
Nous avons vu dans l’article précédent les principales notions liées aux formats de données. La théorie c’est bien, la pratique c’est encore mieux.
Voici donc une liste non-exhaustive des formats que l’on rencontre couramment dans les environnements Data.
CSV (Comma Separated Values)
Commençons doucement …
Sûrement un des formats les plus répandus. Il n’est pas propre au domaine de la Data et est utilisé par un large panel de métiers, notamment car il peut être facilement lu, que ce soit avec un éditeur de texte, des outils de reporting ou bien avec des tableurs tels que LibreOffice.
Ce format textuel est utilisé pour les données tabulaires et non imbriquées. Il embarque optionnellement le schéma dans la première ligne, appelée “header”, mais pas les types des valeurs. Chaque valeur est séparée par une virgule et chaque ligne est terminée par un retour charriot.
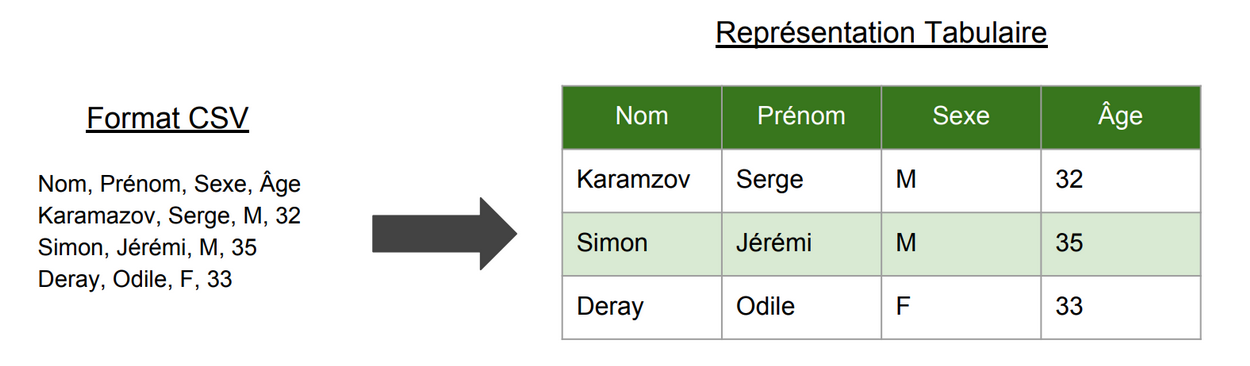
On peut aussi trouver des formats CSV-like, où la virgule est remplacée par un autre caractère (Tabulation, Barre verticale, point virgule … ).
Ce format n’est pas utilisé pour les gros volumes de données car il n’offre pas de possibilité de compression, hors formats courants tels que zip. En revanche comme il s’agit d’un format lisible sans modification par l’Homme, il est souvent utilisé pour les petits datasets, l’exploration de données ou encore les tests.
Bon à savoir : Le type des données n’étant pas embarqué dans le format, une lecture de toutes les données avant de pouvoir inférer les types peut être nécessaire. Selon le framework utilisé, seules les n premières lignes sont utilisées pour inférer le type. Utiliser ce format est donc rarement une bonne idée en production.
JSON (JavaScript Object Notation)
Le bien-aimé JSON (/ʒizɔ̃/), souvent vu comme le XML 2.0, est un format de donnée textuel comme le CSV. Humainement lisible donc.
Comparé au CSV, il possède quelques avantages :
- Le JSON permet de distinguer les chaînes de caractère des nombres, grâce à des guillemets. Néanmoins la distinction entre entiers et nombres flottants n’est pas aussi explicite et aucune méta-donnée sur la précision des nombres n’est donnée. Cette dernière caractéristique peut être problématique lors du traitement dans des langages tels que le JS (exemple).
- Le schéma est embarqué dans la donnée et les structures imbriquées ainsi que des listes sont des types existants dans le JSON. Il est donc souvent utilisé pour les bases de données NoSQL de type document.
Bien que le JSON soit moins verbeux que le XML, sa taille est assez imposante comparée à celles des fichiers binaires. Pour palier ce problème, certains formats binaires (MessagePack, BSON, etc.) basés sur le JSON ont émergé du fabuleux monde de l’informatique. Par soucis de concision, je ne réécrirai pas mon exemple en JSON mais préfère vous rediriger vers le site officiel du JSON pour plus de précision sur la syntaxe.
Bon à savoir : Dans le domaine de la Data et notamment Hadoop le JSON est souvent représenté inline par défaut. C’est-à-dire que chaque donnée est écrite sur une ligne.
Parquet
Ça y est, on rentre dans la cour des grands … Apache Parquet est un format orienté colonne et très en vogue aujourd’hui. Son succès est en partie dû au fait qu’il a été créé pour faire partie de l’écosystème Hadoop. Il y est donc très bien intégré et vit notamment une belle histoire avec Apache Spark.
Ce format embarque avec lui le schéma des données et les types associés. Il existe deux types de données en Parquet, les primitifs et les logicals qui étendent ces derniers. L’association de ces deux types permet l’utilisation de ce format sans travail de conversion. La présence d’un schéma est aussi un avantage car il permet de créer des objets déjà typés lors de l’utilisation des fichiers. Ainsi, nous n’avons pas non plus besoin de lire toutes les données d’une colonne afin d’inférer un type.
Cependant, ce format est binaire et donc pas lisible par l’Homme. De plus, la structure d’un fichier Parquet n’est pas si simple mais peut être schématiquement représentée de la façon suivante :
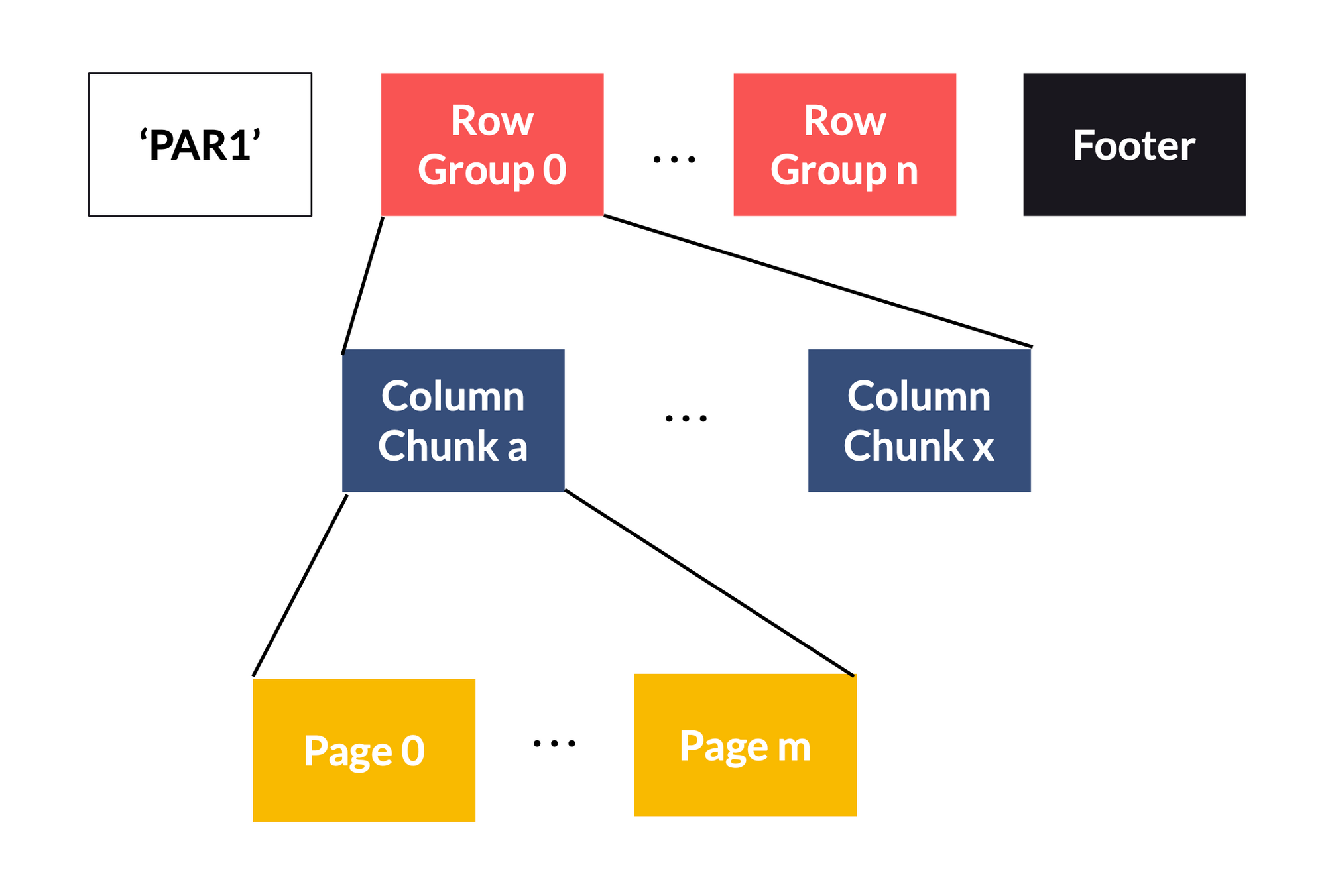
- Header : Il contient un Magic Number, 4 octets identifiant le fichier comme étant un fichier de type Parquet ‘PAR1’.
- Row Group : C’est la représentation logique des données en lignes. Il est composé de column chunks, un par colonne du dataset.
- Column Chunk : Il contient une partie des données pour une colonne particulière. Les lecteurs (readers) peuvent lire des statistiques de chaque colonne (min, max, num_nulls) et ainsi dans certains cas ne pas avoir besoin de lire certains Column Chunks.
- Page : Les pages contiennent les données compressées (~1MB) et partagent des headers communs. Les mêmes statistiques y sont stockées, mais calculées avec une granularité plus fine (Page).
- Column Chunk : Il contient une partie des données pour une colonne particulière. Les lecteurs (readers) peuvent lire des statistiques de chaque colonne (min, max, num_nulls) et ainsi dans certains cas ne pas avoir besoin de lire certains Column Chunks.
- Footer : Il contient les metadata du fichier. Les lecteurs des Parquets lisent tout d’abord, ce fichier de metadata pour trouver les column chunks qui les intéressent. Il contient aussi la taille du fichier de metadata ainsi que le même Magic Number que le header.
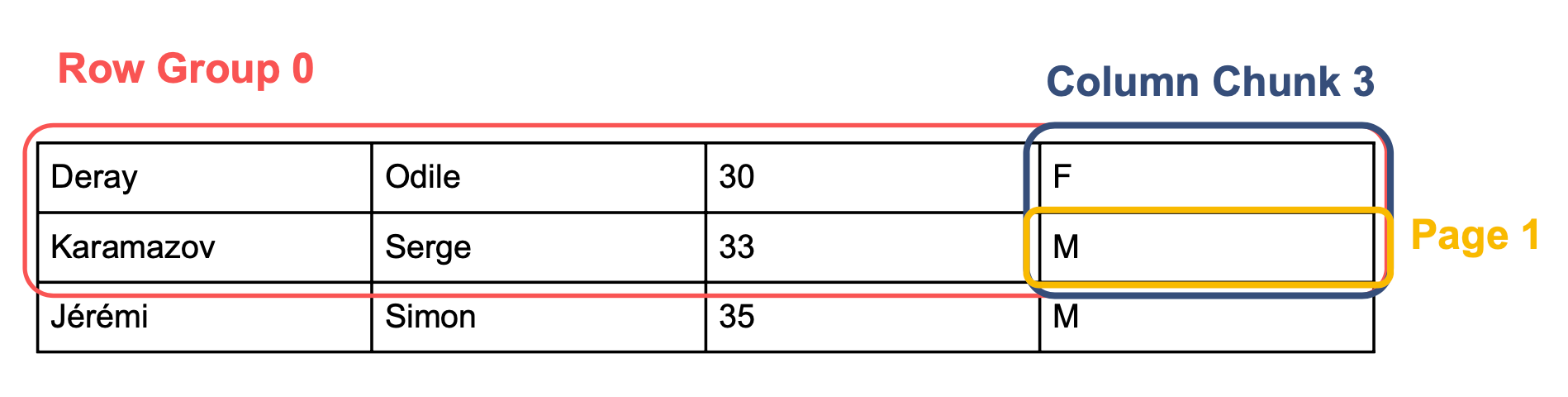
Schématiquement, notre jeu de données pourrait être représenté de la sorte :
Niveau compression, Snappy est l’algorithme par défaut avec du Parquet mais on peut aussi trouver du LZO, gzip et bien d’autres.
La force de ce format est son orientation colonne couplée aux statistiques associées. Il est donc très efficace lorsque des projections et predicate pushdowns sont utilisés. Son intégration avec de multiples outils (Spark, Hive, Flink, Athena, BigQuery, etc.) fait qu’il est aujourd’hui le format le plus utilisé quand on parle de traitements Big Data.
Bon à savoir : Sa structure singulière et son écriture binaire couplée à la compression rendent sa lecture directe très difficile. Pour explorer des données Parquet on peut utiliser un spark-shell qui nous permet aussi de les manipuler. Autrement, il existe l’utilitaire Parquet-tools un peu moins connu mais très pratique qui permet de visualiser les données ainsi que toutes les metadonnées associées au fichier. En bref, spark-shell + Parquet-tools = ❤️
ORC
Le grand rival du Parquet … Apache ORC (Optimized Row Columnar) est un format orienté colonne très utilisé et qui est intégré à l’écosystème Hadoop. Globalement, ORC dessert les mêmes cas d’utilisation que Parquet. Il est souvent utilisé avec Hive.
Les types de données supportés sont multiples (primitifs et composés), la liste de ceux-ci se trouve ici. Tout comme le Parquet, le schéma des données est embarqué dans les fichiers ORC.
Un fichier ORC a une structure presque similaire au Parquet et peut être représenté de la manière suivante :
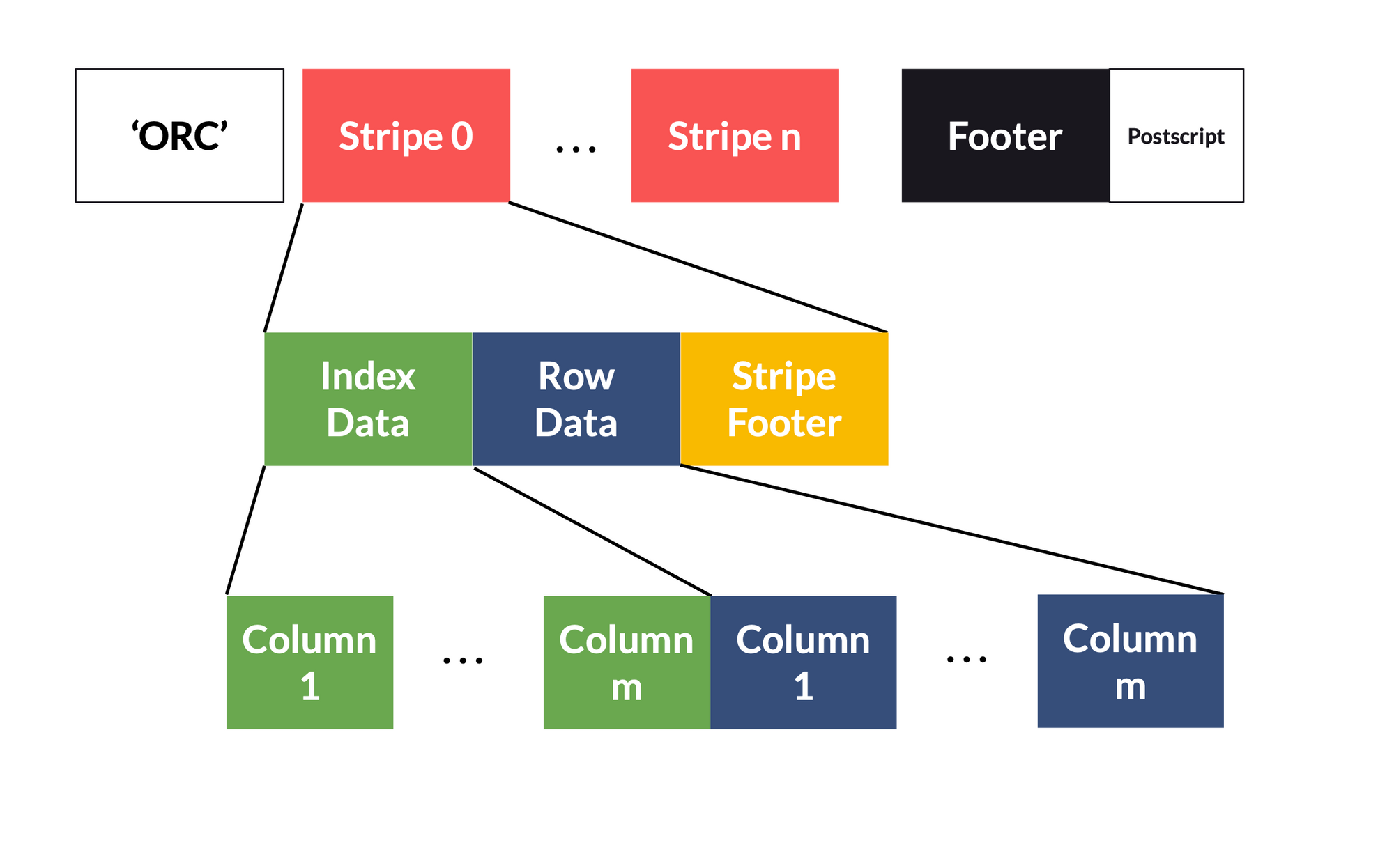
- Header : Le header permet d’identifier le format du fichier, ici ce sera ‘ORC’
- Stripe : C’est ici que la donnée y est contenue, ce sont des blocs de 250Mb par défaut.
- Index data : Contient les index des lignes (row-level) de chaque colonne du stripe. Ce sont des métadatas.
- Column : Contient les index row-level sur la colonne en question.
- Row data : Contient les données de chaque colonne.
- Column : Contient les données de la colonne en question.
- Strip footer : Contient les informations sur l’encodage de la colonne.
- Index data : Contient les index des lignes (row-level) de chaque colonne du stripe. Ce sont des métadatas.
- Footer : Contient les files et strip level index.
- Postscript : Contient les informations nécessaires à la lecture du fichier (meta-data) et n’est jamais compressé.
Les trois index mentionnés ci-dessus font référence à des statistiques calculés sur les données de chaque colonne mais à différents niveaux :
- File-level : Sur tout le fichier
- Strip-level : Sur chaque stripe
- Row-level : Sur 10 000 lignes (row-group) dans une stripe et, la position de départ de chaque row-group.
Ces statistiques, plus complètes que celles offertes par le Parquet, contiennent min, max, sum, count, hasnull, bytesOnDisk et des bloom filters. ORC supporte aussi les opérations ACID (hello Hive).
Par défaut le format ORC est souvent compressé avec le ZLIB, mais d’autres algorithmes tels que le Snappy sont aussi envisageables.
Bon à savoir : L’aspect binaire du format ORC et sa structure alambiquée ne permettent pas une lecture humaine des données. Tout comme Parquet, des solutions existent pour explorer directement des données ORC, spark-shell ou orc-tools.
Parquet Vs ORC
Il y a les pro-“LE wifi” et les pro-“LA wifi” (on reste bienveillant, on ne juge pas), tout comme il y a les pro-Parquet et les pro-ORC. Vous avez pu le voir les formats ORC et Parquet sont assez similaires.
Mais dis-moi Jamy, les deux formats se ressemblent énormément, alors quelles sont les réelles différences ?
ORC a été développé par Facebook puis open-sourcé au sein de la fondation Apache (2013) et en partie maintenu par Hortonworks. Il en est de même pour Parquet, développé par Twitter puis de même donné à la fondation Apache (2013) et maintenu par Cloudera. Cette dernière distribution est la plus populaire et pousse naturellement l’utilisation de Parquet ce qui expliquerait le fait qu’ORC soit moins populaire. Les temps changent, et l’annonce de la fusion en 2018 de ces deux mastodontes va peut-être faire changer les choses.
On se pose donc forcément la question : Dois-je choisir le format Parquet ou ORC ? La question n’est pas triviale. Si vos cas d’utilisation finaux ne passent que par Hive, le format ORC est certainement à privilégier car son intégration y est souvent mise en avant. Sinon, il faut malheureusement prendre le temps de lire les différents benchmarks existants et de tester de manière empirique les performances (stockage et temps d’exécution) de vos transformations avec ces formats, couplés à différentes compressions.
Lors de la rédaction de cet article, le support de ces formats dans l’écosystème Big Data est le suivant :
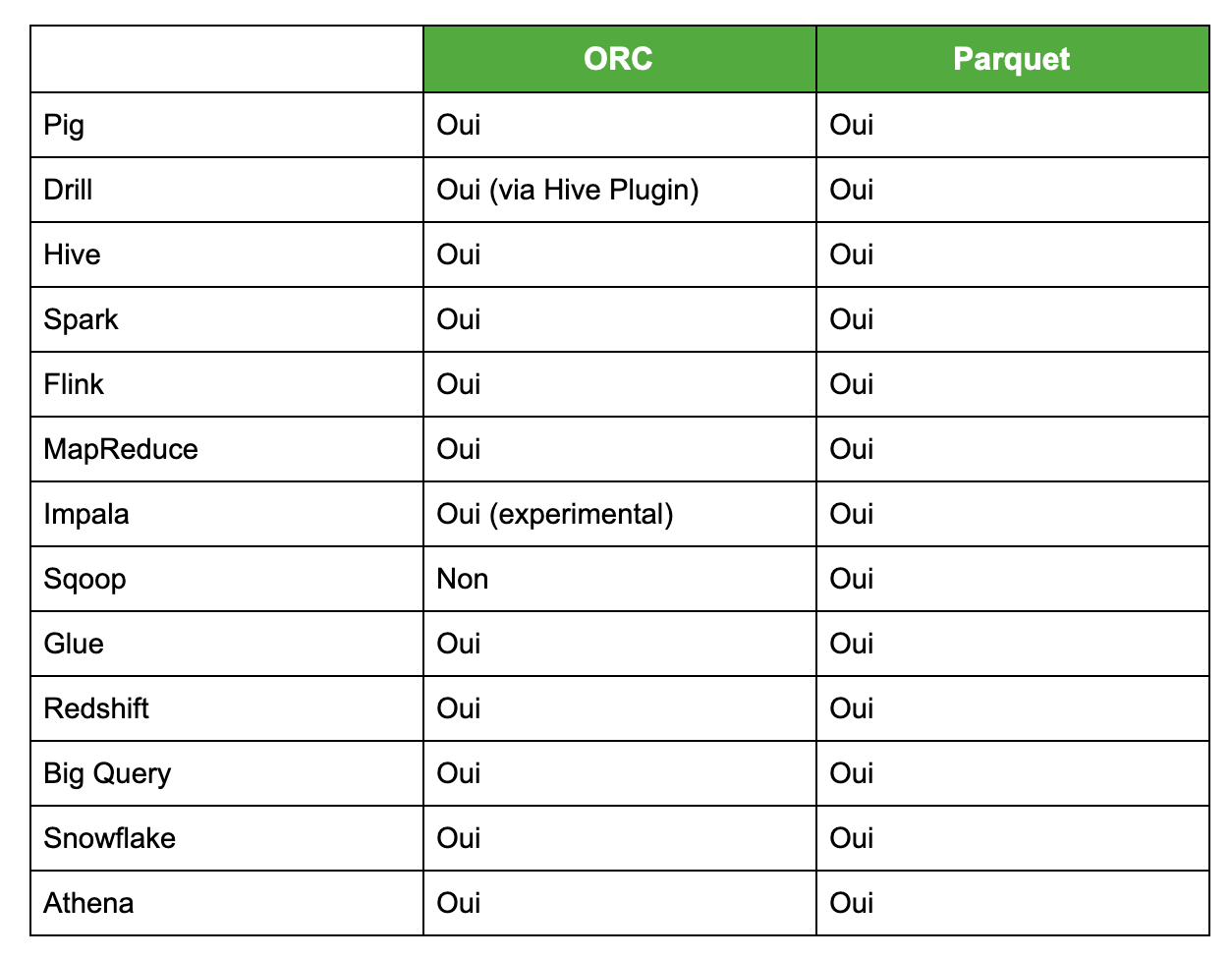
Bon à savoir : Spark est sûrement plus mature sur la manipulation de fichiers Parquet, supportés depuis Spark 1.0, que ORC, introduits eux en Spark 1.4.
RCFile
Pour la petite histoire … RCFile (Row Columnar File) peut être considéré comme le premier fichier format colonne de l’écosystème Big Data, un peu comme le MapReduce du Spark. Le premier papier introduisant RCFile a été publié en 2011. Tout comme ORC et Parquet les concepts de projection pushdown, compression, lazy evaluation y étaient possibles et il était aussi fait pour fonctionner avec MapReduce.
Toutefois, aucune metadata sur les données n’était présente. Et ainsi le predicate pushdown impossible. De plus les rowgroups étaient seulement de 4MB, les lectures séquentielles n’étaient donc pas optimales.
C’est pour ces raisons qu’ont été introduits ORC et Parquet.
Avro
Le troisième mastodonte de la data. Apache Avro, créé en 2009, est un format de sérialisation de données. Contrairement aux formats de données colonnes, son objectif est le transfert des données dans l’écosystème Hadoop (donc environnement distribué).
Un fichier Avro peut être schématiquement représenté de la sorte :
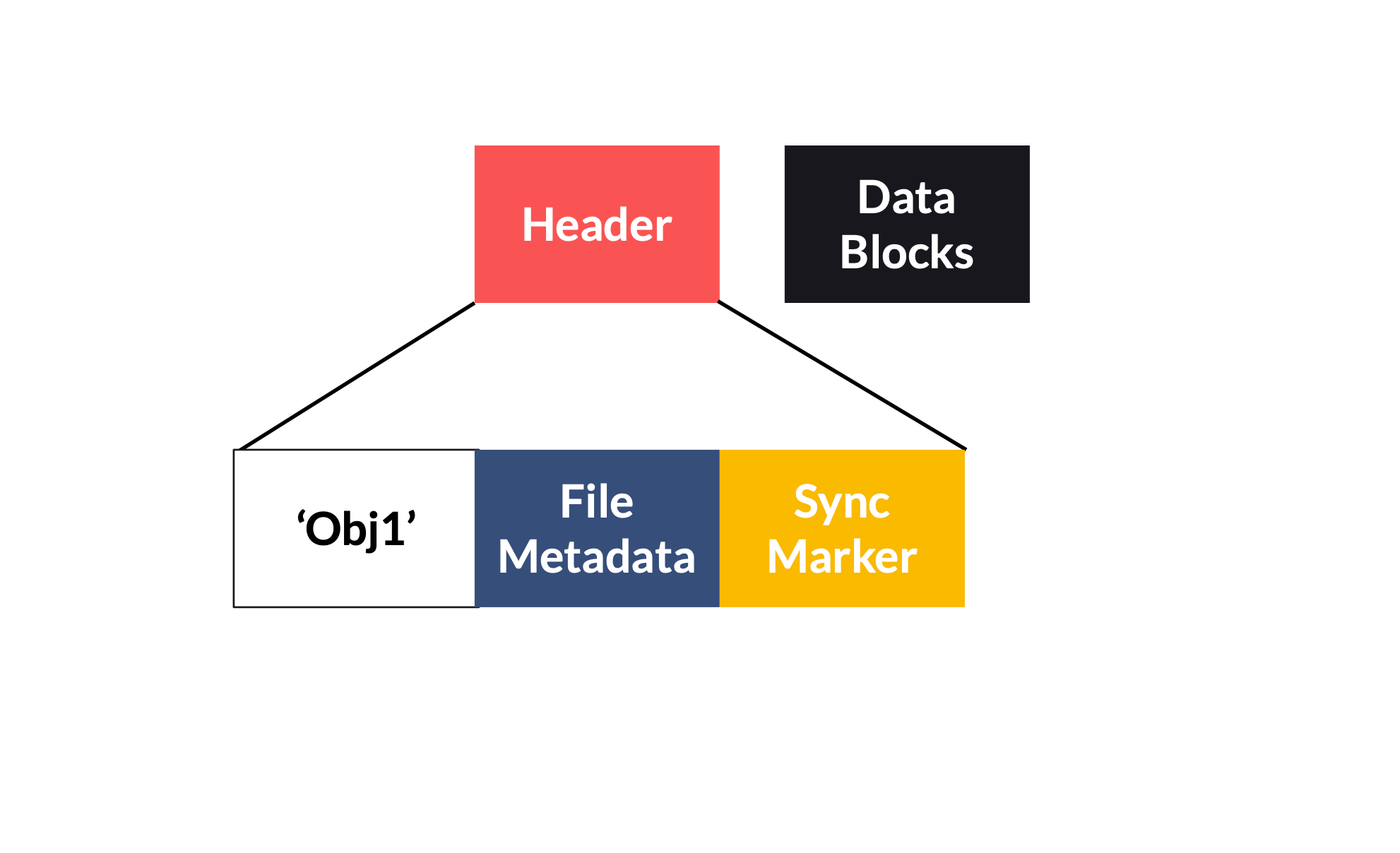
-
Header : Les trois premiers bytes du header informent que le fichier est du type Avro et sont suivis de la version Avro du fichier, ici 1.
- Sync Marker : Permet de vérifier que le fichier de données n’est pas corrompu, comme un checksum par exemple.
- File Metadata : contient (roulement de tambour …) les metadonnées du fichier au format JSON. Elles sont composées du schéma de la donnée, du codec et de la compression. Pour notre exemple, le schéma serait le suivant :
{
"type": "record",
"namespace": "fr.lesnuls",
"name": "Informations",
"fields": [
{ "name": "Nom", "type": "string" },
{ "name": "Prenom", "type": "string" },
{ "name": "Age", "type": "int" }
{ "name": "Sexe", "type": "string" }
]
}
- Data Blocks : contiennent les données en soit, le plus souvent en binary mais le format peut aussi être du JSON (pour débugger par exemple).
La donnée Avro embarquant le schéma, l’utilisateur n’a pas besoin d’écrire les classes de sérialisation/désérialisation de la donnée lui-même. Ce qui est un avantage non-négligeable lorsque l’on veut un système robuste et flexible, schématiquement parlant. La backward compatibility et forward compatibility ne sont donc pas à implémenter par l’utilisateur.
Apache Avro implémente aussi le Remote Procedure Call (RPC) qui permet au producteur et consommateur de la donnée d’avoir exactement le même schéma. Ce qui facilite donc grandement la résolution de schéma niveau consommateur.
Souvent Apache Avro est la sérialisation recommandée lorsque l’on utilise Apache Kafka, qui inclut un schema registry (version confluent).
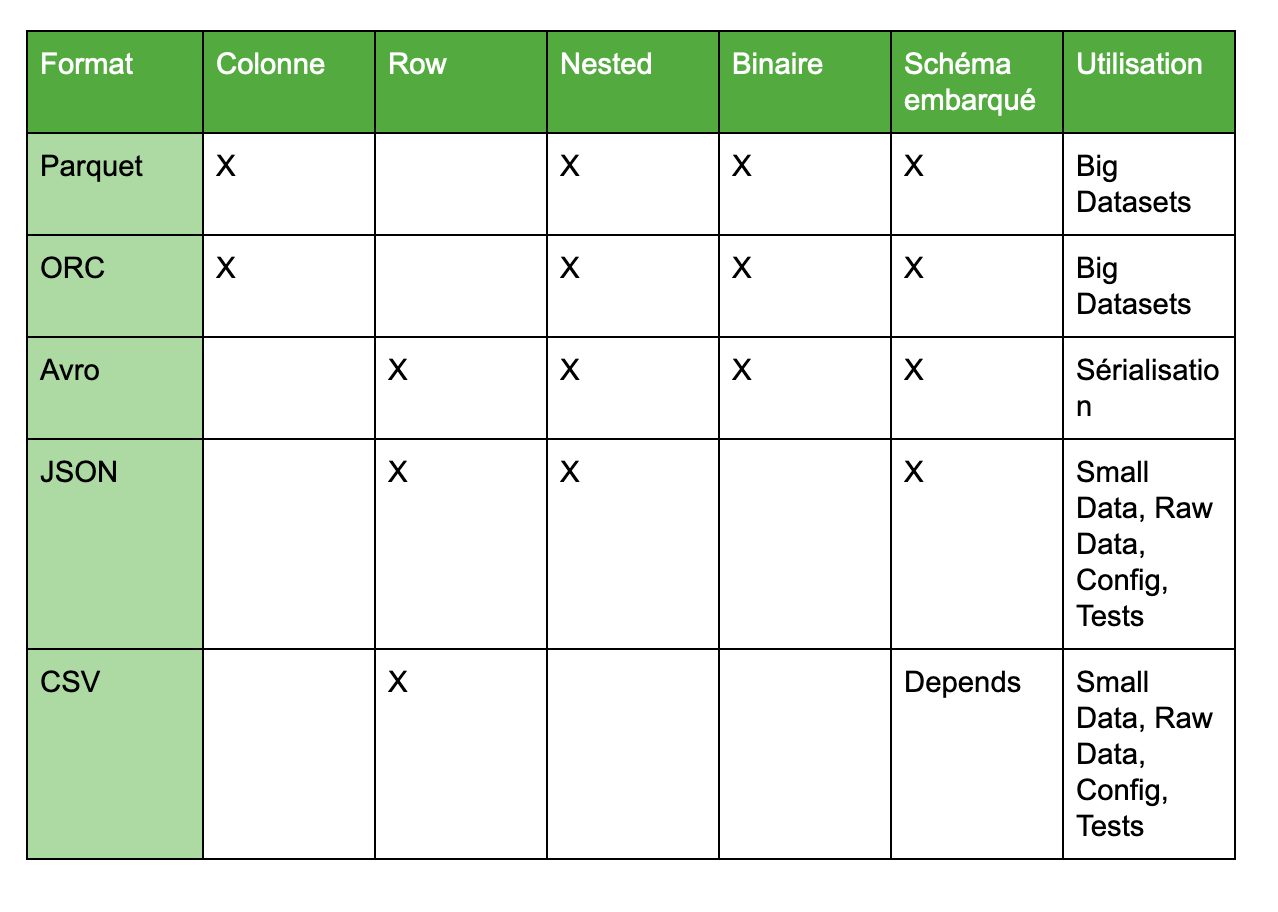
Récapitulatif
Voici un tableau récapitulatif des formats présentés dans cet article :
Conclusion
Nous avons vu que les formats binaires offrent des capacités de compression et d’accès aux données en colonne que ne permettent pas les formats CSV ou JSON.
Ces 2 caractéristiques sont déterminantes pour accélérer les traitements de données car elles réduisent énormément le volume de données qui va être effectivement traité.
C’est donc devenu une bonne pratique que de passer sur un format évolué dès que la donnée est acquise. Cela réduit le volume de stockage et le temps de traitement, donc mécaniquement l’énergie consommée et aussi les coûts.
