
Les objets connectés envahissent progressivement notre paysage, à titre personnel mais aussi professionnel. Le coût unitaire de capteurs connectés permet à tout un chacun de prototyper et de construire des systèmes pouvant être assez rapidement complexes. Les informations collectées peuvent assez rapidement devenir importantes. Mais souvent leur traitement, et donc leur valorisation, reste un problème épineux. De même, la création de valeur par l’interpretation de signaux et le déclenchement d’actions dérivées peut se révéler être une tâche assez complexe à mettre en oeuvre.
Offrir une plateforme permettant de tirer profit d’un parc d’objets connectés, passifs ou actifs, est un challenge que certaines entreprises technologiques ont relevé. Des acteurs majeurs, comme AT&T ou IBM, proposent de faciliter la construction de plateformes globales offrant un ensemble de solutions pour gérer cette problématique. Cela couvre la collecte des données émises, leur transport, la capacité à créer des flux de données et de traiter l’information reçue, mais aussi de déclencher des actions sur des capteurs actifs… Le fil conducteur de ces plateformes est de permettre la création rapide de nouvelles applications ou services.
IBM a travaillé autour d’une solution logicielle open sourcée permettant la création de chaînes de traitement. Cette solution se nomme Node-Red (https://nodered.org/). La vocation de cette solution est de permettre de lier aisément des sources de données à des composants de traitement, locaux ou distants, et de créer des chaînes de valeurs en quelques clics. La promesse de cette solution semble convaincre, puisqu’AT&T utilise aussi ce projet dans son offre M2X en en faisant le socle de son produit AT&T Flow Designer. IBM l’utilise aussi de façon étendue en l’intégrant à son offre sur Bluemix et en permettant l’exécution des chaînes de traitement au sein de son environnement cloud.
Alors qu’est-ce que Node-Red plus précisément ?
Techniquement, il s’agit d’une application reposant sur Node.js et permettant le design des chaînes de traitement dans un environnement Web. Node-Red fonctionne comme un ETL : une palette de connecteurs, des composants de traitement, des possibilités de wiring entre tout cela. Regardons maintenant un peu plus dans le détail.
Les composants de la palette
La palette des composants vient par défaut avec un ensemble de connecteurs assez complet. On retrouve assez classiquement des composants permettant de lire (input) et écrire (output) des données, ainsi que plusieurs autres catégories : des fonctions (split, join, range, delay, …), de l’analyse (un simple composant d’analyse de sentiment par défaut), du stockage (file), etc. On trouve facilement en input et output de quoi construire les premières bases d’une chaîne de traitement. Les types récurrents dans l’IoT sont présents (MQTT, HTTP), néanmoins la liste comporte quelques manques. De même, la section analyse fait office de parent pauvre avec un seul composant à disposition, qui d’ailleurs est plutôt limité dans son usage.
Heureusement, cette palette n’est qu’une base de départ. Il est possible de l’enrichir de plusieurs façons :
- en installant de nouveaux composants depuis la liste officielle des composants Node-Red,
- en développant ses propres composants.
Dans le premier cas, le catalogue à disposition permet de rapidement couvrir un spectre très large et souvent suffisant pour 95% des besoins. Le support des protocoles manquants par défaut est plutôt large. On trouvera donc des composants XMPP, CoAP, etc. Mais on trouvera aussi des connecteurs vers des solutions de persistance complémentaires (InfluxDB, Cassandra, etc.), mais aussi Kafka, etc. Il s’agit ici d’un pool de presque 1000 composants de qualité et/ou maturité variable aussi.
Dans le second cas, il est possible de rapidement wrapper une librairie ou un service avec un composant custom. La documentation explique assez clairement la démarche à suivre.
L’éditeur
La création de flows est très simple : du drag & drop de composants, de la configuration via un panneau contextuel et du cablage entre composants. L’organisation par onglet permet de gérer un grand nombre de flows en les organisant de façon logique en sous-ensembles. Des facilités permettent aussi des appels entre flows, même s’ils ne sont pas présents sur le même onglet.
Le déploiement d’un flow
Une fois installé, Node-Red expose la UI de design, mais permet aussi l’exécution des flows définis. L’édition d’un flow se conclut généralement par une action de déploiement. Le déploiement peut fonctionner selon 3 modes :
- un déploiement global, de type annule et remplace,
- un déploiement pour l’ensemble des composants du flow concerné,
- un déploiement uniquement des composants modifiés.
Un simple clic sur le bouton de déploiement et les flows se trouvent mis à jour et opérationnels. Simple et efficace.
Concrètement, que peut-on vraiment faire ?
Tout cela reste assez abstrait. Voici donc quelques explications pour mettre le pied à l’étrier.
Mon premier flow
Non pas qu’il soit compliqué d’installer Node-Red en local, mais à l’heure des containers, ce serait dommage de passer à côté de l’image fournie, qui permet de démarrer en quelques secondes, voire minutes. Armé de Docker donc, vous pouvez vous appuyer sur l’image “node-red-docker” (https://hub.docker.com/r/nodered/node-red-docker/) et démarrer le service.
docker run -d -p 1880:1880 --name mynodered -v ~/.node-red:/data nodered/node-red-docker
Une fois le container démarré, il est possible d’accéder à Node-Red via un navigateur. En fonction du binding de port que vous choisirez entre le container et le host, vous pourrez adapter l’URL.
Nous pouvons commencer par quelque chose de simple : récupérer des valeurs d’un capteur exposées via une API HTTP. Vous me direz, quel capteur ? Encore faut-il en avoir un sous la main et qui plus est, apte à servir des requêtes HTTP. Un tel capteur est assez simple à créer soi-même, en partant du maintenant très célèbre ESP8266. Laissons de côté cet exercice électronique et considérons que le capteur existe et retourne une enveloppe JSON comportant plusieurs métriques (température, humidité, pression atmosphérique) sous cette forme simpliste :
{
temp: {
value: 20.1,
unit: "C"
},
humidity: {
value: 72.3,
unit: "%"
},
pressure: {
value: 1020,
unit: "HPa"
}
}
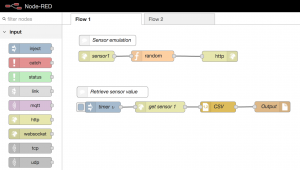
Simulons d’abord le capteur. Pour cela, il est assez simple de créer un point d’entrée avec Node-Red directement. L’API sera donc servie par Node. Quelques composants vont suffire :
- input HTTP,
- function,
- JSON,
- output HTTP.
Posons les 4 composants sur le designer et commençons la configuration.
Composant HTTP (IN)
On va répondre à des requêtes de type “GET” envoyées sur une URL (relative à l’adresse du serveur Node-red) “/sensors/1”.
Function
On crée dans cette fonction une intelligence exceptionnelle qui génère des valeurs aléatoires pour chacune des métriques et stocke cela dans un objet JS :
var sensor = {temp:{value:0,unit:"C"}, humidity:{value:0,unit:"%"}, pressure:{value:0,unit:"HPa"}};
sensor.temp.value = Math.floor(Math.random()*(40)-5);
sensor.humidity.value = Math.floor(Math.random()*100);
sensor.pressure.value = Math.floor(Math.random()*(100)+950);
msg.payload = sensor;
msg.headers={
"Content-Type":"application/json"
};
Composant HTTP (OUT)
Un déploiement (bouton “deploy” en haut à droite) permet de tester cette API.
curl http://localhost:1880/sensors/1
Tout fonctionne, notre mock de capteur est en place. Attaquons-nous à une récupération périodique des valeurs et un stockage dans un fichier. De façon très simple et intuitive, les composants à mettre en place vont être :
- un composant apte à simuler un timer : input->inject,
- un composant pour appeler l’API : function->HTTP request,
- un composant pour produire du CSV sur la base des données reçues : function->CSV,
- un composant pour produire un fichier : storage->file.
Configuration des composants
On injecte une valeur qui n’a pas de sens particulier ici, un timestamp par exemple, via le composant Inject. On spécifie surtout l’intervalle de temps, toutes les 3 secondes par exemple, avec un démarrage à l’initialisation du flow.
Le composant HTTP forge une requête HTTP. On choisit donc la méthode à utiliser : GET, ainsi que l’URL cible (sans doute dans votre cas : http://127.0.0.1:1880/sensors/1).
On mappe l’objet reçu sur une structure avec délimiteur en utilisant le composant CSV. Puis on stocke ceci dans un fichier texte en spécifiant le chemin (note : ce chemin se trouve bien sûr dans le container… ne le cherchez pas sur l’hôte, sauf si vous avez monté un volume pour cela).
Cet exemple simple illustre l’aisance de conception de flow et de leur déploiement.
Mon second flow
Voyons maintenant un peu plus loin en mettant en oeuvre un composant traditionnellement utilisé : un broker MQTT (Mosquitto ici, mais ce n’est pas le seul).
Toujours en s’aidant de Docker, démarrons Mosquitto :
docker run -d --name mosquitto -p 1883:1883 -p 9001:9001 eclipse-mosquitto
Et redémarrons Node-Red pour prendre en compte Mosquitto :
docker stop mynodered && docker rm mynodered
docker run -d -p 1880:1880 --name mynodered -v ~/.node-red:/data --link mosquitto:broker nodered/node-red-docker
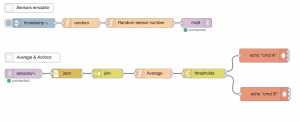
Créons un second flow (bouton “+”), nommé par défaut Flow 2. Ajoutons un simulateur de capteurs, à l’image de celui créé sur le Flow 1. Même logique ici : un injecteur, paramétré pour produire à intervalle régulier (1s) un message, envoyant vers un composant générant un message aléatoire (copié-collé du flow 1 : le composant function nommé “Random”).
Envoyons le tout vers un autre composant Function, qui cette fois génère aléatoirement un nombre compris entre 1 et 10. Ce nombre représente ici un identifiant de capteur. Il est affecté à la propriété “topic” (“sensors/” + randomId) à laquelle le composant suivant est sensible.
Le tout est envoyé donc vers le serveur MQTT.
Maintenant, mettons nous en position de consommer des messages poussés dans Mosquitto. Il suffit pour cela d’un connecteur MQTT (input), configuré pour lire tous les messages envoyés dans un sous-topic de “sensors”. En sortie, les messages étant récupérés sous forme de chaîne, un composant json les transforme en objet JS.
Le composant “join” bufferise ensuite selon une règle simple : créer des paquets de 10 messages consécutifs agrégés en un seul. Le composant Function “Average” calcule les moyennes pour les 3 valeurs de chaque message agrégé. Enfin le composant Switch permet de dispatcher vers des actions différentes (ici des appels vers des commandes exécutées sur l’OS) en fonction de seuils définis.
Ce second flow, un peu plus riche, permet d’entrevoir les possibilités de conception et l’aisance de définition et de déploiement.
En conclusion
La vraie richesse est surtout rendue possible par la palette communautaire de composants. Vous avez besoin d’un composant de type PID pour asservir un pilotage de commande ? C’est disponible ! Accéder à un serveur InfluxDB, plutôt pertinent lorsqu’il s’agit de stocker et d’accéder à des données temporelles issues de capteurs ? Disponible aussi ! Nous n’avons pas abordé non plus la gestion des erreurs, prise en charge par défaut et permettant de cabler les automatismes utiles pour traiter ce type de cas.
L’interconnexion avec un écosystème de services, exposés dans votre SI, peut aussi se réaliser de façon très simple : exposez vos API et consommez les depuis vos flows, voir créez vos propres composants pour wrapper les appels aux services et rendre leur intégration plus simple. Pour vous faire une idée de la forme que cela peut prendre, vous pouvez tester par exemple les composants proposés par Microsoft en accès gratuit (mais limité) autour de fonctions cognitives (NLP, image recognition, etc.) Transposez ça par exemple sur des fonctions de simulation techniques complexes d’un système industriel et vous pouvez apercevoir le type de service pouvant être offert pour la création de flows sophistiqués.
Node-Red, bien que déjà riche, ne présente pas autant de possibilités que les plateformes industrielles qui l’utilisent. Il peut dans le cas de déploiements limités ou non critiques être une réponse à lui seul, comme aussi devoir laisser la main à des plateformes beaucoup plus étendues, comme celles citées en début d’article (IBM Watson IoT Platform, AT&T M2X, etc.) Ils offriront non seulement des composants très sophistiqués (suite de composants “intelligents” Watson s’appuyant sur les travaux d’IA de l’éditeur), mais aussi la prise en charge de la haute disponibilité, les possibilités offertes par le cloud en termes de scalabilité, etc.
En attendant, vous pouvez d’ores et déjà vous initier à votre propre échelle, sur une modeste Raspberry Pi et quelques capteurs ici ou là dans votre logement. Certains l’utilisent déjà massivement pour leur domotique.
