

Dans la jungle du développement informatique, l’animal le plus féroce pourrait bien être votre domaine métier… Aujourd’hui, lorsque nous programmons, il est important de comprendre ce que nous sommes en train d’implémenter. Encore plus dans un contexte Agile où la discussion et le partage de la connaissance font partie intégrante dudit manifeste:
Business people and developers must work together daily throughout the project
Il est parfois compliqué pour un développeur et un Product Owner de se comprendre même si désormais il existe beaucoup d’outils et de façons pour échanger autour de ces sujets. C’est également le rôle du PO (je vous conseille cet article qui démystifie son rôle et ses préjugés) d’organiser son besoin et réussir à le faire comprendre aux développeurs. La mise en place de méthodologies comme le BDD (Behaviour Driven Development) permet justement d’avoir un meilleur partage de l’équipe dans l’écriture, la compréhension et la validation des comportements que devra respecter notre application, à travers l’écriture de scénarios fonctionnels (souvent écrits dans un langage dédié, généralement le Gherkin) qui mettront en lumière le besoin métier.

La fameuse Big Ball Of Mud (qui décrit l’architecture d’un logiciel sans architecture évidente) a tendance à arriver plus souvent qu’on ne le pense au sein d’un projet. En complément d’une conception aux petits oignons, il va cependant être utile pour votre domaine métier, qu’il soit maintenable et cohérent. Voyons ensemble les spécificités des moteurs de règles, leurs avantages et leurs inconvénients et bien sûr, une des manières de le tester.
Un moteur de règles : Késako ?
Un moteur de règles se base essentiellement sur un moteur d’inférence qui va être chargé de répondre aux conditions données sur les règles et les faits, afin de résoudre le cas en cours d’évaluation… Ou comme le dit si bien Martin Fowler, ici :
You can build a simple rules engine yourself. All you need is to create a bunch of objects with conditions and actions, store them in a collection, and run through them to evaluate the conditions and execute the actions.
Il va nous permettre de séparer les traitements et les données, qu’on appelle respectivement les règles et les faits. Les règles métier, en général, suivent une organisation semblable à un arbre de décision. Grâce à l’implémentation d’un moteur de règles, on va notamment pouvoir rendre modulable nos règles, et donc n’avoir aucun couplage fort entre les règles et le reste de notre application. A savoir, qu’un grand nombre de règles métier, bien évidemment, peut faire ralentir nos traitements…
Il existe principalement 2 types de moteurs d’inférence :
- Le moteur par chaînage avant:
- On part des faits et des règles et on en déduit une solution finale : le plus utilisé et le plus simple…
- Le moteur par chaînage arrière
- On part de la solution et on essaie de remonter jusqu’aux faits et aux règles : Utilisé principalement en IA et plus complexe à mettre en oeuvre...
En pratique
Nous allons mettre en place un moteur de règles simplifié qui va nous servir à la détection de forme (triangle ou quadrilatère). Commençons par nous créer un DSL pour écrire d’un côté les faits et les règles, par exemple :
Imaginez 2 fichiers distincts contenant ces données qui sont donc séparées du reste de l’implémentation et compréhensibles par tout le monde. C’est un premier pas vers le partage de la connaissance et le couplage faible ! On est sur la bonne voie…
Ensuite, nous allons devoir valider les faits, c’est-à-dire calculer le nombre de côtés, connaître le nombre de côtés égaux, vérifier la présence d’angles droits… Ici, nous n’allons pas nous intéresser à ceci, je vous laisse libre dans le choix de l’implémentation 😊
Intéressons-nous, maintenant, au moteur de règles.
Pour lire notre DSL, il va bien sûr falloir utiliser un lexer (découpage de notre phrase en mots-clés reconnaissables) et un parser (hiérarchisation des mots-clés) … En général, on choisira d’utiliser les expressions régulières et un AST si on souhaite réaliser un moteur de règles poussé.
Côté Frameworks
En Java, il existe différents frameworks sur le marché comme Drools, qui intègre toute une suite d’outils autour du moteur de règles afin d’établir nos règles et les orchestrer grâce à une UI. D’autres frameworks comme OpenL Tablets sont de simples moteurs de règles n’intégrant que le strict minimum pour ne pas surcharger notre application.
La plupart des moteurs de règles (Java) respectent la JSR-94, définie comme étant la norme à suivre en matière de moteurs de règles (notamment dans le respect de l’API Rule Engine de javax.rules). Cette spécification répond aux besoins de la communauté en matière de réduction des coûts liés à l'intégration de la logique métier dans les applications et tente de donner un cap commun aux moteurs présents sur le marché.
Toutefois, il existe également de plus petits moteurs qui répondent tout à fait au besoin comme Easy-Rules mais qui ne suivent pas la JSR-94. Ces moteurs de règles peuvent donc différer en terme d’intégration et de performances : à utiliser avec précaution.
Les écritures de règles peuvent se faire dans un DSL normé (pas comme celles que j’ai définies au-dessus…) appelé MVEL. Il est généralement utilisé pour exposer les règles via une configuration (.xml, .yml, .drl...) ou par annotations.
Exemple simple de MVEL:

Comment tester mon moteur de règles maintenant ?
Grâce à des outils comme Cucumber (Framework) et Gherkin (DSL), nous allons pouvoir définir conjointement avec le Product Owner, dans un langage commun (je rappelle que la clé du moteur de règles est de séparer les règles du code de l’application), le comportement de notre application, et ainsi tester nos différents cas possibles. Reprenons notre système de détection de polygones à 3 et 4 côtés.
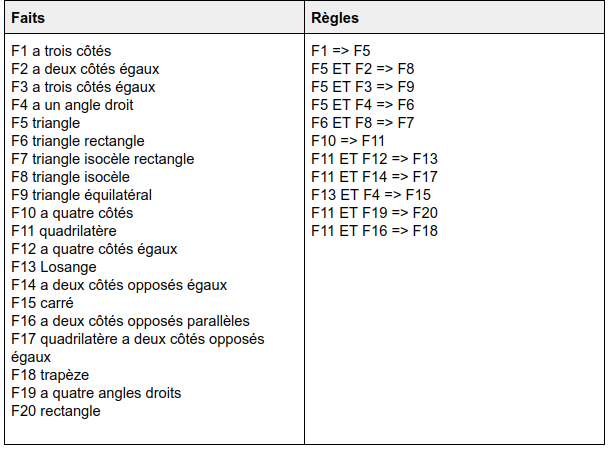
Un exemple de tests écrits pour la détection des différents triangles suivant les faits et règles ci-dessus :
De cette façon, grâce à la séparation ordonnée dans les règles et les faits, notre moteur de règles peut être testé dans sa globalité et dans un contexte fermé. Grâce à la mise en place des features Gherkin, ici, en anglais, nous avons pu organiser nos règles métiers de façon à pouvoir les faire évoluer simplement, et constituer également une documentation vivante !

“Le BDD, qu’est ce que c’est?”, Arnauld Loyer, blog arolla.fr, 2012
L’implémentation de nos tests (dans le langage de notre choix) grâce aux différents Frameworks comme Cucumber (Java) ou SpecFlow (C#), vont nous permettre d’organiser notre test à la façon d’un scénario au format Given / When / Then, donc en Gherkin :
- Given : un prérequis
- When : une action
- Then : un résultat
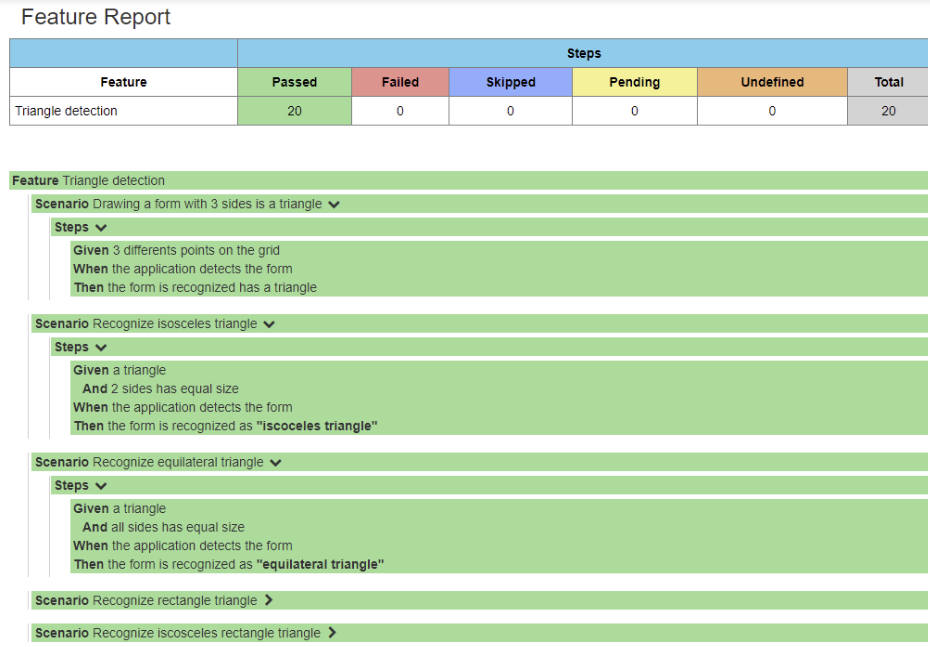
On peut également écrire les scénarios pour les quadrilatères:
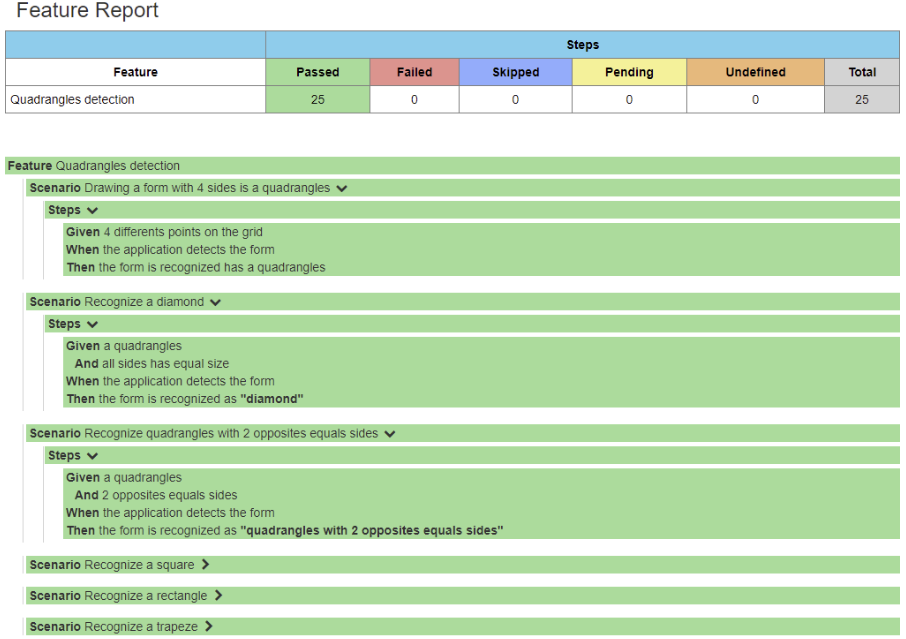
Conclusion
Nous n’avons pas abordé le cas des moteurs de règles sur de grands volumes de règles. Sur les cas ci-dessus, notre base de faits et de règles est plutôt minime et logique. En pratique, dans un contexte plus imposant, le nombre de cas devient vite exponentiel, et il est parfois complexe d’identifier chaque solution. Certains acteurs importants de l’IT comme IBM ou Red Hat, l’ont bien compris et ont créés des systèmes optimisés pour des traitements sur des centaines de milliers de règles… avec des outils de Big Data. Ces entreprises offrent généralement une prestation de conseil spécifique, comme par exemple lors de l’élaboration du projet (IBM) concernant les contrôles aux frontières des aéroports.
Quant aux tests, Il existe plusieurs papiers de recherche qui traitent de ce sujet, notamment ce papier de l’Université de Manchester qui propose une stratégie de tests sur de gros volumes à l’aide d’une base de données.
En début de projet, ou pendant une refactorisation, si vous pensez avoir (ou avez…) une quantité de règles de gestion importante (plus d’une dizaine), qu’elles évoluent au fil du temps, qu’elles font appel à des définitions métier complexes, je vous conseille d’utiliser un moteur de règles et d’y ajouter les tests d’acceptation comme vu précédemment. L’objectif est également d’ajouter ou développer la cohésion dans l’équipe et de faire une introduction au BDD. L’écriture commune des test cases est une étape importante dans la création de notre produit, elle vous fera gagner du temps et vous assurera un suivi de vos règles de gestion : So… try it 😎
