

Il était une fois, l’histoire du projet parfait. Laissez-nous vous expliquer sa genèse, les défis que nous avons relevés et les enseignements que nous en avons tirés.
Tout commence en septembre 2022, quand émerge la nouvelle startup Fairplayer de KSS, l’accompagnateur Ippon de startups.
Sur le papier, Fairplayer, c'est : "Le financement alternatif des clubs sportifs professionnels par émission de jetons numériques destinés à la fan base du club".
Le challenge proposé à l’époque est de sortir un premier MVP d'ici la fin d'année 2022 avec un premier club pilote.
Nous sommes aujourd’hui en mai 2023, et après le succès du premier pilote, nous lançons un nouveau club, le LOU Rugby. La marketplace est déjà disponible ici.
Comme nous avions pu le faire pour Prismea il y a quelques années, nous souhaitions partager avec vous les enseignements que nous avons tirés de cette expérience Fairplayer. Dans cet article, nous plongerons au cœur de notre parcours, en explorant les défis auxquels nous avons été confrontés et comment nous avons réussi à les résoudre.
Cet article est co-écrit par les 4 développeurs du projet. Il n’y a pas forcément de lien entre chaque section, il s’agit avant tout d’une mise en lumière des éléments qui nous tiennent le plus à cœur, que nous souhaitons mettre en avant et partager.
Méthodologie d’une équipe évolutive
Le projet ayant 9 mois d’ancienneté lors de la rédaction de cet article, l’équipe a eu le temps de beaucoup évoluer et de profiter d’expertises diverses.
Le développement de la solution a débuté en septembre 2022 avec 3 développeurs fullstack, dont un expert de l’univers Web3.
La pluridisciplinarité de l’équipe est un atout qui permet de couvrir efficacement un large éventail de sujets. Récemment, l’équipe a accueilli un stagiaire fullstack, jugeant ce projet comme une belle carte de visite de ce qui se fait techniquement en 2023 chez Ippon Technologies.
Au démarrage du projet, nous avions comme objectif avec les fondateurs de livrer une version minimale viable (MVP) de la plateforme de vente de produits pour 2023. La priorisation des tâches est souvent remise en question sur ce projet et notre vision est principalement portée sur les 2 semaines à venir. Nous utilisions pour ce faire un tableau virtuel inspiré de la méthode Kanban, dans lequel figuraient les tâches macro, que nous ajustions au fil de nos avancées.
Étant donné qu’il s’agit d’un projet porté par Ippon, nous avons eu la chance de pouvoir faire appel facilement aux experts Ippon de chaque domaine pour venir nous épauler sur le projet et ses différentes problématiques. En effet, en plus de nos compétences de développement, un consultant produit/UX, une consultante UI et un expert DevOps nous ont accompagnés durant l’élaboration du projet.
L’architecture composite de Fairplayer
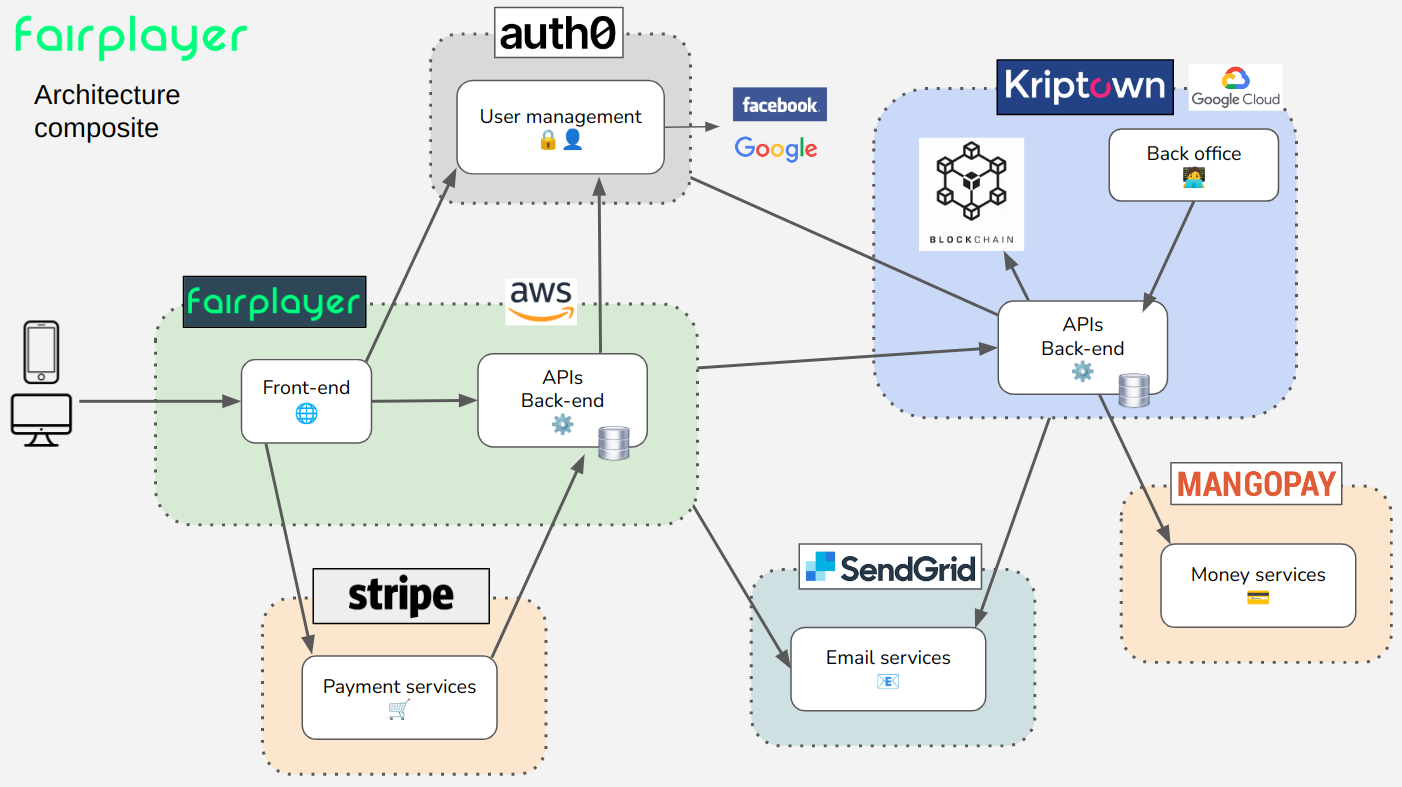
Architecture composite de Fairplayer et des partenaires
Voici à quoi ressemble la solution Fairplayer. Nous avons principalement un front-end en TypeScript / Vue.js et un back-end en Java / Spring Boot dans leurs dernières versions, le tout hébergé sur AWS.
La partie exposée à l’utilisateur est une application web. Nous avons commencé avec une approche mobile first (élaboration d’une Progressive WebApp) pour nous concentrer par la suite sur l’adaptation desktop.
Nous nous appuyons sur un ensemble de partenaires qui répondent à tous les besoins non essentiels, nous parlons d’architecture composite. Ainsi, nous pouvons focaliser nos forces sur le but premier de Fairplayer : apporter de nouveaux revenus aux clubs de sport.
Comme on peut le voir sur le schéma, nous travaillons avec Kriptown pour gérer les actifs numériques stockés sur une blockchain (fork privé d’Ethereum) et la gestion d’identités (KYC nécessaire). Nous utilisons également Auth0 pour gérer les authentifications des utilisateurs, MangoPay pour la gestion des transactions financières liées au portefeuille d’actifs numériques, SendGrid pour la gestion des e-mails et Stripe pour les paiements en ligne.
Un MVP uniquement front-end
Durant la première phase du projet, nous avons dû faire des choix techniques pour respecter la deadline serrée de sortir un MVP pour fin 2022. Kriptown nous a fourni une solution back-end pour gérer l’émission de jetons, la gestion des comptes utilisateurs et de leurs KYC, ainsi que la gestion de la boutique. Nous avons fait le choix de ne réaliser, dans un premier temps, qu’une partie front-end, en nous appuyant entièrement sur la solution back-end Kriptown couplée à leur solution de connexion Auth0. Cette décision a considérablement accéléré notre développement, nous permettant de fournir plus rapidement une solution fonctionnelle.
Cependant, ce choix comporte des inconvénients. Nous avons créé une dette technique en étant très dépendants de la solution de Kriptown. Afin de ne pas impacter notre métier avec des notions propres à Kriptown, nous avons mis en place côté front-end une architecture hexagonale. Cette architecture nous a permis de créer une protection (anti-corruption layer) entre notre métier et les endpoints fournis par Kriptown. Par exemple, la notion de “Startups” chez Kriptown est transformée en “Clubs” dans notre métier.
Une fois le MVP mis en place, nous avons initié notre projet back-end. L’objectif de ce nouveau projet était de pouvoir ajouter des fonctionnalités que l’API de Kriptown ne permettait pas. Nous avons dans un premier temps créé un back-end servant de proxy, qui se contentait d’interroger l’API de Kriptown. En prenant l’exemple du endpoint de récupération des produits d’un club, nous avons pu ajouter de nouvelles fonctionnalités comme la gestion de catégorie ou de rareté, qui sont des notions inconnues pour Kriptown.
JHipster Lite
Pour les différentes applications que nous avons développées, nous avons généré le code avec JHipster Lite. Il s’agit d’une déclinaison du projet Open-Source JHipster.
Dans cette version, on favorise les approches autour du craftsmanship : la qualité est au centre (outils de lint configurés de manière stricte, couverture de code à 100%). Le code est structuré autour d’une architecture hexagonale. Tout est pensé pour pouvoir utiliser les approches xDD (TDD, BDD, DDD).
Comme pour la version classique de JHipster, le but est de se concentrer sur le code métier (celui qui a une importance à nos yeux). Le code de “glue” est généré, pas besoin de savoir comment un outil technique se configure et communique avec un autre.
JHipster Lite est un projet encore assez jeune, mais il était largement assez mature pour pouvoir être utilisé. Nous avons pu contribuer à l’amélioration du projet Open Source en corrigeant les quelques imperfections que nous avons découvertes en l’utilisant.
On ne peut que vous recommander l’outil : https://www.jhipster.tech/jhipster-lite/
GraphQL
Pour atteindre les objectifs du MVP, nous avons eu besoin de consommer le service de notre principal partenaire : Kriptown. Pour ce faire, nous avons utilisé GraphQL, un langage de requête de données, utilisé pour leur API côté serveur.
Pour rappel, lors du MVP, le back-end n’existait pas encore. Les requêtes GraphQL étaient réalisées depuis notre front-end vers le serveur Kriptown.
GraphQL est facilement intégrable à une architecture hexagonale. En effet, une fois le client instancié, il suffit de paramétrer les méthodes de query et de mutation.
async query<T>(query: string, options: { variables?: OperationVariables; cache?: boolean } = {}): Promise<ApolloQueryResult<T>> {
return this.apolloClient.query(buildQueryOptions(query, options)).catch(error => this.throwError(error));
}
async mutate<T>(mutation: string, input?: Record<string, any>, options = { flatInput: false }): Promise<FetchResult<T>> {
return this.apolloClient
.mutate({
mutation: gql`
${mutation}
`,
variables: createVariables(input, options.flatInput),
})
.catch(error => this.throwError(error));
}
De là, il ne nous reste plus qu’à créer nos adapters comme habituellement, en injectant notre classe de méthodes templates. GraphQL permettant de récupérer seulement les données souhaitées, il est très simple de séparer chaque schéma récupéré dans des adapters différents et ainsi de s’assurer de l’intégrité et de la protection de notre domaine.
Pour plus d'informations concernant le fonctionnement de GraphQL, je vous invite à consulter cet article. Ici, nous allons parler d’un cas pratique et de la façon dont nous l’avons implémenté sur Fairplayer.
Pour implémenter GraphQL dans une webapp, nous avons utilisé la bibliothèque JavaScript Apollo Client. En plus de son client, Apollo possède également un explorer :
Apollo Explorer, https://www.apollographql.com/tutorials/fullstack-quickstart/06-connecting-graphs-to-apollo-studio
Cela nous a grandement aidé dans la prise en main et l’implémentation de GraphQL dans notre webapp.
De plus, Apollo Client dispose d’un système de cache. Par défaut, chaque fois que le client Apollo récupère le résultat d’une requête, il vient stocker localement son résultat afin de permettre un usage plus rapide lorsque celle-ci est appelée à nouveau. Cela est assez pratique pour requêter les données d’un club ou les informations personnelles d’un fan, car une fois définies, elles ne sont généralement pas sujettes à beaucoup de changements.
const GET_KYC_QUESTIONS = `
query KycQuestions {
lcbftQuestions {
text
lcbftAnswers {
text
}
}
}
`;
return this.kriptownCaller
.query<KriptownKycQuestionsResult>(GET_KYC_QUESTIONS, { cache: true })
.then(response => toKycQuestions(response.data));En revanche, les transactions liées aux portefeuilles sont fréquentes (mise en cache inappropriée) et asynchrones (transactions insérées dans une blockchain). Ces transactions nécessitent d’avoir des données à jour et réactives. Pour cela, il existe la méthode watchQuery.
WatchQuery nous permet d’utiliser l’option pollInterval afin d'exécuter la query périodiquement, toutes les secondes ici, assurant une mise à jour presque en temps réel.
observableViewerBalance(): Observable<Optional<Fiat>> {
return this.kriptownCaller
.watchQuery<KriptownViewerResult>(GET_VIEWER_BALANCE, { pollInterval: 1000 })
.map(({ data }) => Optional.ofZero(data.viewer.balance).map(euro));
}
Cette méthode renvoie un objet du design pattern Observable, redéfini simplement dans notre code du domaine :
export interface Subscription {
unsubscribe(): void;
}
export interface Observable<T> {
subscribe(onNext: (value: T) => void): Subscription;
}
Une fois dans le composant, il nous suffit d’appeler la méthode précédemment créée, qui exécute la lambda subscribe à chaque nouvelle réponse. Attention à ne pas oublier d’unsubscribe à la fin des opérations.
const observable = await fanRepository.observableFiatNotProcessed();
subscription = observable.subscribe(fiatNotProcessed => {
if (fiatNotProcessed.isEmpty()) {
subscription.unsubscribe();
router.push({ name: 'paymentConfirmed', query });
}
});
Tests d’intégrations côté front-end
Il est important de nous assurer que le code appelant les partenaires (ex : Kriptown, Sendgrid, …) reste fonctionnel dans le temps, alors que nous ne contrôlons pas les évolutions de ces API. Concrètement, il faut vérifier que l’API reste disponible, que les résultats de l’appel sont correctement mappés vers nos objets, que le contrat n’est pas cassé dans le temps, que le partenaire ne supprime pas cette API, etc.
Nous avons l’habitude de tester notre intégration avec nos partenaires côté back-end.
Nous avons souhaité faire la même chose côté front-end. Nous avons ainsi des tests JavaScript pour vérifier les appels à nos “partenaires” : le back-end et les partenaires externes (Kriptown, …).
À l’usage, nous trouvons cela très pratique : cela nous offre la possibilité de faire du TDD sur le développement de l’API, de vérifier qu’on ne casse rien lors d’un refactoring de code, et bien sûr que ni nous, ni le partenaire ne casse l’API dans le temps.
const repository = getProvider(walletRepositoryKey);
describe('WalletRepository - Int test', () => {
it('should credit wallet by card', async () => {
expect(await repository.creditWalletByCard('155481741', makeTwoHundredsTokensOfOneCents(), '666')).toBeDefined();
});
});
Code coverage et Sonar
Nous avons fait le choix de n’avoir aucun dashboard de monitoring de qualité de code tel que Sonar.
En effet, nous intégrons la qualité de code dès la phase de développement de nos fonctionnalités, cela nous permet d’éviter d’avoir des pertes de qualité dans notre code qui ne seraient traitées au mieux qu’a posteriori.
Pour cela, nous disposons d’une CI assez complète avec plusieurs étapes dont la responsabilité est d’assurer ce contrôle de qualité :

Nous nous assurons par exemple que la couverture de code est à 100%. Si ce n’est pas le cas, cela nous indique qu’il y a sans doute du code mort ou un problème lors d’un refactoring. En effet, cette métrique n’est pas un but recherché en soi, mais davantage d’une résultante de la méthode TDD.
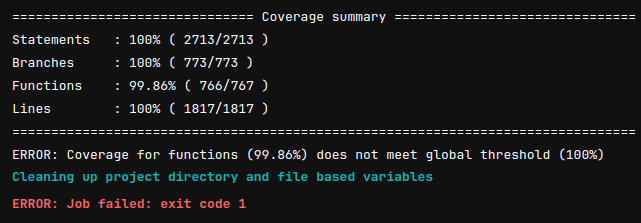
Toujours lors de la CI, Sonar permet de vérifier si le code n’a pas d’imperfections (exemple : code complexe, problème de sécurité, …). Comme vous pouvez le voir ci-dessous, si une seule erreur est détectée par cet outil, la CI se met en échec et nous force à apporter une correction.
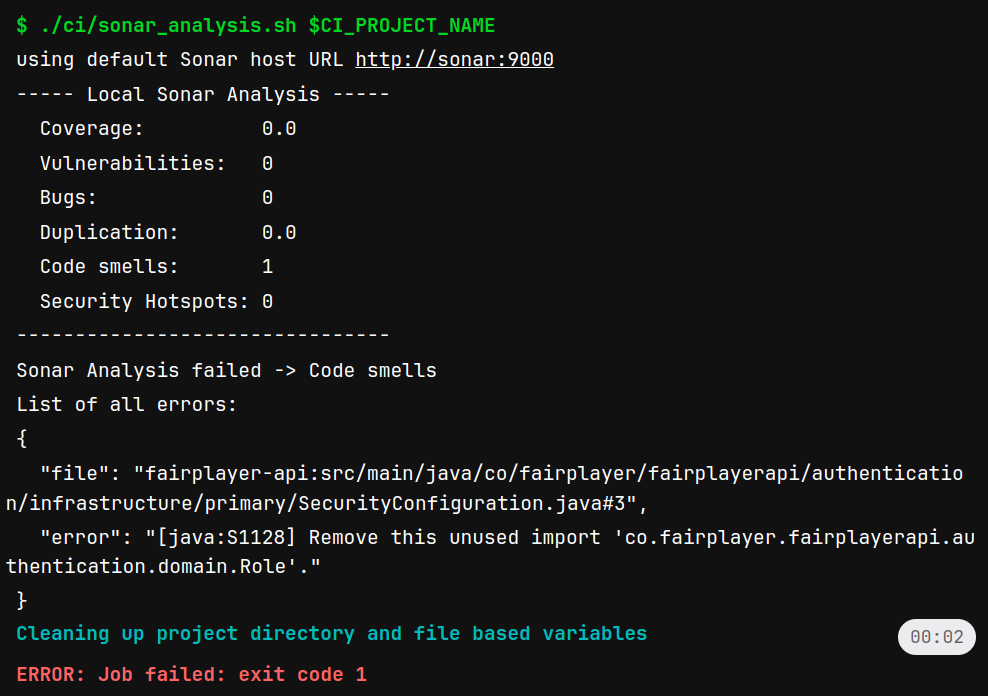
Finalement, la CI nous assure d’avoir un code de qualité dans le temps : on évite toutes sortes d’erreurs, qui ne seraient pas relevées lors de la revue de code. De plus, cela nous évite de devoir gérer les problèmes a posteriori et ainsi créer de la dette technique sur le projet.
Gestion des fichiers statiques
La partie de gestion et d’hébergement de fichiers est un élément clé de notre projet : images des produits, documents légaux, etc. Pour être le plus rapidement possible sur le marché, nous avons tout d’abord fait le choix d’héberger nos fichiers sur Imgur. Nous savions que ce n’était pas une solution viable dans le temps, car pas industrialisable (opérations très manuelles).
Par la suite, nous avons décidé de stocker les images en interne. Pour cela, nous avons choisi d’utiliser la même architecture que notre webapp, c’est-à-dire une stack serverless sur AWS (S3 + CloudFront + Route 53).
Ainsi, cette solution est beaucoup plus industrialisée et plus proche de nos process de développement : les images sont versionnées et soumises à relecture sur GitLab.
Blockchain : les barrières rencontrées
Fairplayer construit l’ensemble de sa solution autour des technologies du Web3. Petit à petit, nous avons expérimenté des travaux lors de nos différents ateliers et développements, et il en résulte des conseils qui peuvent servir à quiconque veut travailler sur le sujet, car la route est semée d'embûches. Cela mérite un article à part entière. Restez connecté pour être sûr de ne pas le rater.
En attendant, ne manquez pas l'évènement dédié Blockchain, le 8 juin, avec l'intervention du CEO et co-fondateur de Fairplayer.
https://blockchainday.ippon.tech/



