

Dans cet article, nous allons voir comment mettre en place un déploiement progressif d’une application dans un cluster Kubernetes grâce à Flagger.
🤔 C’est quoi un déploiement progressif?
Avant de commencer à découvrir Flagger, nous allons faire un rappel de ce qu’est un déploiement progressif ; une des stratégies de déploiement préconisée par le mouvement DevOps.
À l’origine, Kubernetes fonctionne en mode Rolling update, c'est-à-dire qu’une nouvelle version de l’application est lancée en parallèle de la version actuelle et lorsque celle-ci est prête, on envoie 100% du trafic sur cette version, puis on supprime l’ancienne version. Cela permet de ne pas avoir de temps d'arrêt.
Le problème de ce mode de déploiement est que le trafic passe d’une version à une autre très rapidement et sans contrôle.
L’idée du déploiement progressif permet de “jouer” plus finement avec le réseau et ainsi pouvoir proposer des solutions de mirroring (duplication du trafic), split des utilisateurs, etc. Ce qui permet de limiter l’impact de la nouvelle version sur les SLO (rollback si une erreur est détectée) ou de faire des previews pour des utilisateurs cible.
🤔 C’est quoi Flagger?
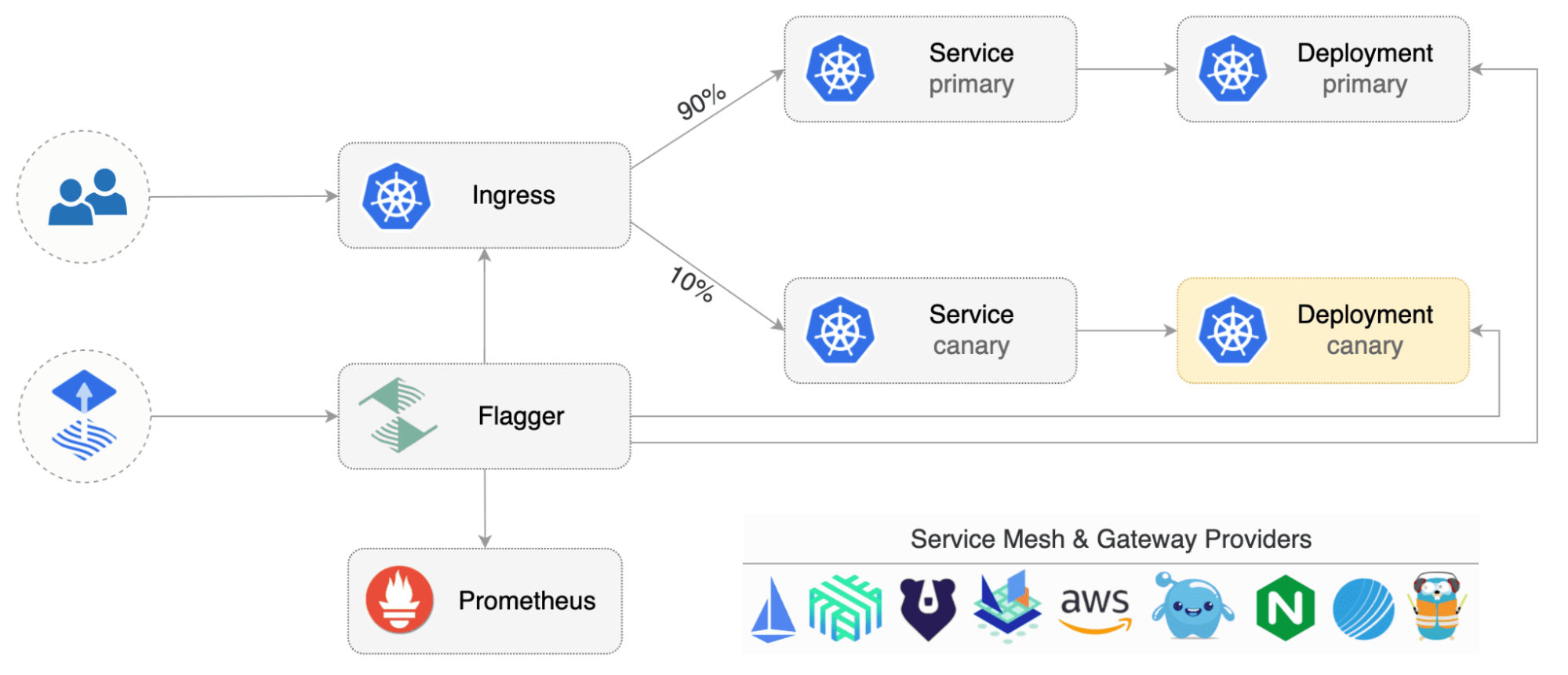
Flagger permet de déployer de façon progressive une application tout en mesurant les indicateurs de performance clés tels que le taux de réussite des requêtes HTTP, la durée moyenne des requêtes, etc. Grâce à ces indicateurs, Flagger est capable de promouvoir ou abandonner le déploiement.
Flagger est un outil open source qui se déploie sur un cluster Kubernetes.
Pour gérer le trafic réseau, Flagger se base sur les mesh controller comme par exemple Istio Nginx, Gloo Edge ou Traefik. Le Mesh controller fournit les mécanismes réseaux nécessaires pour que Flagger implémente les processus de déploiement progressif. Flagger va changer automatiquement les ressources de ces controllers afin que cela corresponde à notre demande.
Pour monitorer notre application, Flagger se connecte à Prometheus afin de récupérer les metrics.
Flagger propose plusieurs modes de fonctionnement:
-
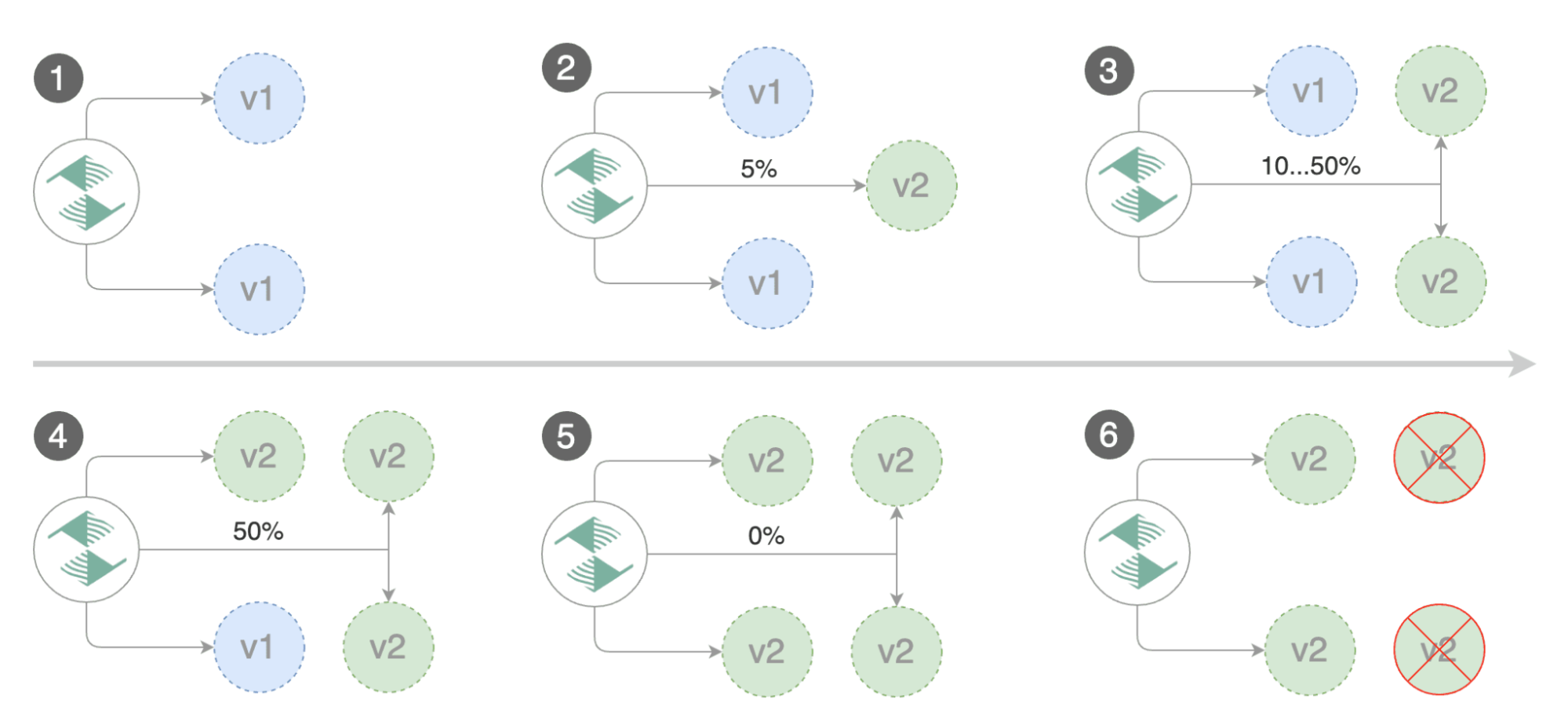
Canary Release (progressive traffic shifting)
Le but du canary release est de déployer une nouvelle version de notre application et de router le trafic réseau sur cette nouvelle version.
Flagger va mettre en place des poids (pourcentage réseau) sur les deux versions et changer au fur et à mesure les poids tout en contrôlant les erreurs.
-
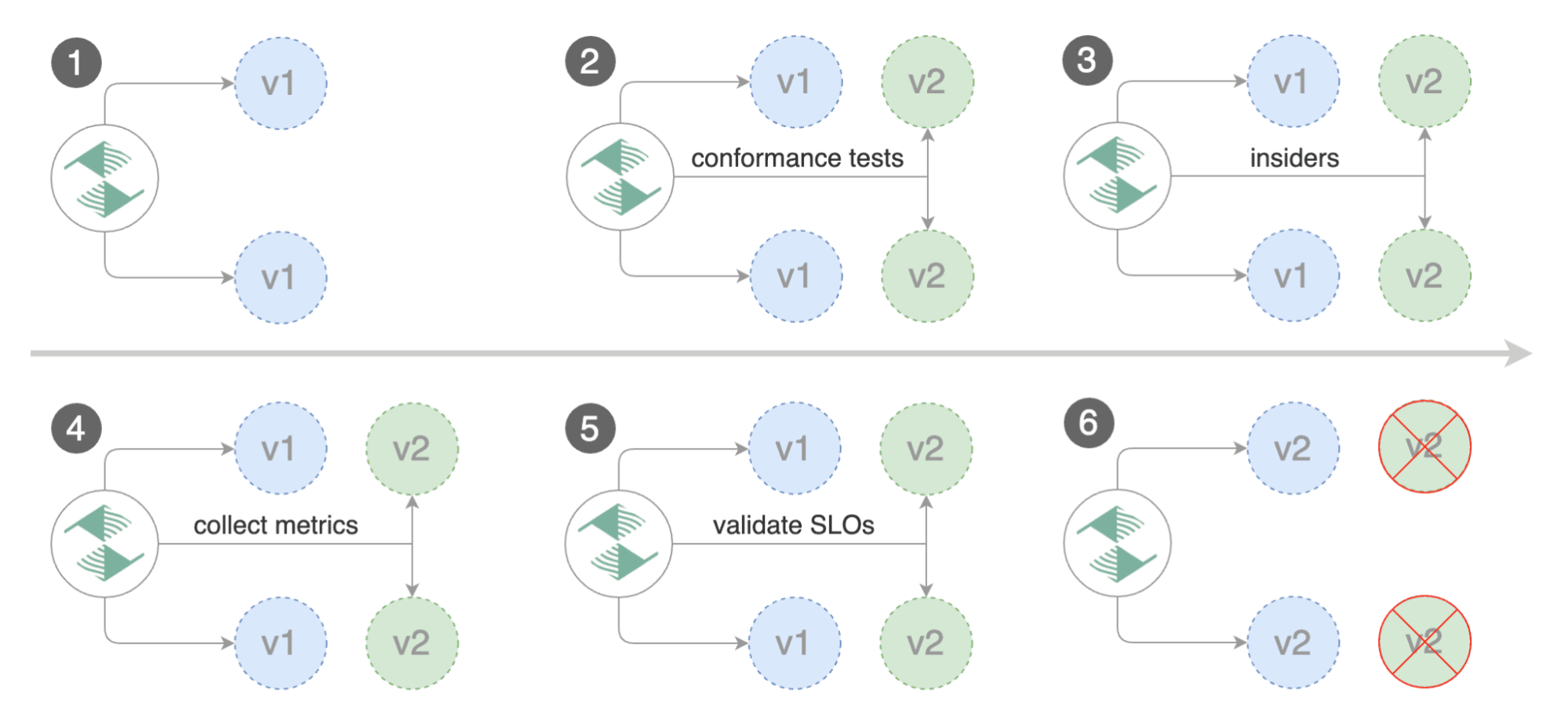
A/B Testing (HTTP headers and cookies traffic routing)
L’A/B testing consiste à comparer deux versions d’une page web ou d’une application. Une partie des utilisateurs sera alors dirigée vers la première version tandis que l’autre sera affectée à la seconde en fonction des en-têtes HTTP ou Cookie.
-
Blue/Green (traffic switching)
Le déploiement bleu/vert (en anglais « blue green deployment ») est une stratégie de gestion du changement pour la publication de code informatique. Pendant qu'un environnement est actif et sert les utilisateurs finaux, l'autre est inactif.
-
Blue/Green Mirroring (traffic shadowing)
Le déploiement bleu/vert mirroring est une stratégie qui consiste à dupliquer le trafic afin que les deux versions aient la même donnée en entrée.
En fonction du mode que l’on choisit, certains mesh controller peuvent ne pas être compatibles comme ici avec le mode Blue/Green Mirroring qui n’est supporté que par Istio.
Installation de Flagger
Dans cette partie, nous installons Flagger sur un cluster Kubernetes.
Pour cela, nous allons tout d’abord créer un namespace “flagger-system” et installer les CRD nécessaires :
$ kubectl create namespace flagger-system
$ kubectl apply -f https://raw.githubusercontent.com/fluxcd/flagger/main/artifacts/flagger/crd.yaml
Une fois l’installation des CRD (Custom Resource Definition) terminée, nous pouvons installer flagger via un chart helm. Nous allons dans un premier temps ajouter le repo Flagger
$ helm repo add flagger https://flagger.app
Une fois le repo ajouté, nous installons Flagger via la commande suivante:
$ helm upgrade -i flagger flagger/flagger --namespace=flagger-system --set meshProvider=istio --set metricsServer=http://prometheus:9090
Les deux paramètres les plus importants à renseigner sont le Mesh Provider qui permet de définir le provider utilisé et l’url de Prometheus afin que Flagger puisse monitorer l’application pendant son déploiement.
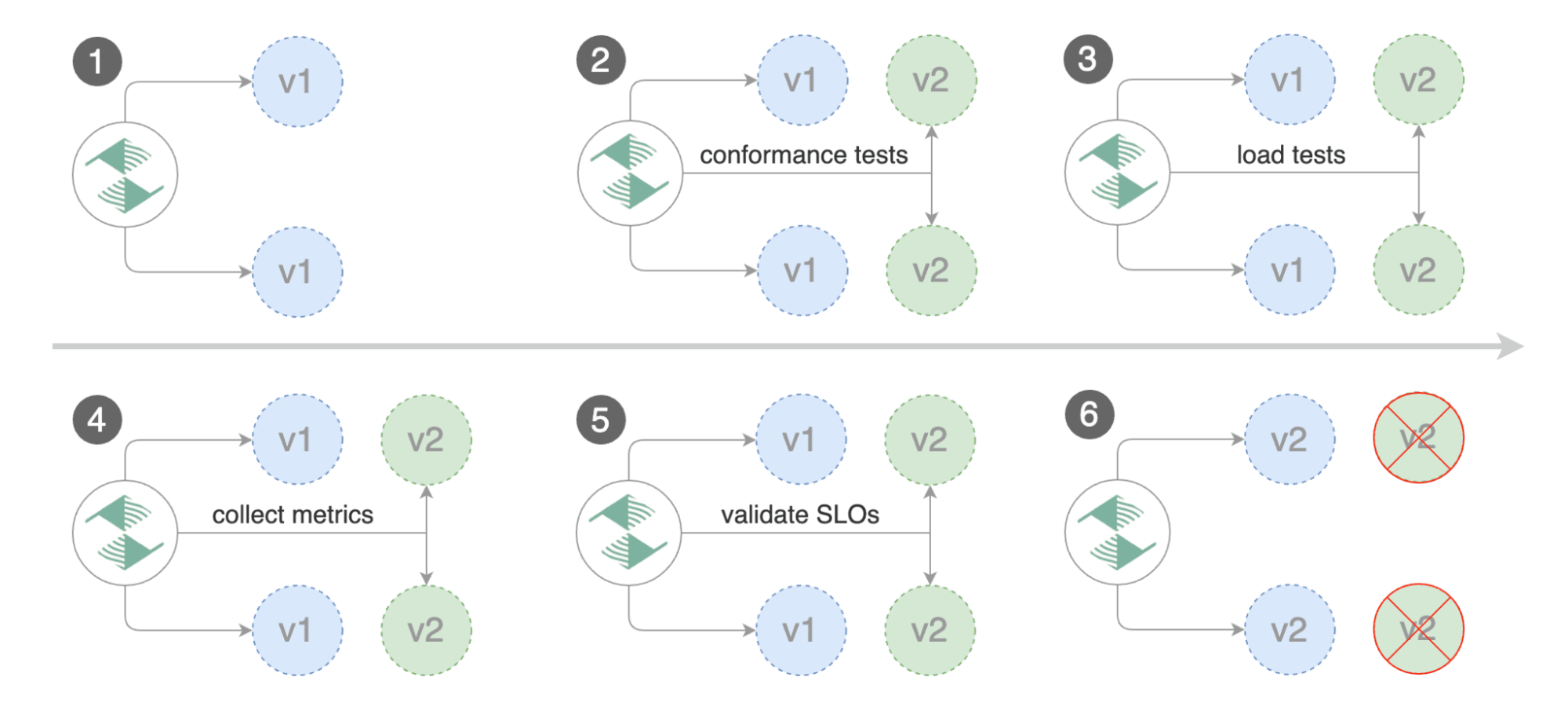
En option, nous pouvons installer un chart helm qui permet de faire des tests de charge via des api.
$ helm upgrade -i loadtester flagger/loadtester
👷♂️ Utilisation de Flagger
Flagger se base sur la ressource “Deployment” pour générer deux nouveaux deployment
- “Primary” qui correspond à la version stable
- “Canary” qui correspond à la version à tester
Pour configurer Flagger, nous utilisons une Ressource de type “Canary”
apiVersion: flagger.app/v1beta1
kind: Canary
metadata:
name: podinfo
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: podinfo
service:
port: 9898
analysis:
alerts:
- name: alert Discord
providerRef:
name: cnb
namespace: cnb
severity: info
interval: 1m
threshold: 10
maxWeight: 50
stepWeight: 5
metrics:
- name: request-success-rate
thresholdRange:
min: 99
interval: 1m
- name: request-duration
thresholdRange:
max: 500
interval: 1m
webhooks:
- name: load-test
url: http://flagger-loadtester.test/
metadata:
cmd: "hey -z 1m -q 10 -c 2 http://podinfo-canary.test:9898/"
Cette ressource se décompose en plusieurs parties afin de configurer au mieux Flagger:
La première partie “targetRef” consiste à définir la cible de notre canary:
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: podinfo
autoscalerRef:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
name: podinfo
Cette partie consiste à définir quel déploiement doit utiliser Flagger pour générer “Primary” et “Canary”
La deuxième partie “autoscalerRef” permet de sélectionner le HPA (horizontal pod autoscaling) à utiliser comme modèle pour générer les HPA de “Primary” et “Canary”
spec:
autoscalerRef:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
name: podinfo
La troisième partie “Service” permet de sélectionner le “Service” à utiliser comme modèle pour générer les services de Primary et Canary.
Attention en fonction du mesh-provider que vous avez choisi.
spec:
service:
name: podinfo
port: 9898
portName: http
appProtocol: http
targetPort: 9898
portDiscovery: true
La dernière partie “metrics” consiste à définir les metrics que Flagger doit surveiller lors du canary.
Elle permet de configurer:
- nos alertes (discord, slack, etc.)
- les intervals, maxWeight et stepWeight
- l’interval permet de définir le temps entre deux augmentations du trafic sur la nouvelle version.
- maxWeight permet de définir le poids à atteindre.
- stepWeight permet de définir l’augmentation du trafic réseau entre deux intervals
- les metrics à surveiller
- En option, un webhook à appeler à chaque interval
spec:
analysis:
alerts:
- name: alert Discord
providerRef:
name: cnb
namespace: cnb
severity: info
interval: 1m
maxWeight: 50
metrics:
- interval: 30s
name: request-success-rate
thresholdRange:
min: 99
- interval: 30s
name: request-duration
thresholdRange:
max: 500
stepWeight: 10
threshold: 5
webhooks:
- metadata:
cmd: "hey -z 1m -q 10 -c 2 http://podinfo-canary.test:9898/"
name: load-test
timeout: 5s
url: http://loadtester.flagger-system/
Exemple d’alerte reçue sur Discord
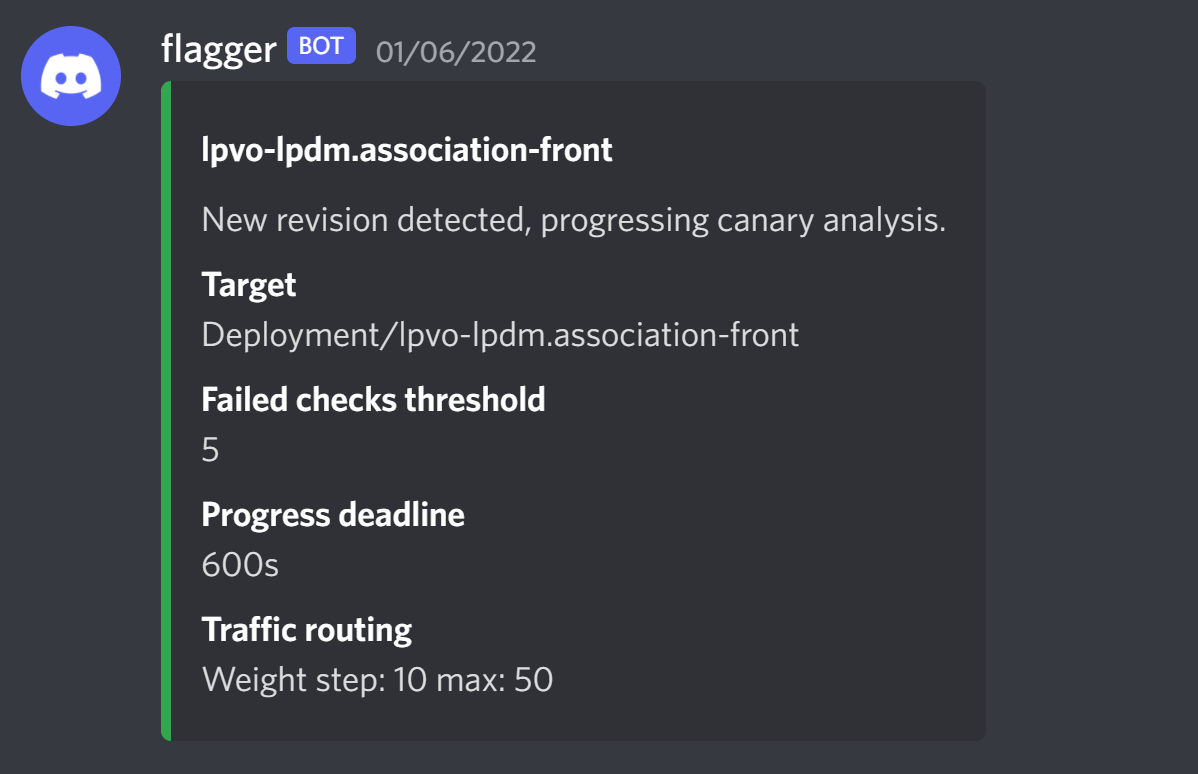
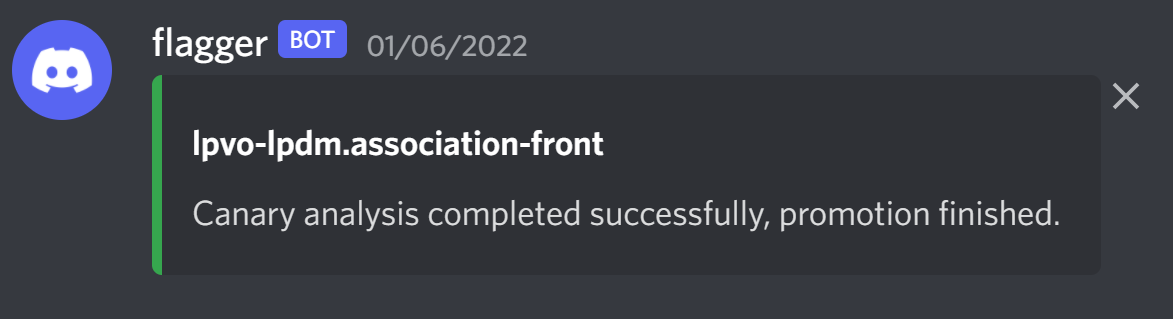
🧐 Conclusion
Dans cet article, nous avons vu comment utiliser l’outil Flagger pour déployer progressivement notre application.
Flagger va nous apporter des gains importants :
- Détection/Création automatique des changements sur le déploiement;
- Surveillance des metrics tout au long du déploiement;
- Rollback automatique si erreur détectée;
- Notification lors du démarrage, d’erreur et en cas de succès
Il faut cependant garder à l’esprit que Flagger a besoin de plusieurs dépendances pour qu'il puisse fonctionner correctement (Prometheus et un Mesh provider comme Istio).
