

Le service AWS Controllers for Kubernetes (ACK) est un service géré par l’équipe AWS Kubernetes actuellement en cours de développement. Ce service vise à permettre de manager les services AWS tels que S3 ou ECR directement depuis Kubernetes. L’objectif étant à terme de faire de Kubernetes la tour de contrôle permettant aux équipes infra de gérer leurs ressources.
Cet article a pour but de découvrir ce service et de le tester via l’installation d’un controller au sein d’un cluster Kubernetes.
Quel est l’intérêt de ACK?
ACK peut être considéré comme étant une abstraction supplémentaire de la gestion des ressources AWS qui s’ajoute aux différentes solutions déjà existantes.
Aujourd’hui, il existe 3 niveaux "d'abstraction" d’infrastructure as code:
- Niveau 1 : infrastructure as code définie sous la forme de script shell. Dans cette catégorie, on peut citer le lancement de commandes via l’AWS CLI ;
- Niveau 2 : utilisation d’outils tels que puppet, terraform, ansible, salt afin de définir étape par étape l’infrastructure que nous voulons mettre en place ;
- Niveau 3 : nous définissons seulement l’état final désiré de l’infrastructure. C’est à ce niveau qu’appartient ACK.
Actuellement, l'utilisation d’AWS et de Kubernetes représente une complexité de conception qui n’est pas aisée à appréhender. En effet, ces architectures demandent d’articuler les ressources entre elles afin de permettre à l’infrastructure générale de fonctionner correctement. La compréhension de l’infrastructure dans sa globalité est donc nécessaire et demande de switcher très régulièrement entre les différentes technologies.
AWS nous propose avec ce nouvel outil de permettre à son utilisateur de créer de nouvelles ressources et de contrôler leur état courant. Ainsi l’utilisateur n’aurait plus qu’à définir l’état de la ressource AWS désirée et le contrôleur se chargerait de faire passer la ressource de l’état courant à l’état désiré.
Voici un schéma simplifié du fonctionnement de ACK :
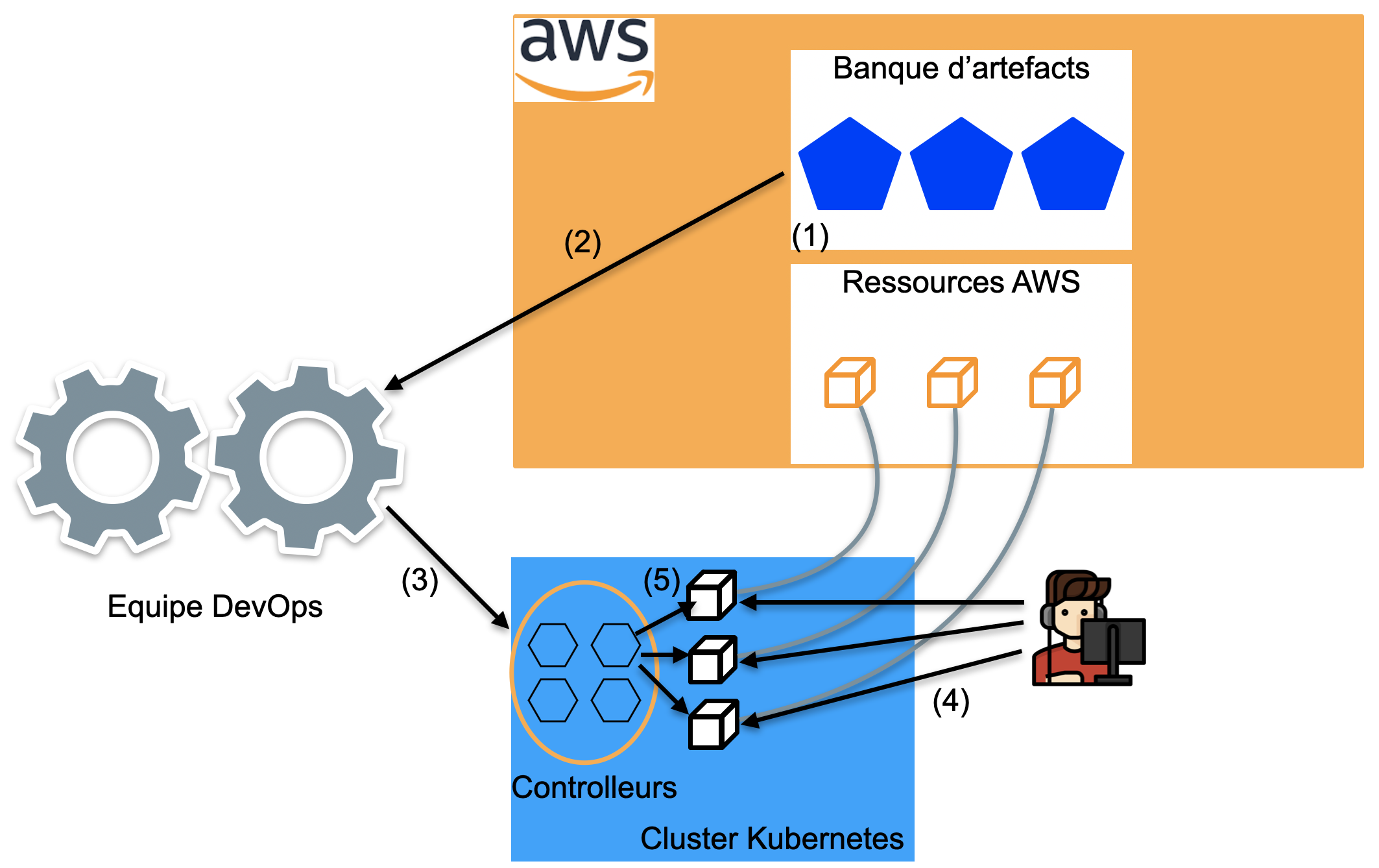
Imaginons que nous sommes membres de l’équipe chargée de maintenir l’infra (Equipe DevOps).
Une équipe de développeurs souhaite que l’on mette en place un bucket S3 dans le but de pouvoir stocker les images du site que nous administrons. Afin de gérer de manière autonome ce bucket ainsi que l’ensemble des buckets S3 que l’on va créer par la suite, nous avons besoin de récupérer les manifests qui définissent le controller-s3 depuis AWS (1-2). Nous déployons ensuite le contrôleur directement dans le cluster Kubernetes (3). En appliquant la “Custom Resource Definition” fournit par AWS, nous avons aussi défini par extension de l’API Kubernetes un nouveau “Kind” qui se nomme “bucket” et qui servira à déployer des bucket S3. Enfin, les développeurs d’applications n’ont plus qu’à créer les “customs resources” bucket représentant les ressources AWS (4). Basé sur ces ressources, le controller S3 crée, met à jour ou supprime les ressources AWS associées via des appels à l’API d’AWS (5).
L’utilisation de ACK permettrait finalement à Kubernetes de devenir l’unique source de vérité concernant les ressources déployées sur AWS. Cela permettrait ainsi une meilleure lisibilité des ressources déployées (unicité du lieu de contrôle). Le fait de manager les ressources AWS depuis un cluster Kubernetes rendrait aussi plus simple l’intégration des nouveaux membres des équipes. En effet, les informations portant sur l’infrastructure étant disponibles dans Kubernetes, cela réduirait le nombre de technologies à maîtriser. Ainsi un nouveau membre pourrait avec la compréhension des manifests YAML bien appréhender l’infrastructure globale sans connaissance particulière de terraform ou AWS CloudFormation.
Un autre avantage lié à l’utilisation du service ACK pourrait être de léguer plus de responsabilités aux développeurs concernant le déploiement de ressources sur AWS. Les développeurs de chaque équipe auraient ainsi pour charge de veiller à leurs ressources AWS via les contrôleurs sur Kubernetes. A terme l’objectif serait finalement d’avoir un namespace de déploiement de ressources customs par équipe de développement. Ceci permettrait alors de cloisonner ces ressources associées à des ressources AWS par namespace Kubernetes. On peut imaginer mettre en place des restrictions portant sur les namespaces accessibles “en écriture” aux développeurs afin d'avoir une politique de “moindre privilège”.
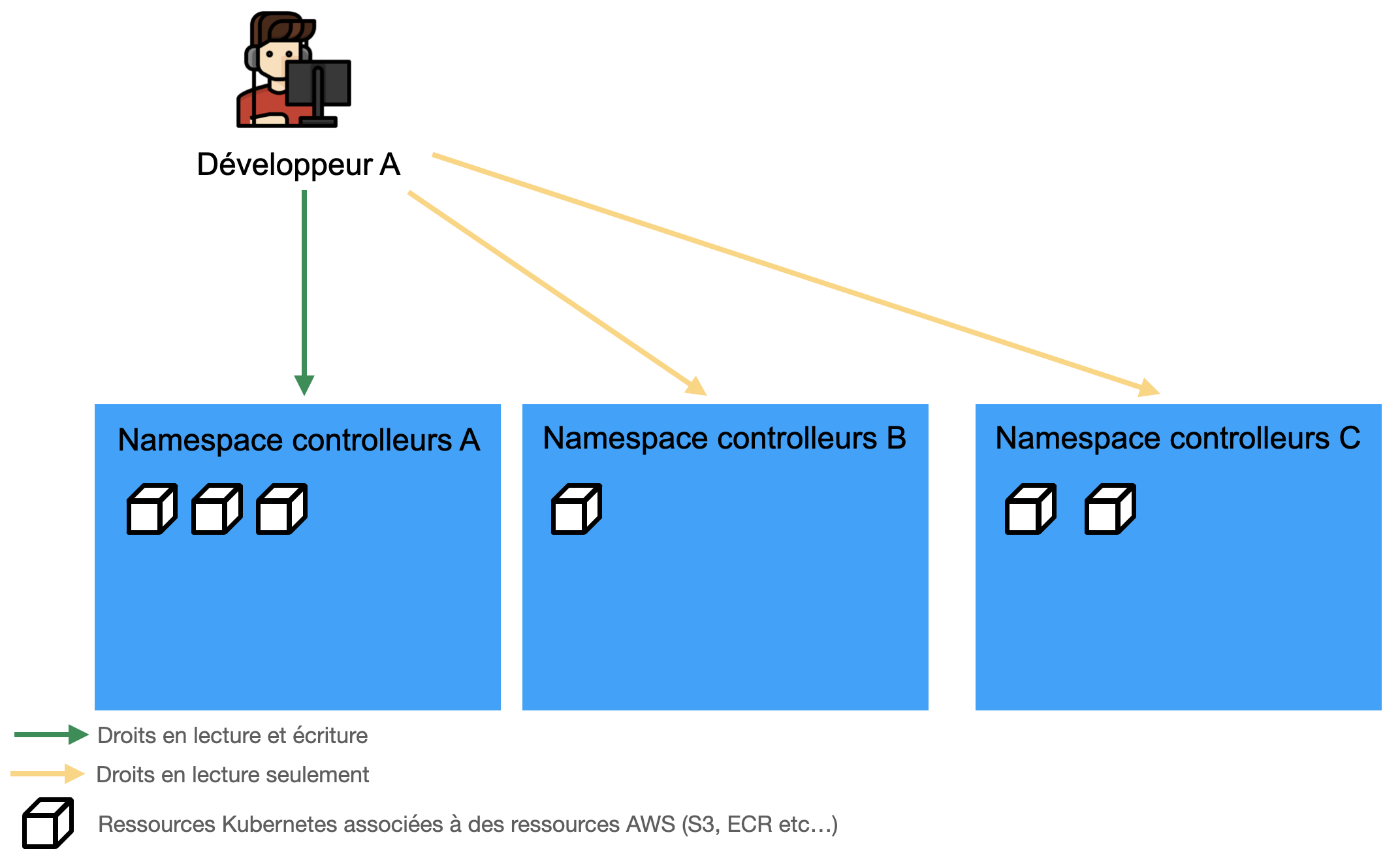
Préparation au test de ACK sur un cluster Kubernetes
Outils nécessaires :
- docker
- kubectl
- helm 3
- eksctl (si besoin de mettre en place un cluster Kubernetes managé rapidement sur AWS)
Afin de tester ce service, j’ai fait le choix de mettre en place rapidement un cluster Kubernetes EKS via les commandes suivantes :
curl --silent --location
“[https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$](https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$)(uname -s)_amd64.tar.gz” | tar xz -C /tmp
mv /tmp/eksctl /usr/local/bin
Et j’ai ainsi pu créer mon cluster via la commande :
eksctl create cluster --name=ack-test-eks --nodes=2 --region=eu-west-1
Il est possible de consulter la stack cloudformation sur AWS afin d’en savoir plus sur les ressources créées précédemment.
Nous sommes fin prêt à tester ACK :D
Passons à la phase de test
Les charts Helm sont mis à disposition dans le répertoire ECR suivant :
https://gallery.ecr.aws/aws-controllers-k8s/chart
Il existe un chart par service controller. Ici, nous allons tester le contrôleur de service S3.
Tout d’abord, il nous faut récupérer le chart helm qui nous intéresse (la version actuelle étant la v0.0.1) :
export HELM_EXPERIMENTAL_OCI=1
helm chart pull public.ecr.aws/aws-controllers-k8s/chart:s3-v0.0.1
L’export de la variable HELM_EXPERIMENTAL_OCI est nécessaire car ce chart Helm est expérimental.
On exporte ensuite le chart dans un path temporaire :
mkdir -p /tmp/chart
helm chart export public.ecr.aws/aws-controllers-k8s/chart:s3-v0.0.1 --destination /tmp/chart
Jetons un coup d’oeil au chart Helm :
Nous pouvons observer la présence de CRDs (Kubernetes Custom Resource Definitions). Ces CRDs permettent de définir des ressources customs dans le but de pouvoir créer et gérer des ressources AWS.
Le CRD présent va permettre alors via l'extension de l’API Kubernetes de gérer un bucket S3 sur AWS.
Dans les templates, nous pouvons observer la présence :
- d’un ClusterRole qui donne l’autorisation d’utiliser le nouveau “apiGroups” créé par le CRD ;
- d’un serviceAccount associé au déploiement du controller sur Kubernetes ;
- d’un ClusterRoleBinding qui permet au serviceAccount précédemment cité d’assumer le ClusterRole créé ;
- d’un déploiement qui définit le déploiement du contrôleur responsable de la gestion de la ressource AWS créée.
Avant d’installer le chart Helm, nous créons un namespace dans lequel seront créées les différentes ressources Kube :
kubectl create namespace ack-test
Nous pouvons maintenant installer le chart Helm :
helm install --namespace ack-test ack-s3-controller /tmp/chart/ack-s3-controller
Il est nécessaire de donner au service account créé, ack-s3-controller, des droits sur les ressources AWS S3. On crée donc un rôle avec des droits administrateur sur S3:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": "*"
}
]
}
Au moment de la rédaction de cet article, le chart helm n’étant pas à jour, j’ai remplacé le contenu du fichier service-account.yaml par le contenu suivant:
{{- if .Values.serviceAccount.create }}
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
app.kubernetes.io/name: {{ include "app.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/version: {{ .Chart.AppVersion | quote }}
k8s-app: {{ include "app.name" . }}
helm.sh/chart: {{ include "chart.name-version" . }}
name: {{ include "service-account.name" . }}
annotations:
{{- range $key, $value := .Values.serviceAccount.annotations }}
{{ $key }}: {{ $value | quote }}
{{- end }}
{{- end }}
Et j’ai mentionné l’ARN du rôle créé précédemment dans le fichier values.yaml
Une fois l’installation terminée, nous pouvons définir et appliquer un manifest YAML comme celui ci-dessous qui utilise la nouvelle API Kubernetes créée s3.services.k8s.aws :
apiVersion: s3.services.k8s.aws/v1alpha1
kind: Bucket
metadata:
name: my-bucket-test-ack
spec:
name: my-bucket-test-ack
Voici un schéma indiquant les actions qui se déroulent lors de l’application du manifest précédent :
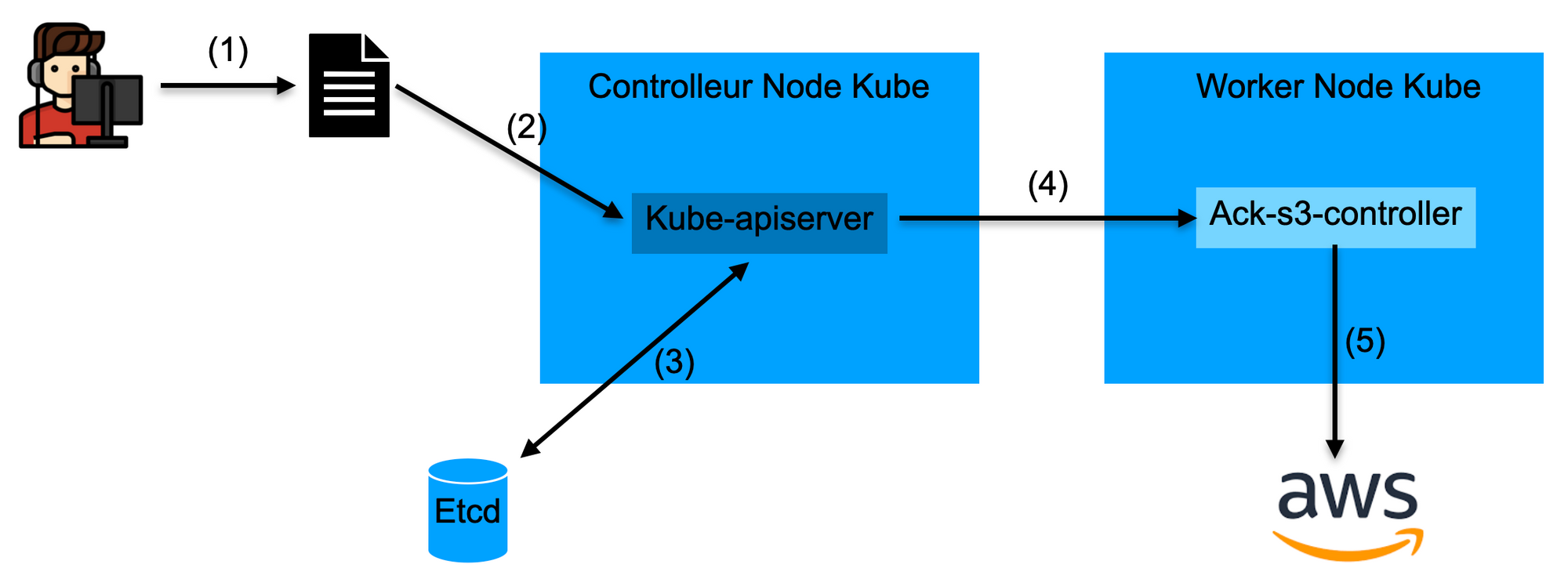
Lors de l’application du manifest décrivant le bucket S3 (1), le serveur API Kubernetes détermine si l’utilisateur a les droits requis afin de créer une ressource custom du type s3.services.k8s.aws (2).
Si l’utilisateur est autorisé et si le manifest est valide, le serveur API Kubernetes enregistre la ressource custom dans le volume etcd (3).
Le service controller S3 est alors notifié qu’une nouvelle ressource custom a été créée (4). Enfin, le controller communique avec l’API AWS pour créer le bucket S3 (5).
Une fois le bucket créé, nous pouvons retrouver la ressource Kubernetes associée en jouant la commande suivante :

De même, du côté du controller nous retrouvons bien dans les logs la création du bucket associé:

Que pouvons nous retenir de cette exploration?
Le service ACK semble intéressant à mettre en place pour les diverses raisons citées précédemment. Il me semble cependant que ce service reste à privilégier pour les entreprises bénéficiant d’une maturité importante sur les technos AWS et Kubernetes. En effet, une bonne maîtrise de ces ressources de la part de l’équipe DevOps permet de bien encadrer la mise en place de ACK. Cette mise en place passe par la séparation des ressources dans les namespaces et les questions de sécurité liées au management des ressources AWS depuis Kubernetes. Afin d’adopter une politique de “moindre privilège”, il est conseillé de donner aux utilisateurs de Kubernetes seulement accès aux namespaces nécessaires. Cette granularité peut s’avérer difficile à mettre en place et à maintenir dans des grandes structures au sein desquels les équipes doivent avoir accès à un nombre élevé de ressources. Une réflexion toute particulière est alors portée sur les mesures de sécurité à prendre et sur la manière de les mettre en place. De même, un autre sujet de réflexion intéressant porte sur la manière de migrer efficacement et sans trop de complexité nos infrastructures actuelles (reposant souvent sur du Terraform, CloudFormation ou autres) vers ACK.
J’attends de mon côté avec impatience la version finale afin d’avoir des retours de mises en place dans des contextes d’entreprise.
