

Dans la 1ere partie, je vous ai présenté cloudWatch dans l'utilisation des métriques, de la surveillance de ces métriques et la gestion des événements.
CloudWatch dispose également d’une gestion des logs très pratique pour démarrer dans de bonnes conditions une production.
4.1. CloudWatch & Log Group
CloudWatch ne permet pas seulement de gérer des métriques et de les utiliser. Il sert également à remonter des logs, qu’ils s’agissent de logs système ou de logs applicatives.
Ces logs seront consultables depuis la console (pour les personnes qui ont les droits de consulter CloudWatch).
En plus de récupérer les logs, vous pouvez appliquer des pattern sur vos logs pour récupérer par exemple le nombre de code erreur sur une durée.
Dans le fichier de configuration de l’agent CloudWatch, il y a une section pour récupérer des logs et les envoyer dans CloudWatch. Chaque fichier envoyé créé une entrée dans “log group”.
Voici un exemple en terraform pour récupérer l’un de ces “log groups” :
#######################
# NGINX
# - Recuperation du loggroup prod-nginx (log nginx)
#######################
data "aws_cloudwatch_log_group" "logs_nginx" {
name = "prod-nginx"
}
Créons ensuite un “log-metric-filter” : il faut évidemment que vos lignes soient formatées selon un certain nombre de champs. Par exemple, les lignes nginx sont découpées par des blancs et donnent les informations suivantes : ip, vide1, vide2, timestamp, request, status_code, size, champ1, agent.
Sur “Status_code”, on veut compter le nombre de codes erreur 5xx (toutes les erreurs 500). Le pattern de comptage sera donc :
[ip, vide1, vide2, timestamp, request, status_code=5*, size, champ1, agent]
Vous pouvez tester vos patterns de découpage de vos chaines depuis la console et via l’appel à la cli :
aws logs test-metric-filter --filter-pattern '[ip, vide1, vide2, timestamp, request, status_code=5*, size, champ1, agent]' --log-event-messages AA.BB.CC.DD - - [14/Nov/2018:10:26:09 +0000] "POST /myapp/myOperation HTTP/2.0" 200 836 "-" "curl"'
Je vous invite à lire la doc AWS sur ce sujet pour voir ce qu’il est possible de faire :
https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/FilterAndPatternSyntax.html
La création du log-metric-filter se fait comme suit en terraform :
#######################
# NGINX
# - Creation du log-metric-filter sur les lignes en HTTP 5xx
#######################
resource "aws_cloudwatch_log_metric_filter" "nginx_prod_errors5x_filter" {
name = "NginxHTTP5xxCount"
pattern = "[ip, vide1, vide2, timestamp, request, status_code=5*, size, champ1, agent]"
log_group_name = "${data.aws_cloudwatch_log_group.logs_nginx.name}"
metric_transformation {
name = "NginxHTTP5xxCount"
namespace = "LogMetrics"
value = "1"
default_value = "0"
}
}
C’est terminé. On vient de créer une métrique “NginxHTTP5xxCount” dans le namespace “LogMetrics”. On pourra donc ajouter des alarmes sur cette métrique et se les faire notifier.
Une stack très répandue dans les équipes de prod est : ELK, pour ElasticSearch - LogStash - Kibana. De nombreuses productions utilisent cet outil pour indexer leurs logs. Voyons dans le § suivant, comment mettre en place facilement ce dispositif.
4.2. ELK
Avant de commencer, quelques considérations sur l’utilisation de cette stack. Monter une stack ELK “en soit” est relativement simple. Ce qui est plus compliqué c’est de la rendre scalable.
Bien que pratique et totalement intégrée avec CloudWatch, AWS ne fournit pas une architecture ELK qui se redimensionne automatiquement en fonction de l’utilisation. Le principe est de tailler votre infrastructure (aussi bien en terme de “compute” et que de volumétrie) à la création.
Le principe de fonctionnement est le suivant :
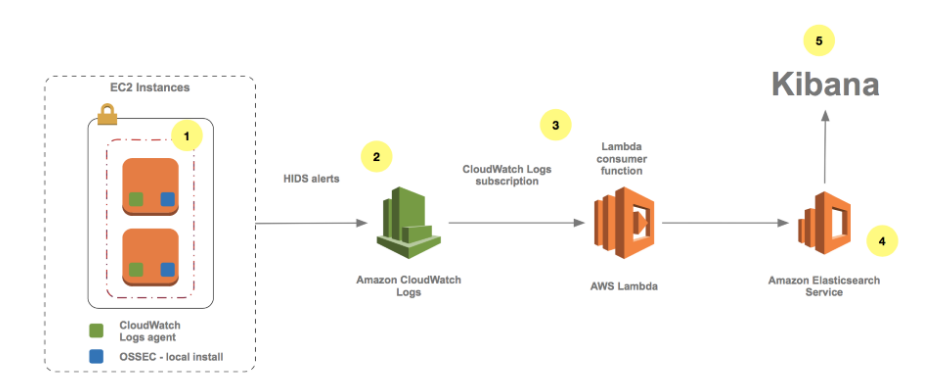
C’est encore une fois une fonction Lambda qui va être invoquée par Cloudwatch Logs à chaque nouvelle entrée de logs dans un LogGroup. Cette notification se fait sur un filtre permettant de désigner un ou plusieurs LogGroup(s).
La fonction Lambda transmet les logs dans un format JSON au service ElasticSearch d’AWS en les associant avec les valeurs des filtres.
Il est ensuite possible de visualiser les entrées dans ElasticSearch grâce au client Kibana fourni avec le service AWS ElasticSearch.
Pour créer un domaine ElasticSearch via la console, voici la procédure :
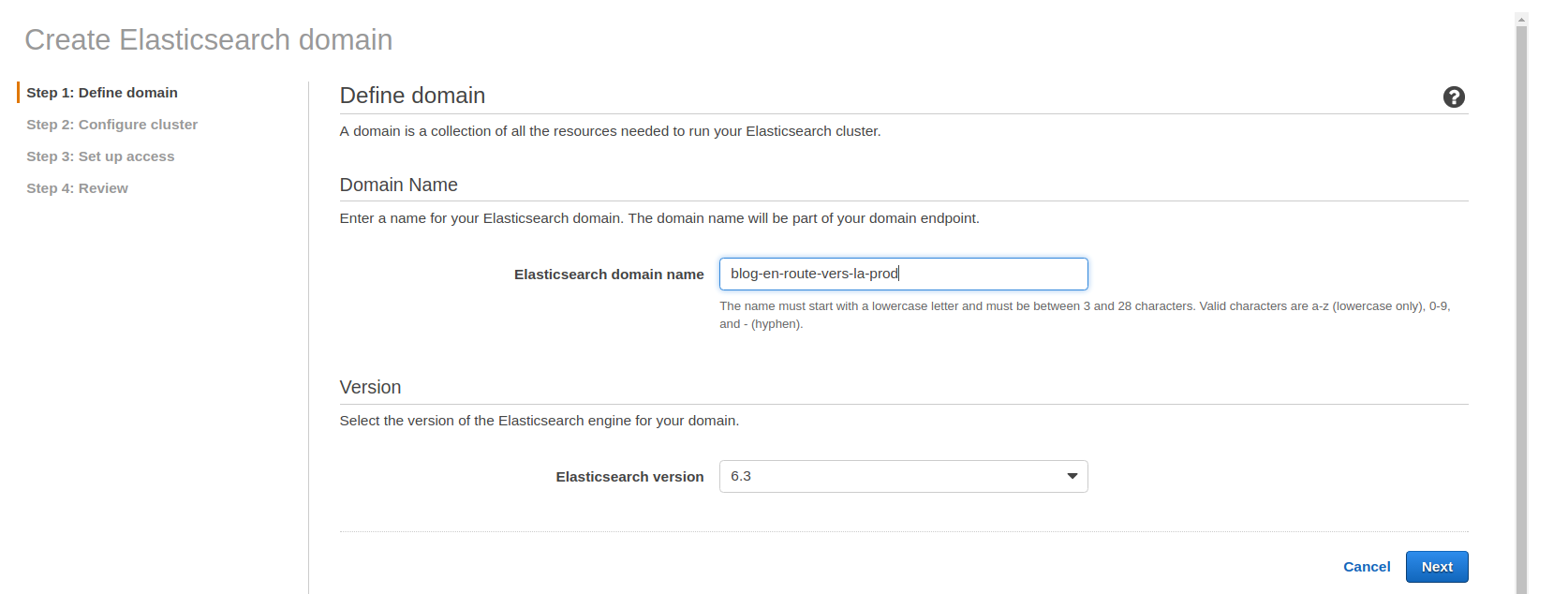
Renseignez le nom de votre cluster et la version d’ElasticSearch.
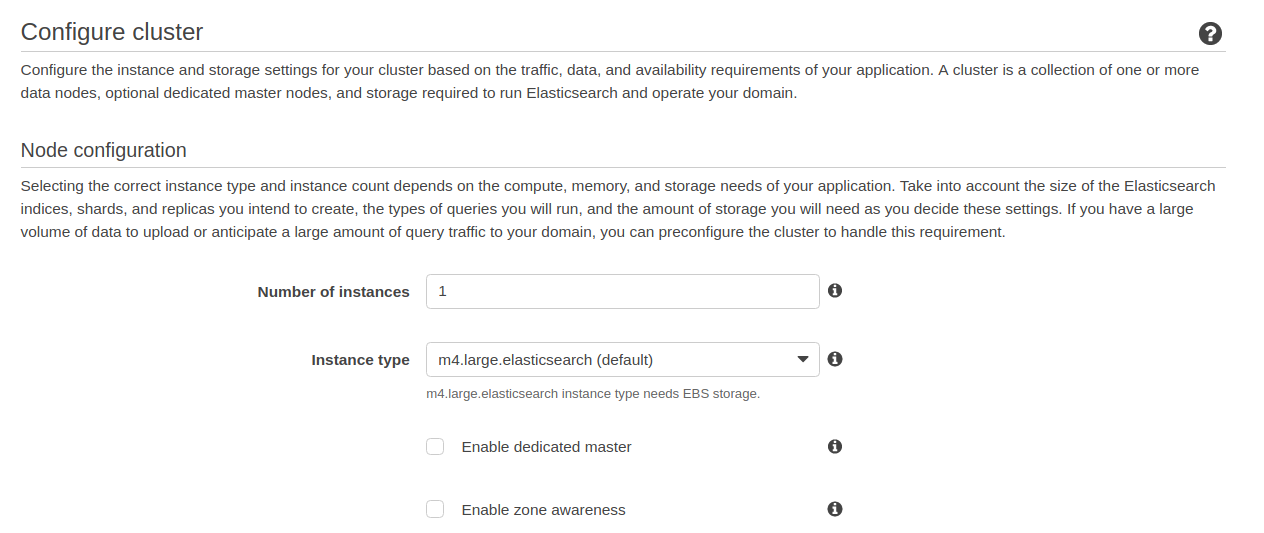
Ici, il faut tailler votre cluster (nombre d’instances et type d’instance).
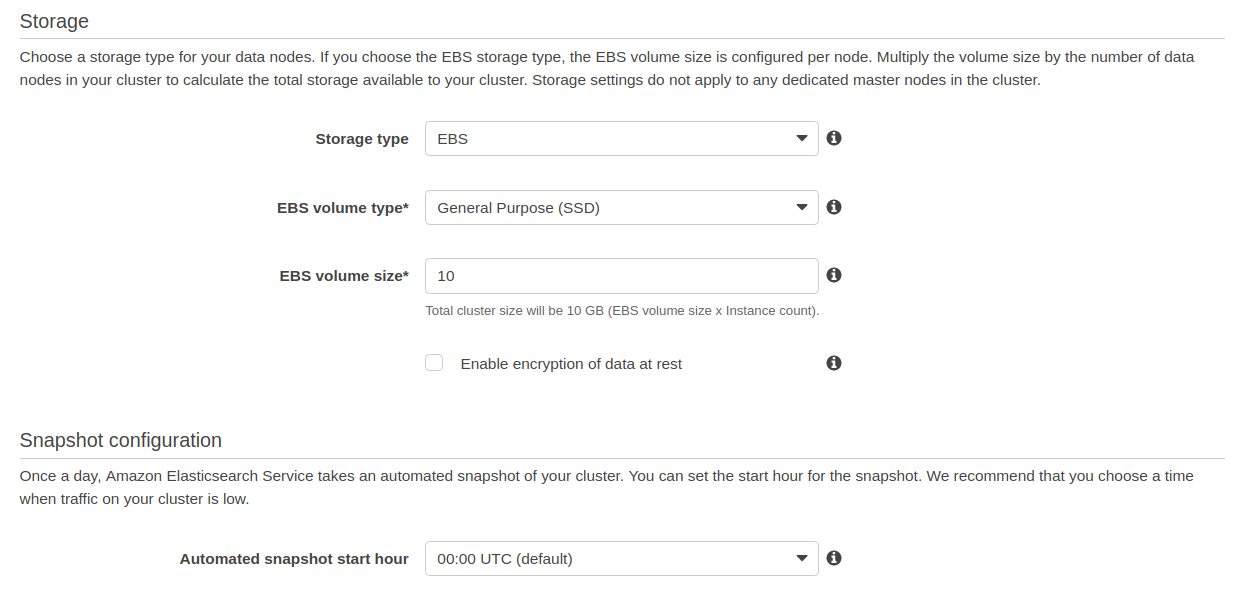
Ensuite, côté stockage, remplir les champs selon la volumétrie estimée.
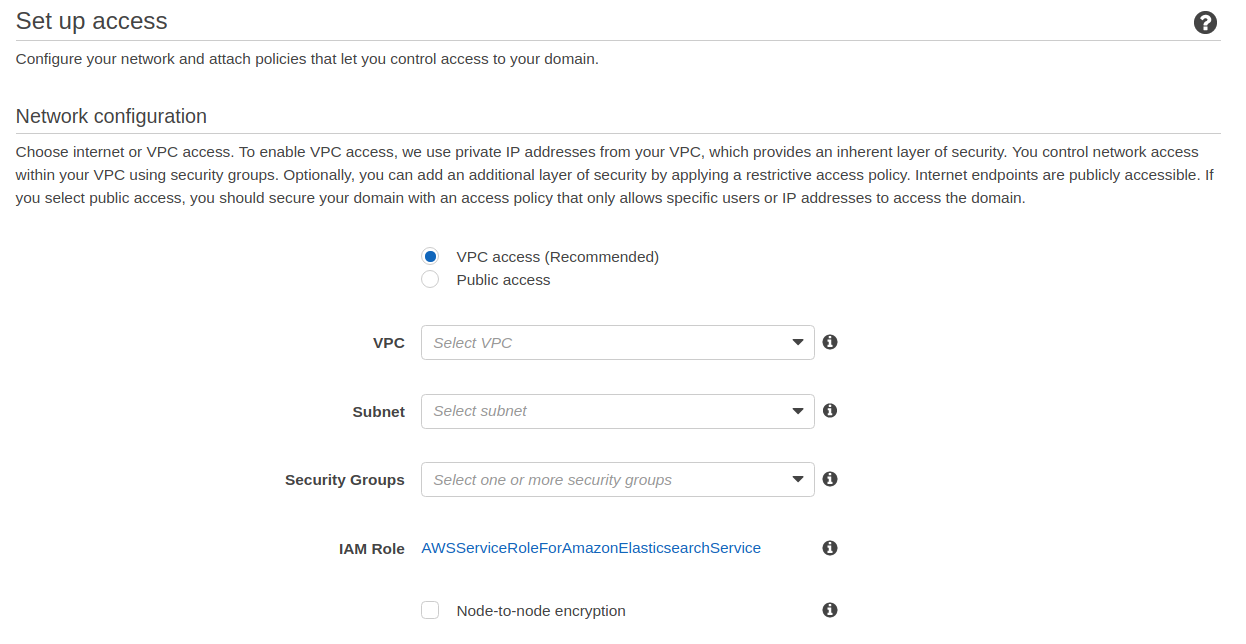
Ensuite, il est nécessaire de spécifier les accès au cluster ElasticSearch. Laisser “VPC Access”, sélectionner votre VPC, le subnet dans lequel vous voulez le mettre et choisissez le SecurityGroup qui régira vos accès réseau sur le cluster.
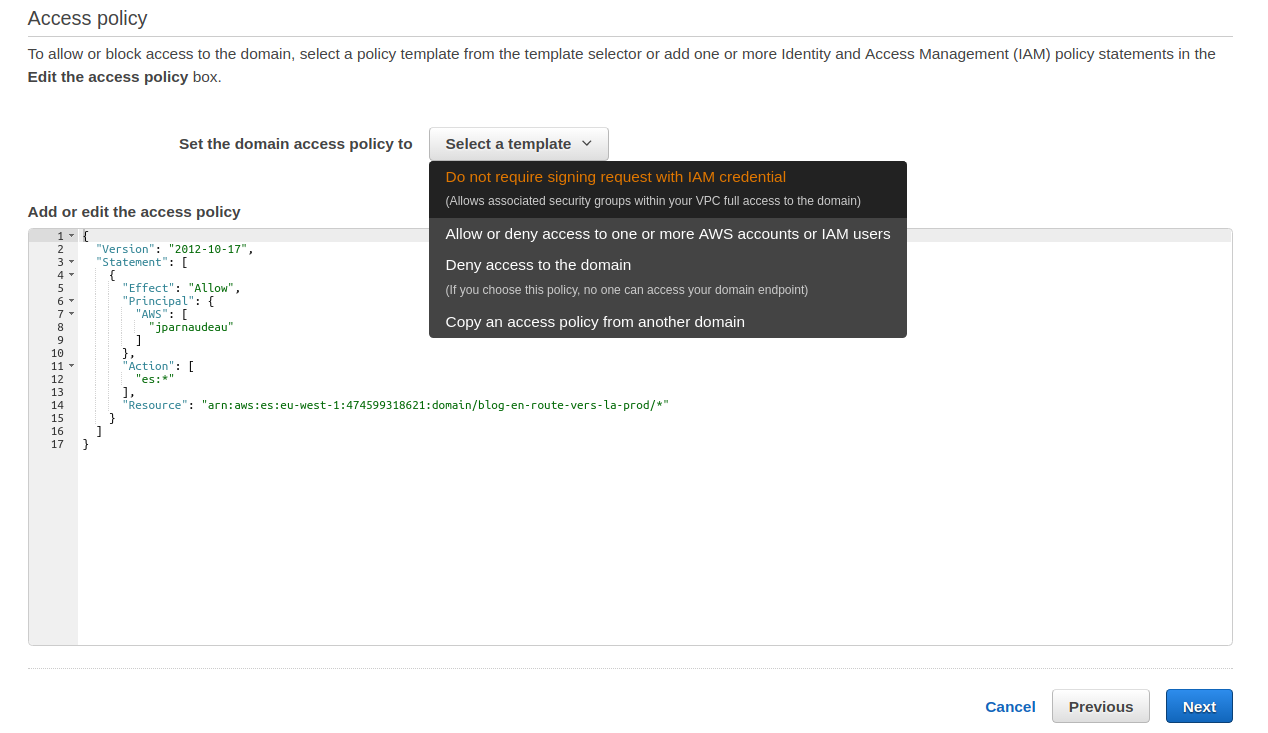
Enfin, définissez les ressources qui seront autorisées à se connecter. AWS fournit plusieurs “template de policy”, dont notamment “Allow or deny access to one or more AWS accounts or IAM Users”.
Une fois votre cluster ElasticSearch créé, vous disposez d’un accès à votre kibana :
https://
Remarque : c’est une adresse joignable uniquement au sein de votre vpc (si à la création vous avez coché “VPC Access”). Il vous faudra donc très certainement faire un forwarding de port pour vous y connecter :
ssh -L 8443:<aws_elasticsearch_private_ip>:443
Reste à écrire la fonction Lambda. Pour cela, vous pouvez commencer par faire un tour sur la console, dans les blueprints qu’AWS vous propose :
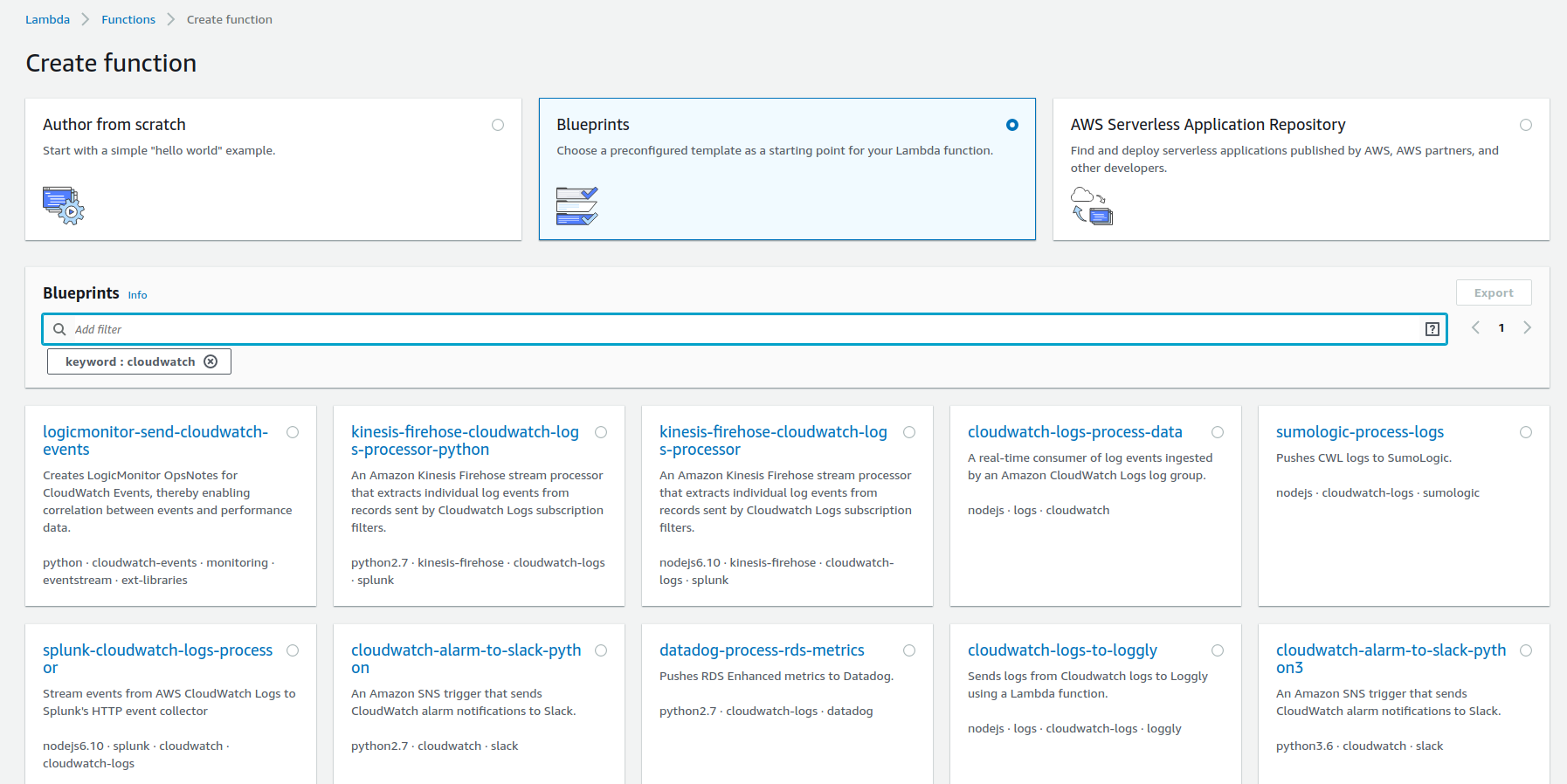
Pour effectuer l’envoi d’un flux d’un LogGroup vers ElasticSearch, vous pouvez vous inspirer du lien suivant :
https://gist.github.com/torgeir/aa3c28c336fc977b9ebf10784bc1a666
function transform(payload) {
if (payload.messageType === 'CONTROL_MESSAGE') {
return null;
}
var bulkRequestBody = '';
payload.logEvents.forEach(function(logEvent) {
var timestamp = new Date(1 * logEvent.timestamp);
var indexName = [
'cwl-' + payload.logGroup.toLowerCase().split('/').join('-') + '-' + timestamp.getUTCFullYear(), // log group + year
('0' + (timestamp.getUTCMonth() + 1)).slice(-2), // month
('0' + timestamp.getUTCDate()).slice(-2) // day
].join('.');
var source = buildSource(logEvent.message, logEvent.extractedFields);
source['@id'] = logEvent.id;
source['@timestamp'] = new Date(1 * logEvent.timestamp).toISOString();
source['@message'] = logEvent.message;
source['@owner'] = payload.owner;
source['@log_group'] = payload.logGroup;
source['@log_stream'] = payload.logStream;
var action = { "index": {} };
action.index._index = indexName;
action.index._type = payload.logGroup;
action.index._id = logEvent.id;
bulkRequestBody += [
JSON.stringify(action),
JSON.stringify(source),
].join('\n') + '\n';
});
return bulkRequestBody;
}
C’est dans cette fonction qu’on découpe la ligne selon les champs qui la compose. Ceux-ci seront utilisables tels quels dans vos dashboards kibana.
Côté sécurité, il faudra comme toujours créer un rôle et l'associer à votre fonction Lambda. Ici, le rôle devra contenir les policy suivantes :
AWSLambdaVPCAccessExecutionRole : Permet d’accéder aux ressources d'un VPC
une custom policy permettant de pousser des éléments sur ElasticSearch :
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:*:*:*"
]
},
{
"Effect": "Allow",
"Action": "es:ESHttpPost",
"Resource": "arn:aws:es:*:*:*"
}
]
}
Pour terminer, il est nécessaire de purger les logs dans votre cluster. Cela peut se faire avec la commande suivante :
curl -X POST "<elasticsearch_hostname>/*/_delete_by_query" -H 'Content-Type: application/json' -d '{"query": {"range" : {"@timestamp" : {"lte": "'"$(date +'%Y-%m-%dT%H:%M:%SZ' --date='1 week ago')"'"} }}}'
Vous pouvez également créer une fonction Lambda avec un déclenchement à intervalle régulier :
import boto3
from requests_aws4auth import AWS4Auth
from elasticsearch import Elasticsearch, RequestsHttpConnection
import curator
host = 'myes-6ybe2lffffffdcxmd2u6hoddm.eu-west-2.es.amazonaws.com'
region = 'eu-west-2'
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
# Lambda execution starts here.
def lambda_handler(event, context):
# Build the Elasticsearch client.
es = Elasticsearch(
hosts = [{'host': host, 'port': 443}],
http_auth = awsauth,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection
)
index_list = curator.IndexList(es)
# Filters by age, anything with a time stamp older than 30 days in the index name.
index_list.filter_by_age(source='name', direction='older', timestring='%Y.%m.%d', unit='days', unit_count=30)
print("Found %s indices to delete" % len(index_list.indices))
# If our filtered list contains any indices, delete them.
if index_list.indices:
for index in index_list:
print(index)
Je m’arrête là. On a très facilement mis en place notre cluster ElasticSearch et envoyé nos logs sur celui-ci. Il ne reste plus qu’à créer des dashboards dans Kibana sur les différents champs composant une ligne de log.
Dernière remarque mais non des moindres : l’utilisation d’un cluster ElasticSearch et de fonctions Lambda ont un coût. Compter environ 120 $ / mois pour une application qui génère des logs dans une volumétrie “normale” (4 Go / jour).
