

Si parvenir à obtenir un modèle de ML fonctionnel sur sa machine est plutôt monnaie courante aujourd’hui, réussir à déployer automatiquement ce modèle en production est déjà beaucoup plus rare. Lors de sa conférence “MLOoops : comment faire échouer la mise en production du ML ?“ donnée au Salon de la Data 2022 à Nantes (voir cet autre article du blog Ippon), Paul Peton (Tech Lead IA Chez Avanade), dit à ce propos que 85% des projets de ML n’arrivent pas en production. L’industrialisation des modèles a donc encore du terrain à conquérir.
Figure 1 : Illustration du workflow MLOps, autre nom donné à l’industrialisation de l’IA
Source : https://blent.ai/le-metier-de-machine-learning-engineer/
Début 2022, lors de mon stage de fin d’études chez Ippon, j’ai dû réaliser avec d’autres stagiaires un chatbot sous la forme d’une application mobile. Destiné aux commerciaux et directeurs/directrices d’agence, ce chatbot est chargé de répondre à des questions concernant les compétences des collaborateurs d’Ippon. En tant que stagiaire data, je gérais la partie IA du chatbot. J’ai ainsi été amené à réaliser un modèle de classification de texte, utilisé pour déterminer, à la réception d’une question, quel type de question a été posé.
Pour réaliser ce modèle, j’ai d’abord utilisé la solution managée Comprehend (service NLP d’AWS). Toute cette épopée est d’ailleurs racontée dans mon premier article “Classifiez facilement du texte avec Comprehend”. Cependant, le coût de fonctionnement du chatbot était trop important avec cette solution (~1300$/mois). J’ai ainsi dans un second temps réalisé le modèle moi-même à l’aide d’un transfer learning sur le modèle de NLP français CamemBERT (voir mon second article “Mettez en place une classification de texte performante grâce à un CamemBERT”).
Dans ce troisième et dernier article de la série concernant la classification de texte, je vous propose donc de dresser un bilan en comparant les 2 stratégies de création de modèle que j’ai suivies afin de déterminer quelle solution est la meilleure. Nous confronterons les 2 approches selon 5 critères : le coût, la facilité de création du modèle, la facilité d’industrialisation, la rapidité d’inférence et les performances du modèle. Nous dresserons ainsi une matrice de décision qui pourra vous servir à faire le choix entre l’une ou l’autre des solutions.
Rappel du contexte et méthode de comparaison
Pour la suite de cet article, je supposerai que vous avez lu les 2 précédents articles de la série (article n°1, article n°2), mais voici un petit rappel. Le chatbot devant supporter 3 types de questions j’ai cherché à réaliser une classification à 3 classes :
- “Qui est + [nom d’une personne] ?” ⇒ classe WHO_IS
- “Qui s’y connaît en + [nom d’une technologie] ?” ⇒ classe WHO_KNOWS_ABOUT
- “Comment ça va ?” ⇒ classe HOW_ARE_YOU
À l’avenir d’autres types de questions pourront être ajoutés. Les données d’entraînement du modèle de classification sont, de ce fait, amenées à être modifiées, d’où la nécessité d’un déploiement du modèle en production le plus automatisé possible. Pour comparer la solution managée Comprehend à la solution basée sur le transfert learning de CamemBERT sur ce critère de la facilité d’industrialisation, j’attribuerai à chacune une note de 1 à 5 (5 étant la meilleure note). J’en ferai de même pour tous les autres critères (facilité de création du modèle, coût, performances, etc.).
Aussi, afin de prendre en compte le fait que certains critères sont plus importants que d’autres, un coefficient entre 1 et 5 sera attribué à chacun. Nous obtiendrons alors une matrice (voir figure 2) qui nous donnera, en faisant la somme pondérée des notes, la meilleure solution selon nos critères et nos pondérations.

Figure 2 : Matrice de décision servant à déterminer quelle solution est la meilleure
Pour le projet chatbot, le critère le plus important (coefficient 5) était celui de la rapidité d’inférence (le chatbot doit répondre aux questions quasi instantanément). La performance du modèle et le coût de la solution sont également 2 critères importants (coefficient 4). Si l’industrialisation du modèle est essentielle, le fait qu’elle soit facilement réalisable n’était pas spécialement primordial, ce qui explique le coefficient 2. Enfin, cette réflexion est aussi valable pour le dernier critère (facilité de création du modèle) qui a toutefois un peu plus d’importance (d’où le coefficient 3).
Lançons donc maintenant le match en commençant par une comparaison sur la facilité de création du modèle.
Comparaison n°1 : Facilité de création du modèle
Du point de vue de ce critère, Comprehend gagne le match puisqu’il gère toute cette partie de façon autonome. Il suffit effectivement de soumettre un dataset (respectant certaines contraintes) pour qu’un entraînement soit automatiquement lancé. Aucune connaissance en développement de modèles de ML n’est donc requise. Après l’entraînement, le modèle est enregistré dans Comprehend et des métriques permettant d’évaluer ses performances sont consultables notamment via l’interface AWS.
La tâche est en revanche bien plus ardue avec CamemBERT car il faut faire le transfer learning soit-même. Il est de ce fait nécessaire, contrairement à la solution d’AWS, de mettre les mains dans le code et de posséder des connaissances dans le domaine du Machine Learning et du NLP. Il y a toutefois moins d’efforts à fournir que si nous avions dû construire un modèle from scratch. De plus, cette étape peut être grandement facilitée grâce à l’utilisation de la librairie transformers d’Hugging Face (dont le fonctionnement et l’utilisation ont été décrits dans l’article n°2 “Mettez en place une classification de texte performante grâce à un CamemBERT”). J’ai cependant dû me former à cet outil et j’ai rencontré quelques problèmes lors du développement, d’où ma note de 2/5.
Facilité de création du modèle (coefficient 3)
Comprehend : 5/5 - CamemBERT : 2/5
Comparaison n°2 : Facilité d’industrialisation
Nous nous attaquons ici au plus gros point, même si dans le cadre du projet chatbot, puisqu’il ne s’agissait que d’un stage, l’industrialisation souhaitée était quelque peu allégée par rapport aux standards habituels. Nous ne voulions pas, par exemple, mettre en place de vérification des performances du modèle obtenu avant qu’il soit déployé et utilisé. Le gros du travail se concentrait donc sur l’automatisation des étapes permettant de déployer un modèle. Concrètement, nous souhaitions que lorsqu’un dataset au format JSON est déposé dans un bucket S3 (espace de stockage sur AWS), un entraînement soit automatiquement lancé puis qu’un endpoint soit créé sans la moindre action de notre part.
Voici donc quelques détails sur le travail que j’ai dû réaliser pour industrialiser le modèle selon ce fonctionnement dans chacun des deux cas.
Industrialisation avec Comprehend
Pour Comprehend, j’ai réalisé l’architecture suivante (voir figure 3). Elle se lit de gauche à droite et peut être expliquée par le workflow suivant :
- Lorsqu’un dataset JSON contenant les données d’entraînement (ne respectant pas les contraintes imposées par Comprehend) est déposé dans un bucket S3, une lambda function (start_training) est lancée.
- Cette lambda function va convertir le fichier JSON en un fichier CSV (déposé dans un bucket S3) respectant les contraintes exigées par Comprehend et lancer un entraînement sur ces données.
- Avant de finir son exécution, la lambda function start_training va lancer une step function (service d’automates à états finis d’AWS) chargée de vérifier toutes les 2 minutes grâce au lancement d’une lamba function (check_model_status) l’état de l'entraînement (est-il toujours en cours, terminé, en échec, ...).
- Lorsque Comprehend a terminé l’entraînement du modèle, des métriques (notamment la matrice de confusion) sont créées et permettent d’évaluer les performances du modèle obtenu.
- Lorsque la step function aura permis de détecter que l’entraînement s’est terminé avec succès, elle lancera une Lambda function (create_endpoint) chargée de créer un endpoint référençant le modèle récemment obtenu afin de le rendre disponible pour l’inférence.
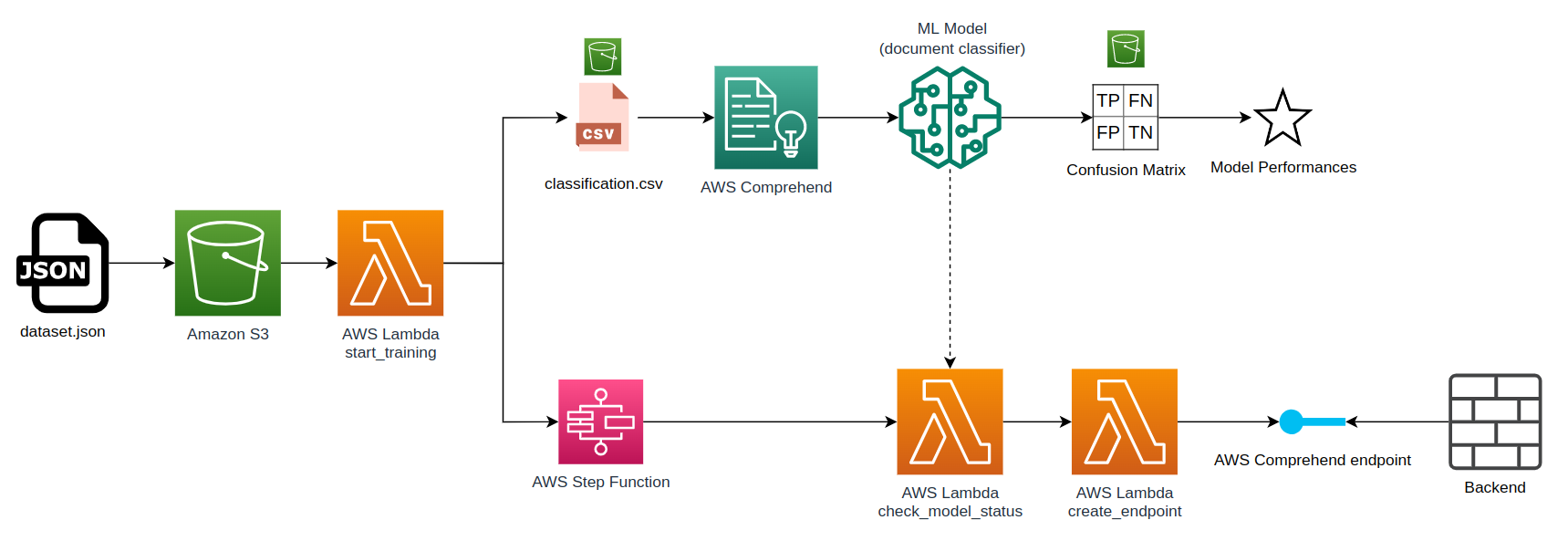
Figure 3 : Architecture mise en place pour industrialiser le modèle obtenu avec Comprehend
Le code des fonctions Lambda a été écrit en Python et l’ensemble des ressources AWS a été géré grâce à Terraform (outil d’Infrastructure as Code). Il s’agissait de ma première expérience de réalisation d’une architecture sur AWS, et la réalisation m’a paru plutôt accessible.
Pour information la durée totale du workflow entre le dépôt du fichier JSON et la fin de la création de l’endpoint est d’environ 30 à 35 minutes (environ 20 minutes pour l’entraînement et 15 minutes pour la création de l’endpoint).
Industrialisation avec CamemBERT
Pour CamemBERT, j’ai dû réaliser une architecture un peu différente en introduisant le service de Machine Learning de référence d’AWS : SageMaker. Ce service se décrit comme une solution permettant de “créer, entraîner et déployer rapidement et facilement des modèles de ML pour tous les cas d'utilisation avec une infrastructure, des outils et des flux entièrement gérés”. Notez qu'il n'est pas du tout obligatoire de passer AWS, ni même forcément nécessaire de passer par un cloud provider pour industrialiser le modèle. Il s'agissait cependant du cadre privilégié pour le stage.
Dans mon cas, j’avais déjà créé le script d’entraînement du modèle sur ma machine grâce à un transfer learning de CamemBERT réalisé à l’aide de la librairie transformers (voir mon précédent article). J’ai donc cherché à utiliser uniquement les fonctionnalités d'entraînement et de déploiement des modèles que propose SageMaker. Dans sa documentation, SageMaker explicite le workflow à suivre permettant de réaliser ces deux étapes grâce au schéma suivant (voir figure 4).
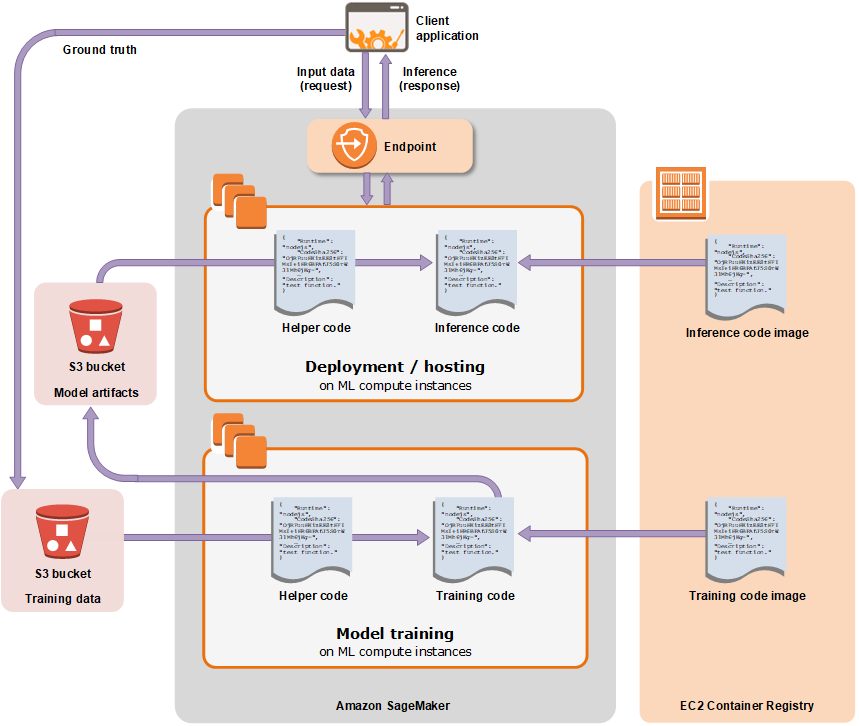
Figure 4 : Schéma représentant le workflow d’utilisation d’AWS SageMaker
Source : https://aws.amazon.com/es/blogs/aws-spanish/introduccion-a-sagemaker-studio/
Tout commence avec la brique rouge “Training Data” située en bas à gauche. Ces données vont être utilisées par SageMaker en complément d’une image Docker stockée sur AWS ECR (Elastic Container Registry) contenant le code d’entraînement du modèle. Le service pourra ainsi lancer l’entraînement sur le type d’instance d’entraînement de notre choix. À l’issue de l’entraînement, les informations du modèle (ou model artifacts : poids, métadonnées, etc.) seront déposées dans un bucket S3.
Il est alors possible de créer un endpoint, ressource qui sera le point d’entrée des demandes d’inférence. Lorsqu’une prédiction est demandée par un client, SageMaker charge le modèle et le code d’inférence (également stocké dans une image Docker présente sur ECR) sur le type d’instance d’inférence de notre choix. Le client à l’origine de la demande d’inférence reçoit alors une réponse de la part de l’endpoint.
J’ai donc très légèrement adapté ce workflow à notre cas d’utilisation et ajouté des Lambda functions pour faire le lien entre les différentes étapes, ce qui a donné l’architecture suivante (voir figure 5).
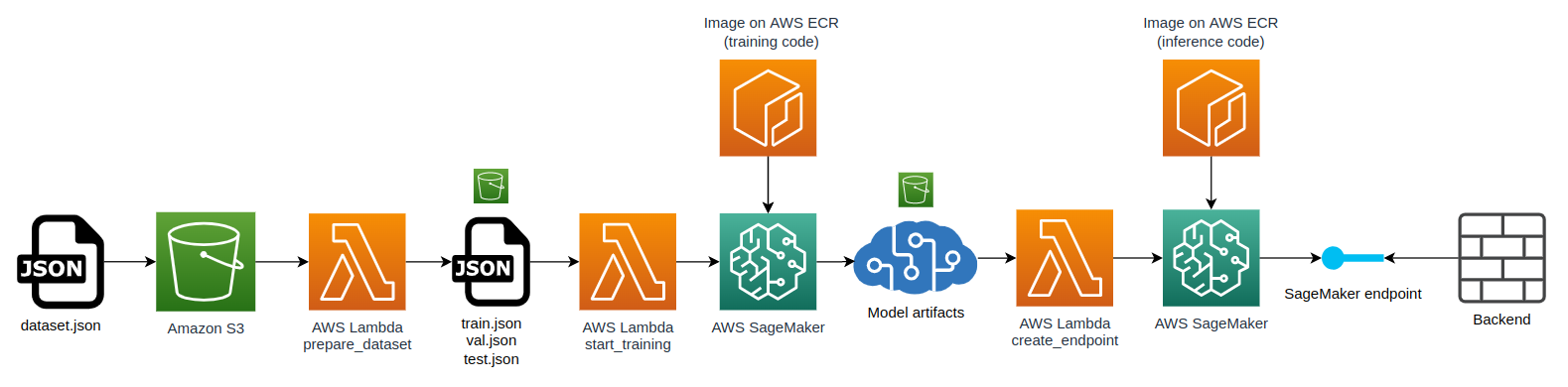
Figure 5 : Architecture mise en place pour industrialiser le modèle obtenu par transfer learning de CamemBERT
Comme pour l’architecture utilisant Comprehend, j’ai utilisé Python et Terraform. J’ai en revanche eu beaucoup plus de mal à réaliser cette solution pour 2 raisons :
- Je n’étais pas du tout familier avec la création d’images Docker et les concepts de conteneurisation. J’ai donc dû essuyer quelques plâtres avant d’arriver à mes fins.
- SageMaker est un service extrêmement vaste, complet et complexe que j’ai dû découvrir en partant de 0. Il y a beaucoup de vocabulaire à intégrer et l’on se perd rapidement dans la documentation. Aussi, il y a plusieurs façons de manipuler SageMaker : utiliser le SDK AWS traditionnel (boto3 dans mon cas), utiliser le SDK SageMaker censé nous extraire de la trop grande complexité des appels API de boto3, ou bien utiliser la solution SageMaker pipelines. Après avoir exploré les 3 pistes pour choisir selon moi la plus accessible, j’ai opté pour le SDK SageMaker. J’ai cependant rencontré plusieurs problèmes dans le développement de mes fonctions Lambda à cause de la taille de la librairie (trop lourde pour être attachée au zip de la lambda) et de bugs toujours existants comme cette erreur d’import.
Avec un peu de persévérance, j'ai finalement réussi à mettre en place cette architecture et faire fonctionner le workflow. Pour information la durée totale du workflow entre le dépôt du fichier JSON et la fin de la création de l’endpoint est d’environ 12 à 14 minutes (environ 6/7 minutes pour l’entraînement et 6 minutes pour la création de l’endpoint), soit près de 2 fois plus rapide que l’architecture précédente.
Sur ce second critère de facilité d’industrialisation, c’est donc à Comprehend que je donne l’avantage. Il est effectivement nettement plus simple d’industrialiser le modèle avec Comprehend (qui intègre déjà par nature une partie de cette industrialisation) plutôt qu’avec CamemBERT où tout est à faire.
Facilité d’industrialisation du modèle (coefficient 2)
Comprehend : 4/5 - CamemBERT : 2/5
Comparaison n°3 : Rapidité d’inférence
Concernant la rapidité d’inférence du modèle, j’ai testé les 2 solutions en leur soumettant 4 fois une série de 10 demandes de prédictions (en laissant 1 seconde entre chaque demande d’une même série). Pour le modèle obtenu avec Comprehend, j’ai pu observer un temps de réponse moyen de 106 ms (écart type de 64 ms) par prédiction. Pour le modèle obtenu avec CamemBERT et hébergé sur SageMaker, j’ai pu cette fois observer un temps de réponse moyen de 344 ms (écart type de 82 ms), soit plus de 3 fois plus long que Comprehend (mais ce résultat est tout de même satisfaisant pour notre cas d’utilisation).
Attention toutefois à la question du volume de demande à traiter sur une période de temps donnée. Dans notre cas d’utilisation, le chatbot devait recevoir un nombre très limité de questions (nous avons estimé ce nombre à maximum 10 par minute). C’est ainsi que nous avons décidé d’utiliser pour faire l’inférence du modèle basé sur CamemBERT une instance ml.t2.medium (la moins chère et moins performante des instances possibles sur SageMaker). Pour Comprehend, nous n’avons pas la main sur le type d’instance à utiliser pour l’inférence. Il est néanmoins possible de choisir le nombre d’unités d’inférence (UI) à attribuer à l’endpoint, qui correspond au nombre de caractères par seconde que ce dernier est capable de traiter. Nous avons choisi le nombre minimum d’UI (1) qui correspond à un débit de 100 caractères/s.
Les temps moyens donnés ci-dessus correspondent à un temps de réponse pour une requête envoyée seule lorsque le modèle n’est pas sollicité. Si les 10 phrases sont envoyées les unes à la suite des autres sans pause entre elles, les résultats sont différents. Pour Comprehend le temps moyen passe à 309 ms avec un écart type de 340 ms (le débit maximum de 1 UI est atteint, l'enpoint est saturé, certaines requêtes prennent alors plus d’une seconde). Pour CamemBERT, le temps de réponse reste stable avec un temps de réponse moyen de 345 ms (écart type de 85 ms).
Compte tenu de ces résultats très satisfaisants pour notre cas d’utilisation (réponse fournie quasi instantanément, même si les 10 questions sont posées les unes à la suite des autres), et du fait qu’il soit assez difficile de comparer directement et équitablement les 2 solutions (à cause du manque de transparence de Comprehend sur l’instance utilisée pour faire l’inférence) j’ai décidé de donner la note maximale aux 2 solutions.
Rapidité d’inférence (coefficient 5)
Comprehend : 5/5 - CamemBERT : 5/5
Comparaison n°4 : Performances
Du côté des performances des modèles les 2 solutions montrent de très bons résultats. Voici les matrices de confusions des modèles présentées dans chacun des 2 articles précédents. Pour rappel le dataset entier contient 390 exemples de phrases. Cependant, la répartition entre les splits de train, de validation et de test ne sont pas les mêmes pour les deux modèles (39 phrases dans le split de test pour Comprehend contre 59 pour CamemBERT).
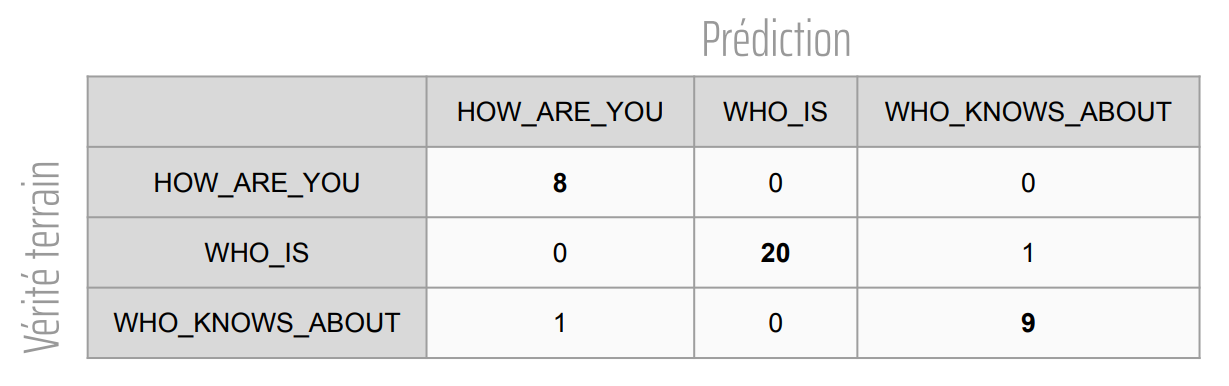
Figure 6 : Matrice de confusion du modèle obtenu avec Comprehend
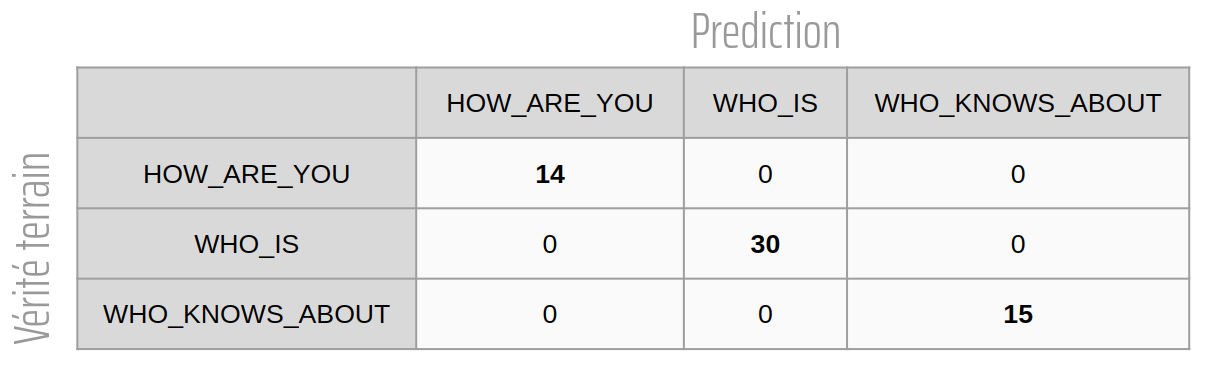
Figure 7 : Matrice de confusion du modèle obtenu par transfer learning de camemBERT
Avec ces matrices, on peut se dire que le modèle basé sur CamemBERT semble plus performant que le modèle obtenu avec Comprehend car il ne commet aucune erreur sur son split de test alors que le modèle Comprehend en fait 2 (et ce alors que le split de test du modèle Comprehend contient moins d’éléments). Il faudrait cependant répéter l’expérience de comparaison plusieurs fois en entraînant et testant les modèles sur les mêmes splits afin de pouvoir tirer de vraies conclusions scientifiques et non pas un simple début d’intuition.
Performances (coefficient 4)
Comprehend : 4/5 - CamemBERT : 5/5
Comparaison n°5 : Coût
Pour ce cinquième et dernier critère de comparaison, il aura fallu faire des recherches assez approfondies. Il n’était effectivement pas simple au début du projet d’estimer le coût d’utilisation des modèles, surtout pour Comprehend dont la tarification est assez complexe. Après m’être plongé dans la documentation de Comprehend et SageMaker j’ai pu obtenir ces estimations (voir figure 8).
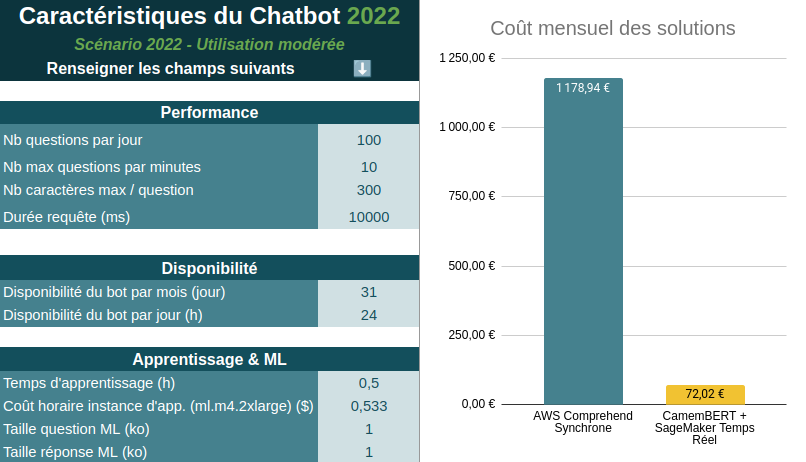
Figure 8 : Caractéristiques du chatbot et coûts mensuels associés pour les 2 solutions
La différence de coût est frappante. Le fonctionnement du chatbot 24h/24 et 7j/7 avec le mode synchrone (prédiction en temps réel) de Comprehend est extrêmement coûteux (presque 1200€/mois). Le mode asynchrone de Comprehend (présenté dans le premier article de cette série) serait beaucoup plus abordable (environ 39€/mois pour les mêmes critères) mais il n’est pas compatible avec notre cas d’utilisation. L’avantage est donc cette fois pour la solution utilisant CamemBERT, bien plus abordable à environ 72€/mois.
Pour information, SageMaker possède depuis avril 2022 un mode serverless extrêmement prometteur et très avantageux en termes de coût (à peine plus de 2€/mois pour les mêmes critères selon mes estimations). Cette piste n’a cependant pas été explorée, car le mode serverless était encore en version de test au début stage lancement du projet. De plus, le temps de cold start aurait pu être problématique dans notre cas d’utilisation.
Coût (coefficient 4)
Comprehend : 1/5 - CamemBERT : 4/5
Conclusion
Toutes ces comparaisons nous permettent donc de compléter la matrice de décision présentée au début de cet article, ce qui donne le résultat suivant (voir figure 9). L’addition de l’ensemble des notes pondérées donne la solution basée sur CamemBERT gagnante de ce grand match. Les résultats sont toutefois extrêmement serrés (68 vs 71) et la tendance pourrait tout à fait être différente selon vos propres critères, pondérations et compétences.

Figure 9 : Matrice de décision complétée
J’espère que cette série de 3 articles sur le sujet de la classification de texte vous aura plu et qu’elle vous aura permis d’en savoir plus sur la réalisation d’un projet nécessitant la création et l’industrialisation de ce type de modèle. Vous l’aurez compris, Comprehend et CamemBERT possèdent tous deux des avantages et inconvénients et le choix de l’une ou l’autre des solutions dépendra principalement de certains critères. Je vous conseille donc de vous poser les questions suivantes et de vous référer ensuite à la liste des avantages et inconvénients ci-dessous pour choisir la meilleure solution.
Questions importantes auxquelles répondre :
- Avez-vous besoin de prédiction en temps réel ? Si oui sur quelle période de temps ?
- Avez-vous des connaissances en Deep Learning ?
- Quel est votre budget mensuel pour l’utilisation du modèle ?
Comprehend : Avantages
- Service Comprehend de taille raisonnable ⇒ facile à prendre en main
- Pas de connaissances de ML nécessaires
- Bonnes performances
- Inférence rapide
- Industrialisation plutôt facile à réaliser
Comprehend : Inconvénients
- Coût en mode synchrone très élevé pour de longue période de disponibilité (~1300 $/mois)
- Effet boîte noire très important (input : dataset, output : modèle)
- Solution restreinte à l’écosystème AWS (pas possible de télécharger son modèle ou de l’héberger ailleurs que sur AWS)
CamemBERT + SageMaker : Avantages
- Bonnes performances
- Inférence rapide
- Leviers possibles sur l’apprentissage
- Coût abordable pour du temps réel sur de longues périodes
- Coût presque dérisoire en mode serverless
- SageMaker permet d’avoir la main sur l’hébergement du modèle (quelle instance utiliser, code de pré-traitement, …)
- Solution non restreinte à l’écosystème AWS (on peut remplacer SageMaker par d’autres solutions comme MLflow pour ne jamais recourir à AWS)
CamemBERT + SageMaker : Inconvénients
- Transfer Learning à faire soi-même (librairie transformers d’Hugging Face)
- Industrialisation plus complexe
- SageMaker pas simple à prendre en main (gros service AWS)
Voir les 2 autres articles de cette série :
