

Article co-écrit par Aïssa BENHAMIDA et Jérémy RATSIMANDRESY.
Introduction
Game Changer est un projet qui repose sur deux idées : explorer les usages de GraphQL et en générer rapidement une architecture serverless. En quelques mots, à partir d’un schéma GraphQL, qui décrit les différents types de données, on peut générer une application complète de gestion de données. D’un côté, la partie serveur permet le traitement de requêtes GraphQL et des actions à appliquer sur nos données (modification, lecture) et de l’autre la partie cliente permet d’avoir une interface pour interagir avec ces données.
Principes de conceptions
C’est quoi le low-code ?
Le low-code c’est cette notion qui, dans un contexte de besoin de productivité et de rapidité de tests/déploiement, se développe de plus en plus et redéfinit la vision que l’on porte sur le développement logiciel. L’objectif est d’obtenir des solutions informatiques prêtes à l’emploi rapidement, tout en réduisant l’écriture de code au minimum.
Pour cela, on favorise l’usage de générateurs et d’outils templates. Le logiciel Excel est un exemple d’outil qui s’inscrit dans cette logique : initialement, le tableur n’a pas de fonction particulière, mais une fois les cellules remplies, par des fonctions mathématiques par exemple, on obtient une application fonctionnelle personnalisée selon le besoin, sans avoir eu besoin d’écrire de nombreuses lignes de code. De la même façon, on cherche à automatiser le plus possible les problématiques de traitement de données et de requêtes.
La force du cloud pour du serverless
On dit “ce qui est fait n’est plus à faire”, et c’est ce que le Cloud vient ainsi apporter dans un contexte de low-code. Des tâches comme définir des ressources mémoire, exécuter du code ou encore gérer le maintien des environnements (pour les coûts) sont facilement délégables aux services de cloud computing. Une instance Lambda par exemple, n’a pas besoin d’être administrée manuellement. Le code contenu est exécuté automatiquement, en fonction d’événements déclencheurs définis. L’utilisateur se concentre ainsi sur le contenu plutôt que sur la forme et la structure.
GraphQL pour encapsuler l’ensemble
GraphQL, pour Graph Query Language, est une spécification de description de données qui propose une alternative aux services REST traditionnels dans un environnement d’API. Trois grands principes les distinguent.
Tout d’abord, l’accès aux données en contexte GraphQL s’effectue à partir d’un point d’entrée unique, qui se termine par convention en /graphql, alors qu’en REST les points d’accès sont définis en fonction des données recherchées et des requêtes.
Ensuite, les requêtes GraphQL sont encapsulées dans la méthode HTTP POST quel que soit le type de requête, là où REST utilise l’ensemble des méthodes HTTP pour préciser la nature de la requête.
Enfin, le point fort de GraphQL réside dans la possibilité de construire dans sa requête la réponse souhaitée, en indiquant uniquement les informations sur les objets que l’on souhaite. Un serveur REST retournera au contraire l’ensemble des informations des objets correspondant à une requête même si elles ne sont pas pertinentes pour l’utilisateur.
Dans cette optique, GraphQL est une solution qui permet d’améliorer les performances (pour le transport de données notamment), d’accorder une liberté pour les clients au niveau des requêtes et de simplifier l'accessibilité grâce à l’unique point d’accès d’API.
Architecture
Le projet se présente comme un ensemble de générateurs qui s’appuient sur le framework de scaffolding Yeoman : un pour l’aspect serveur et deux pour l’aspect client.
Partie serveur
L’enjeu principal était de pouvoir obtenir une API possédant les propriétés de la spécification GraphQL, à l’aide des différents services que proposent AWS. Chacun d’entre eux occupe un rôle clé :
Lambda
C’est le cœur de notre API GraphQL, qui héberge tout le code d'exécution du serveur. Les requêtes des clients transmises par l'intermédiaire du service API Gateway sont interprétées et traitées pour interagir avec la base de données Aurora. Les données reçues en réponse ou les erreurs sont ensuite retransmises à Lambda qui réachemine ces résultats vers les clients dans le sens inverse.
Aurora Serverless
Ce système de base de données dit serverless se base sur la non nécessité pour les utilisateurs de paramétrer les différentes caractéristiques du serveur de base de données. Les ajustements de stockage et de performance sont entièrement gérés par AWS.
Pour le projet, ce service permet de stocker les données de l’application générée. Le choix de postgres comme moteur de base de données permet de faciliter la gestion relationnelle des données.
API Gateway
Ce service fournit le point d’accès du serveur GraphQL, pour permettre aux clients d’envoyer des requêtes, et déclenche l’exécution de la lambda en les transmettant.
Cognito
Avec Cognito, on dispose de la possibilité de créer et administrer des groupes d’utilisateurs, afin de leur accorder des droits et des restrictions. On restreint ainsi l’accès aux données de notre application, en imposant à notre point d’accès défini par l’API Gateway la nécessité d’un token d’authentification.
S3 et CloudFront
Ces deux services souvent complémentaires dans des environnements de développement web en cloud vont permettre le déploiement de la partie front de l’application. D’une part S3 correspond à des espaces de stockage pouvant supporter différents types de données : images, vidéos, fichiers texte. L’ensemble du code front est donc déposé dans une instance de ce service. D’autre part, CloudFront est un CDN, ce qui va faciliter l’accès aux ressources grâce à une adresse URL générée. Cette adresse pointera directement sur les fichiers contenus dans l’instance S3 précédemment créée.
Une image étant plus parlante que des mots, on obtient l’architecture suivante :

L'exécution d’une requête se déroule de la manière suivante :

Le générateur permet ainsi d’obtenir un module Node.js qui servira de code pour l’instance Lambda et un ensemble de fichiers de configuration terraform permettant de mettre en place toute la structure décrite au sein d’AWS.
Partie cliente
Associé à notre API, le client fournit une interface utilisateur permettant de réaliser l’ensemble des opérations CRUD définies selon la spécification GraphQL. L’objectif idéal est d’appliquer ces principes sur l’ensemble des frameworks front usuels dont React, Angular ou encore Vue.
Ember
Ce framework a servi de point d’entrée pour affiner le concept de la partie cliente. D’une part, chaque objet aura son ensemble de composants front (route, template). D’autre part, à travers l’addon Ember Data, on bénéficie d’une logique de gestion de données interne, à travers un store, qui supporte les relations entre entités et assure un aspect de persistance de données avec la partie serveur de l’application. Des objets Model propres à Ember sont créés pour chaque type d’objet.
Source : https://guides.emberjs.com/v5.1.0/models/
Ce schéma expose parfaitement cette deuxième partie : l’application gère ses données en interne à travers le store, mais communique aussi avec le serveur pour assurer une synchronisation des données.
Le générateur obtenu s’appuie ainsi sur le système d’addon propre à Ember et permet à partir d’un projet ember vierge de générer l’ensemble du système front (route, composant, template) pour chaque type d’objet ainsi que la logique de persistance de données.
React
À partir de l’exemple d’Ember avec Ember Data nous avons imaginé une implémentation similaire avec React. On avait donc besoin d’une gestion centralisée des données, à travers l'état de l’application, tout en maintenant une synchronisation avec notre API serverless. Redux apparaissait comme un candidat idéal pour ces opérations.
En effet, ce système de gestion d’état centralisé est conçu pour s’intégrer de manière optimale avec React. En s’inspirant du fonctionnement d’Ember Data, nous avons adapté son implémentation au sein de l’application finale afin de permettre une persistance des données entre le serveur et la partie cliente. Ainsi, pour chaque interaction avec l’application faite par l’utilisateur ayant un impact sur les données, un objet Action va être envoyé à la logique de Redux (Store). En fonction de la nature de l’action, des modifications sur l’état de l’application, c’est-à-dire la représentation de ses données, sont appliquées et l’interface utilisateur (UI) se met à jour pour transmettre visuellement les changements. Dans le même temps, ces modifications sont transmises de manière asynchrone au serveur sous forme de requêtes GraphQL et sont appliquées sur les données en base de données. Enfin, dans le cas de récupération de données depuis le serveur, les Actions vont attendre de recevoir ces données par requêtes GraphQL pour permettre ensuite au store de remplir l’état de l’application.
Le schéma ci-dessous illustre ce principe en prenant comme exemple une interaction avec trois sources d’API.
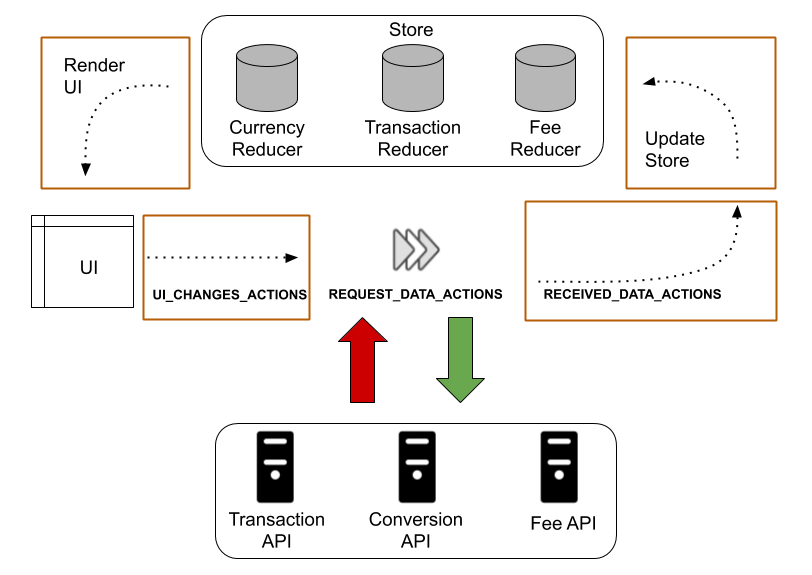
Le générateur obtenu permet comme pour Ember d’obtenir à partir d’un projet React vierge l’ensemble du système front mais aussi la logique de gestion d’état proposée par Redux. Cette implémentation réussie amène à imaginer une application plus large sur d’autres frameworks, en utilisant Redux ou d’autres gestionnaires de store parfois mieux optimisés en fonction des frameworks (Vuex pour Vue par exemple).
Le mot de la fin
En utilisant les capacités de services du cloud et les outils front-end, on a obtenu un framework de génération d'applications serverless qui s’inscrivent dans l’écosystème de GraphQL. Aujourd’hui le projet est disponible sur son repo Github dans sa première version, avec de nombreuses pistes qui restent à creuser pour le rendre plus robuste : support des types de relations, support de l’ensemble de la spécification GraphQL, ajout de nouveaux supports front-end…
La vidéo de démonstration suivante permet de rendre compte de l’utilisation concrète du projet :