
Ces dernières années, le Cloud se développe à grande vitesse, et ce dernier apporte tout son lot de nouvelles problématiques. Même si la thématique de l’observabilité ne date pas de l’ère du Cloud, elle revêt aujourd’hui d’une importance toute particulière. En conséquence, le marché regorge d’outils pour surveiller son architecture et ses applications.
Aujourd’hui nous allons nous intéresser à l'un de ces outils : Datadog, l’objectif de cet article est de vous le faire découvrir.
Pourquoi Datadog ?
Polyvalence
Datadog permet de superviser les logs et les métriques tout en proposant des services d’Application Performance Management (APM) et de corrélation de métriques. De plus, Datadog s’adapte aux infrastructures traditionnelles jusqu’aux infrastructures serverless.
Application SaaS
Datadog est distribué en tant que service intégralement managé par l’entreprise éponyme. Ainsi, vous disposez d’une application hautement disponible clef en main.
Facilité d’intégration
L’interconnexion de Datadog à vos environnements se fait via un système d’intégrations. Leur mise en place est simple et grâce à la polyvalence, les intégrations permettent de remonter les logs, les métriques, les traces... avec la même solution.
Datadog est fourni avec des intégrations pour de nombreuses applications et de services très populaires (AWS, Azure, GCP, Nginx, Kubernetes, etc..).
User friendly
Datadog est une solution simple à prendre en main avec une interface intuitive qui vous permettra de créer des dashboards simplement avec du drag’n’drop, mais aussi de visualiser toutes vos métriques et vos logs, ainsi que vos traces si vous activez l’APM.
Tags
A l’instar des ressources dans un environnement Cloud, toutes les ressources sur Datadog disposent de tags récupérés automatiquement depuis le Cloud Provider, ou bien ajoutés de façon personnalisée.
Fonctionnalités de Datadog
- Collectes de métriques
- Collecte de logs
- APM
- Dashboards
- Alertes
- Corrélation de métriques
Intégration Datadog
Comme son nom l’indique, c’est ce qui permet de relier Datadog à vos environnements, afin qu’il collecte l’ensemble des données (métriques, logs, traces) utiles. Les intégrations peuvent se faire à l’aide d’un agent, ou bien d’un crawler.
Agent Datadog
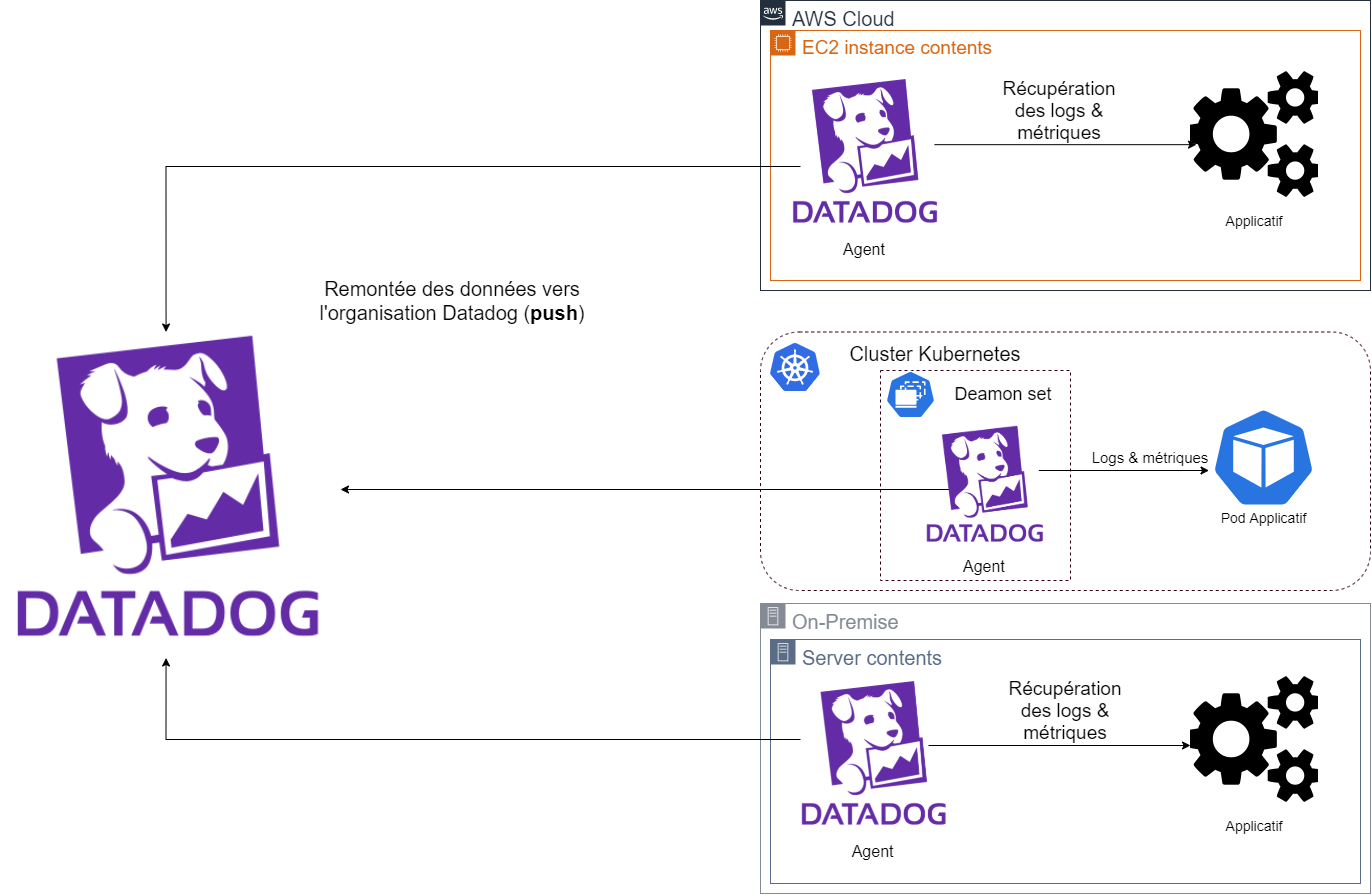 |
|---|
| Fonctionnement agent Datadog |
L’Agent Datadog est un binaire à faire tourner sur les hôtes auxquels vous avez accès. Ce dernier est à utilité multiple, il permet à la fois de remonter les logs, les métriques, mais aussi les traces, chacune de ces fonctionnalités peuvent s'activer dans la configuration YAML associée à l’agent (**/etc/datadog-agent/datadog.yaml**). L'intérêt de cet agent c’est donc sa polyvalence face aux besoins.
[...]
##################################
## Log collection Configuration ##
##################################
# @param logs_enabled - boolean - optional - default: false
# Enable Datadog Agent log collection by setting logs_enabled to true.
logs_enabled: false
# @param logs_config - custom object - optional
# Enter specific configurations for your Log collection.
# Uncomment this parameter and the one below to enable them.
# See https://docs.datadoghq.com/agent/logs/
logs_config:
# @param container_collect_all - boolean - optional - default: false
# Enable container log collection for all the containers (see ac_exclude to filter out containers)
container_collect_all: false
[...]
Ex: Activation/Désactivation de la collecte des logs applicatifs
De plus l’avantage de l’Agent est qu’il est agnostique de la plateforme sur laquelle il tourne, il s'exécute sur une machine, indépendamment qu’elle soit une instance EC2, un worker Kubernetes ou une VM on premise. L’agent est installable sur tous les OS les plus répandus (Amazon Linux, Ubuntu, CentOS, Windows, etc…).
Attention: Dans le cadre d’une utilisation de l’agent pour remonter exclusivement des logs, il est préférable d’utiliser une solution comme FluentD à l’aide de ce plugin. Cette solution a l’avantage d’être gratuite et open source, contrairement à l’agent Datadog qui sera facturé en tant que host (voir la tarification).
Documentation Agent Datadog
Exemple complet du fichier de configuration
Crawler - SaaS
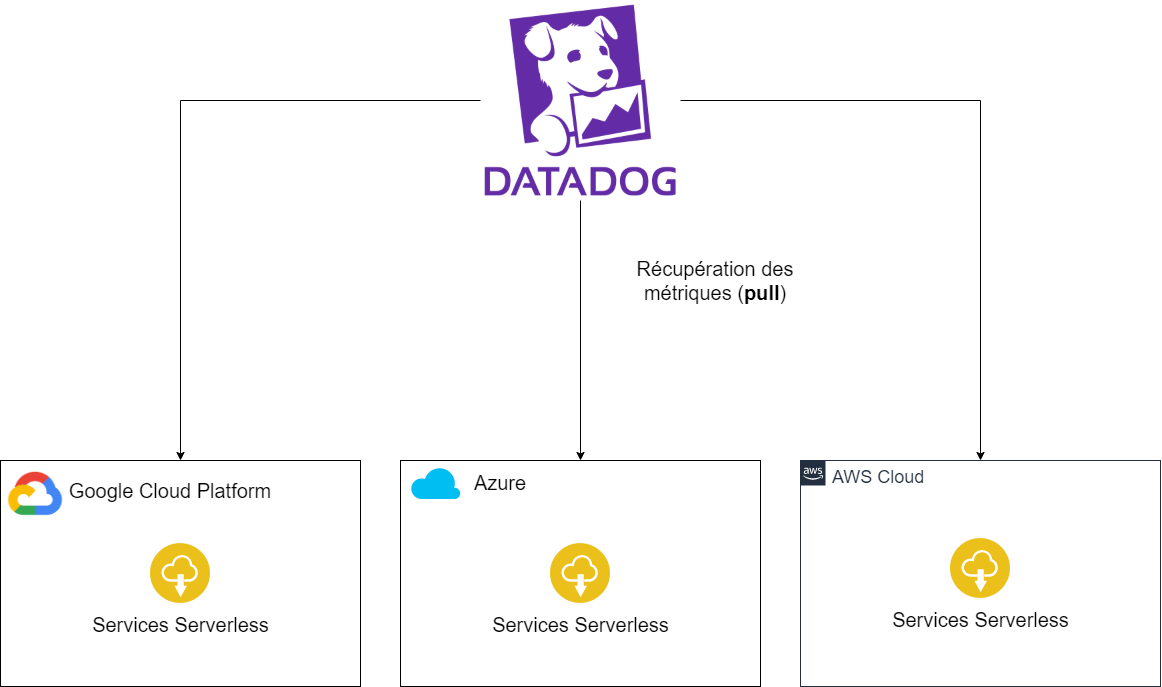 |
|---|
| Principe crawler Datadog |
Pour certains services très populaires tels que AWS, Azure, GCP, Heroku et bien d’autres, Datadog fourni des intégrations sous forme de crawler. Celle-ci prend la forme d’une délégation de rôle avec des permissions permettant à Datadog de récupérer les métriques. Ce dernier les récupère depuis le service de monitoring du cloud provider (par exemple CloudWatch pour AWS).
Le crawler se révèle d’une très grande utilité lorsqu’il est nécessaire de remonter les métriques des services serverless (pour remonter les logs, cf. partie Log Forwarder). En revanche, lorsqu’on a accès aux hôtes, il vaut mieux préférer installer un agent afin d’éviter de payer le passage par le service monitoring de votre Cloud Provider qui peut causer une latence ou un surcoût (CloudWatch a une latence de 5 minutes par défaut). Ainsi, si on souhaite remonter les logs et métriques d’une application non serverless, alors il sera préférable de les remonter à l’aide d’un Agent.
Les intégrations Cloud permettent également d’associer automatiquement les tags liés à vos ressources Cloud dans Datadog. Cela vous permettra ainsi de simplifier la gestion de vos dashboards, avec les tags renseignant l’environnement associé à une ressource, ou encore gérer votre billing avec des tags renseignant le projet associé à vos ressources.
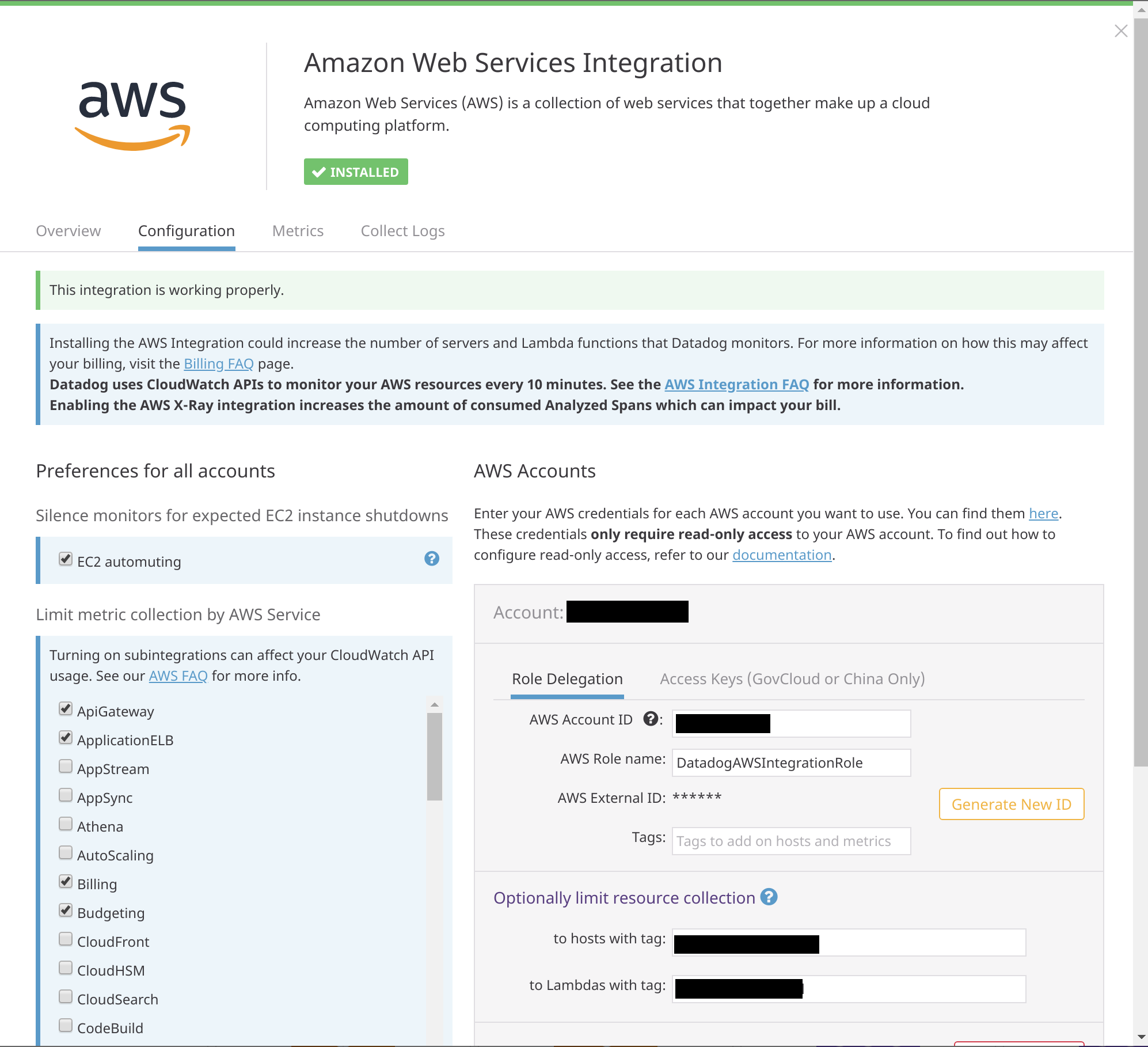 |
|---|
| Configuration du crawler AWS |
Afin de bien comprendre les différences entre le Crawler et l'Agent, voici un tableau comparatif :
| Crawler | Agent | |
| Installation | Depuis l'interface des intégrations Datadog | Binaire à installer sur les hôtes |
| Fonctionnement | Pull des métriques via une délégation de rôle. Configuration depuis l'interface Datadog & liste d'autorisations sur le cloud provider | Push des métriques, logs & APM sur Datadog. Configuration à l'aide d'un fichier YAML sur l'hôte |
| Cas d'utilisation | Récupération des métriques des services cloud serverless | Récupération des métriques, logs, APM (en fonction de la configuration) depuis un hôte sur lequel on a accès |
Log Forwarder - SaaS
Les Logs Forwarders s’utilisent en complément des crawlers, ils permettent de remonter les logs de vos services Cloud comme les logs réseaux, les logs des load balancer, ou bien les logs de vos applications serverless (Lambda, Cloud Function, Fargate, etc…). Datadog fournit la solution Log Forwarder pour chaque cloud provider :
- AWS : Datadog Forwarder (Lambda) + CloudWatch ou Kinesis Data Stream + CloudWatch
- GCP : Cloud Pub/sub + Stackdriver
- Azure : Azure Function + Event Bridge
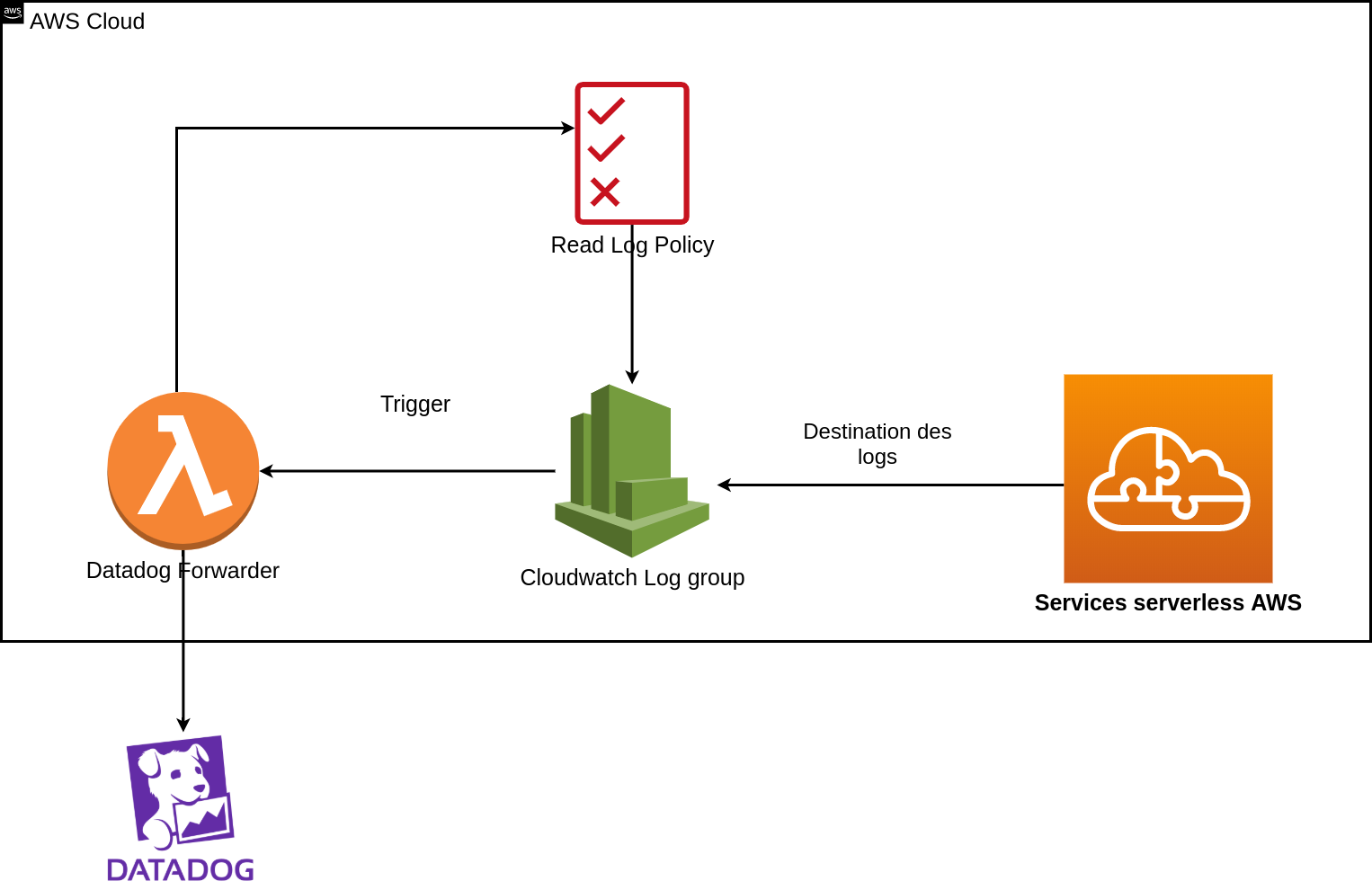
Principe du Log Forwarder sur AWS
Custom metrics
Dans le cas où vous ne seriez pas satisfait des métriques remontées par vos intégrations, vous pouvez créer vos propres métriques et les envoyer à Datadog soit en passant par l’API soit en utilisant les nombreux SDK disponibles. A l’instar de vos métriques classiques, vos custom metrics sont constituées d’une valeur, d’un nom, d’un timestamp, d’un type et d’une liste de tags.
Les custom metrics sont parfaites pour représenter une mesure fonctionnelle dans votre application. Elle permettront de créer des dashboards destinés au métier, et vous pourrez également leur configurer des alertes.
Enfin, toutes les métriques sur Datadog (custom ou non) sont stockées pendant 15 mois et elles ne sont pas archivables, contrairement aux logs.
Log Management
Le Log Management sur Datadog dispose de certaines particularités. Par exemple, il existe une différence entre les logs ingérés et les logs indexés.
Tous les logs ingérés sont envoyés dans une solution de stockage object dans votre Cloud Provider (Amazon S3, GCP Cloud Storage, Azure Storage). L’envoi des archives dans le bucket se fait grâce au rôle que vous avez délégué à Datadog dans l’intégration Cloud que nous avons vus précédemment.
Les logs indexés sont ceux qui sont stockés sur Datadog et qui bénéficient des fonctionnalités que Datadog offre pour les logs. Vous pourrez les rechercher à l’aide d’un langage de requête, les ajouter à votre dashboard, ainsi que les mettre en corrélation avec des métriques et les relier à des traces. Il est également possible de générer des métriques sur la base de vos logs : vous pourrez par exemple générer une métrique indiquant le nombre de logs d’erreurs sur un projet (identifié par un tag). Ce genre de métriques générées à partir de vos logs peuvent se révéler utiles pour donner un sens fonctionnel.
Enfin, les logs indexés sont conservés durant une période de rétention préalablement définie, au delà de cette période ils seront toujours disponibles dans vos archives et peuvent être indexés à nouveau via la fonctionnalité de rehydrate. Cela peut être utile lors d’un audit par exemple.
Datadog est fourni de base avec un index sans aucun filtre, ce qui indique que tous les logs ingérés sont indexés, ce qui n’est pas forcément une méthode économique et il est préférable de créer ses propres index afin de ne sélectionner que les logs qui ont de l’importance selon votre contexte. Chaque index dispose de sa propre durée de rétention, de règles de filtrage pour sélectionner ce qu’il faut indexer, et également de la possibilité de mettre en place un quota journalier de la quantité de logs à indexer.
Application Performance Management (APM)
La fonction APM permet d’analyser en détail la performance de votre application à l’aide des traces.
Les traces servent à suivre le parcours d’un utilisateur sur votre application, et à identifier les points de blocage, les composants qui sont plus lents que d’autres, ainsi vous pouvez construire un dashboard représentatif de l’expérience utilisateur sur votre application.
Des dashboards de performance prêts à l’emploi qui surveillent les requêtes, les erreurs et la latence de vos services Web sont livrés de base avec la fonctionnalité d’APM, vous pourrez les utiliser comme base et les personnaliser.
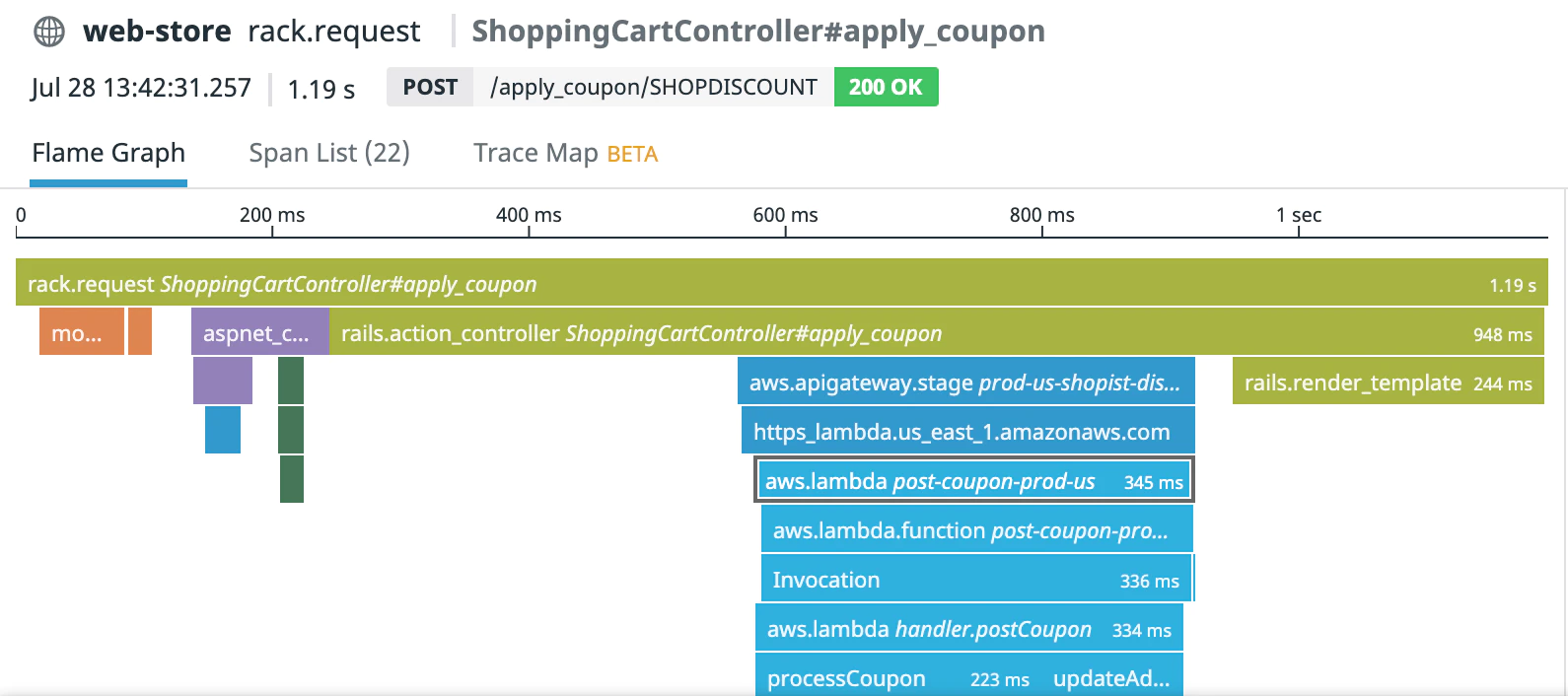
Exemple de traces
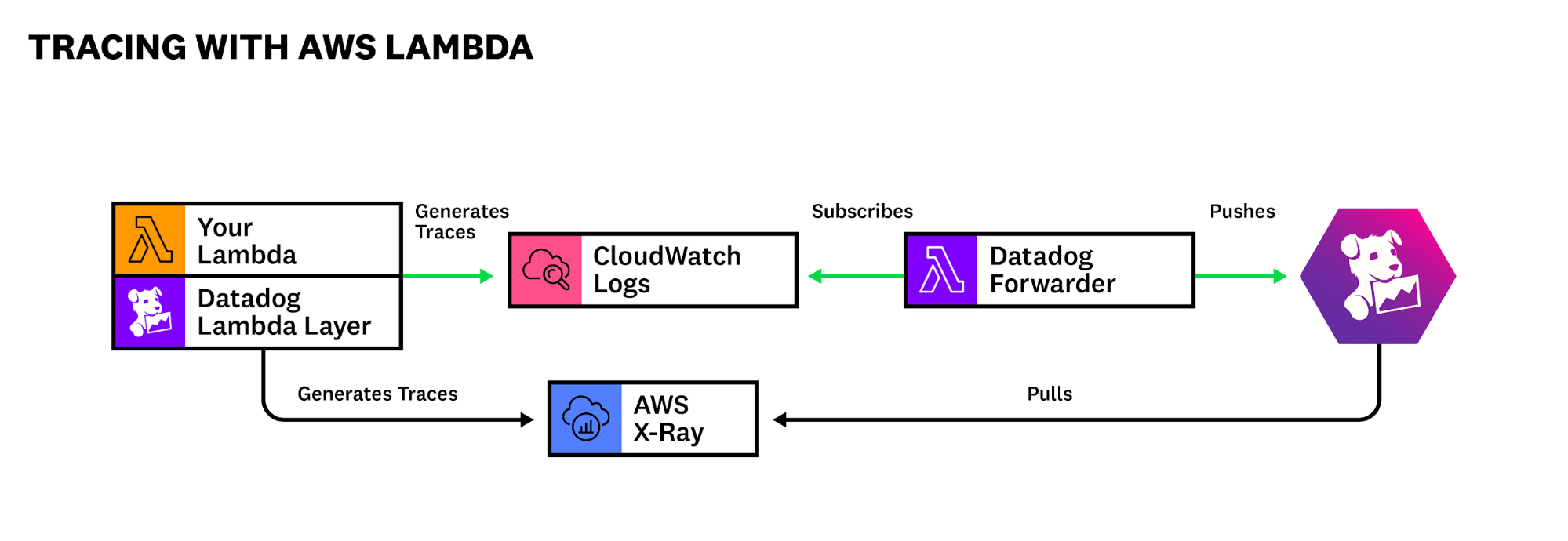
L’APM fonctionne comme suit : Vous devez configurer votre application à l’aide du SDK Datadog afin d’envoyer les traces à l’agent, il doit être préalablement configuré pour activer l’APM. Dans le cadre d’une application serverless pour laquelle vous ne pourrez pas installer d’agent, il existe des alternatives. La première alternative consiste à activer X-Ray sur vos Lambdas puis à configurer Datadog pour qu’il récupère les traces générées par X-Ray. La seconde alternative se constitue d’une couche (layer) fournie par Datadog qui va générer les traces et les stocker dans CloudWatch Logs, puis la Lambda Datadog Forwarder que nous avons vue précédemment ira pousser les traces dans l’organisation Datadog.
Attention, l’APM entraîne des frais supplémentaires. Pour en savoir plus, référez vous à la tarification de Datadog.
Organisations
Les organisations sont les contenants des ressources Datadog à l’instar d’un compte AWS, elles permettent donc d’isoler logiquement vos métriques, vos logs, vos traces, vos Dashboard d’une organisation à une autre. Chaque organisation dispose de sa liste de membres avec trois rôles prédéfinis (Admin, Standard, Read Only), mais il est également possible de créer des rôles personnalisés pour vos utilisateurs.
Utilisez les organisations afin de structurer votre architecture Datadog à l’image de votre entreprise, vous pouvez faire une organisation par projet, ou bien par BU par exemple, tout dépendra de votre volonté de segmentation.
Actuellement la fonctionnalité des multi-organisations est disponible sur demande via un ticket à envoyer au support de Datadog. Il est fort probable qu’elle devienne tout public et activable à l’initiative de l’utilisateur, référez vous à la documentation afin d’avoir des informations à jour.
Dashboards
Lorsque vous disposez de toutes les métriques et logs que vous souhaitez, il est important d’en tirer une valeur ajoutée en passant à l'élément clef de la supervision, comment représenter la santé de mon SI de manière visuelle ?
Les Dashboards sur Datadog se divisent en deux catégories : les timeboards et les screenboards.
- Screenboard : Disposition libre, chaque graphique peut avoir son propre intervalle de temps.
- Timeboard : Disposition automatique, l'échelle de temps est unique pour tout le dashboard.
La différence étant au final très faible, dans une grande partie des cas vous n’aurez pas à vous soucier du type de dashboard que vous créez.
Que cela soit un timeboard ou un screenboard, vous avez la possibilité de le construire à l’aide de widget en drag’n’drop.
Création d’un nouveau Dashboard
Pour chaque widget ajouté au Dashboard, il est possible de le paramétrer par une ou plusieurs métriques, ainsi que d’appliquer des filtres sur les hôtes.
Prenons l’exemple suivant : Soit trois hôtes hébergeant un apache, chaque hôte dispose d’un agent Datadog correctement configuré afin de remonter les métriques d’Apache. Il est donc possible d’effectuer une moyenne de la métrique par host (Ici le nombre de bytes/s).
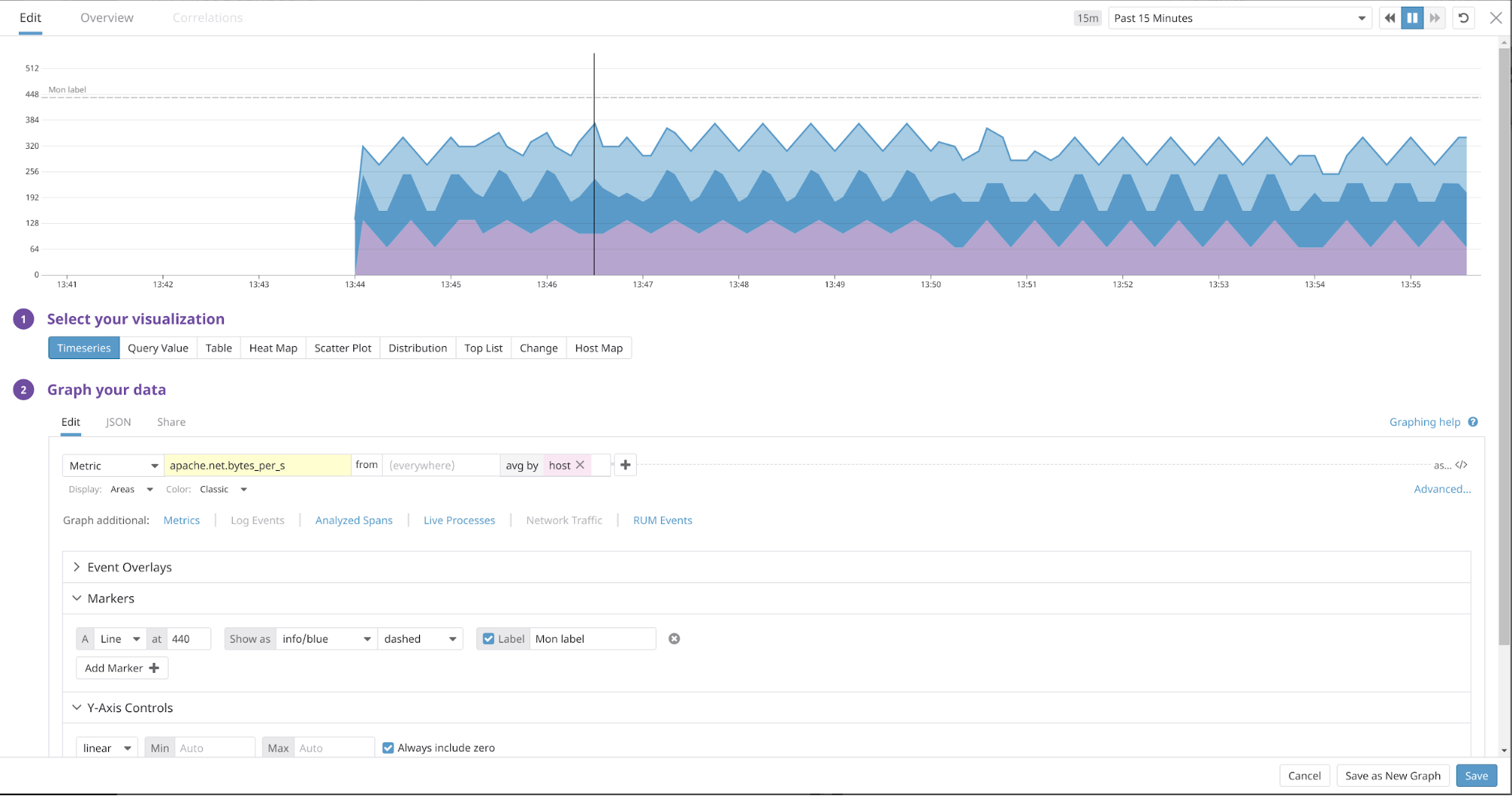
Création d’une timeseries
Il existe de nombreuses autres visualisation de données, telles que des heat map, host maps, distributions... et bien d’autres encore, la liste exhaustive se trouve ici. Ces différentes visualisations vous aideront à tirer une plue value graphique de vos métriques.
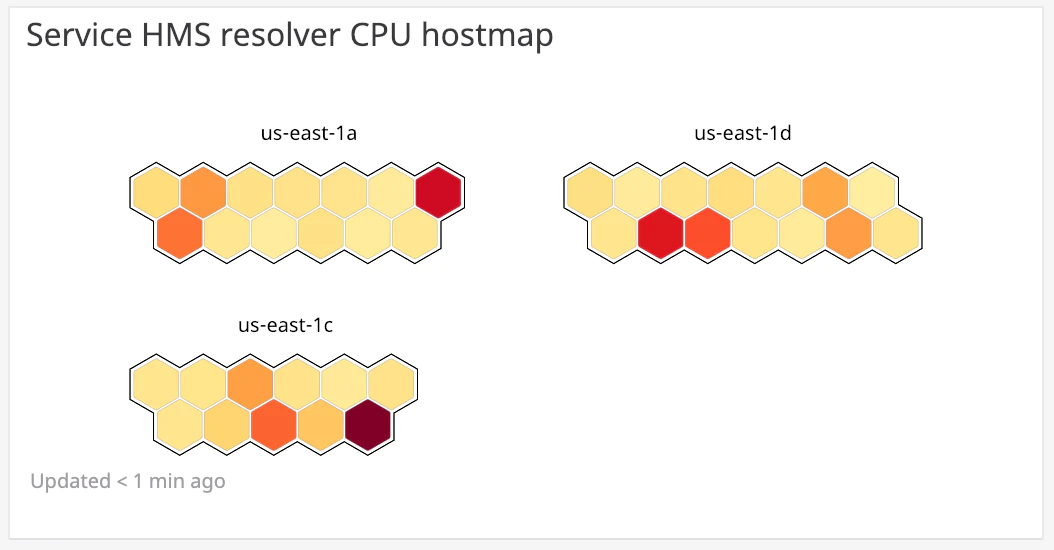
Une hostmap se révèle très utile pour avoir une vision d’ensemble (groupé par tag)
Monitors
Une solution de monitoring se doit de lancer des alertes. Ceci est possible grâce aux monitors. Les types de monitors que Datadog propose sont nombreux, et en voici une liste non exhaustive :
- Host : Vérifier que un ou plusieurs hosts transmettent des données à Datadog
- Métrique : Comparer les valeurs d’une métrique avec un seuil défini
- Logs : Surveille les logs recueillis par Datadog, et recevoir une alerte sur une volumétrie de logs et / ou bien sur un attribut de log (Log d’erreur)
- Prévision : Recoit une alerte lorsque Datadog prédit qu’une métrique s'apprête à franchir un seuil
Une hostmap se révèle très utile pour avoir une vision d’ensemble (groupé par tag)
 |
|---|
| Création d’un monitor Datadog |
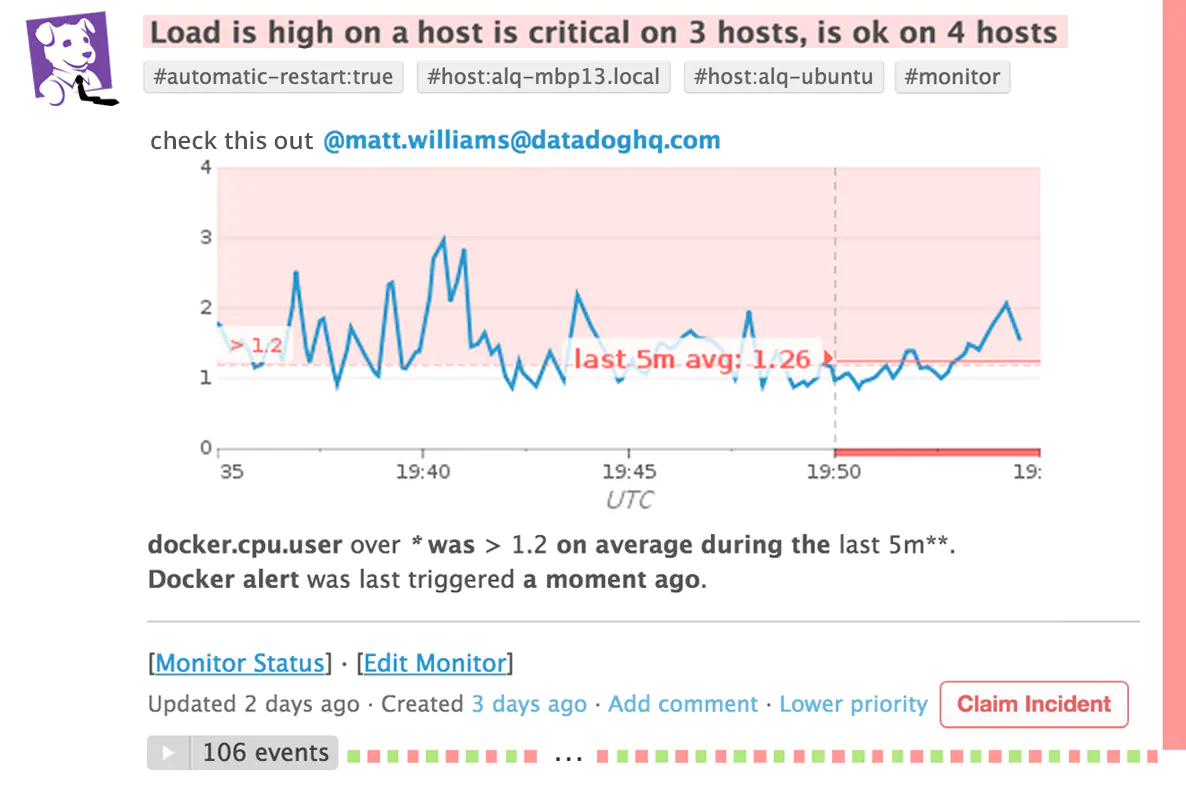 |
|---|
| Alerte reçue par mail |
Les monitors vous permettent également de définir des Service Level Objectives (SLO) chiffrés qui constituent un outil essentiel pour optimiser le niveau de fiabilité d’un site. La définition de bons SLO est une étape importante si vous souhaitez mettre en place les principes du Site Reliability Engineering (SRE) que je ne détaillerai pas dans cet article.
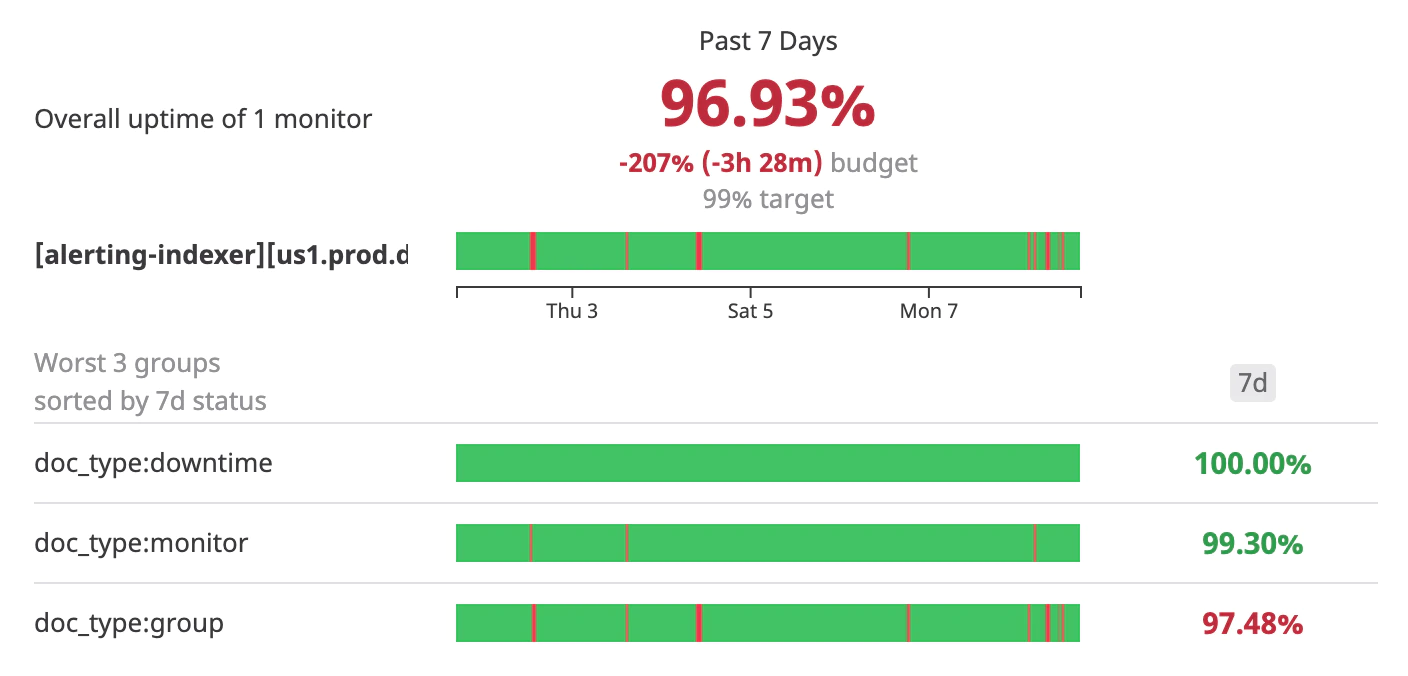 |
|---|
| Exemple de SLOs sur Datadog |
Corrélation
Les corrélations de métriques vous aident à identifier les causes potentielles d’un problème en recherchant d’autres métriques ayant un comportement anormal durant la même période.
Pour explorer les corrélation d’une métriques, il suffit de cliquer sur n'importe quel graphique où elle est présente et de sélectionner Find correlated metrics.
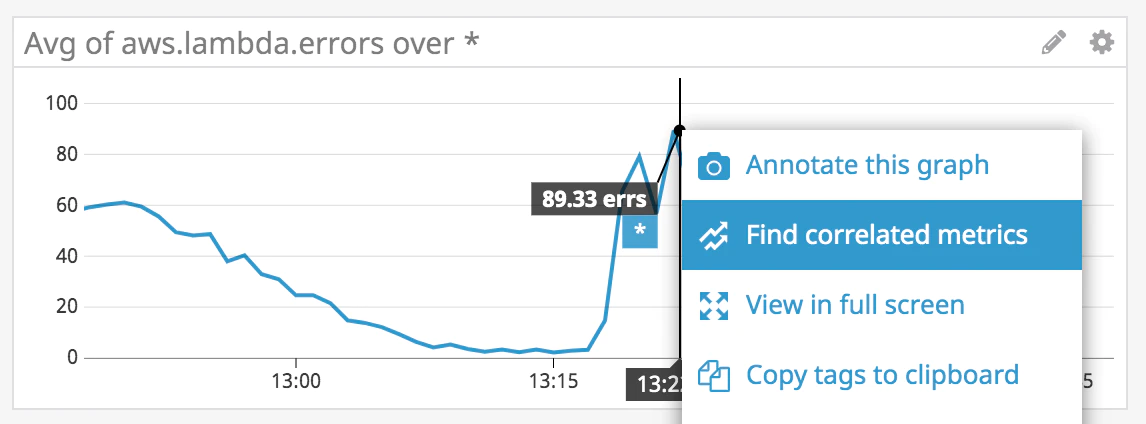
Vous devrez ensuite sélectionner l'intervalle de temps d’étude pour la corrélation.
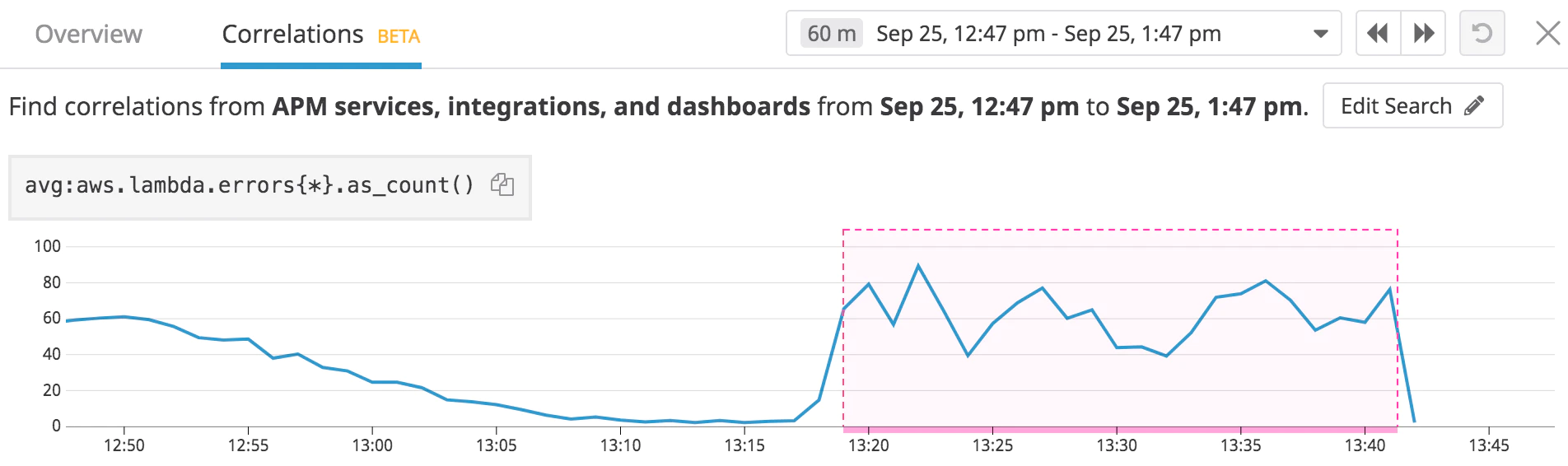
Enfin, l’ensemble des métriques corrélées s’afficheront comme suit :
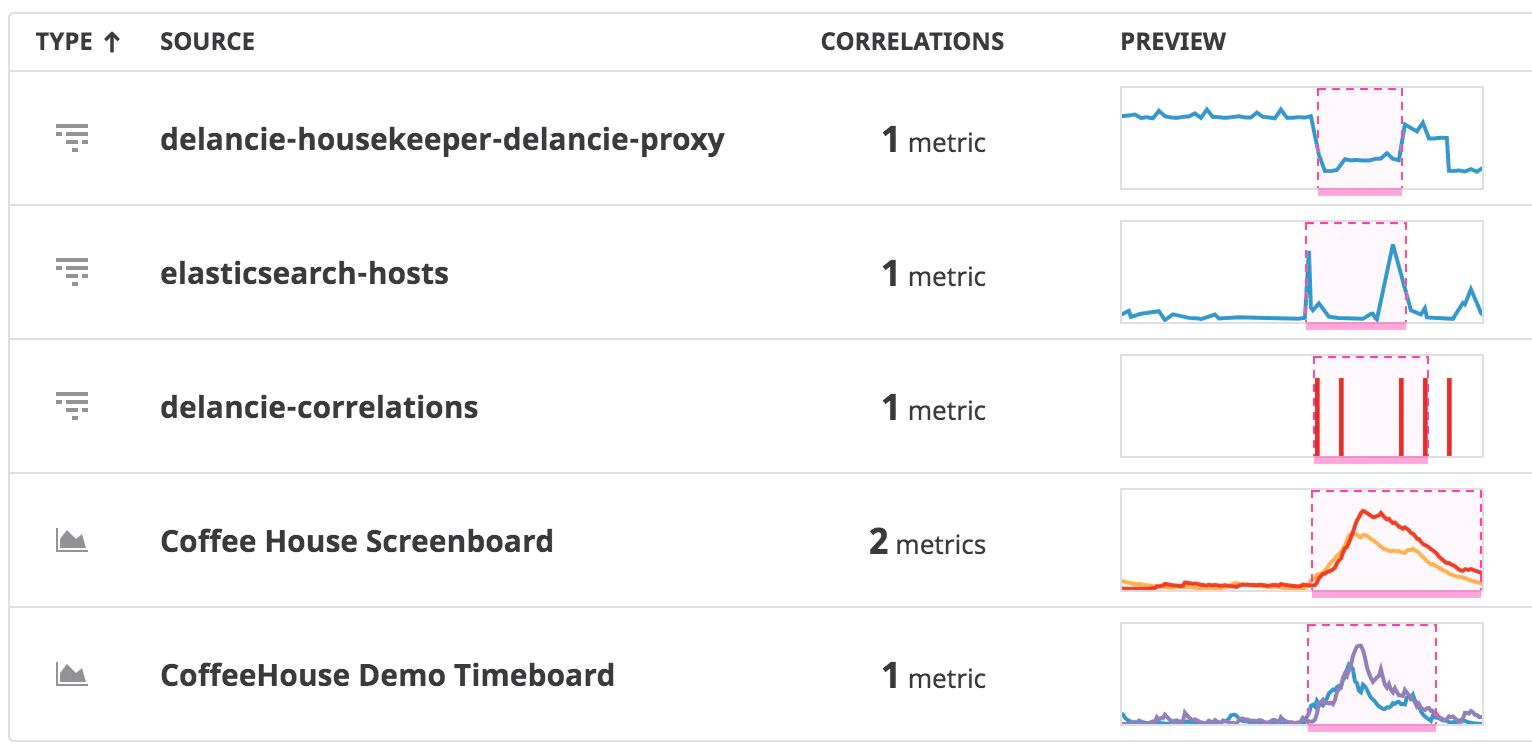
La corrélation de métrique se révèle intéressante lorsque vous avez un comportement anormal sur une custom metric fonctionnelle, vous pourrez trouver les métriques techniques qui ont également eu un comportement anormal durant le même intervalle de temps.
Autres services
Datadog offre d’autres services moins majeurs que je ne vais aborder en détail :
- Serverless functions monitoring : Monitor vos stacks serverless : metrics, traces, service map.
- Security monitoring : Détection de menaces pour votre application et votre infrastructure.
- Network performance monitoring : Donne de la visibilité sur le trafic entre vos services.
- Real user monitoring : Mesure l’expérience end-to-end pour les utilisateurs mobiles et web.
- Synthetic monitoring : Simule des requêtes et actions pour mesurer la performances des pages web et APIs.
- Continuous profiler : Analyse la performance de votre code, détecte les méthodes et classes les plus gourmandes en ressource.
Et l’automatisation dans tout ça ?
Datadog expose une API HTTP pour manipuler tout ce que nous avons vu, les ressources (dashboards, monitors, custom metrics) sont importables et exportables au format JSON. L’authentification se fait via des clefs que vous devez générer depuis vos organisations.
Cette API peut être manipulée soit grâce au SDK Datadog disponible dans un grand nombre de langages décrits ici, soit grâce au provider Terraform. Le choix de Terraform est intéressant, car vous pouvez utiliser le même outil pour provisionner des ressources à la fois dans votre Cloud Provider, et dans Datadog. Dans le cas où vous devez faire une intégration Cloud Provider ⇔ Datadog, vous aurez besoin de créer un rôle (et des permissions) côté Cloud, et configurer l’intégration côté Datadog en faisant référence au rôle précédemment créée : l’utilisation du même outil simplifie drastiquement votre stratégie d’automatisation.
Toutefois, à la date d’écriture de cet article, certaines parties de l’API comme la création d’organisations et la configuration d'archivage des logs ne sont pas couvertes par le provider Terraform. Pour ces parties, préférez l’utilisation du SDK ou de l’API directement.
Tarification
La tarification de Datadog se fait à la carte et en fonction de l’usage (sauf pour le Log Management), vous trouverez toutes les informations à jour et détaillées ici.
Infrastructure
L’infrastructure au sens de Datadog correspond aux hôtes sur lesquels vous avez installé un agent.
Pour la tarification des hosts, il existe une version pro et une version entreprise. La version entreprise est plus chère mais permet l’utilisation des corrélations et du monitoring prédictif que vous avons vus plus haut.
Pour en savoir plus sur les différences, c’est ici.
Comme vu plus tôt, chaque agent peut monitorer les containers qui tournent sur son host à hauteur de 10 pour la version pro et de 20 pour la version entreprise. Au delà, le monitoring de container sera facturé.
Log Management
Pour le Log Management : Vous payez la quantité de logs ingérés (au GB) à l’usage et sans engagement. Pour les logs indexés vous payez par tranche de million d'événements en fonction de la durée de rétention configurée.
Attention cependant, à la date d’écriture de l’article vous devez vous engager à l’avance sur une volumétrie de logs indexés par mois, si vous indexez moins vous payez le même prix, et si vous indexez plus, alors ce surplus vous sera facturé avec une majoration de 50 %. C’est un point négatif qui sera je l’espère modifié à l’avenir.
Exemple de tarification
Prenons un cas classique où vous souhaitez collecter les métriques, les logs et les traces de votre application.
Votre parc est constitué d’une centaine d’hôtes sur lesquels vous allez installer l’agent Datadog afin de collecter ce dont vous avez besoin.
- 50 hosts version pro avec l’APM d’activé.
- 200 GB de logs / mois correspondant à 2 000 000 d'événement de logs, rétention de 15 jours
| Infrastructure | 50 hosts * $15 = $750 |
| APM | 50 hosts * $31 = $1550 |
| Logs | 200 GB ingérés * 0.1 + 2 (millions) indexés * 1.7 = $21.70 |
| Coût total mensuel | $2371.70 |
Remarque
Enfin, la tarification de Datadog peut surprendre et paraître conséquente au premier abord, mais il faut la comparer avec le coût total de possession (TCO) d’une solution alternative comme ELK + Prometheus / Grafana.
Single Sign On (SSO)
Lorsque le nombre d’organisations augmente, il devient difficile de gouverner l’accès pour chaque organisation. Datadog permet d’interconnecter une organisation à un fournisseur d’identité implémentant SAML (Google, Active Directory, etc…), afin de permettre à chaque utilisateur de se connecter sur la plateforme sans avoir besoin de mot de passe.
L'intérêt, c’est qu’il devient possible de gouverner les accès dans un référentiel centralisé, ainsi lorsqu’un utilisateur quitte la structure, il suffit de le retirer du référentiel pour que ses accès soient révoqués sur toutes les organisations auxquelles il a eu accès.
Actuellement à l’instar des multi-organisations la fonctionnalité de SSO est disponible sur demande via un ticket à envoyer au support de Datadog. Ce dernier se voit ajouter des nouvelles fonctionnalités régulièrement, ainsi il est possible qu’à l’avenir le SSO soit disponible tout public sans demande préalable. Je vous suggère de vous fier à la documentation de Datadog qui reste la meilleure ressource pour avoir des informations à jour.
Bonnes pratiques
- Tagger vos ressources : Cela vous permettra de construire des Dashboards plus efficacement
- Déployez des monitors : Soyez prévenus dès qu’un incident se produit (ou même avant grâce à la prédiction de Datadog)
- Si vous ne remontez pas de métriques depuis un hôte, alors n’utilisez pas l’agent Datadog officiel qui sera facturé, mais préférez l’usage d’un outil gratuit tel que FluentD.
- Définissez des règles de filtrage sur vos index de logs
- Activez le SSO sur vos organisations
Se former
Pour ceux qui désirent se former à Datadog, il existe un centre d’apprentissage gratuit disponible ici : https://learn.datadoghq.com/. Il dispose d’une dizaine de tutoriels qui couvrent une bonne partie des fonctionnalités évoquées ici. Datadog dispose également d’un essai gratuit de 14 jours : https://www.datadoghq.com/free-datadog-trial/. A noter que si vous souhaitez tester Datadog au sein d’une entreprise, n’hésitez pas à contacter un de leurs commerciaux, vous pourrez augmenter la durée de l’offre gratuite !
Bien sûr, je ne peux que vous conseiller de vous référer à la documentation afin de vous familiariser d’avantage avec les principes évoqués dans cet article où je ne suis pas rentré dans le déta
il.
Conclusion
Datadog est à mon avis une solution complète, et simple à utiliser qui permet de faire de la supervision de pointe que l’on soit sur un environnement Cloud ou on premise. Son fonctionnement en mode SaaS vous permettra d’avoir moins de charge sur vos équipes opérationnelles, enfin sa facturation à la carte vous permet de démarrer petit et d’ajouter des services au fil du temps.
Datadog vous permet de centraliser la gestion des métriques, logs & traces au sein d’une seule solution, d’y trouver des corrélations pour identifier la cause d’un incident et d’y définir des SLO afin de mettre en place votre stratégie de SRE.
