

Être Data Engineer c’est beaucoup de développement, mais ce n’est pas que ça ! Une partie du travail consiste à optimiser les traitements, aussi bien sur leur temps d’exécution que sur l’espace requis. Pour ce faire, on peut amener des améliorations sur le hardware, en scalant horizontalement ou verticalement les nœuds d’un cluster ainsi qu’en variant la taille des disques.
Le format des données utilisé est un facteur jouant sur l’espace requis mais aussi sur le temps d’exécution des traitements. Cet article a pour but d’expliquer les principaux formats utilisés actuellement dans l’écosystème Data et d’aider à la prise de décision lors du choix du format à utiliser.

Il est tout d’abord nécessaire de définir les notions qui vont être utilisées afin de partir sur une base commune. Il est indispensable de comprendre ces notion afin de pouvoir choisir le format le plus adapté à votre besoin, c’est la raison pour laquelle cet article sera entièrement consacré à la théorie et suivi d’un deuxième centré sur la pratique.
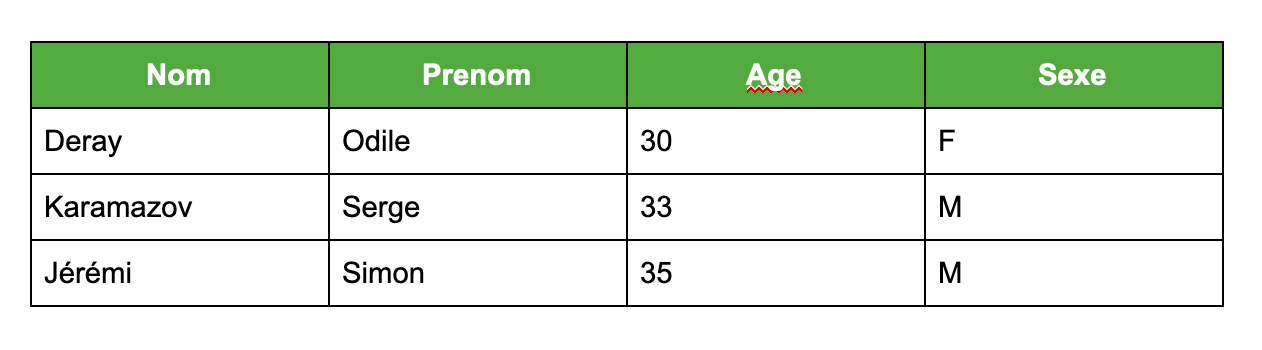
Les données d’exemple utilisées tout le long de cet article sont les suivantes (représentation tabulaire) :
Stockage
Les formats de données existants aujourd’hui permettent de stocker celles-ci sous deux types différents : Row Storage et Columnar Storage.
Les Row storage stockent les données sur disque ligne par ligne. Le nième Nom sera toujours suivi du nième Prénom par exemple. Schématiquement les données seront séparées et stockées de la sorte :
Quant aux Columnar storage (format colonne), elles stockent les données sur disque colonne par colonne. Le nième Nom sera toujours suivi du nième +1 Nom. Schématiquement les données seront séparées et stockées de la sorte :

Si vous voulez creuser un peu plus ce thème, je vous conseille cette présentation.
Projection Pushdown
Le projection pushdown permet de ne scanner que les colonnes qui vont être utilisées dans le programme. Les formats de données colonne permettent de mettre en place le projection pushdown aisément.
Un exemple vaut mieux qu'un long discours : si on ne veut connaître que le Nom et le Prénom des individus de notre dataset d’entrée, le moteur de traitement saura qu’il n’est pas nécessaire d’aller lire les colonnes Age et Sexe. Par exemple, l’Optimizer de Spark (Catalyst) ne lira que les colonnes Nom et Prénom dans les fichiers d’origine lors de la requête suivante si le format de stockage sous-jacent le permet
scala> df.select(col("Nom"), col("Prenom")).show
Ainsi, grâce au projection pushdown, on a évité de lire inutilement 50% des données. C’est bien pensé quand même ...
Predicate Pushdown
Le predicate (ou filter) pushdown permet de filtrer des données en se basant sur les statistiques incluses dans les fichiers.
Par exemple, si on ne veut récupérer que les individus ayant 36 ans ou plus et admettons que le format de fichier utilisé inclut des statistiques sur l’Age. Le moteur de traitement saura qu’aucune donnée de notre dataset ne correspond à ce critère et ainsi retournera rapidement un résultat vide. En Spark Scala (évidemment) une commande utilisant ce predicate pushdown serait la suivante :
scala> df.filter($"Age"> 36).show
Les predicate/projection pushdown permettent d’économiser des I/O disque, du trafic réseau et donc du temps.
Compression
Compresser une donnée, c’est la représenter avec moins de bits que la donnée initiale. Il existe les compressions avec et sans perte.
La compression des données mériterait un article rien qu’à elle, c’est la raison pour laquelle ce sujet ne sera pas plus développé ici. En revanche, si vous avez un peu de temps, je vous conseille d’aller lire cet article (après la fin de celui-ci bien sûr !).
Il n’est pas rare que des données qui se suivent aient la même valeur dans certaines colonnes (e.g. Ville), la compression pour tous les formats colonne est donc souvent très efficace.
Lazy decompression
Prenons l’exemple suivant : on décide de lire des données selon une condition (même requête que le predicate pushdown, Age > 36) et notre format de stockage est orienté colonne. Il serait inefficace de décompresser toutes les colonnes pour rechercher seulement les lignes passant le filtre sur une seule colonne. C’est ici que la lazy decompression intervient. Comme on utilise un format colonne, on peut tout d’abord décompresser seulement la colonne correspondante (colonne sur laquelle le filtre est appliqué, ici Age) et repérer les lignes satisfaisant la condition pour enfin les décompresser.
Imbrication
Des données imbriquées (a.k.a. nested) ne sont pas représentées par une unique valeur mais par une autre structure de données (e.g. Liste, objet, Tuple, etc.). Certains formats ne supportent pas ce type de données, il est parfois donc nécessaire d’aplatir (a.k.a. flatten) les données imbriquées afin de pouvoir les convertir dans ces formats.
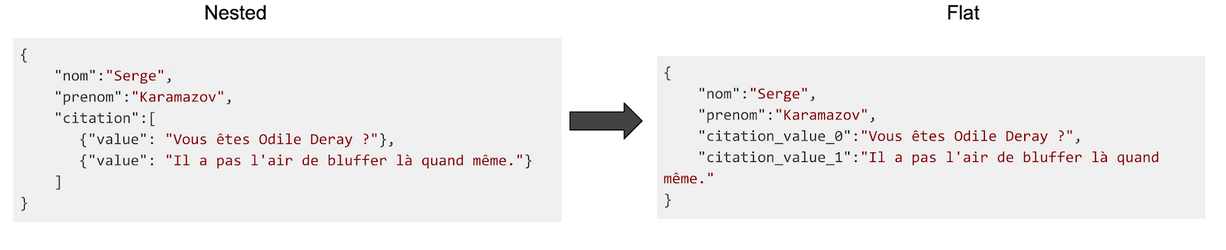
Ci-dessus un exemple de donnée avant (Nested) et après (Flat) avoir été aplatie.
Compatibility
La problématique de la compatibilité entre deux versions de programmes n’est pas inhérente à la Data mais en fait entièrement partie.
Imaginons … une entreprise avec un SI assez simple : un programme A va écrire des données (data V1.0) sur un File System, que va ensuite lire un programme B. Elle décide de mettre à jour son SI et les nouvelles données transférées (data V2.0) auront un schéma différent que data V1.0. Les programmes A&B V2.0 sont donc pensés pour lire et écrire des données 2.0. Pour migrer son SI elle décide d’adopter une méthode Blue/Green. Des versions V1.0 et 2.0 des programmes et données vont donc cohabiter pendant quelques temps.
Si le programme B ne supporte pas l’évolution de schéma, il a de fortes chances de ne pas se terminer et lever des erreurs.
La Forward Compatibility tient dans le fait que le programme B en V1.0 puisse lire des données data V2.0, écrites donc par le programme A V2.0. Inversement, la Backward Compatibility est le fait que le programme B en V2.0 puisse lire des données data V1.0, écrites donc par le programme A V1.0. Ces deux types de compatibilité sont essentiels pour les programmes ayant besoin du schéma de la donnée.
Conclusion
Une fois avoir pris connaissance de toutes ces notions, on se rend compte qu’il est primordial de réfléchir au format à utiliser pour tous nos traitements. Nous en avons donc fini avec la théorie. Dans le prochain article de cette série, nous verrons les différentes implémentation de ces types de formats.
