “Kustomization”:
$ flux create kustomization myapp \
--target-namespace=default \
--source=myappsource \
--path="./infra" \
--prune=true \
--interval=1m \
--namespace=default
Cette ressource se base sur la source “myappsource” créée précédemment et plus particulièrement sur ce qu’il y a dans le dossier “/infra” de ce projet. Il va analyser les artefacts toutes les minutes et appliquer les modifications qui y sont apportées dans le cluster. C’est cette ressource qui va permettre de modifier le nombre de replicas du déploiement de notre exemple.
Observons maintenant l’état de nos pods dans le namespace par défaut:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-7fb96c846b-2t6wk 1/1 Running 0 93s
nginx-deployment-7fb96c846b-4jw9d 1/1 Running 0 93s
nginx-deployment-7fb96c846b-dq6cn 1/1 Running 0 8s
Nous avons bien 3 replicas de notre application sur le cluster conformément à ce qui est renseigné dans le manifeste de déploiement. Il est à noter que nous n’avons jamais créé cette ressource nous même, elle a été créée par Flux qui s’est basée sur ce qu’il y a sur notre répertoire de code.
Vérification de la synchronisation
A partir de ce moment, à chaque fois qu’une ressource sera ajoutée au répertoire sur la branche main, la ressource sera automatiquement créée sur le cluster. En général, le GitOps veut que l’on ne pousse pas directement de contenu sur la branche git surveillée par flux, et on peut d’ailleurs l’interdire depuis Gitlab. On passe plutôt par une merge request, validée par un responsable pour apporter toute modification sur le cluster.
Si je modifie le nombre de replicas de mon replicaset et que je pousse mon code sur Gitlab comme le ferait tout développeur, alors le nombre de replicas sera aussi changé sur le cluster. Faisons le test :
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-7fb96c846b-2t6wk 1/1 Running 0 2m10s
nginx-deployment-7fb96c846b-4jw9d 1/1 Running 0 2m10s
En changeant le nombre de réplicas sur le répertoire Gitlab, nous obtenons 2 replicas sur notre cluster.
Conclusion
Dans ce premier article, je vous ai présenté le principe du GitOps et je l’ai appliqué dans le cadre d’une utilisation sur Kubernetes à l’aide de Flux. Dans le prochain article, je vous présenterai Helm, une alternative à Kustomize pour faire du templating de ressource Kubernetes et vous montrerai comment le mettre en place dans le cadre du GitOps.
Source
- Kubernetes, Wikipedia : https://fr.wikipedia.org/wiki/Kubernetes
- “GitOps ? La réponse à vos questions”, Amine AIT AAZIZI : https://blog.ippon.fr/2021/05/19/gitops-la-reponse-a-vos-questions/
- Installation de Flux, Documentation officielle : https://fluxcd.io/flux/installation/#gitlab-and-gitlab-enterprise
- Mise en place de Flux, Documentation officielle : https://fluxcd.io/flux/get-started/
- “Kubernetes GitOps with FluxCD” - That DevOps Guy : https://www.youtube.com/watch?v=OFgziggbCOg&t=140s
- “Faciliter le déploiements k8s avec Kustomize”, ajdaini-hatim : https://devopssec.fr/article/deploiements-k8s-avec-kustomize
- “Comparing Helm vs Kustomize”,Harness :https://harness.io/blog/helm-vs-kustomize
Les répertoires Gitlab
- Article GitOps - Application : https://gitlab.com/paulboisson/article-gitops-fluxcd-setup
- Article GitOps - Flux Set Up: https://gitlab.com/paulboisson/article-gitops-fluxcd-application
