
This is part 2 of our 5-part series on improving the performance of the Spring-petclinic application. You can find the first part here.
Let’s profile our application
The error from part 1 is quite clear: we fill up all the server memory until the application slows down and crashes.
This is time to launch our profiler! Our two favorite tools are:
- JProfiler, which is the most complete and is a little bit expensive. This is the one we usually recommend to our clients.
- YourKit, which is easier to use and is less expensive. This is the one we use for Tatami, as they provide free licenses for Open Source projects. If you have never used a profiler before, we recommend that you start with Yourkit.
We have used YourKit for this profiling session, mainly because we found its screenshots look better.
As we can see from this first screenshot, we have found our first culprit: Dandelion (which is a tag library used to display nice-looking HTML tables) is using most of our memory.

Dandelion is a great project, but it is using too much memory on this version. As we would love to use Dandelion again, we have filled a bug on the project’s website, and the project’s developpers have been very quick at resolving it!
So the next version of Dandelion doesn’t have this problem anymore, and you can safely use it on high-volume applications.
Solving the memory issue with Dandelion
Of course we will upgrade to the next version of Dandelion, which will resolve this issue, but for the moment, as we need to move forward, we will replace it with a classic HTML table, which is then beautified using JavaScript. We have used JQuery DataTables, which provides a similar, but pure-JavaScript, solution:
We then ran our tests again: we now go up to 560 req/sec and then down again… The application now fails at 3000-4000 users. We have just pushed our memory limit further, but as soon as the heap space is filled up, the whole application starts to fail again.
This is already a big improvement, but it looks like we still have a memory problem. Let’s fire YourKit again:
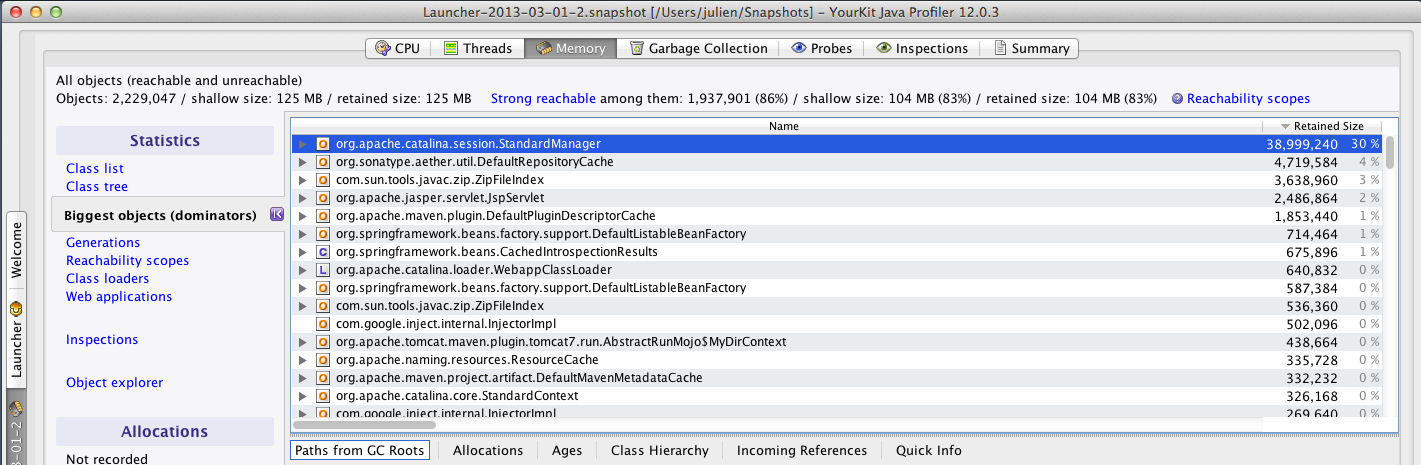
The heap memory is mostly used by “org.apache.catalina.session.StandardManager”, which is Tomcat’s class that manages HTTP sessions. This means the HTTP sessions are using all the free heap space, until the JVM cannot handle connections anymore.
Going stateless
We have fallen into a classical pitfall in Web application design: using stateful data prevents the application from scaling up.
On our application, it is rather easy to become stateless:
For this project, going stateless is mostly a matter of reloading data from the database instead of using the HTTP session as a kind of cache. Of course things are not always that easy, for instance when you manage “conversations” in a business application. Our goal is to lower the amount of data stored in the user’s HTTP session, as it is one of main scalability issues we encounter: we are here rather lucky, as we can remove all of this data.
Once those modifications have been done, let’s launch our stress test again: YourKit confirms that we do not use the HTTP Session anymore, and we can now handle the load without any problem. The biggest object in memory is now “org.sonatype.aether.util.DefaultRepositoryCache”, which comes from Maven (remember that we launch the application with “mvn clean tomcat7:run”).
The application can now handle our 500 threads doing 10 loops for the first time. However, our results are not perfect: we can serve 532 req/sec, but we still have 0.70% HTTP errors.
This result is a little bit slower than what we got during the previous step (we reached 560 req/sec before failing), as we now read more data from the database, instead of using the HTTP Session as a cache.
Tuning Tomcat
We have HTTP errors, which are distributed on all pages: this is a classical problem with Tomcat, which is using blocking IO by default. Let’s use the new Tomcat NIO connector:
(Many thanks to Olivier Lamy for this configuration, which was not explained in the official documentation!).
Now, we have no HTTP error at all, and we are able to handle 867 req/sec.
Conclusion of part 2
Now the application is starting to work! We can handle our 5000 users without any error at all, and the performance is rather good, at 867 req/sec.
On part 3, we will see that we can do even better.
[edit]
You can find the other episodes of this series here : part 1, part 3, part 4 and part 5.
