

Historiser les données est un besoin relativement courant dans une application. Les données les plus importantes sont souvent les valeurs les plus récentes mais il peut être intéressant de tracer les modifications effectuées. De nombreux cas d'utilisation sont possibles :
- réaliser des reportings et indicateurs autour de ces données (Business Intelligence)
- aider à la résolution d’un bug applicatif et éventuellement permettre la correction de données liées à ce bug
- tracer des problèmes de sécurité comme des modifications frauduleuses
- informer l'utilisateur des différents changements intervenus sur ses données
Afin de mettre en place un système d’historisation des données, je vais vous présenter un outil simple à manipuler et compatible avec les applications Java utilisant Hibernate.
Hibernate Envers est un module de Hibernate Core permettant l’historisation de toutes les entités que l’on souhaite auditer. Il fonctionne avec un principe de révision, chaque modification des données amène à une révision persistée dans la base.
Par la suite, je vais me baser sur un projet simple pour présenter l’intégration de Hibernate Envers et les principales fonctionnalités qu’il propose.
Le modèle de données utilisé sera le suivant :
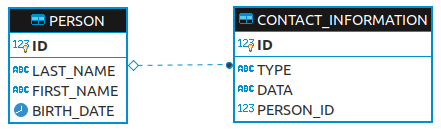
La structure est très simple : on a une entité PERSON avec très peu de champs qui possède une liste qui référence la table CONTACT_INFORMATION. Cette structure nous permettra d’observer les différents comportements de Hibernate Envers lors des modifications.
Configuration
Pour mettre en place Envers, il faudra ajouter la dépendance suivante dans notre fichier de configuration Maven (pour d’autres outils de gestion, voir ce lien). La version de cette dépendance sera la même que la version de Hibernate, le minimum requis est la 3.5.0.
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-envers</artifactId>
<version>${hibernate.version}</version>
</dependency>
Ensuite, il suffit d’ajouter l’annotation @Audited sur les entités ou les champs des entités dont on souhaite tracer les modifications.
import org.hibernate.envers.Audited;
import java.io.Serializable;
import java.time.Instant;
import java.util.HashSet;
import java.util.Set;
/**
* A Person.
*/
@Entity
@Table(name = "person")
@Audited(withModifiedFlag = true)
public class Person implements Serializable
En mettant @Audited sur la déclaration de la classe, cela permet d’historiser tous les champs de l’entité. Si l’on ne souhaite auditer qu’une partie des champs, Hibernate Envers permet l’ajout de l’annotation @Audited uniquement sur les champs qui nous intéressent. Il est aussi possible d’exclure des champs en ajoutant @Audited sur la déclaration de la classe puis en appliquant l’annotation @NotAudited sur les champs qu’on ne veut pas historiser. Lors d’une modification qui ne concerne que les champs annotés @NotAudited, celle-ci ne fera pas d’objet de révision.
Dans cet exemple, j’ai activé l’option withModifiedFlag pour pouvoir obtenir plus d’informations sur les données historisées. Elle permet de tracer quels champs ont été modifiés lors de la révision.
Les tables contenant l’historique : table d’audit
Une fois les annotations mises en place, il faudra créer les tables d’audit dans lesquelles Hibernate Envers va insérer des données. La création peut se faire soit en laissant Hibernate gérer la base de données, soit en créant nous-même les tables via des scripts SQL.
Pour permettre à Hibernate de modifier la base de données, il faudra utiliser la propriété hibernate.ddl-auto. Cela se traduit par la configuration suivante dans application.yml :
spring:
jpa:
hibernate:
ddl-auto: update
L’autre façon de créer ces tables est d’utiliser un outil de migration de base de données. C’est la solution que je recommande en production. Avec Liquibase, il est possible de générer un changelog qui correspond à l’écart entre les entités JPA et la base de données locale : mvn liquibase:diff. Cette commande nécessite la configuration du plugin liquibase-maven-plugin dans le pom.xml.
Voici les tables que Hibernate Envers utilise pour effectuer son historisation :
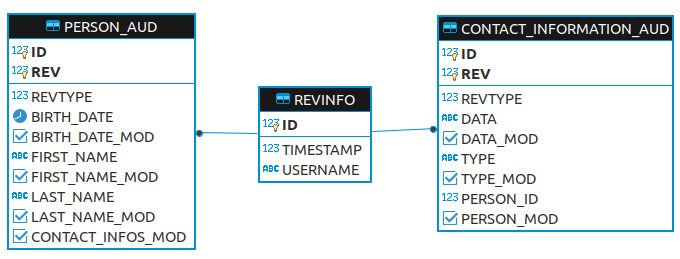
La table REVINFO contient les données comme les numéros de révision ID et les dates de révision TIMESTAMP. Ici, j’ai modifié la table pour qu’elle enregistre une information en plus : le nom de l’utilisateur qui a effectué la modification : USERNAME. Sans modification, les champs par défaut sont REV pour le numéro de révision et REVTSTMP pour la date de révision.
Pour chaque entité annotée @Audited, une table avec le même nom que l’entité et suffixée _AUD est créée. En plus des colonnes correspondant aux champs de l’entité, Hibernate Envers ajoute d’autres colonnes dans ces tables :
- La clé primaire est maintenant une composition de la clé de l’entité modifiée et de la clé de la révision (clé primaire de la table
REVINFO). - Dû à l’option
withModifiedFlag, chaque champs audité sera accompagné d’un champs suffixé_MODde type booléen pour indiquer si le champ a été modifié ou non lors de la révision. - Une colonne
REVTYPEde type numérique est ajoutée pour identifier quelle a été l’action de cette révision : création, modification ou suppression.
Les données des tables d’audit


À chaque modification sur l’entité auditée, Hibernate Envers va insérer une ligne de révision dans la table REVINFO et une ligne contenant les nouvelles données de l’entité dans la table d’audit correspondante.
Dans la table PERSON_AUD, on peut observer que la colonne REVTYPE a trois états 0, 1 et 2 correspondant respectivement aux trois actions d’écriture en base : création, modification et suppression. Lors de la suppression, tous les champs sont enregistrés à NULL sauf l’identifiant de l’entité. Si on veut retrouver les données supprimées, il suffit de requêter sur la révision précédente.
Une autre chose intéressante à noter est que les modifications sur les listes référençant d’autres tables sont aussi tracées. Dans l’exemple lors d’un ajout (révision numéro 3) ou d‘une suppression (révision numéro 5) dans la liste, la colonne CONTACT_INFOS_MOD est à TRUE. Mais aucune donnée modifiée n’est enregistrée dans la table PERSON_AUD puisqu’il n’existe pas de colonne CONTACT_INFOS correspondante. En effet, lors d’une telle manipulation, Hibernate Envers insère la révision dans les trois tables concernées :
REVINFOpour le numéro de révision et la date de révisionPERSON_AUDpour l’information de modification de listeCONTACT_INFORMATION_AUDpour l’identifiant de la commande associée

D’après les figures 4 et 5, seuls les ajouts et suppressions dans la liste sont audités dans la table PERSON_AUD, les modifications sur l’entité associée ne sont pas considérées comme une modification sur la liste (révision numéro 4 absent dans la table PERSON_AUD).
Quelques contraintes
Les modifications directes sur la base de données sont bien évidemment non tracées mais elles peuvent provoquer des incohérences entre les révisions. Néanmoins cela ne perturbera pas le bon fonctionnement de Hibernate Envers. Lors d’une modification d’entité, Envers va tout simplement insérer des lignes dans la table REVINFO et dans la table d’audit de l’entité. Par observation, les flags qui indiquent qu’un champs a été modifié sont calculés sur la différence entre l’entité de la base et l’entité à sauvegarder. En respectant les bonnes pratiques, on ne devrait pas modifier la base de donnée “à la main”. En conséquence, cette contrainte ne devrait pas être un souci.
Une autre contrainte est que l’historisation va prendre beaucoup d’espace dans la base, la taille des tables d’audit deviendra énorme au fil du temps car on ajoute continuellement des données sans jamais en supprimer. De plus, il faudra bien ajouter des indexes sur ces tables d’audit si on veut requêter efficacement dessus, ce qui signifie encore des espaces à allouer. Cette contrainte est un problème incontournable lorsqu’on pratique de l’historisation de données.
Pour aller plus loin
Hibernate Envers offre pas mal d’options à l’utilisateur et donne la possibilité de réaliser des customisations. Dans l’exemple fourni, j’ai activé l’option de flag pour les champs modifiés et j’ai customisé la table REVINFO pour insérer plus d’informations. Il est également possible de modifier le suffixe ou le préfixe du nom des tables. La liste complète des options est disponible dans la documentation.
Dans cette liste, une configuration m’a semblé plutôt intéressante : lors d’une suppression, au lieu de sauvegarder des valeurs NULL on peut sauvegarder les données de l’entité supprimée dans la révision. Cette configuration peut être très utile pour les projets qui intègrent Hibernate Envers à mi-chemin puisqu’ils n’ont pas les révisions complètes des entités.
Les tables d’audit peuvent être examinées en utilisant des requêtes SQL. Hibernate Envers propose lui-même une façon simple de requêter ses tables en utilisant AuditReader. Les requêtes sont déjà implémentées en tant que méthodes de la classe. Cet outil peut être intéressant quand on veut développer une interface front permettant l’exploitation des données historisées.
Conclusion
La mise en place de Hibernate Envers pour répondre à un besoin d’historisation de données est tout aussi intéressante pour les projets en cours de développement que les projets déjà en production. La mise en place de cet outil est relativement facile et le résultat correspond bien au besoin. Sans l’utilisation de cet outil, on aurait besoin de concevoir nous-même tout un système d’historisation et d’implémenter des méthodes complexes pour détecter les champs modifiés d’une entité.
Avec Hibernate Envers, l’historique est clair et les révisions d’une entité sont facilement récupérables. La contrainte d’occupation d’espace supplémentaire pour la base de données est commune à n’importe quelle autre solution d’historisation de données.
Pour les applications nécessitant de l’audit, Envers est un très bon candidat grâce à sa simplicité de mise en place dans une application utilisant Hibernate. La richesse de son paramétrage et la disponibilité d’une API de requêtage permettent de s’adapter à un ensemble assez large de besoins. Tous ces atouts en font donc un excellent outil pour les besoins d’historisation des données.