

Introduction
Qui n’a pas entendu parler des NFT en 2022 ? Véritable phénomène qui a explosé tous les records en 2021, les NFT sont pour certains une révolution, pour d’autres ce n’est qu’une mode. L’objectif de cet article n’est pas de vous convaincre de l’utilité ou non des NFT et encore moins de vous expliquer le fonctionnement intrinsèque de la technologie sous-jacente. Aujourd’hui nous allons nous concentrer sur les besoins des projets qui se développent autour de cet écosystème, en particulier les marketplaces de NFT.
Une marketplace de NFT a pour principe de mettre en relation des possesseurs de NFT souhaitant vendre leurs œuvres d’art numérique, ainsi que des acheteurs prêts à les acheter. Les achats et les ventes de NFT peuvent se faire dans différentes cryptomonnaies (majoritairement de l’Ethereum) et l’une des marketplace actuelle les plus connues est OpenSea. Mais toute marketplace qui se respecte se doit de fournir des informations à ses utilisateurs : données relatives au marché et à leur portefeuille de NFT, historiques de ventes, etc.
C’est ainsi que l’écosystème de la blockchain est amené à rencontrer celui de la Data. Une fois les données extraites de la blockchain, comment faire pour les ingérer de façon industrielle ? Comment en extraire de la valeur utile à ses clients ? Comment visualiser les indicateurs à mettre en avant ?
Vous l’avez sans doute compris, je vais vous expliquer comment au sein d’Ippon Technologies nous avons eu l’opportunité de développer une plateforme data analytics pour une marketplace de NFT.
Pour information, notre équipe était composée de 2 Data Ingénieurs (dont moi-même) à plein temps, ainsi que d’un expert Spark et Databricks et de 2 Data Architectes qui nous ont épaulé et supervisé durant tout le projet.
Et avant de commencer, petit instant d'auto-promotion ! Si vous êtes curieux de découvrir l’écosystème de la blockchain, des crypto-monnaies, de la finance décentralisée ou du Web 3.0, sachez que je crée du contenu très régulièrement sur YouTube où j’essaye de vulgariser au maximum tous ces sujets en vidéo.
Voici le lien de ma chaîne (à consulter après avoir lu l’article évidemment) : https://www.youtube.com/channel/UCjlxqqxeG5HtvKR5zX88Y1w
Et pour ceux qui souhaitent en discuter, je me ferais un plaisir d’échanger avec vous sur Twitter : https://twitter.com/0xcryptosaiyan?s=21&t=ppTDR4xW959Uk4wKSc4urg
Les besoins client
Je vous propose de démarrer notre histoire par un cahier des charges assez ambitieux. Notre client avait besoin de créer sa plateforme data avec un time to market très court de 6 semaines en partant d’une base vierge (from scratch comme disent nos amis anglo-saxons). C’est-à-dire qu’il n’y avait aucune base sur laquelle s’ancrer, seules les données extraites de la blockchain Ethereum étaient à disposition dans un bucket S3 sur AWS.
Il fallait qu’au terme des délais imposés la plateforme soit industrialisée et propose une intégration et un déploiement continus. L’équipe front-end du client devait être capable de venir se brancher directement sur nos données pour les exposer sur leurs tableaux de bord. Nous devions impérativement utiliser Python comme langage de programmation sur la logique métier car les développeurs internes à l’entreprise n’avaient ni la volonté ni le temps pour monter en compétence sur d’autres langages tels que Scala par exemple. De plus, le code de transformation qui nous a été fourni utilisait des bibliothèques Python pour lesquelles nous n’étions pas certains de pouvoir trouver une équivalence en Scala.
L’objectif était d’être capable d’ingérer toutes les 15 secondes (durée entre chaque bloc sur la blockchain Ethereum) les nouvelles transactions réalisées sur la blockchain, de les décoder, pour ensuite les agréger et être en mesure de répondre aux indicateurs de performance définis par le client. En termes de volumétrie, l’historique de la blockchain Ethereum (créée en 2015) représente environ 2 TB de données réparties en 3 tables. Cette volumétrie importante nous a contraint à faire des choix de technologies adaptées afin de répondre au mieux au besoin.
Mais au-delà du défi technique que suggère ces besoins, la logique métier n’est pas en reste car il fallait également développer toute la logique métier relative aux transactions sur la blockchain ainsi qu’au fonctionnement des NFT. Cela a demandé beaucoup d’efforts à notre équipe pour intégrer tous ces principes relativement nouveaux et complexes.
Les solutions mises en place
Databricks, la brick manquante des projets Spark
Étant donné la haute volumétrie de données à manipuler, la complexité des transformations (sans UDF - User Defined Functions - le décodage des données on-chain aurait été impossible) ainsi que les besoins de performance et de scalabilité exprimés par le client, le choix du framework de développement Spark fut évident.
Mais Spark ne peut pas répondre à tous nos besoins, c’est comme un joueur de football qui essayerait de gagner la Ligue des Champions sans équipe : seul c’est impossible (demandez à Mbappé…). C’est donc pour cela que nous avons choisi d’utiliser Databricks pour construire notre plateforme Data.
Databricks est une solution complète permettant de créer une plateforme Data hébergée dans le cloud. Notre choix s’est fait selon les différentes contraintes et attentes du client, et Databricks répond à tous ces critères. Voici une liste des principales raisons pour lesquelles nous avons choisi Databricks :
- Une intégration très simple avec Github et AWS ;
- Des performances et une scalabilité répondant à notre besoin grâce à Spark ;
- La possibilité de créer des jobs en PySpark via des wheel Python ;
- Une haute volumétrie de données simple à manipuler grâce aux Delta Tables ;
- L’exposition de endpoints SQL pointant directement sur les Delta Tables ;
- L’intégration de tableaux de bord de visualisation des données et de monitoring sans besoin d’utiliser un outil externe ;
- Une simplicité d’utilisation et une prise en main accessible et facile à transmettre.
Rome ne s’est pas faite en un jour, notre plateforme non plus
En introduction, nous avons insisté sur l’ambition du projet et ses délais très courts. C’est pour cela qu’il a été convenu de démarrer le projet par un PoC (Proof Of Concept, ou Preuve de concept en français mais c’est beaucoup moins sexy) d’une semaine afin de valider la faisabilité de celui-ci.
L’objectif du POC était de réaliser un petit pipeline d’ingestion de données on-chain (c’est-à-dire de données extraites de la blockchain), d’implémenter un décodage des transactions, de créer une table agrégée et d’exposer un tableau de bord. Nous avons commencé par définir une architecture sur 3 niveaux à nos tables :
- Bronze pour la donnée brute.
- Silver pour la donnée filtrée et nettoyée correspondant aux données opérationnelles de la marketplace venant alimenter le front-end.
- Gold pour la donnée agrégée et enrichie sur laquelle le front-end vient également récupérer les données.
Les premières phases de développement furent facilitées par l’utilisation des Notebooks partagés mis à disposition par Databricks. Ainsi, tous les membres de l’équipe pouvaient collaborer ensemble sur un même Notebook partagé ou développer de leur côté sur le leur. Sans oublier l’interface Databricks SQL qui nous a permis de créer très simplement un tableau de bord complet regroupant les graphiques et indicateurs répondant au besoin du POC.
Merci qui ? Merci Auto Loader !
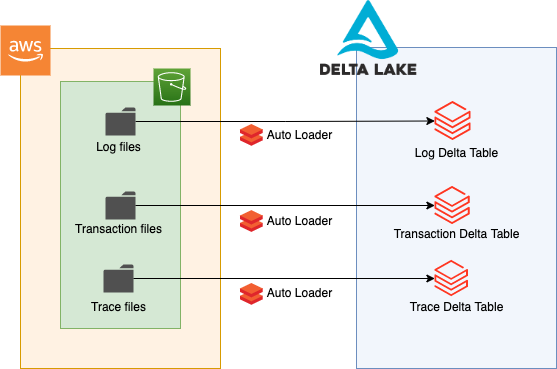
Nous avons commencé par l’ingestion du bronze, et pour ce faire nous avions besoin de mettre en place une mécanique de streaming pour ingérer la donnée brute dans une Delta Table. Pour rappel, les données extraites de la blockchain Ethereum sont déposées toutes les 15 secondes dans 3 buckets S3 sous forme de fichiers Parquet. Nous avions 3 types de fichier à traiter : des fichiers de logs, de transactions et de traces. Inutile de rentrer dans les détails du contenu de ces fichiers mais l’important est de comprendre que chaque table bronze devait être branchée en streaming sur le bucket correspondant.
Le choix de stocker les données bronze dans des tables Delta (en plus de S3 déjà en place) était motivé par la nécessité de les pérenniser et de les compacter sans interrompre les flux afin de pouvoir les traiter à nouveau plus facilement à tout moment.
La solution Auto Loader proposée par Databricks était le choix parfait pour répondre à ce besoin. Elle permet d’ingérer des fichiers en continu depuis un espace de stockage objet dans le Cloud via un job Spark Streaming extrêmement simple. Nos fichiers étant stockés dans des buckets S3 et au format Parquet, nous avons choisi de créer 3 jobs permettant l’ingestion de ces fichiers dans nos 3 Delta Tables.
🎶 Nettoyer, balayer, astiquer… 🎶 Mais surtout FILTRER !
N’oublions pas que notre cœur de métier est les NFT, or sur la blockchain des millions de transactions sont effectuées et toutes ne sont pas relatives aux NFT. On peut par exemple échanger des crypto-monnaies comme de l’ETH ou déclencher des smart-contracts via une transaction. Il faut donc filtrer nos transactions et en extraire seulement l’information qui nous intéresse, c’est-à-dire les transactions correspondant aux transferts, aux achats et aux ventes de NFT.
Nous avons eu la chance que le client possède déjà un code en Python et en Pandas implémentant la logique permettant de décoder les transactions. Or, la difficulté pour nous fut de traduire cette logique métier complexe en PySpark afin de pouvoir distribuer les transformations et profiter pleinement de la puissance de Spark. Nous avons été contraints d’utiliser des UDF (User Defined Function) pour implémenter certaines logiques impossibles à traduire en PySpark directement.
Pourquoi vous n’avez pas juste utilisé Koalas ? - demanderiez-vous. Et bien, nous avons bien essayé et cela fut un échec total ! Le code jonglait en permanence entre les DataFrames Pandas et les listes Python, il était donc impossible à déboguer et absolument pas optimisé pour Spark. Nous n’avons jamais réussi à le faire tourner en Koalas malheureusement.
Une fois le code traduit et prêt à être implémenté, nous devions mettre en place une mécanique permettant de traiter en streaming les données stockées dans nos tables Bronze et d’effectuer « à la volée » les transformations nécessaires. Deux mécaniques ont été mises en place : une première permettant de traiter toutes les données historiques d’un coup via un unique batch et d’écraser les données dans la table Silver et une deuxième faisant appel à l’API de Spark Streaming, permettant pour chaque nouveau fichier ingéré dans une table bronze d’effectuer les transformations et d’insérer (en mode « append ») les données dans la table Silver en streaming.
Une fois la mécanique bien rodée, nous avons pris le soin de stocker les checkpoints des différents streams mis en place dans des buckets S3 afin d’être en mesure de reprendre l’ingestion des fichiers là où elle s’est arrêtée en cas d’arrêt de celle-ci. La localisation des checkpoints se définit à la création des tables, il suffit d’ajouter le chemin absolu vers un bucket S3 et les checkpoints y seront stockés.
La ruée vers l'or
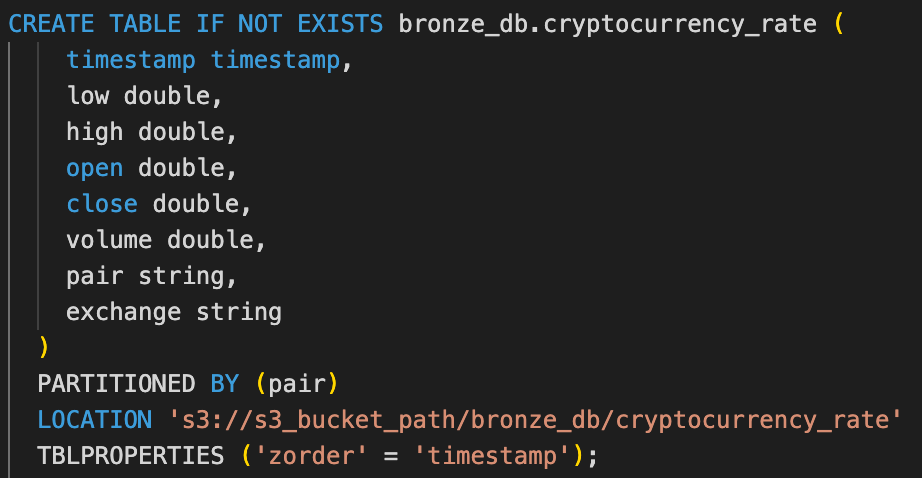
Le niveau Silver étant prêt, il nous restait à construire les logiques d’agrégation et d’enrichissement de nos Dataframes nécessaires pour nos tables Gold. Le périmètre du POC ne s'étendait qu’à une seule table Gold. Sa logique voulait qu’on agrège les données issues des transactions en Silver et qu’on vienne les joindre à des fichiers JSON plats, eux-mêmes stockés dans un bucket S3. Ici, pas besoin d’Auto Loader pour ingérer les fichiers JSON, ceux-ci étant statiques et très peu volumineux, nous pouvions nous permettre de les ingérer une seule fois dans une table Bronze sans job complexe associé.
Nous avons repris le même pattern d’ingestion que celle du Bronze vers le Silver, c’est-à-dire que nous avons utilisé Spark Streaming pour transformer les données dès qu’une nouvelle donnée était ajoutée au niveau Silver, mais également un job pour traiter à nouveau toute la donnée historique et écraser le contenu de la table. Nous avons également pris soin de gérer les checkpoints de chacun des streams au cas où ils s'arrêteraient subitement. Bien que l’interface proposée par Databricks permettant de visualiser le contenu des tables soit assez intuitive, son contenu n’en demeure pas moins abstrait et limité.
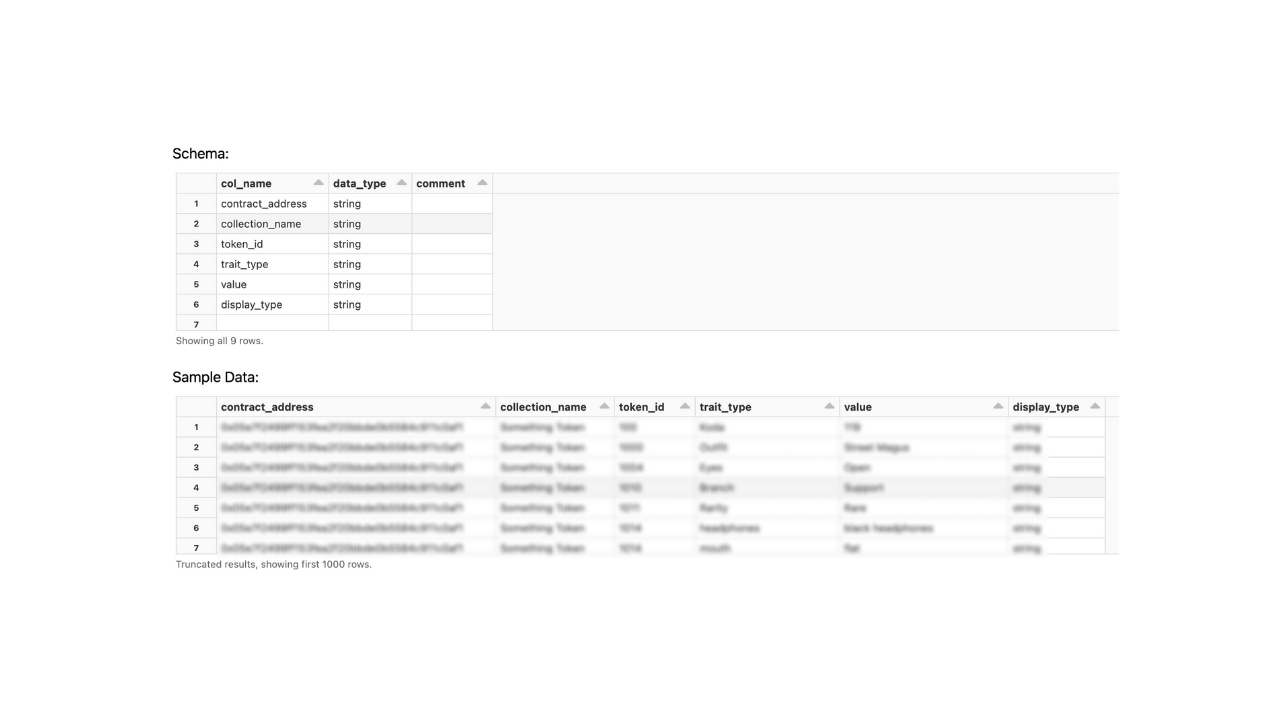
Comme vous pouvez le constater, nous sommes limités aux 1000 premières lignes et le commun des mortels ne saurait interpréter ce type de données sans une visualisation adaptée. Les Notebooks répondent à ce besoin car ils permettent de visualiser rapidement les résultats attendus. Mais nous voulions centraliser ces résultats et les regrouper au sein d’un même espace où il serait possible de visualiser plusieurs graphiques en même temps. Cela servirait également à une potentielle démonstration auprès du client.
C’est donc pour cette raison que nous avons choisi de construire nos premiers dashboards directement sur Databricks. En effet, comme mentionné précédemment, il est possible de créer des tableaux de bord basés sur des requêtes SQL venant requêter nos tables Bronze, Silver et Gold. Pour cela, il suffit d’enregistrer une requête SQL dans l’éditeur de requête, puis de l’importer dans un dashboard afin de construire un graphique associé. L’interface propose de nombreuses possibilités de graphiques (des nuages de points, des courbes, des histogrammes, etc.) et ceux-ci nous ont permis de visualiser nos données facilement en un temps record.
Industrialisation du POC et développement du projet
Une fois le POC validé avec le client, nous avons dû concentrer nos efforts sur l’industrialisation de celui-ci. C’est-à-dire, créer un workflow de développement dont les étapes de validation et de déploiement automatisés permettent de garantir un certain niveau de qualité et de sécurité tout en restant concentré sur la création de la valeur ajoutée (code métier des nouvelles fonctionnalités).
En effet, jusqu’ici nous utilisions des Notebooks pour produire notre code, le tester et créer nos jobs. Nous avons donc initié la création d’un dépôt Github pour y stocker l’ensemble du code de notre projet : code PySpark, définition des jobs Databricks, code des pipelines CI/CD (Github Actions).
Nous sommes partis sur l’approche mono-dépôt, nous avons donc créé un seul dépôt Git pour l’ensemble des pipelines de tous les layers (bronze, silver, gold) car nous avons estimé que leurs cycles de vie étaient assez proches. Les avantages de cette approche sont évidents : le code de la CI/CD est mutualisé et une fonctionnalité correspond à une seule Pull Request. L'inconvénient est que tous les pipelines de tous les layers sont toujours déployés ensemble même si la Pull Request ne concerne qu’un seul layer. Il est donc nécessaire de prendre plus de précautions pour ne pas introduire des effets de bord, c'est-à-dire tester en environnement de preview l’ensemble des pipelines.
Nous avons tout de même conservé les Notebooks pour tester certaines fonctionnalités non testables en local et travailler de façon collaborative sur des prototypes.
Déploiement des jobs sur Databricks
La possibilité de packager le code avec l’ensemble des bibliothèques nécessaires au projet (format JAR) était pendant longtemps notre argument principal en faveur de Scala par rapport à Python. Fort heureusement pour nous, deux mois avant le démarrage de notre projet, Databricks a rendu publique une nouvelle fonctionnalité : la possibilité d’utiliser l’exécutable packagé au format Wheel. La contrainte imposée par le client d’utiliser Python n’en était donc plus une finalement.
Le packaging du code Python permet aux différentes bibliothèques d’être directement intégrées au wheel, cela offre donc un gain de temps au démarrage du cluster ainsi que l’assurance que l’exécutable ne varie pas. Soucieux de créer une architecture simple mais robuste, nous avons implémenté différents fichiers de configuration (entry_point.py, setup.py, fichiers JSON) afin de permettre le déploiement automatique des jobs sur Databricks via notre CD. L’exécutable étant construit et déployé exclusivement par la CI / CD, nous avons fixé des étapes de validation (que je vous décris juste après) afin d’empêcher toute erreur humaine.
Mise en place de la CI/CD
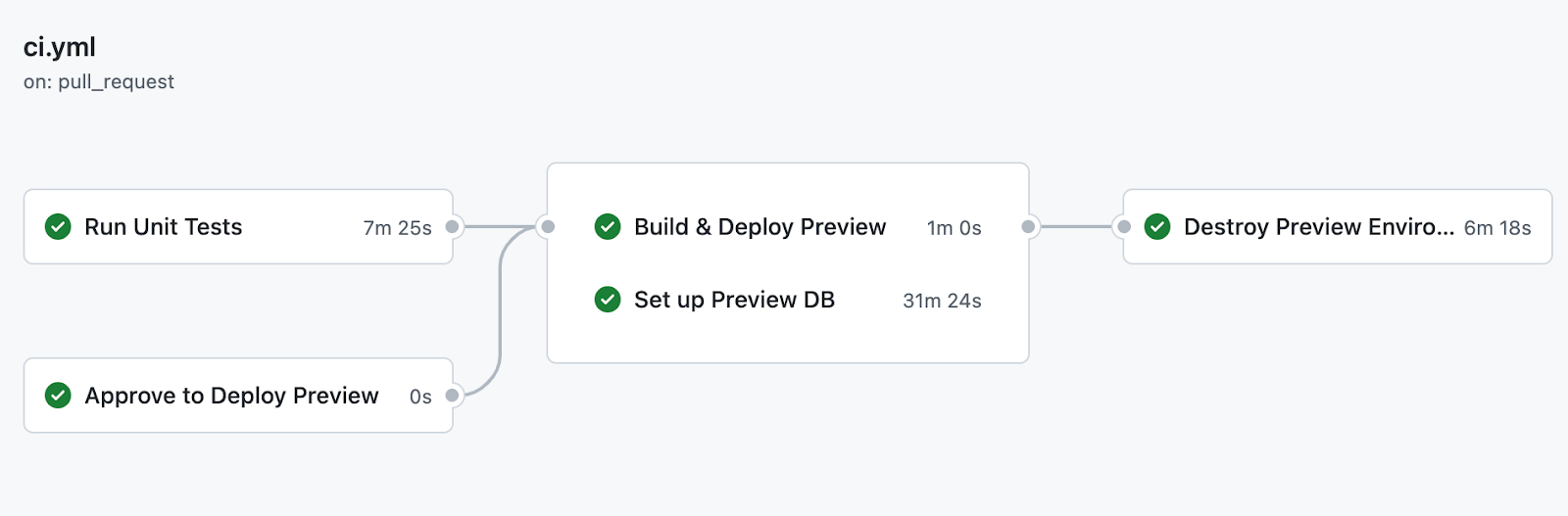
Qui dit déploiement, dit CD (Continuous Deployment), et qui dit CD dit… CI (Continuous Integration). C’est ainsi que nous avons écrit un fichier .yaml pour la CI et un pour la CD. Comme décrit précédemment, le fichier de CI permet de packager le code Python en wheel, de lancer les tests unitaires et déployer un environnement de preview (pas de panique on revient la-dessus juste après).
Tandis que le fichier de CD permet de déployer les jobs sur Databricks avec le code mis à jour en production. Nous avons utilisé le workflow Git “Oneflow” où la branche Master correspond à l’environnement de production et donc tout ce qui va être merge sur Master sera déployé en production. Les étapes de validations d’une Pull Request que nous avons évoquées précédemment sont les suivantes : Pull Request sur Github → Tests Unitaires → Test en environnement de preview → Revue de code → Merge de la Pull Request.
À l’instant, je vous parlais d’environnements de preview, venons-en aux faits. Les environnements de preview permettent de créer, à partir d’une Pull Request sur Git, tous les jobs présents dans le code et de copier toutes les tables présentes dans la base de données de production. Pour éviter la duplication des données et un temps de copie trop long, nous avons utilisé le “Shallow Clone” qui permet de ne copier que les métadonnées des tables tout en pointant sur les fichiers des données de l’environnement de production.
Une fois l’environnement de preview déployé, le Data Ingénieur (ou n’importe qui d’ailleurs) peut déployer les jobs qu’il souhaite et effectuer ses tests sans affecter les données de l’environnement de production. Cela permet également de ne pas avoir à créer un environnement de développement dédié, qui viendrait dupliquer de façon permanente les données de production, ce qui engendrerait des coûts plus élevés, et qui ne serait jamais parfaitement synchronisé avec celui-ci.
Une fois les tests effectués et le passage en production prêt, il suffit de détruire l’environnement de preview, de valider la Pull Request sur Github et de déployer les nouvelles fonctionnalités en production via la CI /CD.
Plus il y a de données plus on rit
À ce niveau du projet, nous n’avions pas encore de données off-chain, excepté les fichiers JSON stockés dans un bucket S3. Et vous vous doutez bien que ces fichiers n’allaient pas subsister très longtemps, de nouvelles sources de données ont donc été ajoutées.
Tout d’abord, nous avons intégré des sources provenant de streams Kinesis contenant des données off-chain issues d’API externes. Elles ont pour but d’enrichir les données on-chain afin de répondre aux KPIs attendus par le client. Ayant besoin d’informations relatives aux transactions, collections et aux autres plateformes qui n’étaient pas directement accessibles sur la blockchain, nous étions contraints d’utiliser des sources externes. Par exemple, les métadonnées de certains NFT ou collections ne sont pas stockées on-chain, nous obligeant à utiliser une API pour les obtenir.
Nous avons donc créé les jobs nécessaires à leur ingestion au niveau Bronze puis effectué les transformations requises pour les intégrer au Silver et au Gold. La principale difficulté fut de joindre les données on-chain et off-chain (nommages différents, doublons, valeurs manquantes, etc.) dans l’optique de créer des tables opérationnelles tout en maintenant un niveau de service inférieur à la minute. N’oublions pas qu’il s’agit d’une marketplace sur laquelle des utilisateurs peuvent effectuer des transactions, les données doivent donc être à jour le plus rapidement possible. Sous peine de faire courir le risque aux utilisateurs d’acheter un NFT déjà vendu.
De plus, je vous avais expliqué au début de cet article que nous ingérions les données issues de la blockchain Ethereum, or, une nouvelle blockchain source (Palm) a été ajoutée. Nous avons donc créé les jobs nécessaires à l’ingestion de ces nouvelles données en Bronze.
Enfin, l’objectif étant d’alimenter une marketplace de NFT, nous devions connaître à chaque instant la conversion des crypto-monnaies disponibles sur la plateforme en USD. Par conséquent, nous avons développé des jobs faisant appel à des API externes telles que Coinbase et Finnhub afin de stocker dans une table Bronze la conversion de toutes les crypto-monnaies en dollar pour chaque minute depuis la création de celles-ci.
Avec l’arrivée de ces nouvelles sources de données et nouveaux besoins, nous cumulons pas moins de 13 tables Bronze sur le projet.
Ensuite, à partir des nouvelles données et de celles que nous avions déjà, nous devions construire environ 15 tables Silver contenant des données filtrées et nettoyées. À ce niveau, les données étaient d’ores et déjà exploitables par le front-end de la plateforme pour exposer les indicateurs nécessaires.
Et avec ceci, vous prendrez bien un peu d’analytics en dessert ? Nous avons donc construit 9 tables Gold nécessitant de nombreuses agrégations et transformations. Ces tables sont directement accessibles par le front-end de la plateforme via des SQL endpoints mis à disposition.
“Détruire la concurrence, c'est tuer l'intelligence”
En effet, ce projet nécessite beaucoup d’intelligence de par son métier complexe et ses mécaniques exigeantes. C’est ainsi que nous avons rencontré un problème auquel nous n’avions pas pensé dès le début : la concurrence. Attention, ici je ne parle pas de concurrence avec d’autres personnes, je parle bien de concurrence entre les différents streams. Laissez-moi vous expliquer !
Toutes les tables créées au sein du projet sont alimentées en streaming et, pour chaque batch de données ajouté dans une table source, les données de celle-ci sont mises à jour par le job. Cela implique parfois d’utiliser des opérations de type Update pour modifier l’état d’une ligne.
Or, lorsque deux streams parallèles veulent mettre à jour en même temps une table via des opérations d’update, l’un des deux échoue à cause de la concurrence (l’approche Optimistic Locking implémentée par Delta Lake), les Delta Tables garantissant les propriétées ACID des transactions (atomicité, cohérence, isolation et durabilité). Et cela même s’ils ne veulent pas forcément modifier la même ligne d’une table, le stockage sous-jacent des tables par Delta Table peut provoquer de la concurrence. En effet, derrière les Delta Tables se cachent tout simplement des fichiers au format Parquet stockés dans un bucket S3. Cela va donc de soi qu’un seul fichier peut contenir plusieurs lignes d’une même table, il suffit donc que 2 streams veuillent modifier des lignes présentes dans le même fichier pour que l’un des streams échoue. Bien que cela soit un “problème” en apparence, cette concurrence assure la cohérence des données en empêchant à l’un des streams d’écrire et de potentiellement corrompre le fichier.
Mais pas de panique, il y a une solution à cela, et c’est tout simplement le partitionnement des tables. Et pour illustrer cela, je vous propose de prendre un cas concret que nous avons eu.
Nous avons la table nft_transfer qui est alimentée par 2 streams : un provenant des tables relatives à la blockchain Ethereum et un provenant de Palm. Ces streams ne font pas qu’insérer les données dans la table, ils peuvent également mettre à jour une donnée si nécessaire. Or, cette mise à jour peut intervenir en même temps sur les deux blockchains, c’est-à-dire que les streams issus de Palm voudront modifier certaines données qui sont possiblement stockées dans les mêmes fichiers que les données d’Ethereum. C’est donc pour cela que nous avons partitionné cette table par blockchain grâce à une colonne “blockchain” dans la table Silver. Ainsi, chaque stream écrit dans sa propre partition, et s’il souhaite mettre à jour une donnée d’une blockchain, nous sommes sûrs que les fichiers impactés ne contiendront pas des données d’une autre blockchain, peu importe le nombre de blockchains ajoutées à l’avenir.
Le partitionnement permet d’organiser les fichiers par partition, ainsi on peut être sûr que les fichiers relatifs à une partition ne contiennent que les données relatives à une certaine valeur de la colonne de partitionnement.
Nous avons rencontré un autre cas de conflit avec nos streams lorsque l’on souhaitait appliquer une optimisation quotidienne sur nos tables. En effet, étant donné que nos streams tournaient en continu sans interruption, il nous était impossible de compacter les données de façon asynchrone, sous peine de voir le stream s’arrêter à cause d’un conflit.
Nous souhaitions lancer ces optimisations au sein d’un job programmé pour se lancer chaque jour. Ce job a pour but d’exécuter la commande OPTIMIZE qui permet d’optimiser les Delta Tables en compactant les fichiers afin d’obtenir des tailles optimales (1 GB par fichier par défaut). Pour pallier cela, nous avons configuré l’auto-compaction des tables au sein même des streams, cela a pour avantage d’effectuer automatiquement l’auto-compaction des fichiers lorsque cela est possible sans entrer en conflit avec l’écriture dans les tables. Cette fonctionnalité proposée par Databricks s’est avérée très utile et presque indispensable à notre pipeline pour conserver des fichiers de taille optimisée et des performances élevées.
Conclusion
Comment conclure en quelques lignes une expérience aussi enrichissante que celle-ci ?
Je vous propose de commencer par un rapide résumé de cette expérience. Nous avons construit une plateforme data pour une marketplace de NFT destinée à fournir des indicateurs clés à ses utilisateurs sur le marché des NFT, les transactions effectuées ainsi que toute information relative aux portefeuilles de ceux-ci. Notre périmètre s’est étendu de l’ingestion des transactions brutes issues de différentes blockchains jusqu’à la mise à disposition de tables agrégées prêtes à l’emploi pour le front-end de la plateforme.
Nous avons implémenté des logiques complexes relatives à ce marché émergent et en perpétuelle évolution. Toutes les tables sont alimentées en streaming grâce à l’Auto Loader proposé par Databricks et à Spark Streaming qui peut utiliser une table Delta comme source.
Une fois la phase de POC validée, l’industrialisation du projet fut l’une de nos priorités, c’est pourquoi nous avons créé une CI / CD permettant l’intégration continue des modifications de code avec Github, la possibilité de tester ses modifications via des environnements de preview répliquant celui de production et le déploiement automatisé des jobs sur Databricks.
Bien entendu, en 6 semaines nous n’avons pas pu mettre en place tout ce que nous souhaitions. Mais les objectifs ont été remplis, le client a à sa disposition un produit fonctionnel répondant à son besoin et ses équipes sont en mesure de reprendre le projet grâce aux séances de passation effectuées à leurs côtés.
Ensuite, il me semble indispensable de mettre en avant l’importance de Databricks. L’environnement et l’écosystème très riche que Databricks met à disposition s’est révélé être un véritable atout au bon déroulement du projet. Des Delta Tables à la création de jobs en passant par les Notebooks et toute l’interface SQL, Databricks nous a permis de répondre efficacement à presque toutes les problématiques que nous avons rencontrées.
Durant tout le déroulé de cet article, nous avons beaucoup insisté sur les problématiques techniques de ce projet, mais n’oublions pas la complexité et la méconnaissance initiale que nous avions de l'écosystème de la blockchain et des NFT. Construire une marketplace de mise en relation de vendeurs de pommes de terre aurait fait notre affaire. Ce défi nous a fait sortir de notre zone de confort et nous avons dû monter en compétences rapidement sur de nombreuses thématiques, que je vous propose d’aborder dans de prochains articles, ici même, sur le blog d’Ippon Technologies. Et croyez-moi, j’ai hâte de vous partager la somme des enseignements que nous a apportés cette mission !