

Cet article a été co-écrit par plusieurs consultants : Achraf EL MAHMOUDI, Arnaud COL, Simon GUILLOCHON, David DALLAGO, Tristan MICHE, Edouard CATTEZ, Imane BENOMAR, Rémy OLIVET et Timothée AUFORT
Ça y est, le AWS re:Invent 2022 est arrivé ! Cette année, Ippon Technologies a envoyé 14 personnes à Las Vegas, 14 consultants avec des spécialités différentes (Cloud & DevOps, Data, Software Engineering …).
Nous avons tous pu assister à des conférences diverses lors de cette première journée. Nous allons vous partager quelques notes prises lors de cette journée, sur des sujets qui nous ont marqués et que nous mettrons probablement à profit dans un avenir proche chez nos clients.
Les services AWS de sécurité pour la détection de menaces sur des containers
Écrit par Timothée AUFORT
Scott Ward, Principal Solutions Architect chez AWS et Mrunal Shah, Head of Container Security chez Warner Bros. Discovery - HBO Max étaient présents pour nous parler des sécurité sur AWS autour des containers.

Scott Ward (à droite) et Mrunal Shah au AWS re:Invent 2022
Les services AWS autour de la sécurité des containers
Depuis début 2021, GuardDuty peut vous aider à protéger vos clusters Kubernetes EKS en utilisant les logs du Control Plane Kubernetes pour détecter des menaces. Les anomalies remontées par GuardDuty EKS sont classées par sévérité et contiennent entre autres un guide de remédiation et du contexte sur l’anomalie (les ressources impactées, l’action réalisée…). N’hésitez pas à consulter cet article de blog écrit par AWS qui parle de ce service plus en détail. En sus, GuardDuty Malware Protection peut désormais être utilisé pour analyser des containers. Il peut détecter des malwares sur ECS, EKS ainsi que sur des clusters Kubernetes classiques déployés sur des instances EC2.
Detective supporte depuis juillet 2022 les workloads EKS. Il permet d’investiguer les résultats remontés par GuardDuty et est capable, à partir des logs d’audit EKS, d’extraire automatiquement les containers des Pods ou encore les comptes utilisateur. Detective renvoie également des détails sur l’activité de l’API Kubernetes ainsi que sur le réseau.
Inspector a été relancé pour les containers au moment du re:Invent 2021 et peut désormais scanner les images Docker. Il peut récupérer les images Docker depuis ECR, extraire chaque couche des images, analyser l’OS ainsi que les paquets installés et regarder plus en détails le filesystem des images. A l’instar de GuardDuty, les résultats renvoyés par Inspector fournissent une sévérité et un guide de remédiation.
Et HBO Max dans tout ça ?
HBO Max utilise un mix de clusters Kubernetes et EKS avec des self-managed nodes. Ils ont des centaines de clusters, des centaines de microservices, des dizaines de milliers de containers pendant les prime times, des milliards de requêtes API par jour…
Ils utilisent GuardDuty pour identifier des menaces sur leurs clusters Kubernetes. Les investigations sont menées grâce à Detective. Inspector est utilisé à la fois dans le cadre EC2 (pour analyser des AMI avant qu’elles ne soient publiées sur AWS) et à la fois dans le cadre container.
HBO Max fait usage des images distroless qui contiennent beaucoup moins de vulnérabilités que des images avec des OS complets et valide avec Inspector que ces images peuvent être déployées sur des workloads de production.
Perspectives ?
Dans un monde où on utilise de plus en plus de containers, les 3 services présentés peuvent clairement apporter de la valeur en termes de sécurité, de monitoring et de qualité de livrables. Il serait dommage de s’en passer.
L’IoT appliqué aux énergies renouvelables
Écrit par Achraf EL MAHMOUDI
J’ai participé à un workshop portant sur la construction d’une plateforme AWS IoT pour un cas d’usage autour des énergies renouvelables (éoliennes). J’étais surtout en quête de nouvelles idées pour mon client qui est justement dans ce domaine d’activité et par envie de découvrir de nouveaux services managés dédiés à l’IoT.

Sources de données : des éoliennes miniatures présentes dans salle
L’objectif de l’atelier est de pouvoir récupérer des métriques issues des turbines physiques, de les traiter via les services AWS (Iot Core, SiteWise et TimeStream) et de les visualiser sur Grafana.
Pour cela, il nous a fallu suivre l’architecture suivante :

À l'issue de cet atelier, les participants sont en mesure de :
- Acheminer et stocker des données issues de capteurs
- Le service IoT Core (3), que nous utilisons dans ce workshop sert de broker MQTT. Il nous permet d’intercepter les messages issues des capteurs et de les distribuer via des règles et actions en direction des services de destination.
- En solution de stockage, nous avons transmis les données brutes vers S3 (8) pour de sauvegarde froide et utilisé Timestream (7) en tant que base temporelle.
- Traiter les données IoT industrielles à l'aide d'AWS IoT SiteWise (4)
- Nous avons notamment utilisé AWS IoT SiteWise pour créer le modèle de la donnée. Ce modèle décrit les mesures à récupérer et leur unité, telles que la température (F), la vibration (m/s2) ou les tours par minutes (rpm)
- Construire des scènes et créer des alarmes et des règles dans le compositeur de scènes AWS IoT TwinMaker (5)
- Le service permet d’avoir une vue 3D des turbines et d’afficher des signaux visuels de l’état de santé des turbines grâce aux règles définies (exemple: si température > 80, affiche la turbine en rouge)
- Connecter les scènes et les données TwinMaker aux tableaux de bord Grafana (6) et créer des applications personnalisées pour un persona d'utilisateur final.
Le workshop était très complet et m’a donné envie d’aller jusqu’au bout. J’ai pu avancer très rapidement sur la première partie, qui consistait en la construction du pipeline d’ingestion jusqu’à S3 et AWS Timestream, ce sont en effet des outils que nous maîtrisons chez Ippon et que nous avons mis en production (cf REX Arkema). D’autres part, j’ai pu approfondir les services AWS SiteWise et AWS TwinMaker que je maîtrisais moins.

Résultats sur Grafana
Le workshop sera disponible au public sur AWS à partir de février 2023, en attendant stay tuned chez Ippon nous allons prochainement sortir un Coding Dojo sur cette thématique !
Build an NFT marketplace on Ethereum with AMB
Écrit par Simon GUILLOCHON
J’ai assisté à un workshop tenu par Rafia Tapia, Blockchain Specialist Solution Architect chez AWS autour des NFT.
Pour réaliser ce workshop, nous avons utilisé des outils variés : une instance medium EC2 pour exécuter le code réalisé sur Cloud9, une table DynamoDB pour stocker les NFT et les rendre accessibles aux différents utilisateurs de notre marketplace, le service Managed Blockchain pour configurer un lien avec Goerli, testnet public d’Ethereum et deux outils de la Truffle Suite (Ganache pour l’environnement de développement et Truffle pour des tests automatisés).

Instance Amazon Managed Blockchain configurée lors du workshop
Puisque lister simplement des outils manque d’intérêt, allons droit au but. L’objectif de ce workshop étant d’apporter un minimum de compréhension sur la réalisation d’une marketplace NFT, voici les quelques notions abordées. D’une part, l’implémentation d’un smart contract ERC 721 grâce à OpenZeppelin permet d’utiliser les nombreuses fonctions liées à l’idée qu’on se fait de l’utilisation d’un NFT. Ensuite, la configuration d’un environnement de développement avec la Truffle Suite combiné avec l’Amazon Managed Blockchain rendent l’outil très puissant pour arriver rapidement à une solution viable à n’importe quel client souhaitant développer sa marketplace sur le Web3.
Merci encore à Rafia Tapia et ses collaborateurs chez AWS pour nous avoir accompagné tout au long de ce workshop qui n’a jamais manqué d’intérêt. Ce workshop servira d’inspiration pour les futurs générations de software engineers de la blockchain chez Ippon Technologies !
La culture de l’innovation chez Amazon
Écrit par Arnaud COL
Giulia Rossi, Principal Digital Innovation Lead @ AWS, nous a présenté comment la culture “It’s Always Day1” permet à tous les employés du groupe Amazon de rester concentrés sur les priorités, à savoir :
- L’obsession client
- Comment en faire un réflex en plaçant le client au coeur de ses préoccupations
- Avec par exemple la fameuse “chaise vide” qui représente le client dans toutes les réunions stratégiques chez Amazon
- La prise de décision rapide
- Comment faire naître des habitudes sur la prise de décision ?
- Un exemple chez Amazon est le principe de la 2 pizzas team. Toutes les décisions qui concernent un sujet doivent pouvoir être prises par une équipe de 7 à 10 personnes. A cette échelle, chacun a son mot à dire.
- Pas de slides ! Chez Amazon, on partage ses notes avant une réunion plutôt que de montrer des slides pendant.
- Dans les notes, il y a tout le niveau de détail nécessaire à la prise de décision.
- Expérimenter pour changer les habitudes
- Avoir des équipes suffisamment proches du client pour proposer des innovations adaptés


Migrating from Amazon EC2 to Amazon ECS for application modernization
Écrit par David DALLAGO

Ce talk présente une modernisation d’application en passant d’EC2 à ECS afin de bénéficier des avantages suivants :
- Coût réduit grâce à la densité d’images exécutables sur une même instance EC2
- Sécurité sur les images déployées
- TTM réduit par rapport au déploiement sur EC2
Le use case consiste à migrer une application de vote :
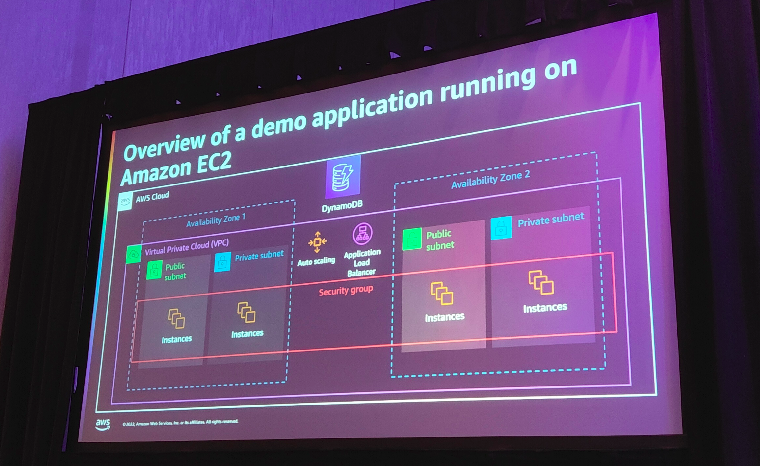
Elle repose sur :
- Un groupe d’instances EC2 I1 en subnet public exposé via un Load Balancer
- Un groupe d’instances EC2 I2 en subnet privé poussant les votes vers une base DynamoDB
- Des security groups pour autoriser les appels HTTP I1 vers I2
- De la réplication sur deux Availability Zone pour la haute disponibilité
- D’autres layers qui ne sont pas visibles dans ce schéma en particulier les différentes briques CloudWatch
Une migration ECS from scratch entraîne :
- La création d’images docker pour les services exécutés sur les groupes I1 et I2
- La création des repository ECR pour héberger les images docker
- La gestion des autres layers cités précédemment.
Nous arriverions à 43 différents composants AWS à manager et créer pour un use case plutôt simple.
Afin de simplifier la mise en place de l’infrastructure AWS Copilot est une CLI type wizard guidant l’utilisateur et visant à :
- Faciliter l’initialisation de tous ces layers pour les développeurs, SRE et platforms engineers
- Initialiser une CICD pour l’application
- Faciliter le management de l’application
Cela tient en quelques étapes simples pour chacun des repository de l’application :
- copilot init : wizard qui va demander le nom du service et son type, Load Balanced Web Service dans notre cas, initialiser l’infrastructure, construire l’image et la déployer. Cela va générer dans le repository un manifest.yml décrivant l’infrastructure, le scaling, les secrets, etc.
- copilot env init : cette commande permet ensuite de configurer un nouvel environnement. Cela va permettre d’avoir des environnements de test (integration, staging, etc).
- copilot deploy : on peut éventuellement déployer manuellement vers un des environnements précédemment configurés, mais il est préférable de configurer une pipeline.
- copilot pipeline init : comme son nom l’indique, cette commande va initialiser une pipeline customizable dans un pipeline.yml et contenant par défaut:
- Un source stage pour pull les sources
- Un build pour pousser l’image vers ECR
- Deploy to test
- Deploy to prod
- copilot svc logs follow : pour voir les logs d’un service
Avec ces quelques commandes, une application est très rapidement déployable sur ECS et nous permet de nous concentrer sur le code métier de l’application.
Pour conclure, je dirais de ma vision consultant backend que cette CLI est un accélérateur de déploiement sur AWS appropriée sur du scale up. Un switch vers le standard du marché Terraform reste possible modulo une charge de travail.
Resources :
- Repository: https://github.com/aws/copilot-cli
- Documentation: https://aws.github.io/copilot-cli/
La migration d’applications de santé vers AWS
Écrit par Tristan MICHE
Les besoins de migration vers le cloud des applications dans le domaine de la santé en particulier les EHR (Electronic Human Record) les cousins américains de notre DMP, mais en général à l’échelle d’un ou plusieurs hôpitaux ont beaucoup augmenté ces trois dernières années, principalement pour trois raisons :
- La “Great Resignation” qui a entraîné une forte tension sur les métiers de l’IT spécifique à la santé
- Une pression financière sans concession sur la disponibilité
- Des cas d’usage se prêtant bien à l’utilisation de services cloud
On notera qu’il s’agit de workload ultra critique disposant systématiquement d’un PRA.
Le succès de ces migrations reposent principalement sur trois piliers suivants :
- Construction d’une Landing zone conforme ( HIPAA/HITRUST aux USA, HDS en France par exemple)
- Un plan de formation systématique des équipes du métier à l’infrastructure
- Des applications modernisées pour tirer partie des avantages du cloud notamment en matière de disponibilité et de sécurité..
Les différents retours d’expériences proposés montrent les avantages d’une approche de migration en trois phases :
- Apprentissage pur: Migration de test à des fins de prises en main des services, des processus de bascule et de migration, mesure de l’impact des changements à apporter.
- Migration des env hors production
- Migration de la production
Les principaux bénéfices observés:
- Une capacité d’innovation supérieure
- Une disponibilité plus simple à gérer, en particulier le processus de PRA
- Un périmètre de conformité plus faible grâce au modèle de responsabilité partagés
Une courte conférence intéressante qui montre les possibilités de migration des applications manipulant des données de santé en optimisant les méthodes standards de migration.
Building a smart city for Buenos Aires city government
Écrit par Edouard CATTEZ
Avec l’utilisation des services AWS pour le Machine Learning, et notamment de SageMaker, Buenos Aires s’est inscrit comme la première “Smart City” du monde.
En entraînant des modèles, les caméras de surveillance de la capitale ont été repensées pour protéger les citoyens et réduire les accidents de la route : détection du port de la ceinture de sécurité et détection du téléphone à la main. C’est aussi une aide à la police qui a été apportée : analyse des plaques et concordances avec les modèles de voiture pour éviter les véhicules maquillés, traçabilité de voitures volées, passage au feu rouge...
Les usages du Machine Learning semblent infinis et peuvent s’adresser à des domaines variés : médical, transport, industrie…
Comment bien analyser les données du développement durable ?
Écrit par Imane BENOMAR
Ma première conférence portait sur AWS Data Exchange et comment l’utiliser pour faciliter la recherche et l’utilisation des données, spécifiquement les données nécessaires pour soutenir le développement durable et les critères environnementaux, sociaux et de gouvernance (ESG).
On a débuté la session par une présentation de l’outil AWS Data Exchange, c’est une Marketplace data qui fournit des jeux de données diverses et multiples provenant de plusieurs sources et accessibles via API, fichiers ou par une connexion directe par les plateformes d’analyse de données comme Amazon Redshift ou Amazon quicksight.
Pour mieux comprendre l’utilité de l’outil, on a fait un focus sur les avantages des voitures électriques pour l’environnement et on a essayé de répondre à un besoin qui est d’installer des nouvelles bornes de recharge pour les véhicules électriques. Pour cela, avec les deux animateurs de la session et la trentaine de participants, on a essayé de construire une architecture sur AWS qui permettra d’analyser rapidement les données sur les bornes de recharge qui existent déjà, les données démographiques et les données de localisations afin de trouver le bon emplacement pour les nouvelles bornes à installer.
On a fait une architecture avec plusieurs options qui intègre AWS Data Exchange, afin de faciliter le data sourcing.
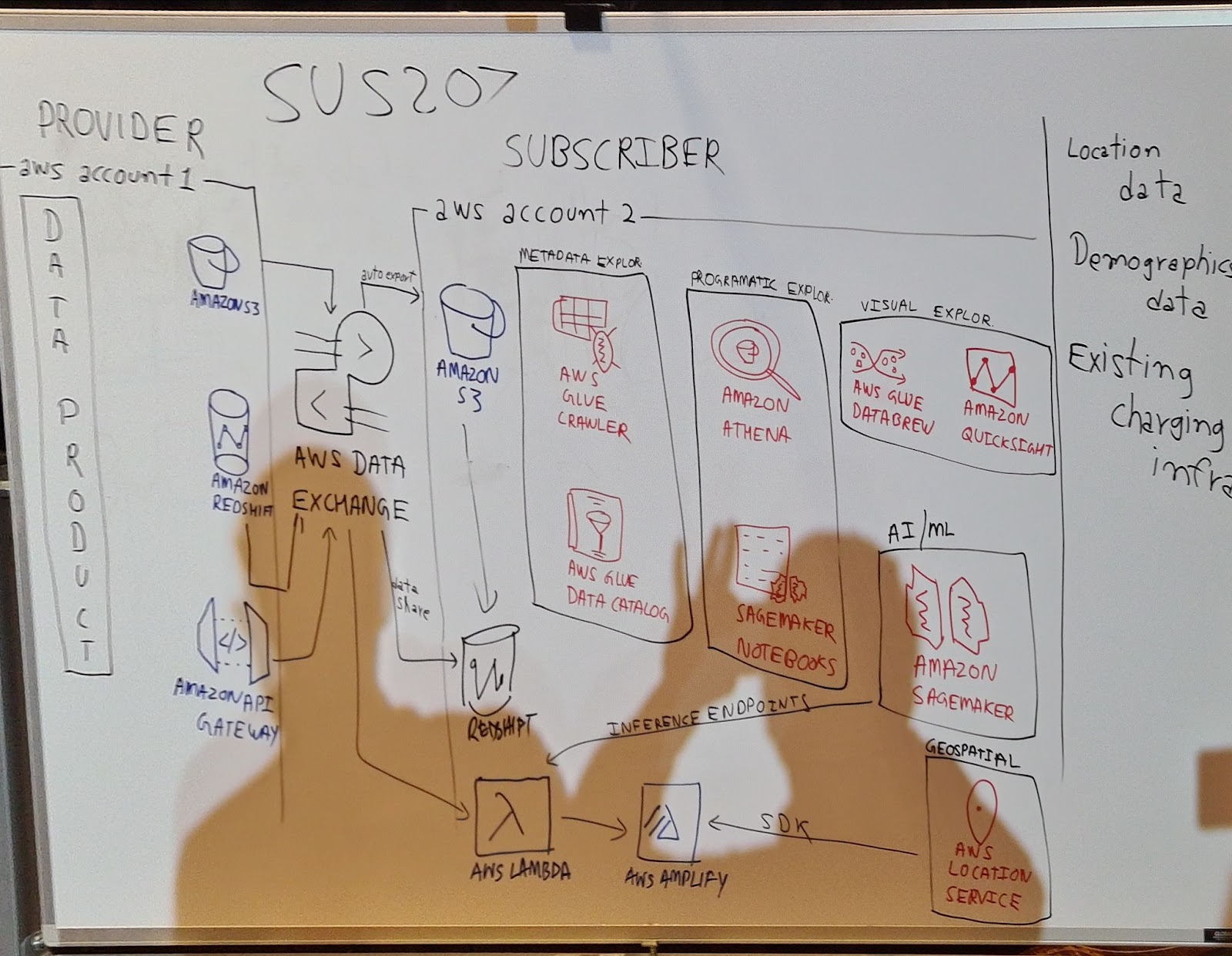
Draft de l’architecture proposée
La session était enrichissante, on a pu proposer une architecture complète en seulement quelques minutes et j’ai beaucoup apprécié le côté intéractif du chalk talk.
Serverless future of data analytics
Écrit par Rémy OLIVET
Voilà 1 an que je n’ai pas réellement développé, c’était le moment parfait pour s’attaquer au serverless en analyse de données. Ce paradigme du cloud computing me ramenait dans mon jardin sans me complexifier la vie dans la gestion des serveurs : Happy Me !
Basé sur le “serverlesspresso” d’AWS, cette machine à café connectée qui prend vos commandes expresso, les envoie à votre machine à café connectée et vous envoie une notification quand le café est prêt, il est maintenant temps d’analyser les commandes passées et les habitudes des clients.
Serverless & Data font bon ménage chez AWS depuis pas mal de temps. Nous nous sommes donc amusé à :
- ingérer la donnée des events générés par serverlesspresso depuis event bridge vers un datalake s3 en utilisant MSK serverless et Kafka-connect ;
- filtrer, nettoyer, transformer la donnée en utilisant EMR serverless ;
- stocker, modéliser et exposer la donnée dans notre datawarehouse Redshift serverless.

En deux heures, nous avions une plateforme ready-to-use jonglant avec des services serverless, prêt à passer en production, à l’échelle. Le workshop était certes dense mais intéressant dans son approche … Serverless is the future !
Je n’ai, maintenant, qu’une seule envie : “trouver une machine à café connectée et faire ça chez moi !”
Keynote Monday Night Live
Écrit par Tristan MICHE et Timothée AUFORT
Pour finir la journée, rien de tel que d'assister à la keynote toujours très dynamique de Peter DeSantis avec cette année encore quelques annonces très réjouissantes :
Dotées de nouvelles cartes Nitro, elles offrent jusqu'à 200 Gbps de bande passante réseau et un packet processing jusqu'à 50 % plus élevé par rapport à la génération précédente. Elle est particulièrement adaptée pour des appliance réseau ou de l’apprentissage AI/ML,
En s’appuyant sur le protocole Scalable Reliable Datagram (SRD), ENA express diminue la latence jusqu’à 50% par rapport au TCP standard tout en augmentant la bande passante maximale par flux de 5 Gbps à 25 Gbps. ENA Express est activable sur les ENA existantes ou nouvelles pour profiter de ces performances entre les instances c6gn fonctionnant dans la même zone de disponibilité.

SnapStart active la mise en cache d’un snapshot immuable et chiffré de la mémoire et du disque lors de la publication d’une Lambda. Ce cache contient ainsi toute la phase d'initialisation. Il permet ensuite une exécution plus rapide et plus prédictible (quasi suppression du cold start). Il n’y a pas de surcoût.

Il ne reste plus qu'à tester ces nouveautés !!!
PS : Pour découvrir notre récapitulatif de la 2ème journée de ce re:Invent 2022, dirigez-vous ici.
