
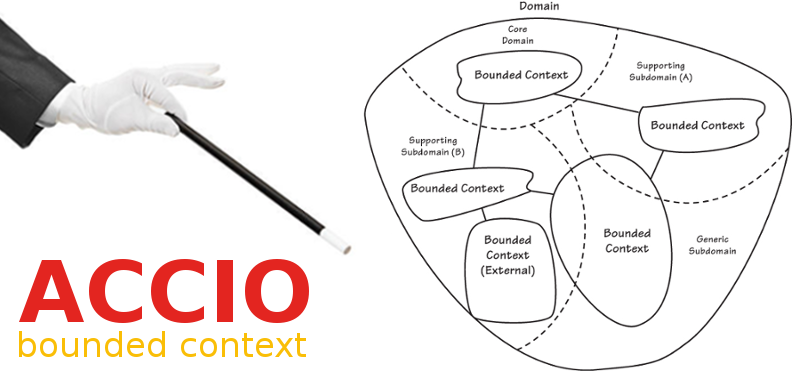
Ça y est, vous avez décidé de faire des microservices. Pour partir sur de bonnes bases vous avez lu l'excellent Building Microservices (de Sam Newman). Vous avez compris, dès les premières pages, que vous ne pourriez pas échapper aux deux lectures réglementaires du Big Blue Book (de Eric Evans) avec, bien entendu, une lecture du Big Red Book (de Vaughn Vernon). Malgré tout ce temps passé, toutes ces connaissances acquises, vous n’arrivez toujours pas à trouver des Bounded Context dans vos domaines métier ? Toutes les invocations à l’esprit de Martin Fowler et le visionnage de ces saintes conférences n’y font rien ?
Je vais lister ici quelques méthodes qui vous aideront à trouver ces satanés blocs qui sont tellement essentiels à la création de microservices dignes de ce nom. Malheureusement, rien de miraculeux, rien d’error-free ! Juste quelques pistes, que l’on peut suivre en parallèle pour, peut-être, aller dans la bonne direction.
Mais pourquoi est-ce si important ?
Avant de se lancer dans une description du comment, essayons de savoir pourquoi il est essentiel d’avoir de vrais Bounded Context pour faire des microservices. En effet, si le périmètre de vos services est mal défini, vous ne pourrez pas :
- Construire et livrer unitairement vos services ; il faudra systématiquement construire et livrer les services liés entre eux à chaque modification d’un service de la chaîne de dépendances.
- Scaler (Up ou Down) unitairement vos services et avoir de vrais gains (financiers ou de performances) sans devoir le faire sur toute la chaîne de dépendances.
- Tester simplement vos services sans avoir à systématiquement démarrer les services de la chaîne de dépendances.
- Organiser des équipes pluridisciplinaires autonomes responsables de groupes de microservices.
En fait, vous perdez beaucoup des avantages des microservices et vous en gardez les défauts (davantage d’applications à déployer et à faire communiquer avec, potentiellement, plus d’erreurs).
Méthode 0 : Pas de microservices
Même si la définition d’un domaine en utilisant les principes du DDD présente bien d’autres avantages que celui de pouvoir faire des microservices, il est vrai que l’on cherche très souvent les Bounded Contexts dans ce but. Cependant, il existe bien des cas où les microservices ne devraient pas être une cible dans les premiers jours de la création de l’application, en voici quelques uns :
- Besoin de sortir très rapidement un premier produit.
- Manque de connaissance du domaine métier.
- Manque de maturité de l’équipe produit.
- Peu de charge / changements prévus, même à terme sur l’application (pour une application de gestion interne, par exemple).
Dans tous ces cas, il sera souvent bien plus rentable de concentrer ses efforts sur la création d’un monolithe bien conçu qu’à la mise en place d’une architecture complexe demandée par les microservices. Sur ce sujet vous pouvez lire le post de Christian Posta About when not to do microservices.
Si le besoin de passer à des microservices se fait ensuite sentir, il sera toujours possible de le faire mais vous aurez votre application fonctionnelle sur laquelle vous appuyer (que ce soit financièrement ou fonctionnellement). Vous aurez en plus appris énormément sur votre métier, bien plus simplement qu’avec des microservices, lors de la création de cette application.
Méthode 1 : Monolith first
Une première méthode, souvent décrite, est de commencer par faire un monolithe que l’on découpera ensuite. Pour que cette méthode soit la plus efficace possible il faut :
- Faire correctement le code en TDD (en n’oubliant surtout pas la phase de refactor et en faisant du refactor towards deeper insight). Le TDD restant le meilleur moyen d’avoir un réel découpage des responsabilités.
- Séparer les packages de son application par métiers (et non pas par responsabilités techniques comme on le voit bien trop souvent). Le but étant de faire un découpage en packages qui soit hautement cohérent et faiblement couplé, comme devront l’être nos microservices. Le but ici n’est pas encore de mettre en place un système d'événements (qui ne sera pas correctement utilisé) pour communiquer entre les packages mais simplement d’apprendre sur le découpage de notre métier sans avoir la complexité des communications réseau / asynchrones à gérer.
- Découper au mieux sa persistance autour de ces agrégats et éviter les liens entre agrégats dans la persistance.
Une fois cette première application développée et fonctionnelle un temps en production vous pourrez extraire des services dédiés un par un en prenant garde aux nouvelles communications qui vont résulter de ce découpage. En effet, multiplier les applications va vous obliger à faire communiquer ces applications, de préférence aux travers d'événements. Pensez à mettre en place différents patterns antifragiles pour la communication entre vos services (gestion des timeouts, gestion des retries, CircuitBreaker...) pour éviter de bien mauvaises surprises sur des choses qui fonctionnaient très bien sur le monolithe. La lecture de Release It (de Michael T. Nygard) peut être une très bonne idée !
Un autre point qui peut être problématique lors du découpage est la présence de nouveaux Bounded Contexts qui n’existent que dans la persistence (du fait du questionnement de cette persistance par plusieurs applications) de l’application monolithique. Dans ce cas il faut arriver à créer des services dédiés à ces nouveaux métiers.
Le principal défaut de cette méthode est que notre monolithe ne sera jamais découpé aussi bien qu’on le voudrait et qu’il y aura forcément une importante phase de refactoring en profondeur pour permettre un découpage. Il reste cependant bien plus simple (possible) de refactorer un monolith qu’un ensemble de microservices mal découpés.
Si vous trouvez que cette méthode est particulièrement inefficace car elle demande de faire plusieurs fois le travail, ne découpez pas le monolithe, gardez le tel quel. En effet, la charge de travail qu'entraîne une production avec un nombre important de microservices est sans commune mesure avec celle qu’implique le découpage d’une application existante. Si le découpage représente une charge de travail trop importante vous ne pourrez pas gérer vos services en production !
Pour aller plus loin sur cette méthode vous pouvez lire :
- L’article de Martin Fowler sur le monolith first
- L’article de Stefan Tilkov sur le site de Martin Folwer qui explique les risques de l’utilisation de cette méthode
- L’article de Sam Newman sur le sujet
- Low-risk Monolith to Microservice Evolution Part I Part 2 Part 3 de Christian Posta
Méthode 2 : Event storming
L’Event storming est une méthode inventée par Alberto Brandolini qui permet, au cours d’un atelier très simple de découvrir beaucoup de choses sur le domaine, parfois même les Bounded Contexts. Pour cet atelier vous aurez besoin :
- D’un périmètre suffisamment restreint et clairement défini à étudier (en ayant connaissance des parcours utilisateurs, des écrans...).
- D’un facilitateur qui connaît la méthode de l’event storming et le Domain Driven Design.
- Des développeurs (qui sont là pour poser des questions).
- Des experts du métier (qui sont là pour répondre aux questions).
- D’une salle avec un grand mur libre sur lequel on peut écrire (un très grand tableau où l’ on recouvre le mur de feuilles).
- De post-it de couleurs (orange, bleu, rose, jaune et une autre).
- Des stylos et marqueurs qui fonctionnent.
- Du scotch de masquage (pour les erreurs).
- De quelques heures de réelle disponibilité pour tous les acteurs.
L’atelier se déroule de la manière suivante :
- Le facilitateur présente rapidement la méthode en insistant sur le rôle de chacun (il n’existe pas de question stupide...).
- Le périmètre de l’atelier est clairement défini par l’organisateur ou le facilitateur. Il est important de choisir un périmètre suffisamment petit pour pouvoir être traité en une session.
- Tous les participants notent sur des post-it orange les événements du domaine qu’ils connaissent sur ce périmètre.
- Après ~15 minutes le facilitateur reprend tous les post-it et les dispose dans l’ordre logique des événements au mur avec l’aide de tous les participants. Il est possible d’avoir plusieurs lignes d'événements qui ne sont pas liées entre elles.
- Les participants trouvent alors ensemble ce qui déclenche des événements, cela peut être :
- Des commandes : si ce sont des actions faites par des utilisateurs, on les note sur des post-it bleus.
- Un système externe : que l’on note sur des post-it roses.
- Le temps : que l’on note sur des post-it d’une couleur encore disponible en dessinant un calendrier ou une horloge.
- Tout autre type d'événement : que l’on note sur des post-it de la même couleur que le temps (parce qu’on n’a pas forcément toute la collection...).
- Les participants essaient ensuite de regrouper les événements par écrans. Ce sont en fait nos aggregates que l’on note sur des post-it jaunes.
- Les participants essaient ensuite de définir les Bounded Contexts en fonction :
- Des différences de vocabulaire utilisé entre la définition des éléments apparemment semblables de deux aggregates.
- Les isolations qui sont naturellements apparues au mur et pendant les discussions. Les Bounded Contexts sont ensuite clairement dessinés au feutre sur le mur.
- À tout moment, il est possible d’ajouter ou de supprimer n’importe quel élément si tous les participants sont d’accord sur un changement de la vision initiale.
Cela vous semble trop simple ? Trop de magie ? Sincèrement, essayez !
La simplicité de cet atelier (dans son organisation ou son déroulement) est sans commune mesure avec la valeur qu’il va apporter à vos produits ! Même si vous ne trouvez pas les Bounded Contexts du premier coup, le partage de connaissance qui est fait en quelques heures en vaut largement le coût.
Le principal défaut de cette méthode est qu’elle ne permettra pas d’avoir une vision sans faille de votre domaine. Il faudra accepter de refactorer les applications lorsque l’on se rendra compte d’erreurs faites pendant l’atelier. Cependant, c’est un des principes de base du DDD : Refactoring towards deeper insight. Un autre défaut important est qu’elle demande une bonne connaissance du domaine métier et du DDD dans l’équipe dès les premiers jours du produit, ce qui est rarement le cas.
Méthode 3 : Fail Forward
C’est, je le crains, la fin de la magie. Le seul vrai moyen, malgré l’utilisation des méthodes précédentes, de trouver des Bounded Contexts qui soient réellement Bounded c’est :
- D’essayer (vraiment, en production).
- De se tromper (vraiment, ça ne doit pas être grave).
- De se rendre compte de son erreur (vraiment, et de l'assumer, ce n’est pas grave).
- De la corriger (vraiment, en faisant le refactoring pragmatique nécessaire pour faire apparaître les nouveaux contexts ou disparaître des contexts superflus. Dans ce cadre toujours garder en tête que l’effort doit être mis en priorité sur les Core Domain).
- De recommencer.
Est-ce que tout ça en vaut la peine ?
Des Bounded Contexts, c’est la possibilité pour vos équipes d’apporter de la valeur en production au rythme où elles travaillent (sans garder la valeur sur leur poste ou sur des environnements de recette) sans risquer des impacts sur d’autres parties du domaine. C’est la possibilité d’organiser son entreprise en entités indépendantes et autonomes.
Des microservices bien découpés en production, c’est la possibilité de bénéficier de toutes les promesses de cette architecture (scalabilité unitaire, adaptation des technologies, livraisons unitaires...).
Pour savoir si le jeu en vaut la chandelle, c’est maintenant à vous de faire preuve de pragmatisme. Il faut cependant garder en tête qu’une transformation vers les microservices peut échouer, dans ce cas il faut savoir dire stop !
Il faut aussi garder en tête la loi de Conway et penser que l’organisation des équipes devra refléter l’organisation des applications (que ce soit en termes de découpage ou en termes de canaux de communication privilégiés).
