

Ce post fait suite à un webinar récent disponible sur le site Ippon - https://fr.ippon.tech/success-stories/innovate/prismea - qui présente les enjeux business et l'architecture du projet. Ce post a pour but de soulever le capot et vous expliquer les détails du projet côté code.
Je travaille depuis 9 mois sur le développement de la néobanque Prismea. Les challenges techniques sont omniprésents, tant en terme de sécurité, de robustesse, de disponibilité que de scalabilité.
J’ai énormément de choses à dire sur l’ensemble de cet écosystème applicatif après 9 mois de développements. Je vous propose dans cet article de vous donner un tour d’horizon des méthodes, technologies et outils utilisés pour réaliser l’ensemble du socle applicatif de Prismea. Nous évoquerons les différentes briques de l’infrastructure de Prismea, les briques techniques correspondantes (backend et frontend), leur cycle de vie et leurs déploiements sous la forme de microservices, le tout saupoudré d'une bonne dose de Software Craftsmanship.
Les buts de cet article sont de vous donner une vision technique de Prismea et de vous partager quelques astuces. Ce n’est qu'une vue de haut niveau, des pistes pour faire des recherches mais il ne contient pas forcément tous les détails suffisants pour faire les choses directement. Pour cela, je donnerai des liens vers d’autres ressources pour continuer à approfondir les différents sujets évoqués.
Présentation de l’architecture logicielle
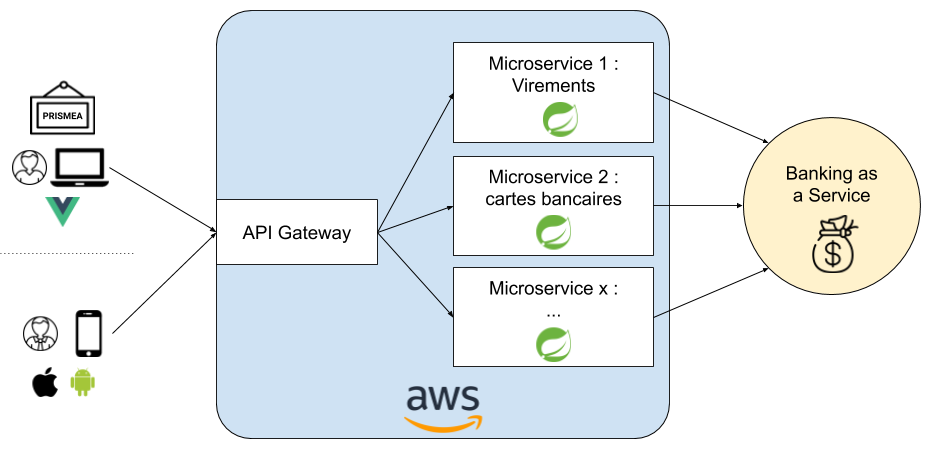
Prismea est une néobanque à destination des pros. Ainsi, elle souhaite accompagner ses entreprises clientes en leur fournissant un ensemble de services, notamment bancaires et orientés trésorerie, le tout depuis leur smartphone. Pour plus de détails, je vous propose de consulter le site officiel.
Voici une présentation succincte des différentes briques logicielles permettant de répondre aux besoins de Prismea :
- Backend proposant des APIs REST à destination des différents frontends : principalement la gestion du compte client et le dialogue avec le partenaire de Banking-as-a-Service pour toutes les opérations bancaires : création d’un compte client, envoi de virements SEPA, demande de carte bleue, etc. ;
- Frontends sous forme d’application web : il s’agit aujourd’hui principalement d’un backoffice pour les opérateurs de Prismea (gestion des clients et de leurs comptes), et demain d’une future application web pour les clients de la néobanque ;
- Frontend mobile pour des applications iOS et Android ;
- Plateformes data ;
- Site vitrine.
Je ne parlerai dans cet article que des 2 premiers points car je ne travaille pas sur les 3 suivants.
Software craftsmanship
Nous avons eu la chance sur ce projet d’accompagner Prismea avec une équipe fervente du Software Craftsmanship. J'ai démarré mon accompagnement et la création du socle technique de Prismea avec plusieurs piliers des communautés software craftsmanship d’Ippon Technologies et de Lyon.
Clean code
Le premier sujet lorsqu’on parle du Software Craftsmanship est souvent le clean code et c’est pour moi un des éléments les plus importants de notre métier de développeur. Cela passe par différentes pratiques comme l’écriture d’un code simple et lisible, des revues de code systématiques et minutieuses, la volonté de toujours livrer un code robuste, testable et testé.
Le clean code passe aussi par des outils comme des linters de code, des contrôles sur la qualité du code (par exemple Sonarqube), des contrôles sur les dépendances utilisées et leurs éventuelles failles.
DDD
Le Domain Driven Design nous a permis de centrer notre code autour du métier de Prismea en faisant ressortir les différentes notions métiers. Pour cela, nous avons créé, en collaboration avec les experts métier, un langage utilisé par toute l’entreprise : le langage omniprésent (ou ubiquitous language). Pour nous aider dans cette démarche, nous avons réalisé au début de notre accompagnement un atelier d’EventStorming. Pour comprendre son fonctionnement et ses enjeux, je vous propose de lire l’article Un EventStorming avec Alberto Brandolini.
TDD & couverture de code
Comme nous étions fortement convaincus par l’utilisation de la pratique, nous avons pu travailler dès le départ en faisant du Test Driven Development. Toute l’équipe n’avait pas la même expertise sur cette méthode qui peut paraître non naturelle. Mais après un accompagnement, tout le monde a réussi à progresser et à l’utiliser au quotidien.
La couverture de code satisfaisante (entre 98% et 100% selon les projets) vient naturellement avec cette méthode. Elle nous sert ensuite d’indicateur interne à l’équipe et est utilisée comme outil de détection de problèmes inhérents à la conception du code.
Si vous voulez en savoir plus sur ce sujet, je vous propose de lire l’article 80 ou 90% de couverture de tests pour un nouveau projet ?
Pyramide des tests
Prismea possédera à terme un socle applicatif conséquent. L’utilisation du TDD apporte beaucoup de tests. Il est donc très important de bien respecter la pyramide des tests et la granularité de chacune des étapes de la pyramide : utilisation des tests unitaires pour faire émerger le design, des tests d’intégration pour vérifier que notre code s’adapte bien aux Frameworks (par exemple Spring, Hibernate), des tests End-to-End pour vérifier la non régression de la chaîne complète, etc.
Si la pyramide des tests n’est pas respectée, on risque de se retrouver avec un coût de maintenance trop élevé. En effet, plus on se rapproche du haut de la pyramide, plus les tests vont être coûteux (à développer, à jouer) et plus le debug sera compliqué (on ne saura pas exactement d’où provient un problème).
Katas
Afin d’aider chacun à prendre ses marques sur des méthodes comme le TDD, nous avons mis en place des katas pour toute l’équipe de développement. Nous nous réunissons régulièrement entre développeurs backend, frontend, data pour travailler sur des petits exercices de code. Ce sont des moments très appréciés par toute l’équipe.
Nous avions arrêté en début de confinement car nous pensions que ce serait trop difficile à organiser à distance. Cependant, nous avons trouvé une organisation efficace avec l’outil de communication Discord. Au début et à la fin de l’atelier, nous communiquons tous ensemble sur un channel global. Pendant l’atelier, chaque binôme se met sur un channel dédié et l’animateur peut passer dans chacun des groupes pour animer le kata.
Pour tous ces sujets autour du software craftsmanship, n’hésitez pas à lire les autres articles du blog qui iront beaucoup plus dans le détail. N’hésitez pas, non plus, à vous rapprocher des différentes communautés autour du Software Craftsmanship, par exemple à Lyon.
Backend
Technologies principales
Nous utilisons comme principales technologies Java 11 (j’espère bientôt Java 14) avec Spring Boot 2 et Maven. Nous nous reposons ensuite sur l’ensemble des outils AWS pour la base de données, le système de messagerie, l’authentification etc.
JHipster
Je ne vais pas présenter de nouveau JHipster sur ce blog, vous trouverez de nombreux articles beaucoup plus détaillés.
Nous avons utilisé JHipster pour bootstrapper très rapidement notre backend. En 2 jours, nous avions déjà une application Spring Boot complète, une première CI/CD fonctionnelle avec GitLab CI et des premières fonctionnalités comme la gestion des documents stockés sur S3 (service de stockage d'objet AWS).
Avec JHipster, nous avons opté pour une génération d’un backend ET d’un frontend, ce dernier nous permettant de bénéficier d’une documentation Swagger et d’un moyen de se logger à Cognito (système d’authentification AWS).
TDD
Le TDD est vraiment facile à utiliser grâce aux outils classiques côté backend : JUnit (dans sa version 5) pour les tests unitaires, Spring Boot Test avec Testcontainers et localstack pour les tests d’intégrations.
Architecture hexagonale
Nous avons opté pour une architecture hexagonale : une architecture constituée de ports et d’adapters complétée d’une couche d’application gérant l’orchestration entre l’infrastructure (primaire et secondaire) et le domaine. Voici un schéma de ce à quoi cette architecture peut ressembler :
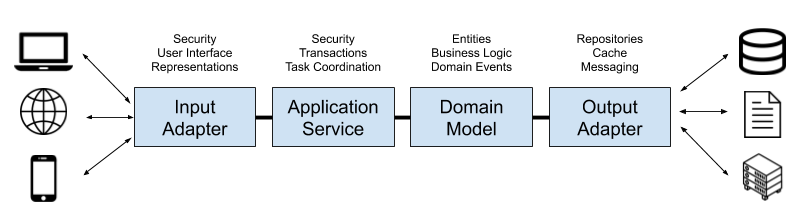
Cette architecture peut être utilisée au sein d’une application utilisant le DDD, mais ce n’est pas obligatoire. Vous pouvez découvrir cette méthode en lisant cet article.
Cette architecture engendre un coût non négligeable, principalement lors de sa mise en place et lorsqu’un nouveau développeur arrive dans l’équipe. Elle permet cependant un découpage très propre du code et une grande maintenabilité. D’ailleurs, chez Prismea, l’utilisation de cette architecture a été très appréciée à plusieurs reprises : suite à des évolutions significatives des spécifications fonctionnelles (c’est indispensable pour une startup), ou lors de changements techniques importants comme le remplacement du système de vérification d’identité.
Prettier Java
Dès le début, nous avons commencé à utiliser le plugin Java de Prettier pour formater l’ensemble de notre code backend. C’est quelque chose que nous avons plutôt l’habitude de voir sur les applications frontend. Pourtant, l’utiliser sur un projet Java fonctionne vraiment bien : le même formatage pour tous les IDE utilisés (notamment celui d'un collègue qui reste borné sur son utilisation d'Eclipse !), pas d’extrait de code lié au formatage qui vient polluer les revues de code.
Je ne saurais pas m’en passer sur mes prochains projets.
Gestion des autorisations
Pour gérer ce que peut faire un utilisateur dans notre application backend, nous avons fait le choix d’avoir une approche autour d’un système d’autorisations en plus des simples rôles. Chaque utilisateur connecté pourra effectuer certaines actions mais pas d’autres. Par exemple, l’utilisateur pourra demander des informations sur son compte mais n’aura pas accès aux données d’un autre compte. Les utilisateurs du back-office auront eux plus de droits que les utilisateurs lambda.
Pour ne pas polluer le code lié aux différents traitements métier, nous avons préféré sortir ce code concernant les autorisations dans du code dédié.
Pour en savoir plus sur cette technique, je vous invite à lire l’article Une gestion des Authorizations sur mesure avec Spring.
Astuces Java pour du code métier
En lien avec le DDD, nous portons une attention toute particulière sur le code de notre domaine métier.
Pour nous aider, nous avons utilisé le principe des builders Java afin de nous assurer de la cohérence de nos attributs : chaque objet est construit seulement s’il respecte toutes les conditions métiers nécessaires (attribut requis, attribut obligatoirement positif, ...). Pour en savoir plus, je vous invite à lire cet article beaucoup plus détaillé : Les Builders dans tous leurs états.
Toujours pour assurer la cohérence de nos objets du domaine, nous avons mis en place l’utilisation des Optional pour tous les attributs non requis de nos objets. Ainsi, cela nous force à toujours traiter le cas où l’attribut ne serait pas renseigné. Le corollaire à cela est que nous savons que les autres attributs sont forcément présents et nous n’avons jamais besoin de faire de vérification de présence. Quand ils existent, nous favorisons cependant l’utilisation des types primitifs : boolean plutôt que Optional<Boolean>.
Je recommande vivement l’utilisation de ces 2 patterns et je vous propose d’aller plus loin sur ce sujet en lisant l’article Des Objets, pas des Data Classes.
Tests End-to-End
Nous avons une suite de tests End-to-End qui nous permet de tester à chaque déploiement les fonctionnalités principales du backend de Prismea : création d’un compte chez Prismea, création d’un compte en banque, virement vers un bénéficiaire, paiement par carte... Le but est de s’assurer que l’ensemble des services essentiels fonctionnent et qu’il n’y a aucune régression.
Pour cela, nous avons utilisé un outil peu répandu dans le monde backend : Jest (d’habitude réservé aux tests unitaires dans les projets frontend). Cet outil est parfait pour réaliser des tests End-to-End sur une API : nous appelons les différents endpoints de notre backend avec axios et nous faisons des assertions sur les données retournées par notre application.
L’ensemble est exécuté avec NodeJS, le tout dans un conteneur Docker sur notre environnement de CI. Le code de ces tests est dans un repository Git à part. À chaque modification de code dans un de nos microservices, l’ensemble de tous les tests End-To-End est rejoué. Cela augmente notre confiance sur l'absence de régressions lors d'une mise à jour sur un ensemble de fonctionnalités essentielles.
Lorsqu’on souhaite automatiser l’ensemble des fonctionnalités d’une néobanque, on rencontre parfois des obstacles. Comment se connecter au backend ? Comment simuler des mouvements bancaires comme un paiement par carte bleue ? Comment tester une réception d’emails ?
Tout n’est pas toujours testable, il faut donc se rapprocher au maximum de la réalité, en acceptant qu’un décalage puisse apparaître (des tests manuels supplémentaires peuvent être envisagés).
Je n’ai malheureusement pas de ressource à vous fournir donnant d’avantage de détails sur l’utilisation de Jest pour des tests End-to-End. Je m’aperçois qu’un article dédié serait pourtant très intéressant. Peut-être l’occasion pour moi d’écrire bientôt un nouvel article ?
Frontend
Le frontend représente pour nous l’application back-office accessible par les collaborateurs Prismea. La future application web à destination des clients de Prismea utilisera les mêmes concepts et technologies.
Technologies principales
Nous avons opté pour un développement avec Vue.js. Nous avons choisi d’utiliser TypeScript plutôt que JavaScript, choix qui nous paraît important pour la robustesse du code (grâce au typage fort, à l’approche orientée objets et aux vérifications faites au moment de la compilation). Nous avons choisi comme moteur de template Pug. Pour découvrir son fonctionnement, je vous invite à lire l’article Introduction à Pug.
Tikui & atomic design
Le style de nos applications web est déporté dans une Pattern Library. Le but est d’avoir un style commun à l’ensemble de nos applications et de pouvoir ainsi faire évoluer facilement notre charte graphique sur l’ensemble des applications. Pour cela, nous avons utilisé Tikui, un projet Open Source que nous avons initié il y a quelques mois. Afin de comprendre comment cela peut être mis en place, je vous propose l’article Déployer son identité graphique.
Afin de faciliter l’organisation et la maintenabilité de notre style graphique, nous utilisons la méthode de l’Atomic Design. Pour approfondir cela, je vous propose de lire l’article Atomic Design dans la pratique.
ESLint & Prettier
Comme évoqué dans la partie backend, nous favorisons la consistance dans le formatage du code avec ici ESLint couplé à Prettier. Le but est d’avoir un code homogène sur l’ensemble de notre base de code.
Jest
Pour nos tests unitaires, nous utilisons Jest. Nous nous servons des tests unitaires pour faire émerger le design (plutôt la partie TypeScript).
J’ai souvent le sentiment que les tests unitaires, et plus généralement le TDD, sont boudés dans les projets frontend. C’est vraiment dommage car c’est tout à fait possible, et les gains sont les mêmes que pour les projets backend. D’ailleurs, grâce au TDD, notre taux de couverture de code côté frontend est de 100% depuis le début du projet.
Pour lancer les tests en continu (et faciliter le TDD), il est possible d’utiliser son IDE (fonction auto-toggle dans IntelliJ) ou bien la fonction “watch” proposée par Jest.
Cypress
En plus des tests unitaires, nous utilisons Cypress pour tester l’intégration avec Vue.js : nous testons le fonctionnement des éléments de la page (boutons, formulaires, ...), les appels au backend etc.
Nous avons opté pour une configuration en tests de composants : le backend est “mocké” pour ne s’intéresser qu’à notre brique frontend. Il n’est pas exclu qu’un jour on vienne ajouter à cela des tests End-to-End, qui feraient des appels réels au backend plutôt que de le mocker.
DDD
Comme pour le backend, nous utilisons le DDD pour nous centrer autour de notre domaine métier : le code du domaine est codé en TypeScript pur, sans utilisation de bibliothèque ou autre brique technique. Nous avons également une architecture hexagonale sur notre code. Je n’ai pas de ressource à vous proposer pour cette fois, peut-être là aussi l’objet d’un prochain article ?
Microservices
Chez Prismea, il existe une vraie volonté de s’orienter vers une architecture microservice. Nous le savons, avoir une architecture de ce type a un coût.
Du monolithe vers des microservices
Malgré l’envie initiale de se lancer dans une architecture microservices, nous avons proposé de commencer par une application monolithique pour ensuite s’orienter vers un découpage en microservices.
Le but était de se concentrer d’abord sur le métier de Prismea et d’avoir un time to market le plus réduit possible.
Bounded contexts
Pour être sûr de réussir cette future transition, nous avons tout de suite découpé notre code en briques métier. Nous avons ainsi découvert et peaufiné les différents bounded contexts de Prismea qui sont la base du découpage en microservices.
Voici un article qui explique notre démarche beaucoup plus en détails : Accio Bounded Contexts.
Outillage
Il est important d’être prêt avant de se lancer dans le monde des microservices. Découper son code et ses applications nécessite beaucoup de prérequis (tests & déploiements automatisés, une forte culture DevOps / cloud, des équipes centrées autour de features, ...), de nouvelles briques techniques (monitoring, logs centralisés, discussions synchrones et asynchrones entre microservices, ...). Pour ça, je ne peux que vous recommander de bien vous former avant de partir dans l’inconnu.
Duplication de code
Lors du découpage d’un monolithe en microservices, nous nous retrouvons avec du code en commun que nous voulons retrouver dans plusieurs microservices.
Il y a dans ce cas plusieurs possibilités. Nous pouvons par exemple copier/coller le même code sur les différents microservices (chacun évoluera librement) ou alors créer des bibliothèques communes, on parle dans ce cas de Shared Kernel.
Ce choix peut se faire au cas par cas : est-ce que le code évoluera forcément de la même façon des 2 côtés ? Quelle est la taille du code dupliqué ? Est-ce que le code dupliqué concerne uniquement les tests ?
Il existe de nombreux autres patterns pour répondre à cette problématique. Je vous invite à regarder le contenu de ce site.
Pour la création de nos bibliothèques communes, nous avons aujourd’hui deux types :
- du code Java (uniquement) pour le code représentant le modèle métier ;
- des Spring Boot starters pour des fonctionnalités plus techniques communes à nos microservices (authentification, sécurité, gestion des erreurs...).
DevOps
Nous avons tâché dès le début du projet à instaurer une culture DevOps. Ce que nous entendons par là est résumé dans l’article To DevOps or not to DevOps.
Culture DevOps & automatisation
Grâce à des personnes dans l’équipe plutôt orientées “Dev” et d’autres plutôt “Ops”, et tous étant sensibilisés à la culture DevOps, nous avons pu mettre des choses en place pour faciliter le développement, le déploiement et le monitoring de nos applications.
Une règle d’or pour que cela fonctionne : toujours automatiser le plus possible et ne pas compter sur les tâches manuelles.
CI/CD
Afin d’augmenter la fréquence et la qualité des distributions de nos applications, nous avons opté pour une CI/CD complète et bien sûr automatisée.
CI/CD de développement : déploiement de stacks éphémères
La première partie de notre CI/CD concerne le développement de nouvelles fonctionnalités. À chaque nouveau commit sur une branche Git liée à une nouvelle fonctionnalité, un pipeline va se lancer. Cela peut être résumé par l’ensemble de ces étapes :
- différentes vérifications liées au code : vulnérabilité dans les dépendances utilisées, formatage du code, qualité du code ;
- lancement des différents tests automatisés ;
- déploiement complet du microservice sur notre infrastructure AWS : cela permet à l’auteur du code (et les relecteurs) de faire des tests complémentaires.

CI/CD de production : le déploiement continu en moins de 30 minutes
La deuxième partie de notre CI/CD concerne la mise en production. Dès qu’un code est accepté par l’équipe, il est mergé sur la branche Git master. Un nouveau pipeline va alors se lancer, avec pour étapes :
- différentes vérifications liées au code (identique à la CI/CD de développement)
- lancement des différents tests automatisés (identique à la CI/CD de développement)
- déploiement complet du microservice sur notre infrastructure AWS (identique à la CI/CD de développement) : notre environnement
masterfait donc office d’environnement d’intégration : il est tout le temps aligné sur la production - lancement des tests End-to-End sur l’environnement
masterqui vient d’être déployé - déploiement en production
Bien sûr, si l’une de ces étapes échoue, on arrête immédiatement. Dans le cas contraire, la mise en production est réalisée. Les tests automatisés sont donc ici cruciaux : ce sont eux qui assurent le bon fonctionnement de la plateforme.

Outils
Pour réaliser toute cette plateforme de CI/CD, voici différents outils que nous utilisons :
- GitLab : gestion du code, des spécifications fonctionnelles, des revues de codes ;
- GitLab CI : lancement de pipelines, création d’environnements pour chaque nouveau code ;
- Terraform : gestion du cycle de vie de l’infrastructure AWS, le but étant d’automatiser l’ensemble des opérations de création, de mise à jour et de suppression ;
- AWS et l’ensemble de ses services : le plus possible des services managés ;
- Datadog : observabilité des applications (logs et métriques).
Conclusion
Cet article donne un aperçu de ce qu’est le socle applicatif de Prismea : un ensemble de technologies passionnantes et à l’état de l’art, une recherche de méthodes et de pratiques efficaces, fortement inspirées du Software Craftsmanship, une volonté d’automatiser au maximum. Le tout dans un environnement complexe : une néobanque proposant beaucoup de services à forte valeur ajoutée.
Évoluer dans un environnement comme celui-là est challengeant et passionnant. Merci à Prismea pour leur confiance.
