

Cet article fait partie d'une série visant à accompagner les entreprises dans leur migration d'un SI Big Data existant vers les offres cloud d'AWS.
Le but de cette série n'est pas de faire un comparatif détaillé sur l'intérêt d'une migration vers le Cloud ! Nous supposons que le choix est déjà fait et qu'il faut donc choisir parmi les solutions natives proposées par AWS.
Les solutions cibles favorisées sont les solutions natives équivalentes lorsqu'elles existent (Kinesis, DynamoDB, ...) et non les offres managées (solutions externes hébergées).
Nous avons donc privilégié le replatforming et non le lift and shift (Cf. stratégies de migration vers le cloud, les "6 R").
En effet, les solutions natives offertes par AWS présentent les avantages suivants :
-
Administration simplifiée et entièrement prise en charge par AWS,
-
Facturation plus avantageuse,
-
Solution parfaitement intégrée dans l'écosystème AWS.
Chacun des articles de la série va s'intéresser à une solution source très répandue dans le monde du Big Data et permettre :
-
De comprendre les différences fondamentales entre les solutions,
-
D'identifier les cas d'usage propices à la migration vers les solutions natives,
-
D'identifier les cas d'usage propices à la migration vers une solution managée.
Introduction
Elasticsearch, Apache Solr et CloudSearch sont des solutions d’indexation et de recherche textuelles. On trouve dans ces solutions des notions avancées qui permettent d’améliorer grandement l’expérience utilisateur dans ces systèmes, telles que la possibilité de trier les résultats par pertinence ou les résultats avec facettes.
Elasticsearch, la référence
La première version d’Elasticsearch est sortie en février 2010 par Shay Banon, et a été créée pour être une solution scalable, ayant une interface HTTP ainsi que des connecteurs pour de nombreux langages. Il s’agit toujours d’un projet open source sous license Apache 2.0 que vous pouvez retrouver ici. Elasticsearch, l’entreprise, a quant a elle été créée en 2012, renommée Elastic en 2015, et propose un ensemble d’outils (certains open sources, d’autres payants) autour d’Elasticsearch et une solution d’Elasticsearch managé dans le cloud (AWS ou GCP).
Elasticsearch est un moteur d’indexation et de recherche basé sur la bibliothèque Lucene qui est distribué, permettant notamment une recherche full-text. L’outil possède une interface HTTP et stocke des documents JSON. Il est écrit en Java, et possède des interfaces dans une multitude de langages.
Elasticsearch est très connu pour être la pierre centrale de la stack ELK : Elasticsearch, Logstash et Kibana (maintenant renommée Elastic Stack avec l’introduction de Beats).Il permet de faire notamment de l’analyse rapide de logs au travers de dashboards grâce à Kibana. De plus, d’autres produits, créés par l’entreprise Elastic, gravitent autour d’Elasticsearch, tels que Beats qui permet d’importer facilement des données à partir d’un grand nombre de sources, ou Site Search permettant d’intégrer facilement de la recherche dans un site web.
Apache Solr, le principal concurrent
Apache Solr est le principal concurrent d’Elasticsearch dans le monde open source. C’est une solution distribuée de recherche textuelle, basée elle aussi sur Lucene, qui est open source et distribuée sous licence Apache 2.0. Depuis 2011, le développement de Solr est intimement lié à Lucene, les améliorations de l’un sont donc directement disponibles pour l’autre.
De plus Solr est inclus dans les distributions HortonWorks, mais c’est aussi la solution choisie par Datastax pour faire de l’indexation sur la base Cassandra, facilitant ainsi son adoption. Il existe un certain nombre d’outils open source construits autour de Solr, tel que Banana, un fork de Kibana permettant de visualiser les données.
CloudSearch, la solution historique d’AWS
CloudSearch est la solution managée cloud d’Amazon Web Service pour adresser les problématiques de recherche dans les applications et les sites web, créée en 2012.
Le service a été mis à jour en 2013 pour une toute nouvelle API. CloudSearch utilise de façon sous-jacente Apache Solr, donc se base lui aussi sur Lucene.
CloudSearch entre dans l’écosystème AWS, c’est-à-dire qu’il va bénéficier simplement des outils AWS disponibles pour monitorer, sécuriser et scaler son cluster.
Elasticsearch et le cloud.
AWS a développé depuis quelques années (2015) une solution managée d’Elasticsearch sur son cloud. Ainsi on peut créer en quelques clics / commandes un index Elasticsearch automatiquement redondé dans AWS. Cette solution managée bénéficie de la même manière d’une intégration simplifiée dans l’écosystème AWS avec la gestion de la sécurité (VPC, IAM…), mais aussi de l’intégration à Kinesis Data Firehose, qui permet de déverser simplement des streams de données dans Elasticsearch. Enfin, une instance de Kibana est directement installée avec les nœuds Elasticsearch.
Concrètement, AWS Elasticsearch est une solution installée sur des instances EC2, mais dont on n’a pas besoin de gérer le scaling ni la redondance, tout cela étant managé par AWS. Il est important de noter que AWS Elasticsearch se base sur la distribution Open Distro, développée par AWS et rendue open source en mars de cette année, et donc ne possède pas exactement les mêmes caractéristiques que la version officielle.
Enfin, Elastic propose de déployer une instance Elastic Stack directement sur le cloud (AWS/GCP) sans passer par un tiers, qui sera managé par leurs soins. Elle est donc difficilement intégrable avec des solutions d’infrastructure as code (IaC) comme Terraform ni avec les solutions d’IAM d’AWS par exemple
Les différences entre les solutions
Je parlerai ici principalement des différences entre Elasticsearch, Solr et CloudSearch. De plus, je ferai des parallèles entre les avantages des solutions managées et des solutions on-premise.
Voici un petit diagramme récapitulatif des points d’attentions lors de la migration
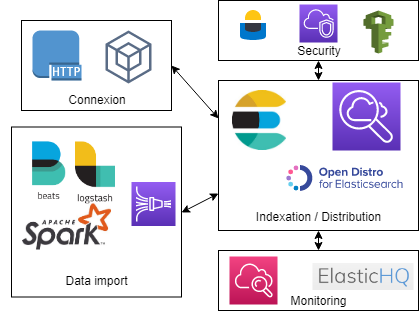
Connectivité
Malgré la liste des connectivités qui est très proche entre les solutions (API REST et langages supportés), la façon de se connecter change beaucoup. Cloudsearch se basant sur Solr, il possède la même connectique.
Enfin, la solution AWS Elasticsearch permet une connexion simplifiée pour le stockage des données avec une intégration avec Kinesis Data Firehose.
Alimentation des données
La façon d’importer les données dans le moteur d’indexation varie entre les solutions. Elasticsearch dispose principalement d’une alimentation via Logstash, autre produit de l’entreprise Elastic, permettant en premier lieu d’envoyer les logs d’un serveur vers Elasticsearch. S’ajoute à cela Beats, permettant d’ingérer des données provenant d’un grand nombre de sources différentes. De plus, Il est possible de créer soi-même son injecteur, pour envoyer ses données, ou d’utiliser un framework tel que Spark pour alimenter Elasticsearch.
CloudSearch, quant à lui, fonctionne par indexation de fichiers (JSON ou XML) en mode batch, c’est-à-dire qu’on va envoyer un fichier contenant un ensemble d’actions (ajout, suppression de documents) dont il exécutera les actions.
Il faut aussi noter qu’il n’y a pas de champ Enum ni de champ boolean dans CloudSearch contrairement à Elasticsearch. De plus il possède un support plus faible des nombres (seuls les types integer et double sont disponibles).
Enfin, la solution managée de AWS permet d’utiliser Kinesis Data Firehose comme source de type streaming afin d’ingérer des données.
Indexation de données
Lors de la création d’un index (ou d’un domaine sur CloudSearch), on peut définir l’utilisation d’algorithmes spécifiques pour la partie analyse et tokenisation des documents. Il y a moins de choix d’algorithmes chez CloudSearch que chez ses concurrents.
Sécurité : Shield et AWS
CloudSearch, étant dans l’écosystème de AWS, se permet de profiter de l’implémentation d’une sécurité assez poussée et de facilement gérer cette composante maintenant essentielle dans beaucoup d’entreprises, notamment pour le contrôle d’accès. L’utilisation de VPC, très conseillée, permet de limiter les possibilités d’accès à la base et donc de sécuriser l’accès aux données.
Concernant Elasticsearch on-premise, il est possible d’y apposer de la sécurité, et notamment du contrôle d’accès. Cependant il s’agit d’un service payant proposé par la société Elastic qui s’appelle Shield. Cette solution a l’avantage d’offrir une protection globale pour toute la stack Elastic, allant jusqu'à Kibana, mais aussi de faire du contrôle d’accès jusqu’au niveau du champ.
Monitoring
Pour passer de l’un à l’autre, il faut penser aux solutions de monitoring de notre cluster. Elasticsearch, grâce à sa communauté, propose des solutions telles que ElasticHQ qui permet de gérer simplement son cluster et ses index. Côté CloudSearch et solutions managées, on monitore principalement à l’aide de CloudWatch, qui utilise les métriques par défaut proposées par la solution.
Les différences entre Elasticsearch et Open Distro
La dernière différence notable entre les différentes solutions présentés est la distribution sur laquelle est construit le produit. Il existe en effet une distribution originale, celle maintenue principalement par Elastic et depuis environ un mois la distribution sur laquelle se base AWS Elasticsearch nommée openDistro. Elle possède des caractéristiques différentes que la distribution classique que je vous laisse découvrir ici. Par exemple AWS a ajouté à openDistro un service d’event monitoring et d’alerting.
Critères de choix solutions cibles
Le premier critère de choix est simplement l’utilisation d’un service managé, ce qui nous permet de ne pas avoir à gérer les machines sous-jacentes. Cela nous permet de facilement avoir accès à l'auto scaling, la sécurité ou même le monitoring.
Le second critère est le cas d’utilisation pour lequel on utilise Elasticsearch. Si on a besoin d’un cas d’utilisation simple et facilement administrable de recherche textuelle, on pourra partir sur CloudSearch. La solution AWS est certes peu fournie en algorithmes, mais possède l’essentiel pour une solution de ce type, et est plus simple à opérer que les autres solutions. De plus, la solution n’est pas prévue pour être nativement intégrée dans Kibana.
Enfin, si on possède déjà des infrastructures dans le cloud Amazon, on peut bénéficier pleinement des outils mis à disposition, ainsi qu’une connexion rapide et simplifiée entre les outils.
Cependant, il n’est pas conseillé de passer vers CloudSearch si on fait une utilisation de concepts avancés dans l’indexation notamment, utilisant des tokenizers particuliers, car certains de ces éléments n’y sont pas disponibles. Dès qu’une utilisation plus poussée d’Elasticsearch est nécessaire, on devra se tourner vers les solutions d’Elasticsearch managées.
Enfin, le dernier point d’attention est la non disponibilité de CloudSearch dans toutes les régions AWS, seule une dizaine de régions peuvent héberger la solution. Vous pouvez trouver toutes les informations sur ce sujet ici.
Migration
Migration des données, la théorie
Pour préparer la migration de vos données de Elasticsearch vers CloudSearch, il faut tout d’abord comprendre comment fonctionne l’ingestion et ses limites dans CloudSearch. Les principales limites à prendre en compte lors de cette phase sont :
-
La taille d’un batch est de 5 mo max,
-
La taille d’un document est 1 mo max,
-
Vous pouvez lancer 1 batch toutes les 10 secondes (Environ 10 000 batch pour 24 heures).
Les batchs peuvent être au format JSON ou XML, formés d’une liste, avec pour chaque document un id unique, un type (ajout ou suppression) et la liste des champs du document.
Il est possible d’augmenter la vitesse d’upload en augmentant la taille de la machine. Ainsi en prenant la machine la plus puissante, on peut exécuter un plus grand nombre de batches en parallèle.
Concernant la migration de données d’un Elasticsearch on-premise et d’un Elasticsearch managé dans le cloud, deux solutions s’offrent à vous. Vous pouvez faire de la même manière un dump de vos données, il suffit alors d’utiliser un outil de migration de données tel que elasticdump, qui permet notamment de migrer l’ensemble des données, analysers et indexes d’un cluster Elasticsearch vers un autre. Il faudra par contre bien prendre en compte que cela doit être fait sur une machine disposant des droits d’accès aux nœuds, et donc dans le VPC sur AWS par exemple.
La seconde solution est de faire une lecture pour réindexation dans le cluster sur le Cloud. Il est possible, à l’aide de la méthode scroll, ou simplement avec un connecteur tel celui de Spark, de lire l’ensemble de la donnée afin de la réécrire dans notre nouvel index (vous pouvez trouver un exemple de cluster EMR temporaire ici). Cela est très utile lorsque l’on a une très grande quantité de données et peut de plus permettre un traitement supplémentaire au besoin.
Migration du Code existant pour utiliser CloudSearch
Pour migrer le code d’Elasticsearch vers CloudSearch, la modification des appels REST nécessitera une adaptation. Les requêtes dans CloudSearch se font dans l’URL, de cette façon :
http://search-movies-rr2f34ofg56xneuemujamut52i.us-east-1.cloudsearch.amazonaws.com/2013-01-01/search?q=(and+(phrase+field='title'+'star wars')+(not+(range+field%3Dyear+{,2000})))&q.parser=structured
Pour Elasticsearch on est sur des requêtes dans le body de la requête. La plupart du temps les appels sont faits au travers d'un SDK, et c'est donc un nouveau SDK qu'il faudra utiliser dans son code pour passer de l'un à l'autre.
En plus de cette migration de code et de la migration des données, il ne faut pas oublier de mettre en place un processus de migration pour passer d’une base à l’autre. Pour cela, la procédure standard est d’ingérer les nouvelles données dans les deux bases en même temps, effectuer la migration de données historiques de la première vers la seconde et enfin de migrer le code vers la nouvelle base de données.
Gestion des Contrôles d'accès et sécurité
Afin de faire fonctionner parfaitement CloudSearch, il ne faut pas oublier d’appliquer le contrôle d’accès de AWS : le service doit être dans un subnet public avec une IP publique si on doit l'appeler à partir d’une application externe, ou bien dans un subnet privé pour que seules vos applications dans le même subnet puissent y accéder.
Il est fortement conseillé d’installer Elasticsearch, dans le cas où il est managé par AWS, dans un VPC privé, avec un contrôle d’accès par ressource géré par l’IAM. Vous pourrez ensuite vous connecter aux machines au travers d’un bastion qui aura les droits d’accès aux nœuds et/ou au Kibana. De plus, il est fortement conseillé de chiffrer les données, paramètre disponible lors de la création du cluster sur AWS.
Estimation du coût AWS
Quels sont les leviers de facturation ?
La facturation AWS pour CloudSearch s’articule autour de trois principaux leviers. Le premier est l'exécution des batchs que l’on lui envoie, et qui coûte 0,1$ / 1 000 batchs (1 batch = 5 mo max)
Ensuite, la facturation dépend des instances sous-jacentes choisies pour CloudSearch et si on choisit le multi AZ. Chaque type d’instance coûte plus ou moins cher selon sa puissance.
Enfin, le dernier point concerne la réindexation manuelle des documents. On peut demander à CloudSearch de réindexer l’ensemble des documents, par exemple en ajoutant un champ à indexer. Cela coûte 0,98 $/go et n’est facturé que lors des actions manuelles, et non lors des indexations automatiques par CloudSearch.
Vous pouvez trouver tous les points de facturation, dépendant de la région cible, ici.
Concernant AWS Elasticsearch, la facturation est faite comme telle :
-
Prix des machines EC2 sous-jacentes à l’installation d’Elasticsearch selon votre besoin (avec les modifications tarifaires en cas d’utilisation d’instances réservées par exemple),
-
Prix du stockage EBS (si applicable) qui est environ de 0,11 $ par go-mois de stockage prévu. Plus d’informations ici.
Il est à noter que l’utilisation des snapshots n’est pas facturée. Vous trouverez les prix précis de chaque type d’instance pour chaque région ici.
Elastic propose une tarification qui, à l’instar de celle d’AWS, s’appuie principalement sur les machines qui feront tourner le cluster. À l’aide de leur calculateur, on peut voir rapidement ce qui sera déployé et le taux horaire / mensuel.
Estimation
Estimation de coûts pour une migration d’un Elasticsearch de 100 go avec des documents de 2Ko moyen vers un CloudSearch. On prendra comme région EU-Irlande et une augmentation de 500 000 documents par jour (1 go environ).
- Coût de migration (one shot)
On possède environ 50 millions de documents, et on peut mettre plus ou moins 2 500 documents par batch. Cela nous fait 20 000 batches pour remplir notre CloudSearch.
On va prendre la machine la plus puissante, qui nous permet de faire 16 insertions en parallèle, cela nous prendra donc environ 3,47 heures pour tout insérer. On aura donc comme coût :
20 000 Batches = 2 $
Instance search.m3.2xlarge = 0,832 $ * 3,47 = 2,89 $
On paiera donc 4,89 $ pour insérer l’ensemble de nos données.
- Coûts de maintenance (récurrent)
Par jour nous aurons 200 batches, ce qui coûte 0,02 $. Pour soutenir la charge, nous avons 3 instances search.m2.xlarge qui coûtent 0,104 $ par heure.
Sur un mois on arrive à : 0,02 * 30 + 3 * 0,104 * 24 * 30 = 225 $/mois
Estimation des coûts d’un Elasticsearch + Firehose
Afin de gérer une infrastructure équivalente, nous allons prendre une instance redondée en stockage optimisé afin de tenir la charge, à 0,275 $ de l’heure (i3.large.elasticsearch). Avec cette instance, nous n’avons pas besoin de stockage EBS, donc le coût de stockage est inclus dans l’instance. On obtient une tarification de 198 $ par mois.
Afin de faire la migration des données déjà existantes, il vous sera facturé la bande passante AWS comme pour toute migration. Cependant, si vous souhaitez utiliser son intégration avec Firehose pour l’ingestion des données, le prix de ce service doit être pris en compte. Si on reprend notre exemple, avec 500 000 objets par jour pesant 2 ko (devant être arrondis à 5 ko pour Data Firehose), avec une tarification à 0,031 $ par Go ingéré pour les 500 premiers to, on obtient 2,38 Go par jour et donc une tarification à 2,28 $ par mois. On a donc un coût de fonctionnement avoisinant les 200 $ par mois.
Estimation des coûts Elastic
Afin de gérer une infrastructure équivalente, nous n’avons pas besoin d’un gros cluster. Cependant, nous souhaitons une redondance sur 3 availability zones, avec des instances capables de tenir la charge principalement en I/O, ainsi qu’une instance de Kibana afin de rester sur quelque chose de comparable. Nous en arrivons donc à une estimation de 255 $ par mois environ.
Comparaison des prix
| CloudSearch | AWS Elasticsearch | Elastic managé |
| 225$ | 200$ | 250$ |
Conclusion
Elasticsearch, Solr et CloudSearch ont, sur la plupart des features nécessaires pour un moteur d’indexation, les mêmes caractéristiques. Les différences se feront principalement sur les notions avancées et les utilisations poussées des différents outils d’indexation, qui sont moins importants du côté de CloudSearch. Jevous conseillons donc de vous tourner vers cette solution dans le cas où votre utilisation d’Elasticsearch est centrée sur de la recherche textuelle. Cependant, pour une utilisation plus poussée, par exemple pour de l’indexation de logs ou l’utilisation dans le cadre d’applications de monitoring, il faudra passer par une installation personnelle ou l’utilisation d’une solution managée d’Elasticsearch.
La complexité de la migration réside principalement sur les connexions vers l’outil, qui changent grandement entre les solutions.
La différence de prix entre les solutions ne nous permettent pas de définir un clair gagnant, d’autant plus que les instances proposées ne sont pas les mêmes entre les solutions de management. Cependant, comparativement au fait d’avoir trois serveurs (afin d’avoir la donnée répliquée comme sur 3 availability zones) qui sont maintenus par une équipe, et le prix de la migration elle-même étant très faible, cela peut valoir le coup pour beaucoup d’organisations de passer sur une solution cloud managée.
Il faut aussi noter que Google a présenté sa solution d’Elasticsearch managé, au cœur d’un grand nombre d’annonces de solutions managées.
Aller plus loin
Comparaison Solr, CloudSearch et Elasticsearch
Solr
CloudSearch
Elasticsearch
CloudSearch limits
Preparing data for cloudsearch
CloudSearch scaling
Disponibilité des services par régions
Sizing cloudsearch
Elasticsearch managé par Elastic
Elasticsearch sur GCP
Le prix d’une architecture serverless
