
Pour traiter ou valoriser des données textuelles, il est souvent nécessaire d’implémenter une classification automatique de texte. Pour ma part, j’ai été confronté à cette tâche sur un projet consistant à créer un chatbot, voué à être utilisé par les commerciaux et directeurs d’agence afin de répondre à des questions concernant les compétences des collaborateurs d’Ippon. Pour fournir des réponses adéquates, il était nécessaire de reconnaître automatiquement quel type de question était posé. Le chatbot devant supporter 3 types de questions (“Qui est + [nom d’une personne] ?”, “Qui s’y connaît en + [nom d’une technologie] ?” et “Comment ça va ?”), j’ai donc cherché à réaliser une classification à 3 classes (respectivement appelées WHO_IS, WHO_KNOWS_ABOUT et HOW_ARE_YOU).
Pour réaliser ce genre de modèle de Machine Learning deux options existent : utiliser une solution managée ou faire soi-même à l’aide d’un framework ML. Afin de concentrer mes efforts sur l’industrialisation du modèle, j’ai tout d’abord opté pour le premier choix. J’ai ainsi eu l’occasion d’utiliser Comprehend, un service de NLP d’AWS permettant, entre autres, de créer facilement des modèles de classification de texte personnalisée à partir d’un petit jeu de données. Toute cette épopée est d’ailleurs racontée dans mon précédent article “Classifiez facilement du texte avec Comprehend”. Si les performances étaient tout à fait satisfaisantes, le coût de l’utilisation du modèle en temps réel 24h/24 était en revanche trop élevé (1300$/mois). C’est pourquoi je me suis finalement tourné vers la seconde option : construire le modèle moi-même.
Dans cet article, je vous propose donc de découvrir comment créer un modèle de classification de texte performant avec peu de données grâce au transfer learning. Je commencerai par donner quelques rappels théoriques sur cette méthode d’apprentissage ainsi que sur le fonctionnement de la bibliothèque transformers d’Hugging Face ayant servi à la réalisation du transfer learning. J’aborderai ensuite, après cette partie théorique, le côté pratique à travers l'entraînement du modèle, son utilisation et les résultats obtenus.
Un peu de théorie
Qu’est ce que le Transfer Learning ?
Pour entraîner un modèle de Machine Learning de façon supervisée (comme le nécessite une classification de document), il faut des données annotées. Dans le cas d’un entraînement “from scratch” ce dataset doit être très important afin d’obtenir de bonnes performances. Cependant, on ne dispose bien souvent en réalité que de peu de données annotées, car soit peu de données sont à notre disposition, soit il serait trop fastidieux d’en annoter un très grand nombre.
Heureusement, avec le transfer learning, petit dataset et bonnes performances ne sont plus incompatibles. Le principe de ce mécanisme est assez simple : utiliser un modèle de Deep Learning (réseau de neurone) pré-entraîné, performant sur une tâche assez générique (différente de la nôtre), et le modifier très légèrement afin d’obtenir une sortie correspondant à notre besoin. Le tout sans faire perdre au modèle les “connaissances” qu’il avait acquises.
La phase de légère modification du modèle original s’appelle le fine-tuning. Cette étape se fait en 2 temps et est représentée sur la figure 1. Il faut premièrement modifier les dernières couches du modèle initial afin d’obtenir un format de sortie en adéquation avec notre tâche. Puis, il reste à entraîner ce modèle légèrement différent sur notre petit jeu de données (spécifique à notre tâche). Peu de données suffisent donc, car il n’y a qu’une petite partie du modèle à entraîner. De ce fait, l’entraînement sera également beaucoup plus rapide que celui du modèle initial et nécessitera ainsi moins de ressources de calcul.
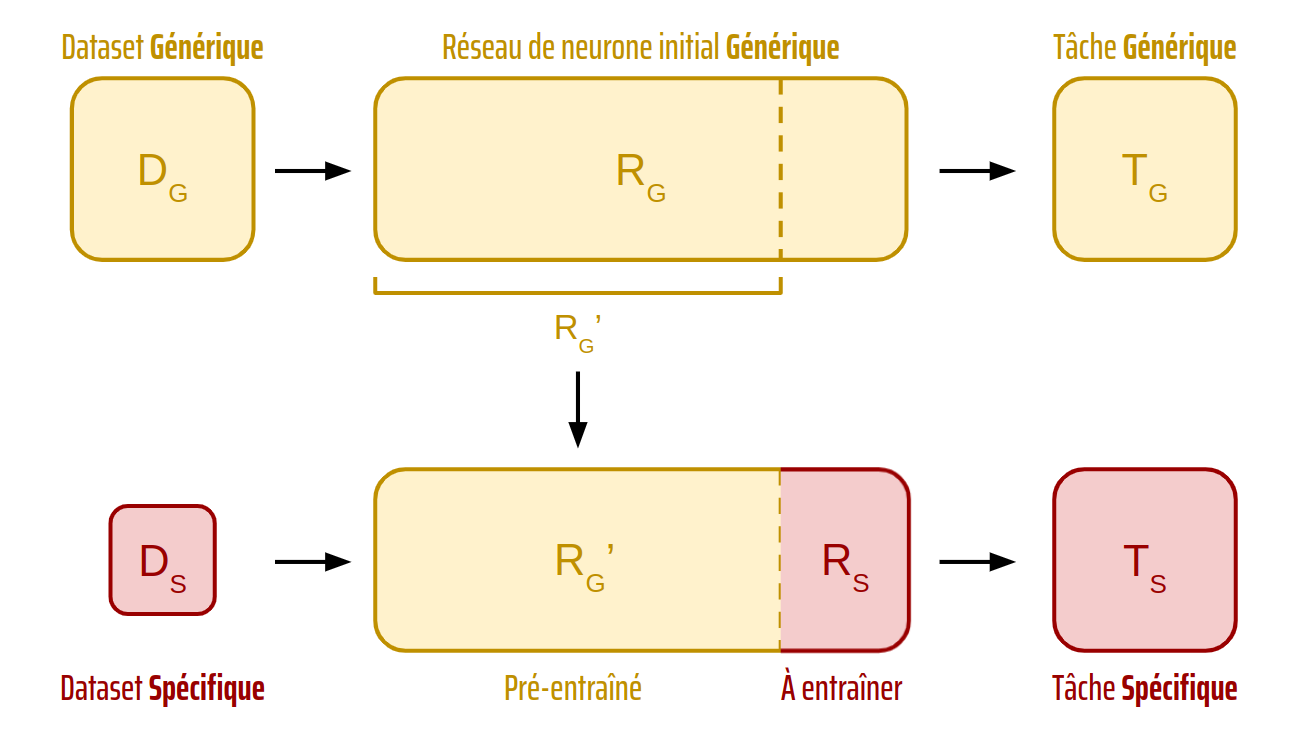
Figure 1 : Illustration du mécanisme de fine-tuning lors du transfer learning
Pour réaliser cette étape de fine-tuning, il est possible de faire les choses “à la main” en modifiant le modèle initial avec un framework de ML tel que PyTorch ou TensorFlow. Cependant, il existe des bibliothèques abstrayant ces manipulations assez fines grâce à des fonctions de plus haut niveau. C’est le cas de la bibliothèque open source Python transformers, créée en 2016 par l’entreprise Hugging Face, et permettant, entre autres, de fine-tuner des modèles de NLP.
En plus d’avoir créé cette bibliothèque, Hugging Face (HF) regroupe des centaines de modèles, parmi lesquels BERT (Bidirectional Encoder Representations from Transformers), un des modèles de NLP anglais les plus populaires. Ce dernier, basé sur l’architecture Transformers (architecture aujourd’hui à l’état de l’art dans le traitement du langage naturel et qui a inspiré HF pour le nom de sa bibliothèque) a été entraîné pour des tâches génériques sur un grand nombre de documents, lui permettant d’avoir en quelque sorte “appris à parler anglais”.
Les questions posées au chatbot étant en français, je me suis intéressé à 2 modèles de NLP français dérivés de BERT : CamemBERT et FlauBERT (cf. figure 2). Ces deux modèles publiés en 2020 possèdent des performances assez proches comme le suggère cet article (cf. partie 4, tableau 2). Mon choix s’est porté sur CamemBERT car contrairement à son homologue il possède dans HF un "Tokenizer Fast" (version améliorée du tokenizer, un outil que j’aborderai plus tard) nécessaire dans certains tutoriels de HF que je comptais suivre.

Figure 2 : Logos des technologies et modèles liés au transfert learning
Fonctionnement du fine-tuning avec transformers
Le principe de fonctionnement du fine-tuning avec transformers est relativement simple. Tout l'exotisme ne réside que dans la première étape qui consiste à définir une variable représentant le modèle que l’on souhaite fine-tuner. Cela se fera grâce à une méthode appelée from_pretrained. Cette méthode devra être appelée via une des classes de la bibliothèque transformers, classe à choisir selon 3 critères :
- le framework de ML que l’on souhaite utiliser pour paramétrer l’entraînement
- le modèle à fine-tuner
- le type de tâche sur laquelle fine-tuner le modèle
Dans mon cas, je souhaitais fine-tuner CamemBERT sur une tâche de classification de texte (appelée “SequenceClassification” dans transformers) en utilisant la syntaxe de TensorFlow (TF) avec laquelle je suis plus à l’aise que PyTorch. C’est pourquoi j’ai choisi la classe TFCamembertForSequenceClassification parmi celles décrites dans la documentation. L'instanciation se fait alors comme décrit dans l’extrait de code 1.
import transformers
model = transformers.TFCamembertForSequenceClassification.from_pretrained("camembert-base", config)
Extrait de code 1 : Initialisation du modèle
Comme vous pouvez le remarquer, il faut préciser en paramètre de la méthode from_pretrained deux arguments :
- L’id exact du modèle à utiliser, car il existe différentes versions de CamemBERT (modèles plus ou moins légers, avec des entraînements différents, etc.).
- La configuration à utiliser (contenant ici notamment le nombre de classes souhaitées en sortie du modèle) : c’est ce qui permettra à la bibliothèque de savoir comment modifier les dernières couches du modèle.
La suite du fine-tuning est tout ce qu’il y a de plus classique : définition des paramètres d’entraînement (loss, optimizer, métriques) compilation du modèle et lancement de l’entraînement (cf. l’extrait de code 2).
import tensorflow
loss = tensorflow.keras.losses.SparseCategoricalCrossentropy()
optimizer = tensorflow.keras.optimizers.Adam()
model.compile(
optimizer,
loss,
metrics=["accuracy"]
)
model.fit(
training_data,
validation_data,
epochs,
callbacks
)
Extrait de code 2 : Paramétrisation et lancement du fine-tuning.
Il est important de noter que les données d’entraînement et de validation (+ celles de test) doivent être pré-traitées avant d’être utilisées pour un entraînement. Pour les labels, une simple conversion des noms de classe en id suffira (WHO_IS : 0, WHO_KNOWS_ABOUT : 1 et HOW_ARE_YOU : 2). Pour les questions, une étape de tokenisation doit être faite afin de les transformer en valeurs numériques. Celle-ci consiste à utiliser un tokenizer pour découper le texte en morceaux (des tokens) recensés dans un dictionnaire propre au modèle initial. Chaque token est associé à un id, ce qui permet de convertir le texte initial en une suite de nombres (cf. figure 3). Certains tokens spéciaux sont automatiquement ajoutés lors de la tokenisation, comme au début et à la fin de la question (<s> et </s>). Ces derniers sont propres au modèle et servent à son bon fonctionnement.

Figure 3 : Exemple de tokenisation d’une question
Mise en pratique
Réalisation du fine-tuning
Si l’implémentation du fine-tuning m’avait l’air assez simple et concise, j’ai toutefois fait face à des difficultés pour pré-traiter les données (types des variables) et enregistrer le modèle. Je me suis alors tourné vers le dépôt github de transformers. Celui-ci contient un dossier regorgeant d’exemples de réalisation de fine-tuning pour différentes tâches en PyTorch ou TensorFlow. Parmi ceux-ci, l’exemple de classification de texte réalisée avec Tensorflow m’a particulièrement été utile. Ce script (assez long, environ 500 lignes, car très générique) permet de réaliser un fine-tuning du modèle de son choix sur une tâche de classification avec un dataset au format CSV ou JSON.
Avec ce script et un jeu de données de 390 exemples de questions pour le chatbot réparties entre train, validation et test (cf. figure 4) j’ai pu lancer un premier entraînement sur 50 epochs avec une taille de batch de 8. Les suivis de la loss et de l’accuracy sur ces 50 epochs sont représentés sur les figures 5 et 6. Concernant le temps d’entraînement, j’ai pu observer une durée d’approximativement 20 secondes par epochs soit environ 17 minutes pour les 50 epochs (avec un processeur i7 et 16 Go de RAM).

Figure 4 : Description des 3 splits du dataset
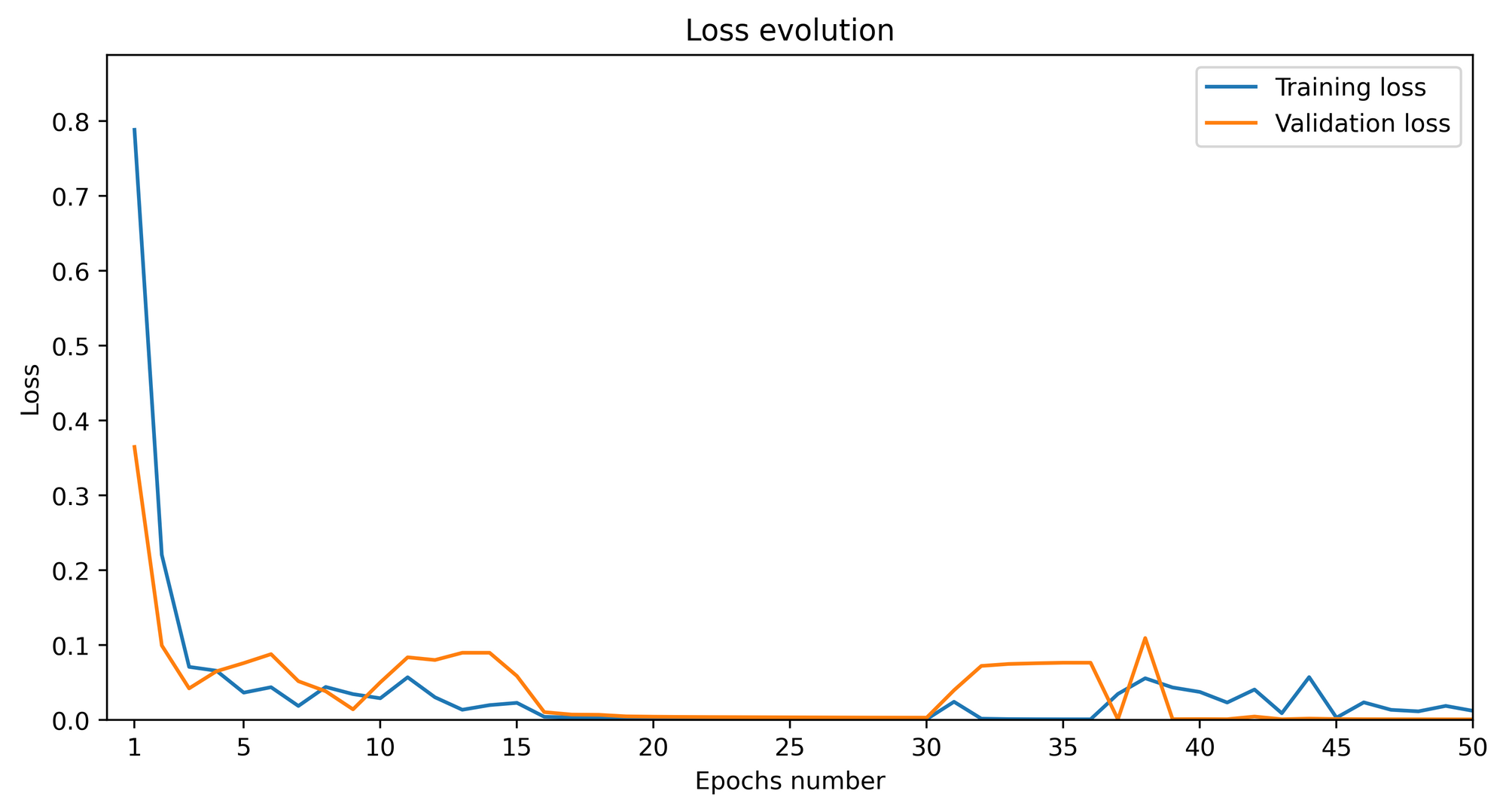
Figure 5 : Évolution de la loss selon le nombre d’epochs
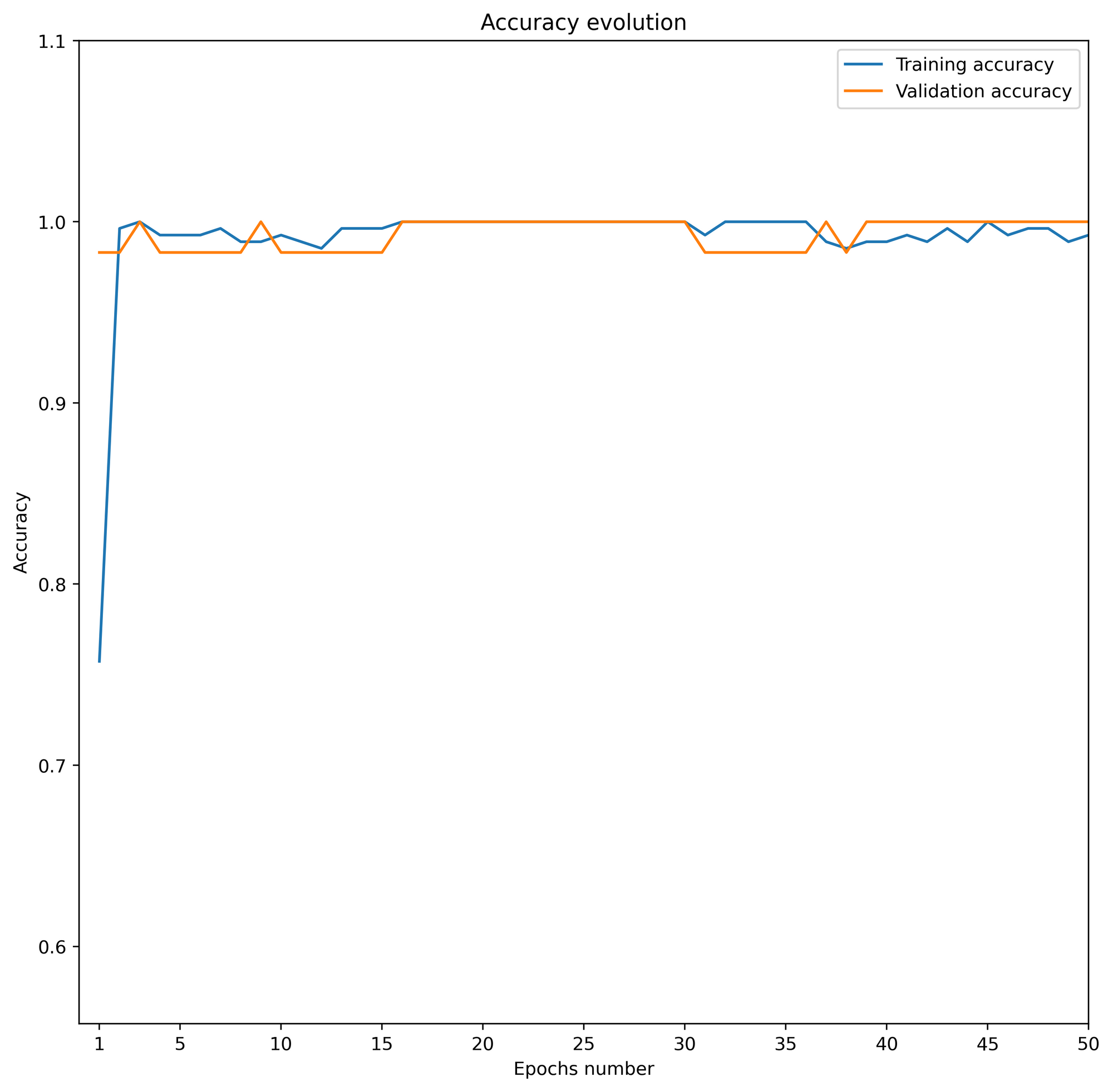
Figure 6 : Évolution de l’accuracy selon le nombre d’epochs
Ces courbes nous permettent de dire que les performances sont excellentes. En effet, la loss de validation diminue jusqu’à atteindre des valeurs très proches de zéro autour des epochs 20 à 30. Ce plateau se retrouve sur la courbe d’évolution de l’accuracy où celle-ci vaut alors 100%.
Suite à ces premiers résultats, un mécanisme d’early stopping à été mis en place pour arrêter l'entraînement lorsque le modèle ne s'améliore plus suffisamment (arrêt si diminution de la loss de validation inférieure à 0.01/epoch pendant 10 epochs). Avec ce mécanisme, l’entraînement s’est arrêté au bout de 20 epochs. La matrice de confusion du modèle obtenu est représentée sur la figure 7. Celle-ci nous permet de constater qu’aucune erreur n’a été commise par le modèle sur le split de test.
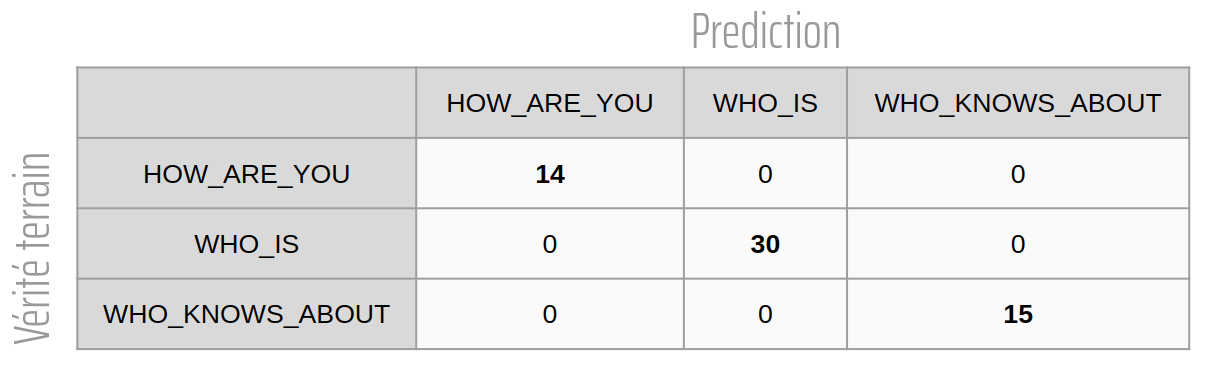
Figure 7 : Matrice de confusion du modèle obtenu
Obtention des prédictions
Après avoir sauvegardé le modèle entraîné avec model.save_pretrained(path_where_to_save), on peut l’utiliser pour obtenir des prédictions en procédant comme suit (cf. extrait de code 3).
# Load the model artifacts
model = TFCamembertForSequenceClassification.from_pretrained(path_to_model)
tokenizer = CamembertTokenizerFast.from_pretrained(path_to_model)
config = CamembertConfig.from_pretrained(path_to_model)
# Tokenize the input so that it can be processed by the model
tokenized_text = tokenizer(input_text, truncation=True, return_tensors='tf')
# Get predictions and transform raw output to probabilities
raw_output = model(tokenized_text)
logits = raw_output["logits"]
probabilities = tensorflow.nn.softmax(logits[0])
# Build the predictions to be returned
# Note : id2label is a dict mapping label ids (0,1,2) to actual label names ('WHO_IS', ...)
predictions = [{"Class": config.id2label[label_id],
"Probability": float(probabilities[label_id])}
for label_id in config.id2label.keys()]
return predictions
Extrait de code 3 : Chargement du modèle et prédictions
Le retour contenant les prédictions obtenues pour la phrase “Qui est-ce qui fait du nodejs ?” est le suivant :
[
{'Class': 'HOW_ARE_YOU', 'Probability': 0.0027706660330295563},
{'Class': 'WHO_IS', 'Probability': 0.0028453748673200607},
{'Class': 'WHO_KNOWS_ABOUT', 'Probability': 0.9943839311599731}
]
Prédiction obtenue après traitement
Conclusion
La bibliothèque transformers d’Hugging Face permet donc, entre autres, de créer des modèles de classification de texte grâce au mécanisme de transfer learning en fine-tunant des modèles comme CamemBERT, un modèle de NLP français. Le principe d’utilisation de la bibliothèque est relativement simple, mais j’ai rencontré quelques difficultés, que j’ai heureusement réussi à surmonter grâce au github huggingface/transformers contenant des exemples de fine-tuning pour différentes tâches (dont la classification de texte).
J’ai ainsi pu réussir à fine-tuner un modèle, qui plus est avec d’excellents résultats. Ce modèle obtenu après un entraînement d’environ 7 minutes (20 epochs) n’a effectivement commis aucune erreur sur le split de test contenant une soixantaine d’exemples. Il serait intéressant de voir si ces excellentes performances se vérifient également sur des problèmes plus complexes avec un nombre de classes plus élevé qu’ici (seulement 3 classes).
Ces performances sont à mettre en parallèle avec celles du modèle de classification de texte obtenu avec Comprehend (un service de NLP d’AWS) dont il est question dans mon précédent article “Classifiez du texte avec AWS Comprehend”. L’accuracy de ce modèle créé grâce au service d’AWS était de 94%, ce qui est légèrement en dessous des 100% du présent modèle obtenu par transfer learning. Sur d’autres aspects en revanche, je pourrai être tenté de donner l’avantage à Comprehend, notamment en ce qui concerne l’industrialisation du modèle.
Je proposerai dans un prochain article une comparaison selon différents critères (coût, facilité de mise en œuvre, etc.) des 2 solutions (Comprehend VS CamemBERT), en mettant l’accent sur le travail à réaliser pour industrialiser les modèles dans chacun des cas. Je dresserai ainsi une synthèse de mes différents essais et recherches en présentant et confrontant les avantages et inconvénients de chaque stratégie. Ce troisième et dernier article devrait donc pouvoir, je l’espère, vous éclairer dans le choix de l’une ou l’autre solution pour la création de vos futurs modèles de classification de texte.
Voir les 2 autres articles de cette série :
