

Cet article est un tutoriel ayant pour objectif de créer une application qui supervise les métriques disponibles d'un ordinateur, "Activity Monitor" sur MacOS, ou bien "Task Manager" sur Windows. Si vous souhaitez visualiser le projet dans son intégralité, le repo Github est disponible ici.
Il n'est pas nécessaire d'être un expert certifié sur les technologies que je vais présenter pour comprendre cet article, au contraire il faut le voir comme un tremplin afin de mieux les appréhender. Cependant une compréhension (même sommaire) de leurs fonctions est toujours intéressante. La consultation préalable des documentations Kafka, ELK et Docker ne peut être que bénéfique.
Présentation
Afin d'apprendre des technologies avec un exercice pratique et de ne pas rester avec une simple connaissance théorique je me suis lancé ce challenge de supervision. La stack technique utilisée est la suivante :
- Kafka : Il s'agit d'un outil, hautement scalable, mettant à disposition des journaux de logs distribués, les Topics. Ceux-ci peuvent être (grossièrement) assimilés à des files de messages. Des applications, Producers, produisent des données, Logs, qu'ils envoient dans un Topic Kafka. De l'autre côté, d'autres outils, Consumers, viennent récupérer ces messages pour les traiter. Ici, les métriques produites par un script Python (Cf partie Visualisation) seront envoyées dans un Topic Kafka.
- Zookeeper : Brique technique permettant à des systèmes distribués de partager un état de manière centralisée, répliquée et hautement disponible. Il est indispensable au bon fonctionnement de Kafka (même avec une seule machine, single node).
- ELK pour Elasticsearch, Logstash et Kibana est une stack fréquente aujourd'hui. Elle permet de transformer, rechercher et analyser des données.
- Logstash : ETL (Extract Transform Load) permettant de récupérer des données, les transformer et filtrer puis de les charger ailleurs. Ici, logstash consomme les logs de Kafka, les filtre/enrichit puis les transmet à Elasticsearch.
- Elasticsearch : Outil permettant d'indexer et rechercher des données. Sous le capot, l'indexation fonctionne avec Apache Lucene. Ici, il permet de stocker les données pré-processées par Logstash puis de les exposer à Kibana.
- Kibana : Outil permettant la visualisation de données présentes dans Elasticsearch. Ici, il est utilisé pour explorer et visualiser les données présentes dans Elasticsearch.
- Docker : Chaque brique technique utilisée dans cet exemple est packagée dans une image Docker. Les différents conteneurs seront ici orchestrés avec Docker Compose. Cet outil permet aussi d'installer avec une seule commande toute une stack avec un réseau privé dédié. J'ai décidé de conteneuriser l'application afin d'avoir des environnements ISO, quel que soit l'OS et aussi de faciliter et automatiser l'installation.
L'architecture se présente comme telle :
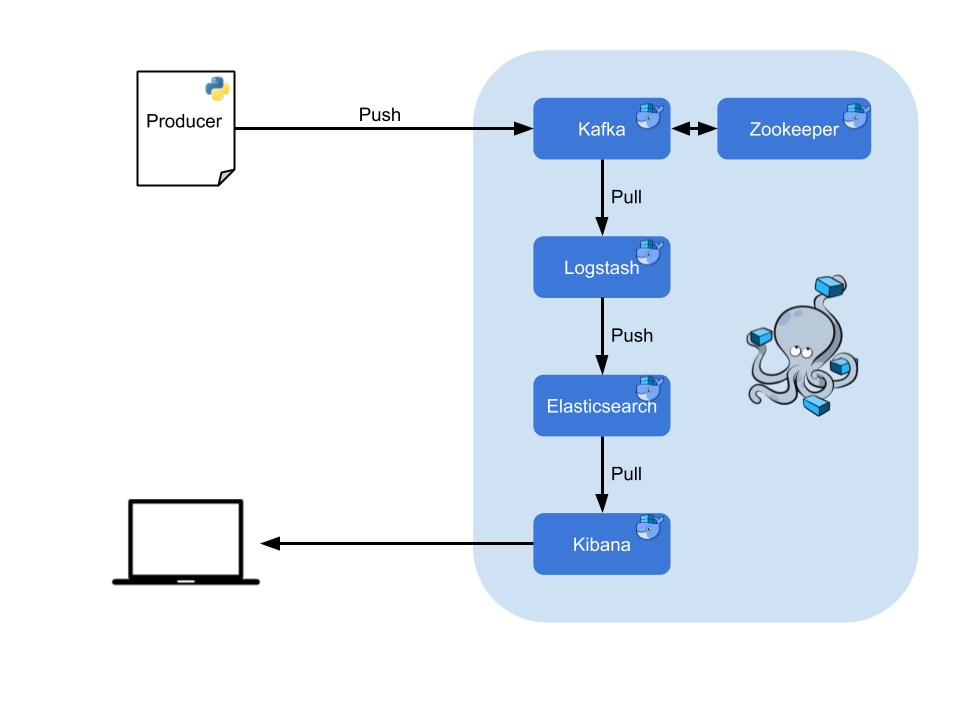
Ces technologies sont couramment utilisées dans des contextes distribués, c'est-à-dire avec des ressources ne se trouvant pas au même endroit. Par exemple, des groupes de machines travaillant en parallèle, des clusters. Le temps de traitement est donc accéléré. Cette stack parait bien évidemment trop lourde compte tenu de la problématique initiale : monitorer les métriques d'un ordinateur. Néanmoins, l'objectif pédagogique de l'exercice justifie leur utilisation.
Lancement de la stack
Il n'est pas utile de réinventer la roue, j'ai donc joint deux repos Github afin de créer ma propre configuration. Ces deux projets étaient pratiques pour commencer, car directement fonctionnels et abordables :
- docker-elk (v. 6.5.2) permet de lancer un Docker Compose avec les éléments de la stack ELK.
- kafka-docker (v. 2.12 - 2.10) permet d'avoir un broker Kafka avec son Zookeeper.
Ces deux projets possèdent bien des options lors du lancement des stacks, mais ici les éléments basiques sont utilisés afin de monter l'architecture rapidement.
L'étape suivante consiste en l'intégration du dossier kafka-docker dans docker elk afin d'avoir un seul et même Docker Compose gérant l'ensemble des conteneurs. L'arborescence du dossier ressemble à la suivante (certains fichiers inutiles à mon exemple ont été supprimés au préalable pour une meilleure lisibilité) :
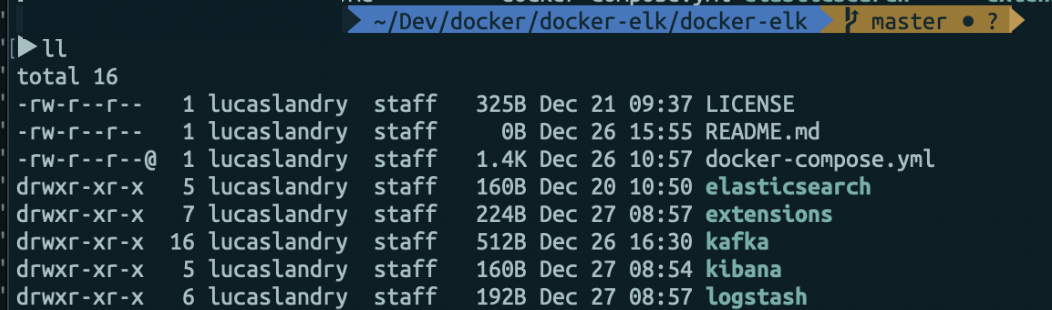
Une fois déplacé dans ce dossier, le docker-compose.yml doit être modifié afin de créer des instances Kafka et Zookeeper. Il faut alors ajouter les lignes suivantes en début de fichier :
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
build:
context: kafka/
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: ${DOCKER_KAFKA_HOST}
KAFKA_CREATE_TOPICS: "metrics:1:1"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
container_name: kafka
volumes:
- /var/run/docker.sock:/var/run/docker.sock
depends_on:
- "zookeeper"
...
Ici nous créons le conteneur ZooKeeper avec lequel Kafka va communiquer, sur son port 2181. Lors du build du conteneur Kafka, la création du topic "metrics" sera effectuée. Celui-ci n'utilisera qu'une partition avec un seul réplicat (oui oui, tout va bien se dérouler dans cet exemple...).
Tip: Afin d'assurer (sur MacOS) le bon fonctionnement de Kafka, je n'ai pas utilisé localhost comme hostname mais la variable d'environnement DOCKER_KAFKA_HOST initialisée dans le .bashrc par la commande :
export DOCKER_KAFKA_HOST=$(ipconfig getifaddr en0)
En lançant docker-compose up à la racine du projet, tous nos conteneurs sont créés et fonctionnels. Mais la configuration actuelle de notre Logstash ne nous permet pas aujourd'hui de lire dans un topic Kafka, il suffit alors de modifier le fichier logstash.conf afin qu'il réponde à nos besoins.
input {
kafka {
bootstrap_servers => "kafka:9092"
topics => ["metrics"]
codec => json
}
}
##filter {
## Add your filters / logstash plugins configuration here
##}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "metrics-index"
}
}
Cette configuration permet de lire les messages dans le topic Kafka "metrics" et de les écrire dans Elasticsearch sous l'index "metrics-index". Seuls les messages JSON sont acceptés ici, mais d'autres règles peuvent être appliquées dans la partie filter, selon le use case.
Il ne reste ensuite plus qu'à lancer le docker compose.
$ docker-compose up --build
L'option build est ajoutée car elle permet de reconstruire les images s'il y a eu du changement dans le code. Option inutile si les images Docker n'ont pas changé.
Visualisation
Le prétexte pour jouer avec toutes ces technologies est de visualiser les métriques de son ordinateur en temps réel, pour cela il faut les produire. J'ai donc écrit un script Python, fonctionnant sur tous les OS, qui récupère les pourcentages de RAM, de CPU et de disque utilisés. Ce script n'a naturellement pas vocation à être utilisé dans un contexte de production. Nous pouvons récupérer plusieurs autres données, tant la librairie psutil est complète.
from kafka import KafkaProducer
from kafka.errors import KafkaError
import psutil
import time
import json
def on_send_success(record_metadata):
print('Topic: ' + record_metadata.topic)
print('Partition: ' + record_metadata.partition)
print('Offset n°' + str(record_metadata.offset))
def on_send_error(excp):
log.error('Error: ', exc_info=excp)
producer = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer=lambda x:
json.dumps(x).encode('utf-8')) #1
while(1):
activity = {}
cpu_percent = psutil.cpu_percent()
memory_percent = psutil.virtual_memory()[2]
disk_percent = psutil.disk_usage('/')[3]
ts = int(round(time.time()))
activity['cpu_percent'] = cpu_percent
activity['disk_percent'] = disk_percent
activity['memory_percent'] = memory_percent
activity['timestamp'] = ts
producer.send('test', activity).add_callback(on_send_success).add_errback(on_send_error) #2
producer.flush()
time.sleep(0.1)
En #1, un producer Kafka sérialise les objets au format JSON. En #2, il envoie les données tout en récupérant la réponse en cas de succès ou d'erreur.
Les données sont alors indéxées dans Elasticsearch, une fois pré-processées par Logstash.
La visualisation peut désormais se faire directement sur l'UI de Kibana (http://localhost:5601).
Il faut alors créer l'index pattern dans l'onglet "Management", puis la visualisation que l'on souhaite dans l'onglet "Visualize". La configuration suivante permet par exemple de créer un graphique affichant le pourcentage du CPU utilisé en fonction de l'heure. On agrège selon le maximum afin d'avoir un graphique lisible, l'intervalle d'agrégation est géré par Kibana dans cet exemple.
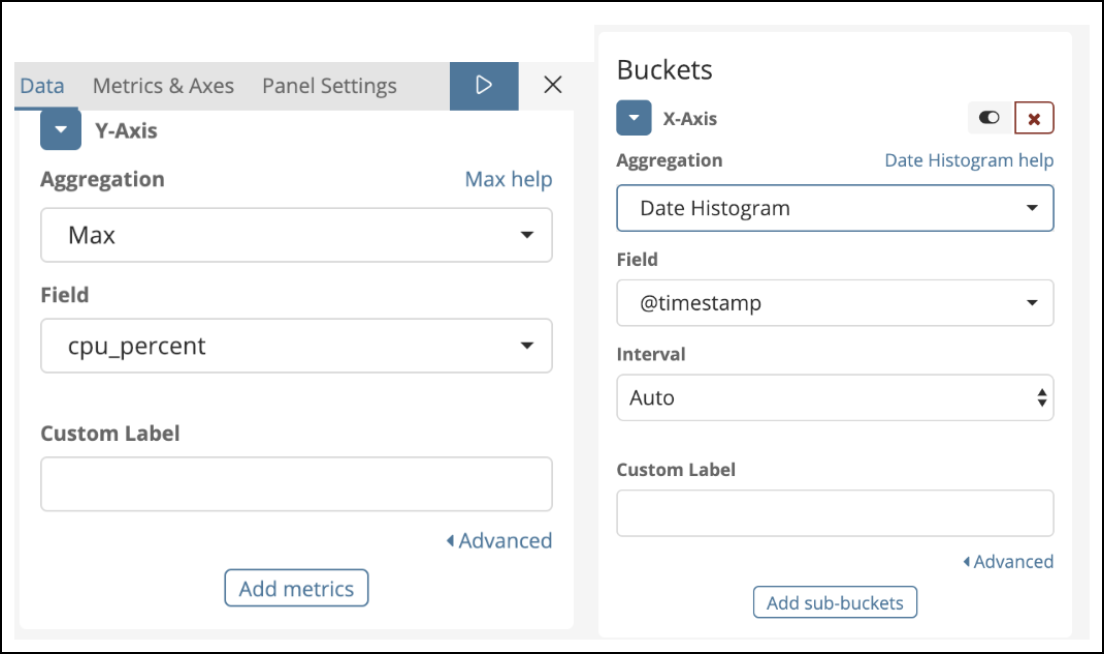
Une fois les graphiques créés, il ne reste plus qu'à les ajouter à un tableau de bord dans l'onglet "Dashboard".
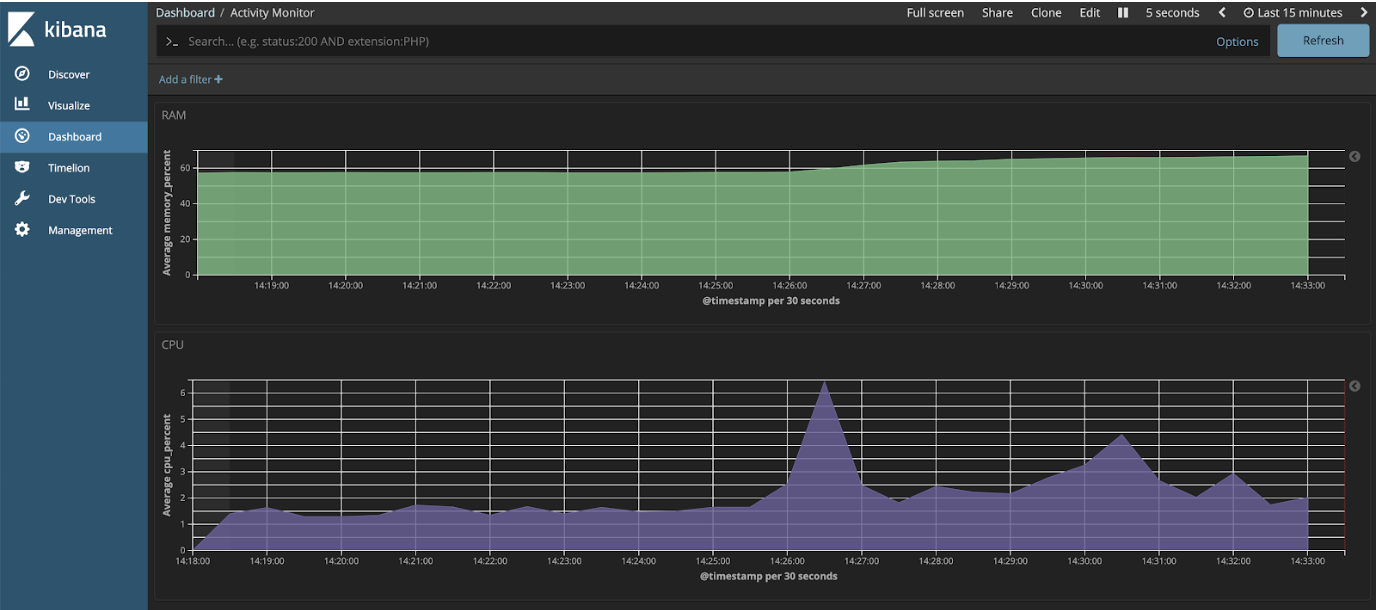
Nous avons désormais en local un Activity Monitor assez simple. Il est bien évidemment customisable autant que votre imagination et les librairies Python l'autorisent. Kibana nous offre une multitude de widgets avec lesquels il est possible de jouer et ainsi améliorer notre dashboard.
Une amélioration possible serait d'installer cette application dans le Cloud. Admettons donc que notre script Python ait été installé sur plusieurs ordinateurs. Nous pouvons inclure l'IP de ceux-ci dans les logs, les enrichir grâce au filtre GeoIP de Logstash.
...
filter {
geoip { source => "ip" }
}
...
Il est alors possible d'afficher une carte indiquant les pays où les machines émettent le plus de métriques :
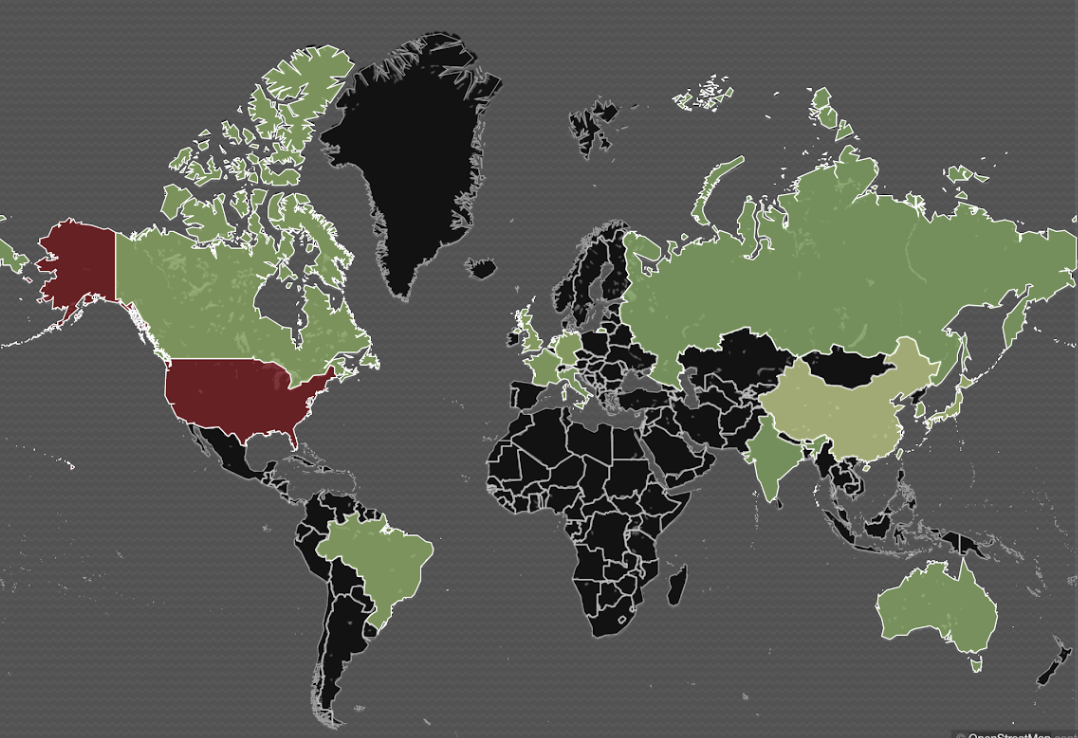
Le champs des améliorations possibles est grand, par exemple en monitorant les ressources utilisées par chaque PID.
Conclusion
L'exemple de supervision d'ordinateur est un projet from scratch dont l'architecture a été créée afin de s'entraîner avec des technologies récentes. Des outils, tels que Grafana, branchés à InfluxDB, Prometheus, Cloudwatch ou encore la stack ELK recevant les données de Metricbeat sont aussi courants dans l'industrie.
Dans l'article suivant nous expliquerons comment développer un daemon Beat récoltant les données. Ça nous permettra de profiter autant que possible de l'Elastic Stack. Puis nous nous intéresserons à Metricbeat.
