

J’ai assisté à une session de Yan Cui, "AWS Serverless Hero", lors du AWS Re:invent 2019 sur comment refactoriser une application monolithique en une application serverless.
Cet article a donc pour but de vous partager le contenu de cette session. Yan Cui citant 8 étapes dans ce voyage dans le monde du serverless, je vais vous les présenter une à une.
Vous pouvez retrouver les slides complets de sa présentation en cliquant ici.
Étape 1 : inverser la Loi de Conway
Yan Cui cite la Loi de Conway qui dit : "les organisations qui conçoivent des systèmes ... sont contraintes de produire des designs qui sont des copies de la structure de communication de leur organisation".
Une architecture serverless est composée de petits composants faiblement couplés qui peuvent scaler et être déployés indépendamment les uns des autres. Si on suit la loi de Conway il faut structurer son organisation interne de la même manière.
Cela implique donc de créer de petites équipes, autonomes et pluri-compétentes qui ont la capacité et la responsabilité de gérer leurs propres services.
Le concept "2 pizzas team" mis en place par Jeff Besos en est un bon exemple : "si vous ne pouvez pas nourrir une équipe avec deux pizzas, c’est qu’elle est trop grosse".

Il est important de noter que l’organisation doit faire confiance à chaque équipe afin de pouvoir leur accorder une certaine autonomie. Cela ne doit pas l’empêcher de vérifier les décisions prises et de les challenger si besoin.
Dernier point et pas des moindres, passer d’un mode de conception monolithique à un mode serverless ne se fait pas sans heurt. C’est un changement drastique que les équipes doivent adopter du build jusqu’au run. Il faut donc accepter qu’une montée en compétence des équipes est obligatoire.
Étape 2 : identifier les services
Un point important cité par Yan Cui est d’identifier clairement les différents services que l’on va produire.
Les applications monolithiques étant généralement de taille considérable et couvrant plusieurs domaines métiers, il est impossible de tout refaire d’un coup. Cela implique donc d’identifier clairement au sein du monolithe les différentes frontières et d’en extraire des services indépendants.
Un service doit avoir l’autorité sur un domaine métier de l’application :
- Il doit être autonome ;
- Il doit connaître ses frontières ;
- Il est propriétaire de ses données et est le seul à pouvoir les exposer ;
- Il est faiblement couplé à d’autres services (à travers des contrats d’interface pour les APIs par exemple).
Attention toutefois à ne pas définir des services trop granulaires. Par exemple, dans le cadre d’un monolithe composé d’un ensemble de ressources sous forme de CRUD, ne pas définir automatiquement un service pour chacune des ressources.
Un service doit représenter un domaine métier clair. Voici un exemple concret :
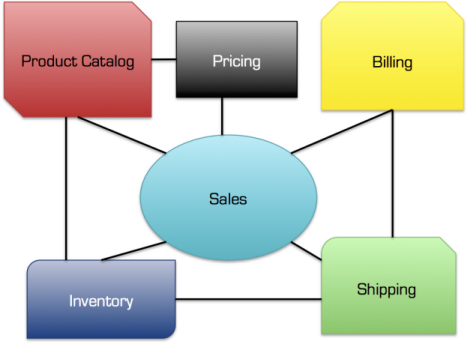
Pour finir, il est grandement recommandé de démarrer sur des services à faible risque et non critique afin d’éviter tout impact business sur l’organisation.
Étape 3 : organiser le code
Un autre changement majeur lorsqu’on développe une application serverless est la manière dont le code va être géré. Dans une application monolithique, c’est généralement simple, un seul repository où tout le code source est stocké. Un choix naturel puisque toute l’application ne génère qu’un seul livrable.
La question qui se pose alors est que doit-on faire dans une application serverless ? Yan Cui cite deux possibilités.
Un repository pour tous les services
Avec un seul repository, chaque service réside dans son propre répertoire. Cette approche est probablement la plus simple à mettre en place mais peut vite devenir un cauchemar si l’application grandit. Et cela peut même devenir un problème si plusieurs équipes travaillent sur différents services puisqu’il sera impossible de gérer les droits d’accès séparément. Ce mode est recommandé pour de petites équipes disciplinées et bien outillées.
Un repository par service
Un service par repository permet à chaque service d’avoir une stack de déploiement et une CI/CD indépendante. La gestion des droits est également facilitée en cas d’équipes distinctes. Les parties communes entre les services (infrastructure et librairies) doivent par contre avoir leur propre repository.De mon point de vue, la seconde approche doit toujours être privilégiée, c’est la solution la plus souple et la moins complexe sur le long terme.
Étape 4 : choisir vos outils
Déployer une application serverless est simple à condition de choisir les frameworks de déploiement qui vous conviennent. Vous serez ainsi capable de déployer une application entière en quelques minutes.
Il existe actuellement plusieurs frameworks, en voici une liste non exhaustive :
Le framework doit être choisi en fonction des besoins de l’organisation et non l’inverse. Une fois la décision prise, il est important que le framework soit adopté par l’ensemble des équipes de l’organisation afin de garantir une certaine consistance dans la manière de déployer entre les différentes équipes.
Étape 5 : développer des fonctions simples
Les différentes fonctions d’un service doivent rester simple et respecter le principe de responsabilité unique de Robert C. Martin. Le but principal étant de faciliter la lisibilité de la fonction afin de comprendre rapidement ce qu’elle fait.
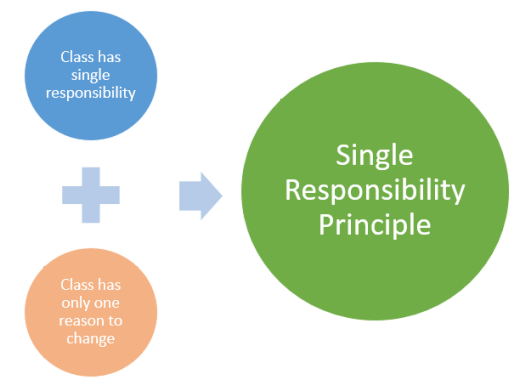
Respecter ce principe permet également d’avoir une sécurité accrue sur la fonction. La fonction n’ayant qu’un seul rôle, ses droits seront limités et si elle est compromise, l’impact et les risques seront moindres qu’une fonction ayant un champ d’action plus large.
Dernièrement, une fonction simple aura moins de code, moins de classe, moins de dépendance à charger au démarrage et le fameux cold start qui fait couler beaucoup d’encre sera moins important.
Étape 6 : basculer sur les nouveaux services gracieusement
Un point clé cité par Yan Cui lors du déploiement d’un nouveau service en remplaçant la partie monolithique est de ne pas impacter les utilisateurs.
Une approche qui a fait ses preuves est de maintenir la compatibilité des APIs existantes pour router le trafic vers le nouveau service. Afin de minimiser les risques il est préférable de router le trafic graduellement (canary deployment) en commençant par exemple avec 10% des requêtes vers le nouveau service. Si les signaux sont verts, augmenter le pourcentage jusqu’à arriver à 100%. Le weighted routing du service Route 53 permet de répondre à ce besoin.
On peut être tenté de vouloir changer l’API pour l’améliorer mais cela apporte un risque plus grand non nécessaire pendant la phase de migration. Il est préférable d’apporter ces modifications dans une seconde étape lorsque la migration sera effectuée.
Étape 7 : repenser la stratégie de test
La manière dont l’application est testée est également différente dans une architecture serverless.
Yan Cui explique que les tests unitaires ont un retour sur investissement moins important et qu’il faut donc se concentrer sur les tests d’intégration. Pour appuyer ses dires il donne en exemple le cas d’un endpoint sur API Gateway qui déclenche une Lambda pour écrire dans DynamoDB une ressource. Tester unitairement la Lambda a peu d’intérêt puisqu’il est plus intéressant de tester le processus de bout en bout pour vérifier que la ressource est bien présente dans DynamoDB.
Bien évidemment cela s’applique uniquement pour des cas simples où la Lambda ne contient pas de règle métier complexe puisqu’il faudrait dans ce cas faire autant de tests d’intégrations que de règles métiers.
Je reste dubitatif sur ce point car selon moi, même si la Lambda est simple il est toujours bon de la tester unitairement.
Il insiste également sur toujours privilégier l’utilisation des vrais ressources AWS lors des tests d’intégrations plutôt que d’utiliser des frameworks de mock tels que LocalStack par exemple.
Étape 8 : consolider le système pour qu’il soit robuste
Plusieurs points ici cités par Yan Cui :
- Mettre en place de l’observabilité sur toutes les briques. Une architecture serverless étant plus complexe de par son design, il est important de pouvoir tracer de bout en bout les requêtes et de pouvoir détecter les points de contention dans le système ;
- Utiliser des timeouts courts et adaptés aux différents processus ;
- Utiliser des files de messages (SQS par exemple) entre les différentes briques pour amortir le trafic ;
- Mettre en place le pattern SAGA pour faciliter le rollback des transactions si nécessaire ;
- Utiliser des circuit breakers pour éviter les failures en mode cascade ;
- Faire du chaos engineering afin de connaître les failles et limites de son système.
Conclusion
Le passage d’une architecture monolithe à une architecture serverless est un virage stratégique, organisationnel et technique qui ne doit pas être sous estimé. Les étapes décrites dans ce billet ont eu pour but de vous donner un point de départ sur les différents aspects de cette transformation. Pour vous accompagner dans cette conduite au changement, faites-vous aider par des experts !
