

Vous n’êtes probablement pas tombé sur cet article par hasard. En effet le traitement/stockage/envoi de données biométriques n’est pas un sujet anodin, et si vous cherchez à envoyer ou recevoir des données biométriques, vous êtes au bon endroit.
Dans les paragraphes qui suivent, je vais vous présenter le format de données biométriques le plus commun quand il s’agit d’échanger ces dernières, accompagné de quelques tips et liens utiles pour approfondir le sujet.
Qu’est-ce qu’un fichier NIST ? (TL;DR)
Pour ceux qui connaissent déjà ce genre de fichier ou qui veulent plonger directement dans la technique, TL;DR :
NIST est un type de fichier permettant de formater des informations biométriques (empreintes digitales, photo, cicatrices, etc.) et autres données concernant le contenu, le format et les unités de mesures des dites informations dans l’objectif d’une transaction dudit fichier.
Pour les curieux 🔍 :
Créé par l’ANSI (American National Standards Institute) il y a de ça plus de deux décennies dans le but d’effectuer des transactions contenant des données biométriques entre différentes organisations et autres administrations de justice pénale. Ce format vous permettra de stocker sous forme de conteneurs, appelés "records", une suite d’informations biométriques telles que des empreintes, des photos de passeport, des photos de visage et même tatouages ou autres cicatrices. Il existe une quinzaine de types de records ayant chacun leur spécificité. Ils permettent chacun de stocker lesdites informations ainsi que les données essentielles à leur traitement mais également des informations essentielles à la transaction du fichier NIST. Pour plus d’informations sur le contexte et l’objectif derrière cette techno je vous invite à consulter la partie #1 de ce document.
Fonctionnement du fichier et Records utiles
Fonctionnement d’un record
Comme dit précédemment le fichier est composé de records, mais comment fonctionnent ces records ?
Chaque record contenu dans le fichier sera composé de plusieurs champs d’informations, pouvant contenir une ou plusieurs entités d’information unique. Les champs d’informations peuvent également contenir des sous-champs (comme Alain).
Chaque sous-champ se compose d’entités d’information regroupées et répétées.
Ils se déclinent en types. Chaque type étant un patron prévu pour contenir des informations concernant une image (Type-7 user-defined image record, Type-14 variable-resolution tenprint image record, …) ou simplement des données liées au fichier et à la transaction.
Point important :
Chaque type possède des champs obligatoires et des champs optionnels. Certains possèdent même un espace dédié pour qu’un utilisateur ajoute des champs personnalisés. Ces champs et leur statut (obligatoire/optionnel) sont définis par un fichier de vérification qui établit un contrat de transaction à la manière d’un XSD pour du XML. C’est ce fichier qu’on va modifier si on souhaite customiser nos records.
Fonctionnement du fichier
Maintenant que l’on connaît leur fonctionnement, voyons comment construire notre fichier avec ces fameux records. Contenant des informations concernant un et un seul individu, chaque record va transporter une information spécifique, une image, une signature, une empreinte digitale, etc. Observons désormais la manière dont ces records sont organisés et les quelques normes qu’ils suivent :
- Premièrement, le fichier contient un et un seul record de type 1 (appelé transaction information record) placé au début du fichier, si le fichier ne contient qu’un seul record, ce sera celui-ci.
- Le record de type 1 fonctionne comme un header pour le fichier, contenant des informations sur la transaction du fichier, le fichier en lui-même et les records qui le constituent.
- En fonction de l’usage et de l’objectif derrière l’envoi du fichier, ce dernier pourra contenir un nombre variable de records contenant des images d’empreintes digitales ou palmaires, de visage, de tatouage, etc. L’ordre de ces records n’importe pas tant qu’il correspond à celui indiqué dans le record de type-1 et dans le fichier de vérification.
Présentations des records
Type-1 transaction information record
Comme expliqué précédemment, le type 1 est obligatoire et doit être présent dans chaque transaction. Il contient des informations sur le type et l’objectif de la transaction (si c’est une requête ou une réponse par exemple) ainsi que sur son contenu (liste des records).
Type-2 user-defined descriptive text record
Ce record a pour objectif d’apporter des éléments de description concernant l’individu lié à la transaction. Il est assez libre et permet de créer un grand nombre de champs personnalisés, l’ajout de ces champs étant décidé par les deux parties de la transaction pour un échange d’informations efficace.
Type 3-4-5-6-7-8-10-14
Tous les records spécifiés ci-dessus sont similaires. Ils ont pour but de stocker une image ainsi que des informations nécessaires à son traitement telles que la résolution de l’image, le type de doigt scanné (index, majeur, …), le format de l’image (JPEG, PNG, …), etc.
Quelles sont alors leurs subtilités ?
La plupart apportent des spécifications et des champs d’informations adaptés au traitement d’un type d’image en particulier, et cela transparaît dans leurs noms :
- Type-3 low-resolution grayscale fingerprint image record
- Type-4 high-resolution grayscale fingerprint image record
- Type-8 signature image record
- Type-10 facial & SMT (scar, mark, tattoo) image record
- Type-14 variable-resolution tenprint image record
Certains de ces records, les types 5/6 low/high-resolution binary record, sont prévus pour l’échange d’images stockées en binaire et sont donc assez peu permissifs en termes de customisation.
Le record restant est légèrement à part. Le type-7 user-defined image record propose en effet une implémentation similaire, cette fois sans spécification. Ce record a pour utilité de stocker un image qui ne se place dans aucune des catégories précédentes et d’ajouter des champs d’information correspondant à ce type d’image. Ainsi, comme le décrit son titre, c'est un record d’image dont le type est à définir par l’utilisateur.
Pour que vous puissiez vous représenter la chose, voici quelques exemples :
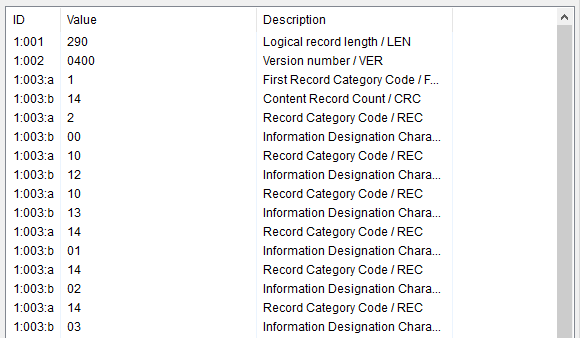
Premièrement voici à quoi ressemble un record de type-1, où l’on peut clairement voir l’application des sous-champs évoqués précédemment (1:003:a et 1:003:b).
Dans une vue plus globale, on peut voir les différents records d’empreintes digitales suivis ici par un record contenant une image de passeport avec sur la gauche les informations liées au record.

Tips et Records Utiles
Maintenant que nous avons vu les grandes lignes d’un fichier NIST, voyons maintenant quelques indications qui pourraient vous être utiles si vous avez à créer ou manipuler ce genre de fichier.
Premièrement je ne vous conseillerais pas de s’orienter vers les records binaires, à moins d’être certain de n’avoir besoin que des informations contenues dans le record de base. Ces records ne vous permettent pas d’ajouter des champs d’informations supplémentaires.
Je ne vous conseillerai pas non plus de vous orienter vers un type-7 (User-defined image record) si vous n’y êtes pas contraints. En effet, les records concernant les empreintes, signatures, photos, etc. proposent un nombre de champs prédéfinis qu’il serait bien fastidieux de reconfigurer manuellement sur un type-7.
Si vous avez besoin d’implémenter une utilisation de ce fichier en Java ou en C#, je vous conseille l’utilisation du SDK NISTPack d’Aware qui, personnellement, m’a bien aidé pour la génération et la vérification de ce type de fichier.
Pour finir, si vous avez besoin d’informations ou de détails supplémentaires, je vous aiguillerai dans un premier temps vers ce document du National Institute of Standards and Technology qui décrit la structure et les différents usages du fichier.
Dans le cas où ce dernier ne suffirait pas, INTERPOL peut vous proposer ce “résumé” de 754 pages sur l’implémentation de l’échange de données biométriques qui, je pense, pourrait contenir les derniers détails dont vous avez besoin. 😇
