

Les modèles de machine learning sont de plus en plus utilisés dans nos applications car ils permettent de réaliser des tâches qui, jusque-là, étaient complexes voire impossibles à résoudre à l’aide d’algorithmes classiques. Ils sont au coeur de l’innovation dans les entreprises car ils permettent d’apporter une valeur nouvelle aux données. Pourtant, le passage d’un PoC (Proof of Concept) à une intégration dans une application en production ne se réalise pas facilement. Ainsi, une bonne partie des projets de machine learning n’arrivent jamais en production.
Comme reporté par le Gartner, jusqu’en 2019, 85% des projets IA resteront en état d’alchimie, et un des rôles du data engineer est justement d’aider les data scientists dans cette mise en production.
Les applications utilisant du machine learning se font en deux phases. Dans cet article je m’intéresserai particulièrement à la deuxième phase :
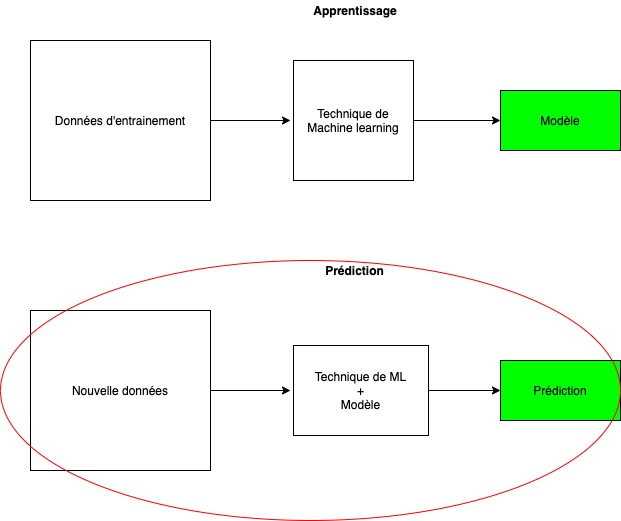
Quels choix pour l’infrastructure permettent l’application du modèle sur de nouvelles données ? Pourquoi ne pas utiliser des function as a service (FaaS) pour effectuer l'application du modèle ? Quelles en sont les limites ?
Dans un premier temps, je justifierai l’utilisation d’une telle infrastructure pour certains types d’applications. Dans un second temps, nous verrons comment mettre en place une telle infrastructure serverless avec une petite expérimentation : construire une fonction serverless dans AWS permettant la détection d'objets dans une photo (comme dans l’exemple ci-dessous par exemple), pour en exposer les limitations.

Du FaaS pour l’application de modèle ?
Un Data scientist est plus proche de la recherche, par conséquent son code n'est pas forcément adapté aux infrastructures de production.

Pour répondre à cette problématique, on utilise le plus souvent des orchestrateurs de conteneurs pour faire tourner le code dans des serveurs on-premise, ou bien même dans le cloud pour profiter de plus d'élasticité en fonction du besoin.
Ce choix est pertinent lors de l'entraînement car ce dernier peut se révéler long (plusieurs heures voire plusieurs jours). Cependant il l’est beaucoup moins pour la phase d’application du modèle. En effet, cette dernière est beaucoup plus rapide et peut être exercée de manière irrégulière pour certaines applications.
Les FaaS ou fonction serverless sont des fonctions qui permettent d'exécuter du code sans se préoccuper du provisionnement des serveurs et de ne payer que pour la durée d'exécution du code. Leur utilisation se révèle donc pertinente dans le cas de la phase d’application du modèle.
Passons maintenant à la pratique afin de découvrir les limites d’une telle infrastructure. Pour cette expérimentation je fais le choix d’utiliser le service de fonction serverless d’AWS : Lambda.
Expérimentation : choix de l’algorithme
Pour la détection d’objets, les modèles les plus efficaces sont les modèles de deep learning. Si vous n’avez aucune connaissance dans le domaine, je vous conseille de lire cette suite d’articles.
Pour un modèle de deep learning, le modèle sera constitué de l’ensemble des poids qui ont été ajustés sur le réseau de neurones. Il faut donc connaître la configuration du réseau (quelles sont les couches ou “layer” successives qui ont été appliquées) et les poids du modèle. Tous ces fichiers devront être accessibles pour mon code. Deux solutions s’offrent alors : ajouter les fichiers du modèle et de la configuration à l’archive du code de la Lambda ou alors aller le chercher systématiquement lorsqu’on en a besoin.
C’est la deuxième solution qu’il faut privilégier pour plusieurs raisons. Premièrement, la taille du code de la Lambda est limitée à 250 Mo (d’après la documentation). Deuxièmement, il serait intéressant de pouvoir changer de modèle à loisir et de le réentraîner sans avoir à redéployer le code.
Dans certains cas il sera plus intéressant de garder le modèle dans l’archive pour réduire les coûts et le temps de traitement. Mais il faudra alors utiliser un modèle assez léger pour respecter les limitations de taille de code de la Lambda.
Le but ici n’est pas de choisir absolument le tout dernier modèle en date mais un modèle qui a fait ses preuves dans la détection d’objets.
Après avoir parcouru plusieurs articles, je me frotte à une première limitation de la Lambda : le code de la Lambda (layer compris) ne doit pas dépasser la limite précédemment énoncée. Or dans la plupart des articles que je trouve, un nombre important de librairies python est utilisé pour les algorithmes de détections d’objets. Ces librairies sont lourdes car elles ne contiennent pas que le code d’application du modèle mais aussi celui d’entrainement du modèle et parfois même des modules de préparations des données.
Astuce : pour avoir une idée du poids des librairies dans votre environnement virtuel, utilisez la commande suivante (dans un terminal linux ou mac) :
pip show pip | grep -o 'Location.*' | cut -f2 -d: | { read LP; du -shc $LP; }
Finalement, je tombe sur l’article suivant qui n’utilise à priori qu’une seule librairie Python lourde pour appliquer le modèle : https://www.arunponnusamy.com/yolo-object-detection-opencv-python.html. Cette librairie est opencv, une bibliothèque graphique libre permettant le traitement d’images. La taille du module n’étant pas un problème, je décide, de suivre ce dernier. Le modèle utilisé s'appelle “YOLO” dont on peut récupérer la configuration et les poids du modèle ici.

Expérimentation : Implémentation de la Lambda
Tout ce qui a été réalisé en terme de code est disponible de manière libre sur le repository github suivant : https://github.com/tcastel-ippon/object-detection-serverless
Infrastructure
Voici l’infrastructure que nous allons mettre en place pour notre Lambda.
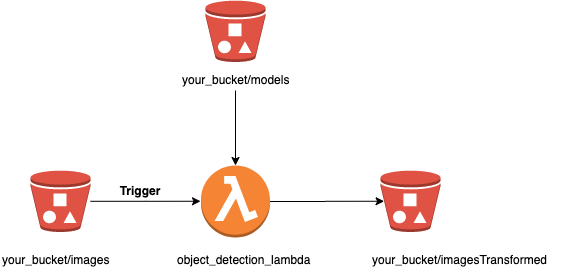
Le dépot d'une image sur notre compartiment de donnée (bucket) permet le déclenchement de notre fonction object_detection_lambda de manière evenementielle. Cette dernière récupère alors les fichiers de poids et de configuration du modèle afin de les appliquer grâce à l’algorithme. La fonction retourne alors l'image enrichie avec les labels des objets détectés, dans un autre dossier du compartiment de S3.
Image originale complétée par les objets détectés :

Mise en place du projet
Pour créer et déployer une infrastructure telle que présentée, avec une Lambda et des buckets S3, il est possible d’utiliser différents outils d’infrastructure as code (IaC) : Terraform, Cloudformation, ou encore Serverless Framework. Ce dernier est un framework qui permet de déployer rapidement des infrastructures serverless. Contrairement à Terraform, Serverless propose uniquement du code pour les services qui gravitent autour des fonctions serverless. Il est particulièrement adapté au déploiement d’architectures micro-services. Dans notre cas, on peut imaginer l’intégration de ce service dans une telle architecture.
Pour commencer un projet avec le provider cloud AWS et en Python :
serverless create --template aws-python3
Pour déployer la Lambda sur votre compte AWS il faudra au préalable configurer vos accès par programmation pour le framework serverless.
Dans le fichier serverless.yml, on peut voir la configuration de la Lambda. C’est ici que nous pouvons définir toute l’infrastructure qui y sera associée. Il est notamment possible d’y spécifier les triggers de la Lambda (le déclencheur ici S3), le runtime (langage et version utilisés), ainsi que le handler qui est la fonction invoquée lorsqu’un événement déclenche la Lambda. Il est donc important de garder une cohérence entre ce fichier de configuration et l’organisation du code. Dans mon cas, je décide d’appeler le module de la fonction lambda_function et le handler lambda_handler.
J’organise ensuite mon arborescence de la manière suivante :
object-detection-serverless/
├─ modules/
├─ object-detection
└─ Tests
├─ lambda_function.py
├─ serverless.yml/
└─ gitlab-ci.yml/
Le dossier module contient le module de détection de la Lambda qui est une refactorisation du code proposé dans l’article précédent afin de s’abstraire du traitement des données. Il n’a besoin pour fonctionner que des fichiers de poids et de configuration placés dans le bucket.
Le code de la fonction Lambda ne fait qu’un simple appel au module d’object-detection, fait la gestion d'événements et renvoie les données traitées.
Déploiement
Lorsque vous déployez votre code, il faut rendre disponibles les bibliothèques dont dépend votre code. Dans notre cas il n’y a que la librairie opencv qui est nécessaire. Les Lambdas bénéficient d’un système de “layer” ou couche en français. Ces couches peuvent être utilisées pour importer les librairies nécessaires au bon fonctionnement du code. Elles sont ensuite utilisables pour d'autres Lambdas, d’autres comptes et peuvent même être rendues publiques. Ceci permet aussi de restreindre la taille du code de base de votre lambda et par conséquent d’afficher ce code dans votre console AWS, ce qui permet de faciliter un débogage lors de l’intégration.
Une méthode possible est d’utiliser une layer partagée par un membre de la communauté open source. Ce dernier peut avoir partagé la référence de ces layers dans un github. Dans le cadre d’un MVP, il est tout à fait possible d’utiliser ces arn pour gagner du temps. Pour cette expérimentation j’ai par exemple utilisé les layers publiés par Keith Rozario dans son projet open source KLayers.
Il est cependant préférable dans l’industrialisation de la solution de mettre en place une construction des layers from scratch. Il faut alors prendre en compte que certaines librairies utilisent des fonctions natives de l’OS, par conséquent le build de la layer doit se faire dans l’environnement d'exécution du code, ici pour une Lambda en python c’est une AMI Linux ou AMI Linux 2 selon le runtime (voir la documentation). Plusieurs solutions sont alors possibles : l’utilisation d’une VM ou d’un docker lors de la création du package.
Attention : Si vous déployez vos Lambdas ou vos layer(s) à la main il se peut que vous soyez bloqués par une des limites de la Lambda. L’archive (zip) de la Lambda que vous déployez ne doit pas dépasser 50 Mo, comme spécifié dans la documentation.
Sachez que ceci est une “soft limit”, la seule “hard limit” concerne la taille du code dézippé qui est de 250 Mo. Voici un article vous indiquant une des façons de contourner cette “soft limit” avec un code compressé supérieur à 50 Mo.

Pour rappel, le code de cette expérimentation est disponible sur le github suivant : https://github.com/tcastel-ippon/object-detection-serverless
Conclusion
Au travers de mes missions, j’ai eu l’occasion de travailler sur la mise en place du service Fargate (service de container AWS serverless) pour déclencher l’application de modèles de machine learning. L’utilisation de containers rend l’opération plus lente que l'utilisation d’une lambda puisqu’il faut charger l’image docker et lancer le container. L’utilisation d’une lambda par rapport au service Fargate, lorsque c’est possible, constitue donc un gain de temps et d’argent lors de la phase d’application du modèle. Pour l'entraînement des modèles, les orchestrateurs de conteneurs restent une meilleure solution que les fonctions serverless (qui ne sont ici pas du tout adaptées du fait d’une exécution dépassant généralement les 15 minutes).
La viabilité d’une telle solution est grandement dépendante du travail des data scientists. S’ils ont multiplié l’utilisation de librairies lourdes, la mise en place dans une Lambda sera plus compliquée.
Les deux autres principaux providers de cloud, Microsoft Azure et Google Cloud Platform ont aussi des services de fonctions serverless, respectivement, Azure functions et Cloud functions. Pour les Cloud functions, les limites sont proches de celles des fonctions Lambda d’Amazon. À noter que la limite de taille de code pour les Cloud functions est deux fois supérieure à celle proposée par AWS ce qui permet sûrement d’appliquer cette méthode dans un plus grand nombre de cas.
