

GraphQL est, comme son nom l’indique (QL = Query Language), un langage de requêtes de données pour API, fortement typé, disposant d’un environnement d’exécution permettant de traiter ces requêtes, le tout basé sur un modèle client-serveur.
C’est en 2012 que Facebook crée la première version du langage, qui passe ensuite en open-source en 2015. Plusieurs spécifications décrivant ses capacités et caractéristiques sont publiées, jusqu’à la dernière datant d’Octobre 2021. Une multitude d’implémentations de cette spécification dans de nombreux langages sont disponibles, que ce soit du côté client ou du côté serveur.
Aujourd’hui, on entend de plus en plus souvent parler de GraphQL comme LA solution alternative à REST. Mais est-ce vraiment la solution idéale ? Comment ce langage fonctionne-t-il ? Dans cet article, je présenterai ses principales fonctionnalités au travers d’Apollo, une des librairies implémentant GraphQL. Mais voyons d’abord la différence de fonctionnement avec REST.
Comparaison avec REST
En utilisant le formalisme de REST, le client doit se plier aux endpoints existants côté serveur pour récupérer les ressources dont il a besoin, et donc souvent appeler plusieurs endpoints pour récupérer la totalité des données (voir plus de données que nécessaire). Avec GraphQL, un seul appel est suffisant pour faire la même chose : le client effectuera cet unique appel au serveur GraphQL qui, lui, se chargera d’aller chercher toutes les ressources que la requête demande.
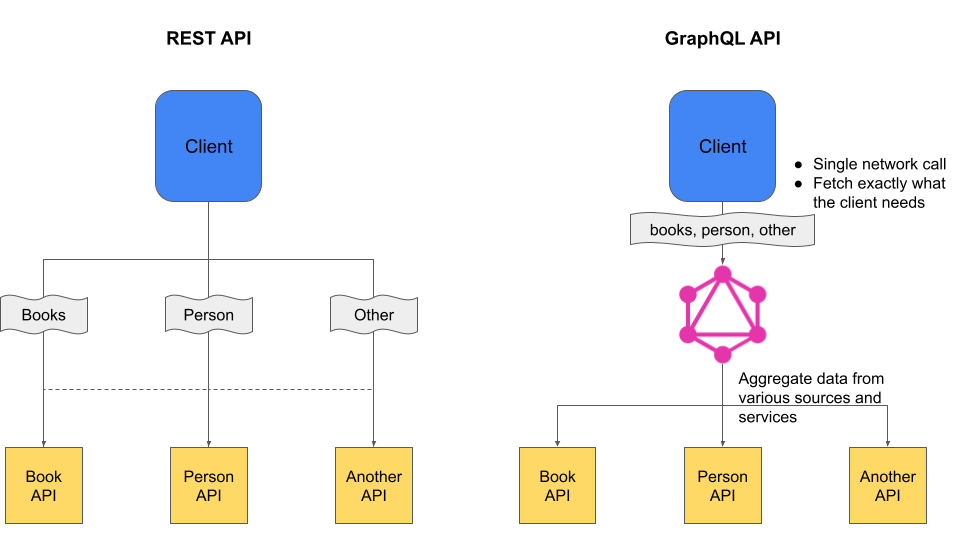
Grâce à GraphQL, on va pouvoir récupérer plusieurs ressources en une seule requête (pattern composite), ressources pouvant être stockées de différentes manières (API, BDD, fichiers, …). Ce fonctionnement permet de demander exactement ce que l’on veut, sans récupérer trop de données (over-fetching) ou pas assez (under-fetching). Cela se traduit également par des appels plus légers et rapides entre le client et le serveur.
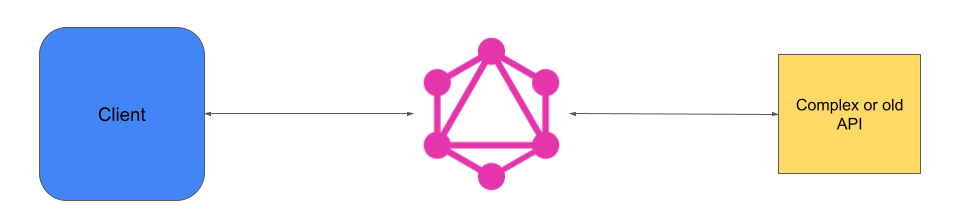
GraphQL peut également être utilisé dans d'autres circonstances. Par exemple, si l'on veut simplifier l'utilisation d'une api complexe, on peut ajouter une brique GraphQL entre le client et cette api (pattern facade). De la même manière, on peut inclure une couche graphQL pour enrichir une ancienne API avec une nouvelle fonctionnalité, par exemple une couche d'authentification (pattern proxy)
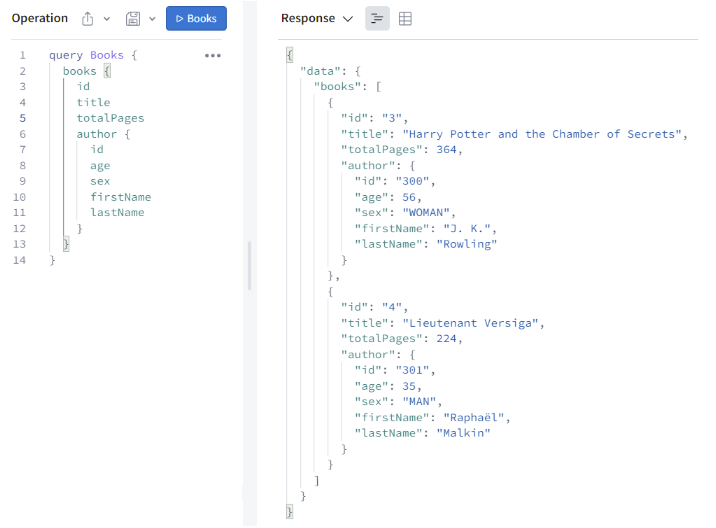
Voici à quoi ressemble concrètement une requête et une réponse du serveur GraphQL :
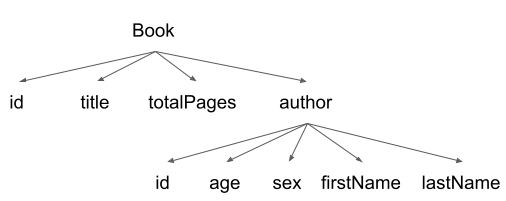
La réponse en sortie est au format JSON et représente un graphe d’objet, où les objets sont liés entre eux. Ces liens peuvent êtres représentés par le graphe suivant :
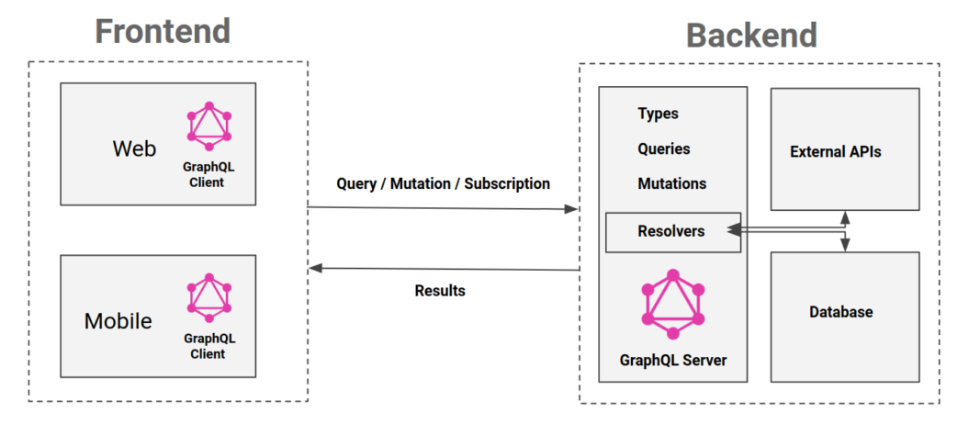
Ci-dessous un schéma récapitulant le fonctionnement de GraphQL avec ces mots-clés spécifiques, dont on verra l’utilisation dans la suite de cet article :
Interlude
Avant de continuer cet article, il est nécessaire d’avoir un aperçu des données sources sur lesquelles les exemples suivants vont se baser. J’appelle « données sources » toutes les données qui peuvent provenir d’APIs externes ou de bases de données. Nous utiliserons une liste de livres et de films qui font référence chacun à une personne via son identifiant (un auteur pour un livre, un réalisateur pour un film). Ces listes simulent la réponse d’APIs externes (API média et API personne par exemple).
const bookData = [
{
id: 3,
title: 'Harry Potter and the Chamber of Secrets',
author: 300,
totalPages: 364,
},
{
id: 4,
title: 'Lieutenant Versiga',
author: 301,
totalPages: 224,
}
]
const movieData = [
{
id: 100,
title: 'Titanic',
director : 10,
runTime: 160,
},
{
id: 101,
title: 'Forrest Gump',
director : 11,
runTime: 140,
}
]
const mediaData = [
...bookData,
...movieData
]
const authors = [
{
id: 300,
firstName: 'J. K.',
lastName: 'Rowling',
dateOfBirth: '1965-07-31T00:00:00.000Z',
sex: 'WOMAN'
},
{
id: 301,
firstName: 'Raphaël',
lastName: 'Malkin',
dateOfBirth: '1987-03-01T00:00:00.000Z',
sex: 'MAN'
},
]
const directors = [
{
id: 10,
firstName: 'James',
lastName: 'Cameron',
dateOfBirth: '1954-08-16T00:00:00.000Z'
},
{
id: 11,
firstName: 'Robert',
lastName: 'Zemeckis',
dateOfBirth: '1951-05-14T00:00:00.000Z'
},
]
const personData = [
...authors,
...directors
]Schéma
Le schéma est l’élément central dans GraphQL. C’est à cet endroit que l’on définit tous les objets et leurs types. Voici les différentes structures possibles :
- Scalar type
- Int
- Float
- String
- Boolean
- ID (une unique valeur sous forme de String, qui permet la gestion du cache)
- Object (Query, Mutation, Subscription)
- Input (permet de passer des objets complexes en paramètre des queries ou des mutations)
- Enum (définit un ensemble de valeurs possibles)
- Union (permet de définir plusieurs types de retour pour un objet)
- Interface (permet de partager un ensemble de champs entre plusieurs objets)
Voici comment on peut représenter nos objets métiers dans le schéma par rapport à nos données sources :
type Book {
id: ID!
title: String!
totalPages: Int
author: Person
}
type Person {
id: ID!
firstName: String
lastName: String
age: Int
sex: Sex
}
enum Sex {
MAN
WOMAN
OTHER
}C’est dans les schémas que l’on va pouvoir également ajouter des règles appelées type modifiers, comme le fait qu’un champ soit obligatoire via un point d'exclamation ou encore spécifier une liste. Voici les différentes combinaisons possibles avec le type String par exemple :
- String : chaîne de caractères pouvant être null
- String! : chaîne de caractères non null
- [String] : Liste pouvant être null, contenant des chaînes de caractères pouvant être null
- [String!] : Liste pouvant être null contenant des chaînes de caractères non null
- [String!]! : Liste non null contenant des chaînes de caractères non null. Une chaîne vide est valide.
Ces règles seront vérifiées par le serveur GraphQL et celui-ci renverra une erreur si elles ne sont pas respectées.
Enfin, GraphQL possède une fonction d’introspection, qui permet de demander au serveur de nous renvoyer son schéma. Cela permet au client d’avoir un descriptif de tous les objets présents sur le serveur et de toutes les opérations possibles avec les arguments associés. C’est donc une sorte de documentation automatique qui est renvoyée, qui permet au client de découvrir facilement les fonctionnalités disponibles.
Resolver
Une fois que GraphQL a vérifié la requête grâce à sa syntaxe et son schéma, les resolvers vont entrer en jeu. Un resolver permet d’associer à chaque champ du schéma une requête ou une action pour savoir la manière dont on va traiter ou récupérer les données.
const resolvers = {
Book: {
author(parent) {
return personData.find(a => a.id === parent.author)
}
},
Person: {
// Compute the person's age from date of birth
age(parent) {
var diff = Date.now() - new Date(parent.dateOfBirth).getTime();
var age = new Date(diff);
return Math.abs(age.getUTCFullYear() - 1970);
}
}
}Dans cet exemple, pour récupérer les données d’un auteur rattaché à un livre, on va chercher l’objet Person correspondant dans la liste personData grâce à son id.
Grâce aussi au resolver sur le champ age d’une personne, on va pouvoir transformer notre donnée en entrée (ex : 1987-03-01T00:00:00.000Z) afin qu’elle corresponde avec ce que l’on veut en sortie (l’âge de la personne, donc 35 ans dans notre cas).
On peut noter que les autres champs des objets Book (id, title, totalPages) ou Person (id, firstName, lastName, sex) n’ont pas de resolver. Ceci n’est pas une erreur. Il existe en effet des resolvers par défaut qui permettent de mapper automatiquement la donnée source qui possède le même nom que le champ qui est défini dans le schéma. Par exemple, le JSON source renvoie un champ title pour l’objet Book, et le schéma de l’objet Book possède un champ title, donc GraphQL est capable de faire le mapping tout seul. Cela correspondrait à écrire le resolver suivant :
Book: {
...
title(parent) {
return parent.title
}
},C’est aussi au niveau des resolvers que l’on va définir les opérations possibles que l’on peut envoyer au serveur : query, mutation et subscription.
Query
Une query permet de requêter le serveur GraphQL afin de récupérer un ensemble de données : c’est donc une opération de lecture des données. Le payload de retour est en JSON et plusieurs queries peuvent s’exécuter en parallèle. Ces queries sont définies dans le schéma et traitées dans le resolver.
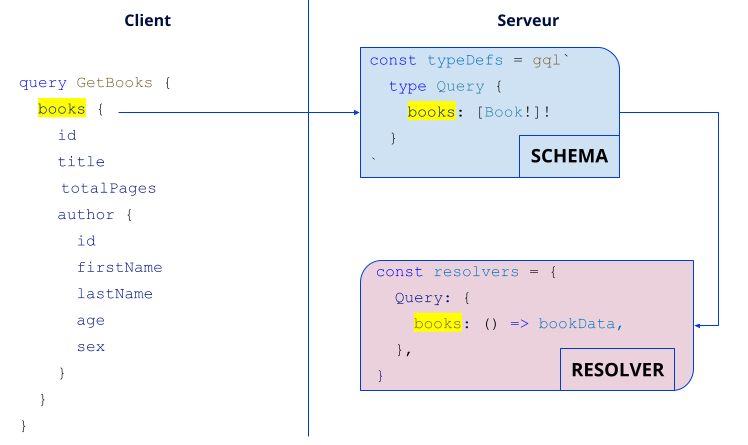
GraphQL arrive à faire le lien entre le client et le serveur via le nom de la méthode que l’on veut appeler (ici, books surligné en jaune). Une fois la requête reçue, le serveur va vérifier que celle-ci existe bien dans le schéma sous le type Query et qu’elle possède les bons paramètres et type de retour (ici, pas de paramètre mais une liste de Book en retour).
Puis, si la requête est valide, le serveur recherche dans le resolver la fonction associée sous le champ Query. Enfin, le resolver retourne les données et les réorganise pour que la réponse corresponde exactement aux champs de la requête, dans l’ordre demandé (ici, le resolver retourne directement bookData, qui correspond au JSON contenant les livres).
Interface
Les interfaces sont des types abstraits qui permettent de partager des champs entre différents objets. Chaque objet implémentant une interface doit au moins avoir les mêmes champs que celle-ci, et d’autres si nécessaire.
Si l’on reprend le schéma précédent avec le type Book, on pourrait imaginer ajouter un type Movie et une interface Media, de sorte à ce que Book et Movie partagent des champs communs (id et title) via l’implémentation de l’interface Media.
interface Media {
id: ID!
title: String!
}
type Book implements Media {
id: ID!
title: String!
totalPages: Int
author: Person
}
type Movie implements Media {
id: ID!
title: String!
runTime: Int
director: Person
}Il est également possible d’implémenter plusieurs interfaces via la syntaxe suivante :
type MyObject implements Interface1 & Interface2 {
…
}Imaginons maintenant que nous voulions récupérer tous les objets Media, en récupérant à la fois les champs communs et spécifiques des objets implémentant cette interface.
Comment le serveur s’y retrouve pour faire la différence entre un Book et un Movie ?
Il faut tout d’abord déclarer la query dans le schéma et écrire le resolver associé (comme pour la query books). C’est ensuite dans le resolver de l’objet Media que l’on va utiliser une fonction spéciale __resolveType fournie par apollo-server et qui va nous permettre de définir le type d’implémentation qui va être retourné, en fonction des champs disponibles dans l’objet : si l’objet possède un champ author, alors on renverra un Book; sinon, si l’objet possède un champ director, on renverra un Movie.
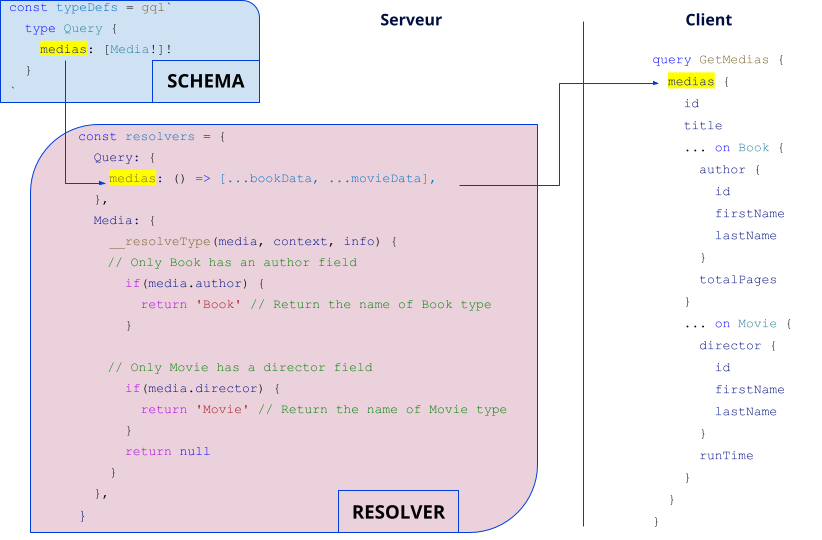
Enfin, la requête côté client utilisera la syntaxe … on Book ou … on Movie pour récupérer les champs propres à ces objets. Cette notation est appelée inline fragment.
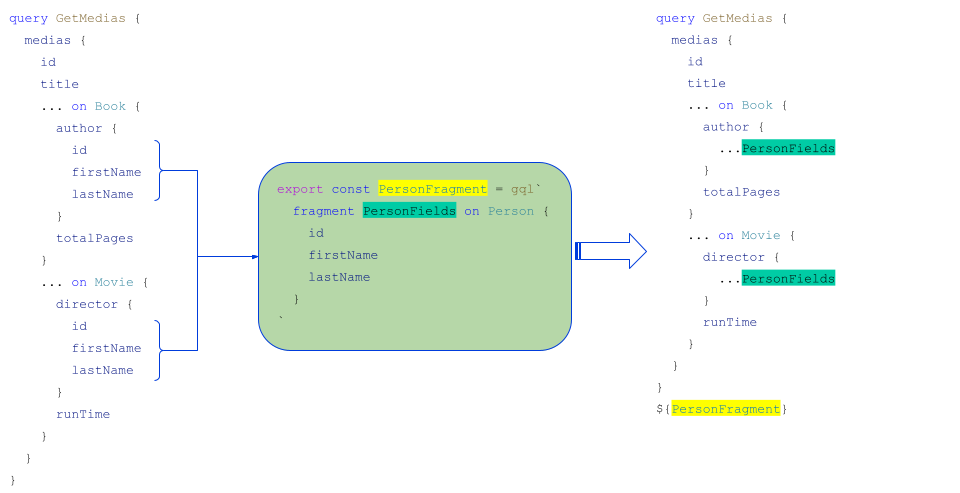
Fragments
En plus des inline fragments, il existe les fragments qui permettent de mutualiser des morceaux de requête côté client. Dans l’exemple précédent, les objets author et director possèdent les mêmes champs id, firstName et lastName. On pourrait donc les mutualiser dans un fragment PersonFragment sous la forme suivante :
Mutation
Les mutations concernent tous les changements apportés aux données : ajout, modification, suppression. Leur fonctionnement est similaire aux queries, avec la définition de la mutation dans le schéma (dans le type Mutation) et la fonction associée dans le resolver (dans l’objet Mutation). Elle peut également retourner un objet, ce qui peut être utile pour récupérer l’état de l’objet mis à jour par cette mutation. Cependant, contrairement aux queries, les mutations s’exécutent en série, l’une après l’autre.
Voici ce que donne un ajout de livre :
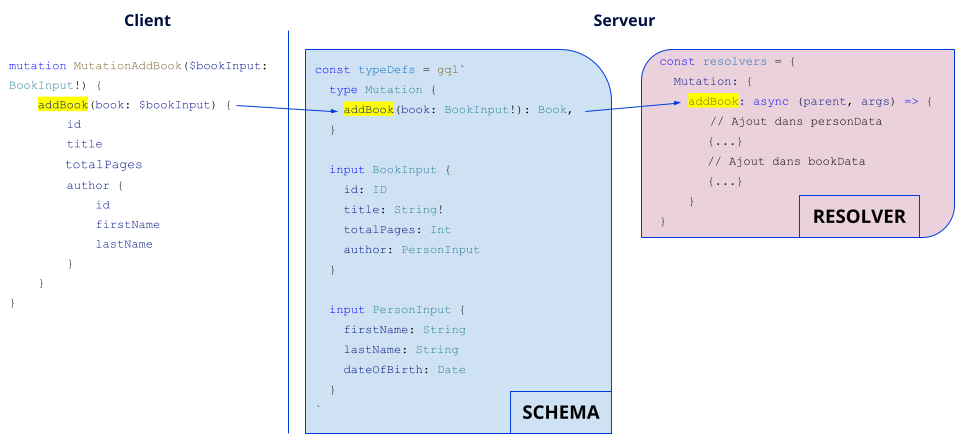
Comme dans l’exemple, on peut utiliser des objets de type input (BookInput et PersonInput), où chaque champ représente un argument, ce qui peut être pratique dans le cas où l’on veut modifier un objet complexe (au lieu de passer les champs un à un).
De la même manière, voici ce que donne une modification de livre :
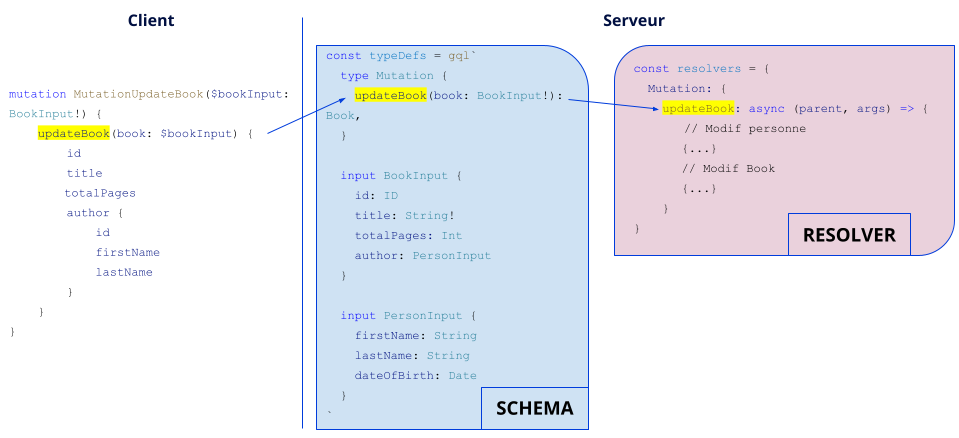
Subscription
Troisième grande famille d’opération possible, les subscriptions. Elles permettent de récupérer des données en réagissant à un événement après s’être abonné à celui-ci. Même si elles sont moins utilisées que les queries et mutations, elles peuvent servir pour être notifié en temps réel d’un changement des données côté serveur, comme par exemple l’arrivée d’un nouveau message sur une application de chat.
Si l’on reprend notre exemple, on pourrait ajouter l’utilisation d’une subscription dans un composant graphique MediasCounter qui irait s’abonner à l’événement d’ajout d’un livre pour ensuite incrémenter un compteur. Voici ce qui se passerait schématiquement :
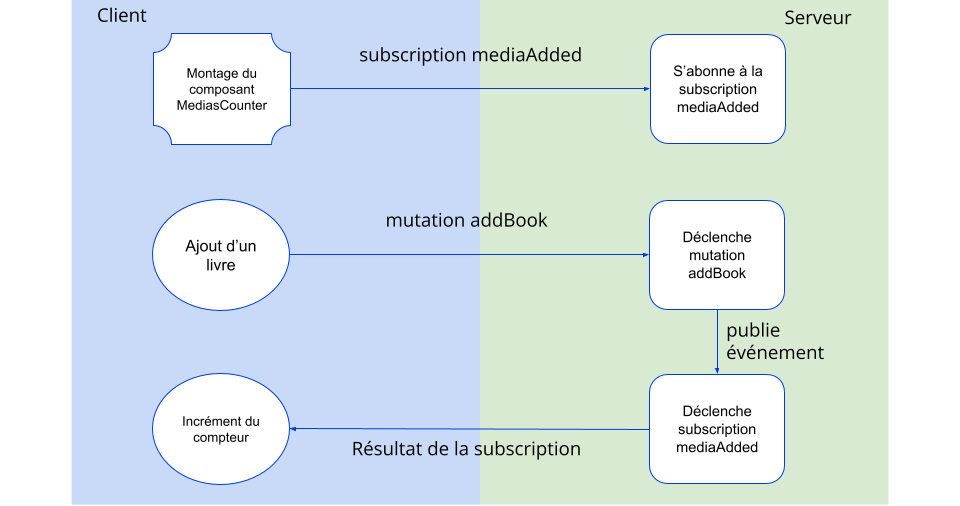
De la même manière que la définition des queries et des mutations, il est nécessaire de définir la subscription dans le type Subscription du schéma ainsi que la fonction associée dans le resolver, dans l’objet Subscription.
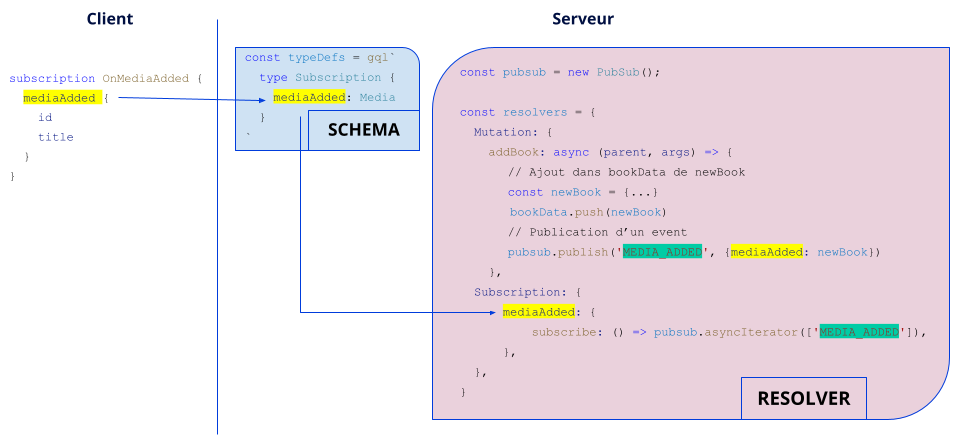
La différence notable avec les queries et mutations est l’utilisation d’un outil de publish/subscribe (ici PubSub via la librairie graphql-subscriptions) qui permet de s’abonner à un événement (pubsub.asyncIterator(['NOM_EVENT'])) et de publier un événement (pubsub.publish('NOM_EVENT', {mediaAdded: newBook})).
On ajoute donc la publication d’un événement MEDIA_ADDED dans la mutation addBook. Tous ceux s’étant abonnés à cet événement recevront donc une « notification » et pourront réagir à cet événement, comme notre composant MediasCounter en incrémentant un compteur d’ajout de livres.
Conclusion
Ainsi s’achève cette présentation de GraphQL. J’ai essayé d’aborder les fonctionnalités les plus importantes à travers des exemples de code pour permettre d’avoir un aperçu plus concret du fonctionnement de GraphQL.
Ce que l’on peut en retenir, c’est qu’il permet d’optimiser les requêtes entre le client et le serveur en demandant exactement les champs dont on a besoin, ce qui permet de réduire la taille de la trame réseau, idéal dans un contexte mobile par exemple. Un autre point important est qu’il permet d'agréger plusieurs sources de données, ce qui est utile dans un environnement complexe avec une multitude de microservices. Aussi, son système d’introspection permet au client d’aborder et de découvrir facilement l’API en auto-générant la documentation.
On notera cependant que la courbe d’apprentissage est difficile du fait des nouvelles notions et de la multiplicité des fichiers, que ce soit côté client que côté serveur.
Finalement, GraphQL est une bonne alternative à REST et est en train de prendre de plus en plus de place dans les architectures qui communiquent avec des APIs. Pour aller plus loin, d’autres points restent à aborder, comme la gestion du cache, la gestion des erreurs, le schema stitching ou encore les différents outils pour débugger.
Webographie
GraphQL | A query language for your API
